
Rumah >Peranti teknologi >AI >UCLA Chinese mencadangkan mekanisme bermain sendiri yang baharu! LLM melatih dirinya sendiri, dan kesannya lebih baik daripada bimbingan pakar GPT-4.
UCLA Chinese mencadangkan mekanisme bermain sendiri yang baharu! LLM melatih dirinya sendiri, dan kesannya lebih baik daripada bimbingan pakar GPT-4.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-03 08:00:161388semak imbas
Data sintetik telah menjadi asas terpenting dalam evolusi model bahasa yang besar.
Pada penghujung tahun lalu, beberapa netizen mendedahkan bahawa bekas ketua saintis OpenAI Ilya berulang kali menyatakan bahawa tiada kesesakan data dalam pembangunan LLM, dan data sintetik boleh menyelesaikan kebanyakan masalah.
 Gambar
Gambar
Selepas mengkaji kumpulan kertas terbaharu, Jim Fan, seorang saintis kanan di Nvidia, membuat kesimpulan bahawa menggabungkan data sintetik dengan permainan tradisional dan teknologi penjanaan imej boleh membolehkan LLM mencapai evolusi diri yang besar.
 Gambar
Gambar
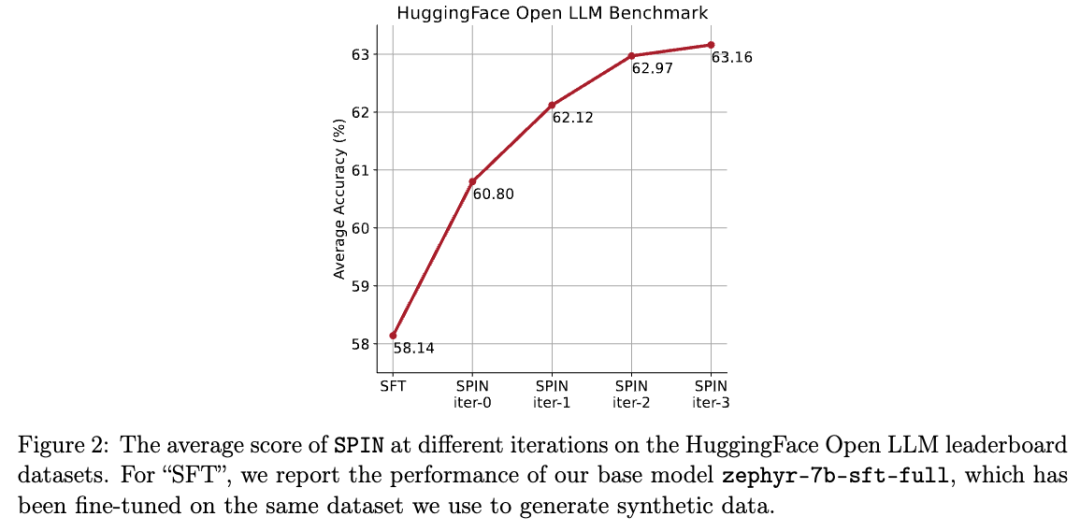
Kertas yang secara rasmi mencadangkan kaedah ini ditulis oleh pasukan Cina dari UCLA. . dan melalui kendiri kaedah penalaan halus, tidak Bergantung pada set data baharu, skor purata LLM yang lebih lemah pada Penanda Aras Papan Pendahulu LLM Terbuka ditingkatkan daripada 58.14 kepada 63.16.

Gambar
Dengan cara ini, evolusi kendiri model boleh diselesaikan tanpa memerlukan data anotasi manusia tambahan atau maklum balas daripada model bahasa peringkat tinggi. 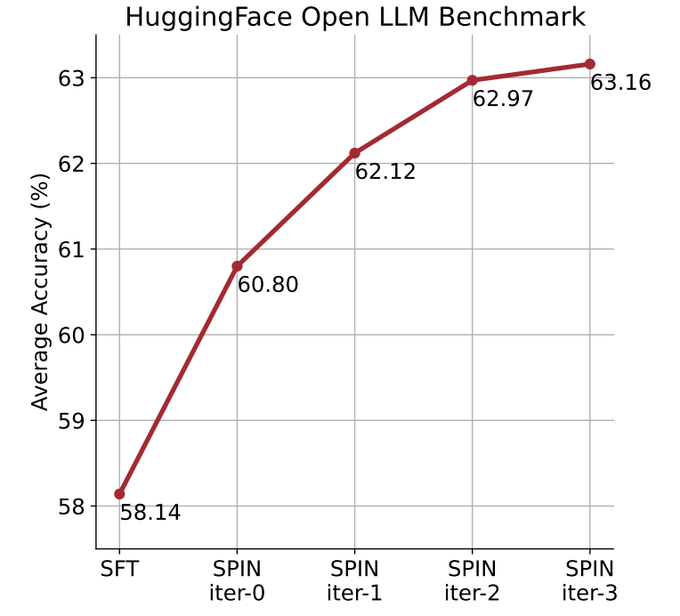
Parameter model utama dan model lawan adalah sama. Bermain menentang diri anda dengan dua versi berbeza.
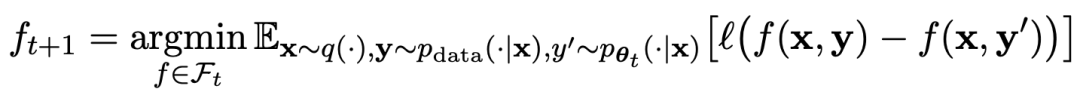 Proses permainan boleh diringkaskan dengan formula:
Proses permainan boleh diringkaskan dengan formula:
Gambar
Kaedah latihan bermain sendiri Secara ringkasnya, ideanya adalah lebih kurang seperti ini:
yang menarik. yang dihasilkan oleh model lawan dengan melatih model utama dan tindak balas sasaran manusia, model lawan ialah model bahasa yang diperoleh secara berulang dalam pusingan, dengan matlamat untuk menghasilkan respons yang tidak dapat dibezakan mungkin.Andaikan bahawa parameter model bahasa yang diperoleh dalam lelaran ke-t ialah θt, kemudian dalam lelaran t+1, gunakan θt sebagai pemain lawan, dan gunakan θt untuk menjana respons y' bagi setiap gesaan x dalam set data penalaan halus diselia.
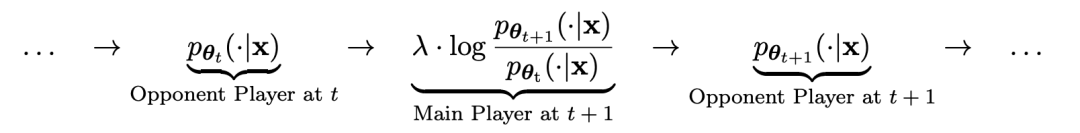 Kemudian optimumkan parameter model bahasa baharu θt+1 supaya ia boleh membezakan y' daripada respons manusia y dalam set data penalaan halus yang diselia. Ini boleh membentuk proses beransur-ansur dan secara beransur-ansur menghampiri pengedaran tindak balas sasaran.
Kemudian optimumkan parameter model bahasa baharu θt+1 supaya ia boleh membezakan y' daripada respons manusia y dalam set data penalaan halus yang diselia. Ini boleh membentuk proses beransur-ansur dan secara beransur-ansur menghampiri pengedaran tindak balas sasaran.
Di sini, fungsi kehilangan model utama menggunakan kehilangan logaritma, dengan mengambil kira perbezaan dalam nilai fungsi antara y dan y'.
Tambah KL divergence regularization kepada model lawan untuk mengelakkan parameter model daripada menyimpang terlalu banyak.
Objektif latihan permainan lawan yang khusus ditunjukkan dalam Formula 4.7. Ia dapat dilihat daripada analisis teori bahawa apabila taburan tindak balas model bahasa adalah sama dengan taburan tindak balas sasaran, proses pengoptimuman menumpu.
Jika anda menggunakan data sintetik yang dijana selepas permainan untuk latihan, dan kemudian menggunakan SPIN untuk penalaan kendiri, prestasi LLM boleh dipertingkatkan dengan berkesan.
Gambar
Tetapi hanya penalaan halus semula pada data penalaan halus awal akan menyebabkan kemerosotan prestasi.
SPIN hanya memerlukan model awal itu sendiri dan set data diperhalusi sedia ada, supaya LLM boleh memperbaiki dirinya melalui SPIN. Khususnya, SPIN malah mengatasi prestasi model yang dilatih dengan data keutamaan GPT-4 tambahan melalui DPO. Dan eksperimen juga menunjukkan bahawa latihan berulang boleh meningkatkan prestasi model dengan lebih berkesan daripada latihan dengan lebih banyak zaman. Memanjangkan tempoh latihan satu lelaran tidak akan mengurangkan prestasi SPIN, tetapi ia akan mencapai hadnya. Semakin banyak lelaran, semakin jelas kesan SPIN. Selepas membaca kertas ini, netizen mengeluh: Data sintetik akan mendominasi pembangunan model bahasa besar, yang akan menjadi berita yang sangat baik untuk penyelidik model bahasa besar! . Matlamat seterusnya adalah untuk mencari LLM baharu yang mampu membezakan antara respons y yang dihasilkan dan respons y' yang dijana oleh manusia. Pemain utama atau LLM baru Dalam lelaran seterusnya, LLM yang baru diperolehi Cara menggunakan SPIN untuk meningkatkan prestasi model Para penyelidik mereka bentuk permainan dua pemain, di mana matlamat model utama adalah untuk membezakan antara respons yang dijana LLM dan respons yang dijana manusia. Pada masa yang sama, peranan musuh adalah untuk menghasilkan tindak balas yang tidak dapat dibezakan daripada manusia. Pusat kepada pendekatan penyelidik ialah melatih model utama. Terangkan dahulu cara melatih model utama untuk membezakan respons LLM daripada respons manusia. Di tengah-tengah pendekatan penyelidik ialah mekanisme permainan sendiri, di mana kedua-dua pemain utama dan lawan adalah LLM yang sama, tetapi daripada lelaran yang berbeza. Secara lebih khusus, lawan ialah LLM lama daripada lelaran sebelumnya, dan pemain utama ialah LLM baharu untuk belajar dalam lelaran semasa. Lelaran t+1 merangkumi dua langkah berikut: (1) melatih model utama, (2) mengemas kini model lawan. Melatih model induk Pertama, penyelidik akan menerangkan cara melatih pemain induk untuk membezakan antara tindak balas LLM dan tindak balas manusia. Diilhamkan oleh ukuran kebarangkalian integral (IPM), para penyelidik merumuskan fungsi objektif: Kemas kini model lawan matlamat untuk mencari LLM yang lebih baik menghasilkan Tindak balas daripada tidak berbeza daripada data p model utama.
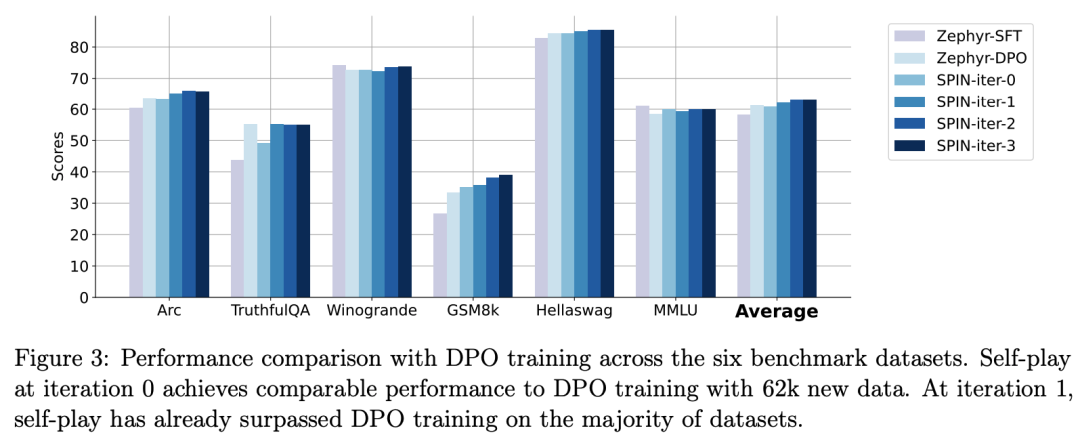
Para penyelidik menggunakan HuggingFace Open LLM Leaderboard sebagai penilaian yang meluas untuk membuktikan keberkesanan SPIN. Dalam rajah di bawah, penyelidik membandingkan prestasi model yang diperhalusi oleh SPIN selepas 0 hingga 3 lelaran dengan model asas zephyr-7b-sft-full. Para penyelidik dapat memerhatikan bahawa SPIN menunjukkan hasil yang ketara dalam meningkatkan prestasi model dengan memanfaatkan lagi set data SFT, di mana model asas telah diperhalusi sepenuhnya. Dalam lelaran 0, tindak balas model dihasilkan daripada zephyr-7b-sft-full, dan penyelidik memerhatikan peningkatan keseluruhan sebanyak 2.66% dalam skor purata. Peningkatan ini amat ketara pada penanda aras TruthfulQA dan GSM8k, dengan peningkatan masing-masing lebih 5% dan 10%. Dalam Lelaran 1, para penyelidik menggunakan model LLM daripada Lelaran 0 untuk menjana respons baharu untuk SPIN, mengikut proses yang digariskan dalam Algoritma 1. Lelaran ini menghasilkan peningkatan lagi sebanyak 1.32% secara purata, yang amat ketara pada Arc Challenge dan tanda aras TruthfulQA. Lelaran seterusnya meneruskan aliran peningkatan tambahan untuk pelbagai tugas. Pada masa yang sama, peningkatan pada lelaran t+1 adalah lebih kecil secara semula jadi terlatih. Para penyelidik mendapati bahawa DPO memerlukan input manusia atau maklum balas model bahasa peringkat tinggi untuk menentukan pilihan, jadi penjanaan data adalah proses yang agak mahal. Selain itu, tidak seperti DPO yang memerlukan sumber data baharu, pendekatan penyelidik memanfaatkan sepenuhnya set data SFT sedia ada. Rajah di bawah menunjukkan perbandingan prestasi SPIN dengan latihan DPO pada lelaran 0 dan 1 (menggunakan data SFT 50k). Para penyelidik dapat memerhatikan bahawa walaupun DPO menggunakan lebih banyak data daripada sumber baharu, SPIN berdasarkan data SFT sedia ada bermula dari lelaran 1. SPIN malah melebihi prestasi DPO dan kedudukan SPIN dalam kedudukan ujian penanda aras malah melebihi DPO. Rujukan: 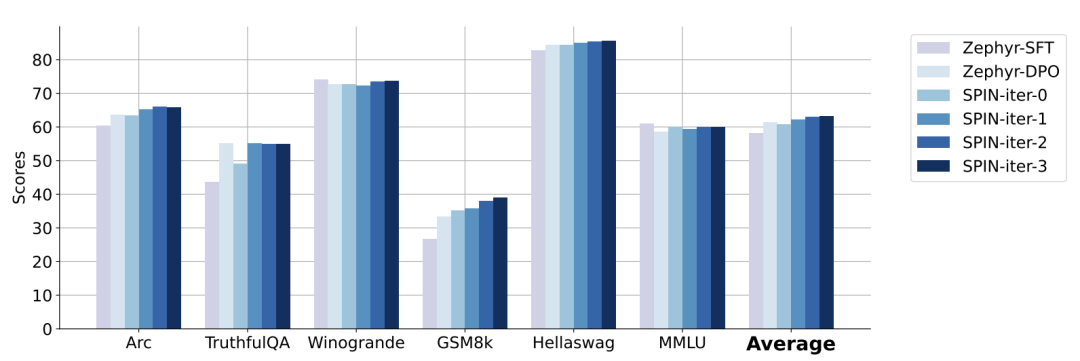 Gambar
Gambar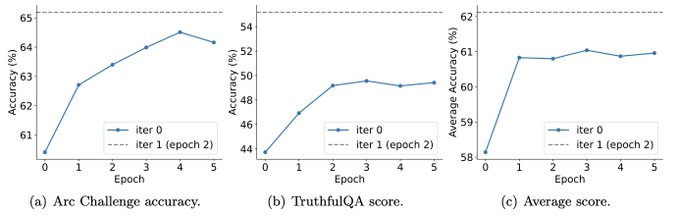 Gambar
Gambar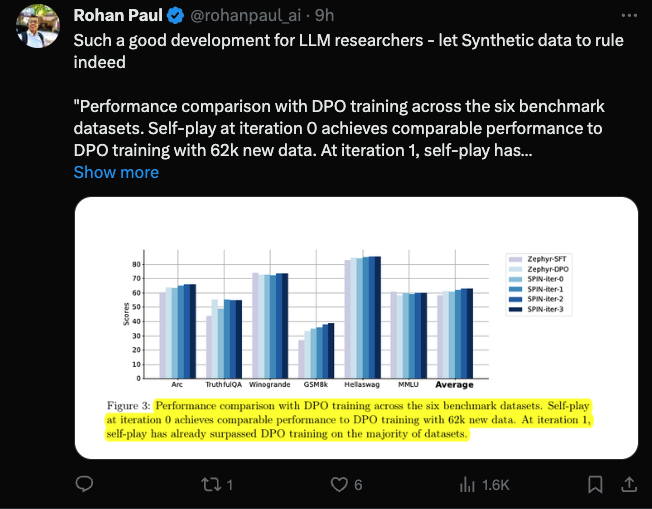 dilambangkan dengan
dilambangkan dengan 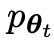 Proses ini boleh dilihat sebagai permainan dua pemain:
Proses ini boleh dilihat sebagai permainan dua pemain: 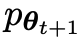 cuba untuk melihat tindak balas pemain lawan dan tindak balas yang dihasilkan oleh manusia, manakala pihak lawan atau LLM
cuba untuk melihat tindak balas pemain lawan dan tindak balas yang dihasilkan oleh manusia, manakala pihak lawan atau LLM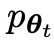 lama menjana Respons adalah sama yang mungkin dengan data dalam set data SFT beranotasi secara manual. .
lama menjana Respons adalah sama yang mungkin dengan data dalam set data SFT beranotasi secara manual. . 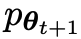 menjadi lawan yang dijana tindak balas, dan matlamat proses bermain sendiri ialah LLM akhirnya menumpu kepada
menjadi lawan yang dijana tindak balas, dan matlamat proses bermain sendiri ialah LLM akhirnya menumpu kepada 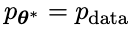 , supaya LLM yang paling kuat tidak lagi mampu untuk membezakan antara versi respons yang dijana sebelum ini dan versi janaan Manusia.
, supaya LLM yang paling kuat tidak lagi mampu untuk membezakan antara versi respons yang dijana sebelum ini dan versi janaan Manusia. 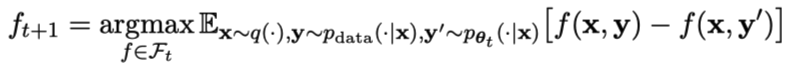 Gambar
Gambar SPIN berkesan meningkatkan prestasi penanda aras
 Gambar
Gambar
Atas ialah kandungan terperinci UCLA Chinese mencadangkan mekanisme bermain sendiri yang baharu! LLM melatih dirinya sendiri, dan kesannya lebih baik daripada bimbingan pakar GPT-4.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Buat pertama kali: Microsoft menggunakan GPT-4 untuk memperhalusi arahan model besar, dan prestasi sifar sampel tugas baharu dipertingkatkan lagi.
- GPT-4 menimbulkan kebimbangan, dan beribu-ribu tokoh teknologi termasuk Musk menyeru agar moratorium pembangunan AI yang lebih kukuh
- watchGPT dijenamakan semula sebagai 'Petey' dan dinaik taraf kepada GPT-4 untuk memintas semakan App Store
- Alibaba Cloud AnalyticDB (ADB) + LLM: Membina Chatbot khusus perusahaan dalam era AIGC