
Rumah >Peranti teknologi >AI >Alibaba Cloud AnalyticDB (ADB) + LLM: Membina Chatbot khusus perusahaan dalam era AIGC
Alibaba Cloud AnalyticDB (ADB) + LLM: Membina Chatbot khusus perusahaan dalam era AIGC

- 王林ke hadapan
- 2023-05-23 12:23:471424semak imbas
Pengenalan
Cara menggunakan vektor pangkalan data +LLM (Model Bahasa Besar) untuk mencipta Chatbot khusus syarikat yang lebih memahami anda?
1. Mengapa Chatbot memerlukan model bahasa + pangkalan data vektor?
Musim bunga ini, produk teknologi yang paling mengejutkan ialah kemunculan ChatGPT Melalui model bahasa besar (LLM), orang ramai dapat melihat bahawa AI generatif boleh mencapai matlamat yang sama seperti bahasa manusia. Dengan keupayaan ekspresi bahasa yang sangat serupa, AI tidak lagi berada di luar jangkauan dan kini boleh memasuki kerja dan kehidupan manusia. Ini telah menghidupkan semula bidang AI yang telah tidak terhitung untuk beberapa lama perubahan. Dalam teknologi generasi akan datang, AI generatif telah menjadi sebahagian daripada modal dan perusahaan yang tidak boleh diabaikan, dan tahap keupayaan infrastruktur yang lebih tinggi semakin diperlukan untuk menyokong pembangunannya.
Model besar boleh menjawab lebih banyak soalan Ia adalah masalah universal, tetapi jika anda ingin berkhidmat dalam bidang profesional menegak, akan ada masalah kedalaman pengetahuan dan ketepatan masa yang tidak mencukupi Jadi bagaimana syarikat boleh merebut peluang dan membina perkhidmatan medan menegak? Pada masa ini terdapat dua model Yang pertama ialah Fine Tune, yang merupakan model domain menegak berdasarkan model yang besar. Ini mempunyai kos pelaburan komprehensif yang besar dan kekerapan kemas kini yang rendah, dan tidak sesuai untuk semua perusahaan aset pengetahuan perusahaan sendiri dalam pangkalan data vektor, dan membina perkhidmatan yang mendalam dalam bidang menegak melalui model besar + pangkalan data vektor Intinya ialah menggunakan pangkalan data untuk kejuruteraan segera. Perusahaan boleh menggunakan kategori menegak peruntukan undang-undang dan duluan untuk membina perkhidmatan teknologi undang-undang dalam bidang tertentu seperti industri perundangan. Contohnya, Harvey, sebuah syarikat teknologi undang-undang, sedang membina "Copilot for Lawyer" untuk menambah baik perkhidmatan penggubalan dan penyelidikan undang-undang. Mengekstrak dokumen asas pengetahuan perusahaan dan maklumat masa nyata melalui ciri vektor dan kemudian menyimpannya dalam pangkalan data vektor, digabungkan dengan model bahasa besar LLM, boleh menjadikan Chatbot (robot soal jawab) menjawab lebih profesional dan tepat pada masanya, serta membina perusahaan- Chatbot tertentu.
Bagaimana untuk Berdasarkan model bahasa besarBiarkan Chatbot menjawab soalan hal ehwal semasa dengan lebih baik ? Selamat datang ke akaun video "Alibaba Cloud Yaochi Database" untuk menonton demo Demo.
Artikel berikut akan menumpukan pada model bahasa besar berasaskan pada ( LLM) + pangkalan data vektor untuk mencipta prinsip dan proses Chatbot khusus perusahaan, serta keupayaan teras ADB-PG untuk membina senario ini.
2. Apakah pangkalan data vektor?
Dalam dunia nyata, kebanyakan data adalah dalam bentuk tidak berstruktur, seperti imej, audio, video dan teks. Dengan kemunculan bandar pintar, video pendek, cadangan produk yang diperibadikan, carian produk visual dan aplikasi lain, data tidak berstruktur ini telah mengalami pertumbuhan yang pesat. Untuk dapat memproses data tidak berstruktur ini, kami biasanya menggunakan teknologi kecerdasan buatan untuk mengekstrak ciri data tidak berstruktur ini dan menukarnya kepada vektor ciri, dan kemudian menganalisis dan mendapatkan semula vektor ciri ini untuk mencapai tujuan menganalisis data tidak berstruktur. pemprosesan. Oleh itu, kami memanggil pangkalan data yang boleh menyimpan, menganalisis dan mendapatkan semula vektor ciri sebagai pangkalan data vektor.
Untuk mendapatkan semula vektor ciri dengan pantas, pangkalan data vektor biasanya menggunakan cara teknikal untuk membina indeks vektor yang biasa kita bincangkan adalah milik ANNS (Anggaran Carian Jiran Terdekat, Anggaran Carian Jiran Terdekat). yang Idea terasnya ialah ia tidak lagi terhad kepada hanya memulangkan item hasil yang paling tepat, tetapi hanya mencari item data yang mungkin jiran terdekat, iaitu, mengorbankan sedikit ketepatan dalam julat yang boleh diterima sebagai pertukaran untuk kecekapan perolehan yang lebih baik. Ini juga merupakan perbezaan terbesar antara pangkalan data vektor dan pangkalan data tradisional.
Pada masa ini dalam persekitaran pengeluaran sebenar, terdapat dua jenis dalam industri Cara praktikal utama untuk menggunakan pengindeksan vektor ANNS dengan lebih mudah. Satu adalah untuk menyediakan indeks vektor ANNS secara berasingan untuk menyediakan penciptaan indeks vektor dan keupayaan mendapatkan semula, dengan itu membentuk pangkalan data vektor proprietari yang lain adalah untuk menyepadukan indeks vektor ANNS ke dalam pangkalan data berstruktur tradisional untuk membentuk DBMS dengan keupayaan mendapatkan semula vektor. Dalam senario perniagaan sebenar, pangkalan data vektor proprietari selalunya perlu digunakan bersama-sama dengan pangkalan data tradisional lain, yang akan menyebabkan beberapa masalah biasa, seperti lebihan data, pemindahan data yang berlebihan, isu konsistensi data, dll. Berbanding dengan DBMS sebenar, proprietari pangkalan data vektor memerlukan penyelenggaraan profesional tambahan, kos tambahan dan keupayaan bahasa pertanyaan yang sangat terhad, kebolehprograman, kebolehskalaan dan penyepaduan alat.
DBMS yang menggabungkan fungsi pengambilan vektor adalah berbeza. Ia adalah pertama sekali platform pangkalan data moden yang sangat lengkap yang boleh memenuhi keperluan fungsi pangkalan data pembangun aplikasi kemudian keupayaan pengambilan vektor bersepadunya juga boleh melaksanakan fungsi pangkalan data vektor proprietari, dan membolehkan penyimpanan dan pengambilan vektor untuk mewarisi keupayaan Cemerlang DBMS; seperti kemudahan penggunaan (secara langsung menggunakan SQL untuk memproses vektor), urus niaga, ketersediaan tinggi, berskala tinggi, dsb.
ADB-PG yang diperkenalkan dalam artikel ini mempunyai pengambilan semula vektor DBMS berfungsi bukan sahaja termasuk fungsi mendapatkan semula vektor, tetapi juga mempunyai keupayaan pangkalan data sehenti. Sebelum memperkenalkan keupayaan khusus ADB-PG, mari kita lihat dahulu proses penciptaan dan prinsip berkaitan Chatbot dalam video Demo.
3. Model bahasa besar LLM + ADB-PG: membina Chatbot khusus perusahaan
Sistem soalan dan jawapan pengetahuan tempatan
Untuk contoh video Demo sebelumnya yang menggabungkan model bahasa besar LLM dan ADB-PG untuk mengulas berita hal ehwal semasa, biarkan LLM menjawab "Apakah itu Tongyi Qianwen?" Dapat dilihat sekiranya kita meminta LLM menjawab secara terus, jawapan yang diperolehi tidak bermakna kerana set data latihan LLM tidak mengandungi kandungan yang berkaitan. Dan apabila kami menggunakan pangkalan data vektor sebagai storan pengetahuan tempatan dan membiarkan LLM mengekstrak pengetahuan yang berkaitan secara automatik, ia menjawab dengan betul "Apakah Tongyi Qianwen?"
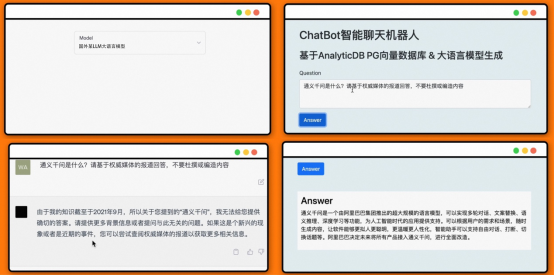
Jawab "Tong Yi Qian " Tanya apa" dokumen, PDF, e-mel, maklumat rangkaian dan kandungan lain. Contohnya:
- Buat pembantu perjalanan dengan menggabungkan maklumat penerbangan terkini dan lokasi daftar masuk selebriti internet terkini serta sumber panduan perjalanan yang lain. Sebagai contoh, jawab soalan tentang di mana tempat terbaik untuk melancong minggu depan dan cara menjadi yang paling menjimatkan.
- Ulasan acara sukan, ulasan berita hangat hal ehwal semasa dan ringkasan. Siapa MVP permainan NBA hari ini.
- Tafsiran topik hangat pendidikan terkini dalam industri pendidikan, contohnya, beritahu saya apa itu AIGC dan apakah itu Stable Diffusion dan cara menggunakannya dan banyak lagi.
- Dalam bidang kewangan, cepat analisis laporan kewangan dalam pelbagai industri dan cipta pembantu perunding kewangan.
- Robot perkhidmatan pelanggan dalam bidang profesional...
Prinsip Pelaksanaan
Sistem QA Tempatan terutamanya berdasarkan gabungan model bahasa besar Keupayaan Penaakulan dan storan pangkalan data vektor dan keupayaan mendapatkan semula. Dapatkan serpihan semantik yang paling relevan melalui pengambilan semula vektor, dan gunakan ini sebagai asas untuk model bahasa besar untuk menaakul bersama konteks serpihan yang berkaitan untuk membuat kesimpulan yang betul. Terdapat dua proses utama dalam proses ini:
a 🎜>
b. Proses Soal Jawab Bahagian DepanDi pada masa yang sama, lapisan bawahnya adalah terutamanya Bergantung pada dua modul:
Modul inferens berdasarkan model bahasa besar
2. Modul pengurusan data vektor berdasarkan pangkalan data vektor
L
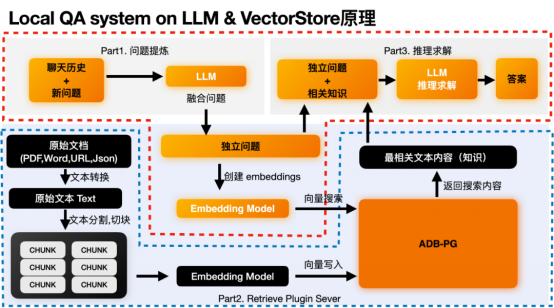
sistem QA okal pada prinsip LLM & VectorStore Proses pemprosesan dan penyimpanan data belakang
Bahagian hitam dalam gambar di atas ialah proses pemprosesan data bahagian belakang, yang terutamanya menyelesaikan pembenaman data asal kami dan menggabungkannya dengan asal Data disimpan bersama dalam pangkalan data vektor ADB-PG. Di sini anda hanya perlu memberi perhatian kepada bahagian kotak bertitik biru pada gambar di atas. Modul pemprosesan hitam dan pangkalan data vektor ADB-PG.
- Langkah1: Mula-mula ekstrak semua kandungan teks dalam dokumen asal. Kemudian ia dipotong menjadi beberapa ketulan mengikut semantik, yang boleh difahami sebagai perenggan teks yang dapat menyatakan makna sepenuhnya. Dalam proses ini, anda juga boleh melakukan beberapa tindakan tambahan seperti pengekstrakan metadata dan pengesanan maklumat sensitif.
- Langkah2: Lemparkan Ketulan ini ke model pembenaman untuk mencari pembenaman ketulan ini.
- Langkah3: Simpan benam dan bongkah asal bersama-sama dalam pangkalan data vektor.
Proses Soal Jawab Hadapan
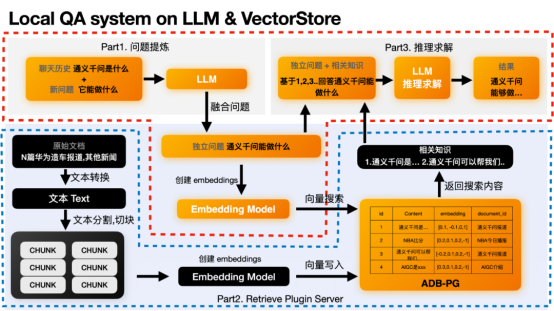
Proses ini terbahagi kepada tiga Bahagian: 1. Bahagian penapisan masalah; Di sini kita perlu fokus pada bahagian oren. Mungkin agak kabur untuk bercakap tentang prinsip, tetapi kami akan menggunakan contoh di atas untuk menggambarkan.
Lsistem QA okal dihidupkan LLM & VectorStore
Bahagian1 Penapisan Masalah
Bahagian ini adalah pilihan dan wujud kerana sesetengah soalan bergantung kepada konteks. Kerana soalan baharu yang ditanya oleh pengguna mungkin tidak membenarkan LLM memahami niat pengguna.
Sebagai contoh, soalan baharu pengguna ialah “Apa yang boleh ia lakukan?” ". LLM tidak tahu siapa yang dirujuk dan perlu menggabungkan sejarah sembang sebelumnya, seperti "Apakah Tongyi Qianwen" untuk menyimpulkan soalan bebas yang pengguna perlu jawab "Apakah yang boleh Tongyi Qianwen lakukan?" LLM tidak dapat menjawab dengan betul soalan samar "Apakah kegunaannya", tetapi ia boleh menjawab soalan bebas "Apakah kegunaan Tongyi Qianwen" dengan betul. Jika masalah anda serba lengkap, anda tidak memerlukan bahagian ini.
Selepas mendapat soalan bebas, kita boleh berdasarkan ini soalan bebas , untuk mencari pembenaman masalah bebas ini. Kemudian cari pangkalan data vektor untuk vektor yang paling serupa untuk mencari kandungan yang paling berkaitan. Tingkah laku ini adalah dalam kefungsian Part2 Retrieval Plugin.
Part2 Vector Retrieval
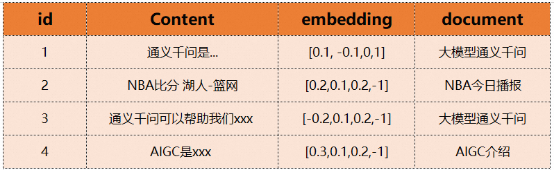
Fungsi pembenaman masalah bebas akan dilaksanakan dalam model text2vec. Selepas mendapatkan pembenaman, anda boleh menggunakan pembenaman ini untuk mencari data yang telah disimpan dalam pangkalan data vektor terlebih dahulu. Sebagai contoh, kami telah menyimpan kandungan berikut dalam ADB-PG. Kita boleh memperoleh kandungan atau pengetahuan yang paling serupa melalui vektor yang diperoleh, seperti item pertama dan ketiga. Tongyi Qianwen ialah..., Tongyi Qianwen boleh membantu kami xxx.
Penyelesaian Inferens Bahagian3
Setelah memperoleh pengetahuan yang paling relevan, kami boleh membiarkan LLM melakukan penaakulan berdasarkan pengetahuan yang paling relevan dan soalan bebas untuk mendapatkan jawapan muktamad. Berikut adalah jawapan kepada soalan "Apakah kegunaan Tongyi Qianwen" dengan menggabungkan maklumat yang paling berkesan seperti "Tongyi Qianwen ialah...", "Tongyi Qianwen boleh membantu kami xxx" dan sebagainya. Pada akhirnya, penyelesaian inferens GPT adalah kira-kira seperti berikut:

4 ADB-PG: pangkalan data pengetahuan perusahaan sehenti dengan carian vektor terbina dalam + carian teks penuh
Mengapa ADB-PG sesuai sebagai pangkalan data pengetahuan untuk Chatbot? ADB-PG ialah gudang data asli awan dengan keupayaan pemprosesan selari berskala besar. Ia menyokong mod storan baris dan lajur, yang bukan sahaja dapat menyediakan pemprosesan data luar talian berprestasi tinggi, tetapi juga menyokong analisis dalam talian serentak tinggi dan pertanyaan data besar-besaran. Oleh itu, kita boleh mengatakan bahawa ADB-PG ialah platform gudang data yang menyokong transaksi teragih dan beban bercampur, dan juga menyokong pemprosesan pelbagai sumber data tidak berstruktur dan separa berstruktur. Sebagai contoh, pemalam dapatkan semula vektor membolehkan perolehan semula vektor berprestasi tinggi dan analisis data tidak berstruktur seperti imej, bahasa, video dan teks, dan perolehan semula teks penuh dan analisis data separa berstruktur seperti JSON.
Oleh itu, dalam senario AIGC, ADB-PG boleh sama ada Sebagai pangkalan data vektor, ia memenuhi keperluannya untuk penyimpanan dan pengambilan vektor, dan juga boleh memenuhi penyimpanan dan pertanyaan data berstruktur lain Ia juga boleh menyediakan keupayaan mendapatkan semula teks penuh, menyediakan penyelesaian sehenti untuk aplikasi perniagaan dalam AIGC. senario. Di bawah ini kami akan memperkenalkan secara terperinci tiga keupayaan ADB-PG: pengambilan vektor, pengambilan gabungan dan pengambilan teks penuh.
Fungsi pengambilan vektor ADB-PG dan pengambilan gabungan pada tahun 2020 Ia pertama kali dilancarkan pada awan awam pada 2018 dan telah digunakan secara meluas dalam bidang pengecaman muka. Pangkalan data vektor ADB-PG diwarisi daripada platform gudang data, jadi ia mempunyai hampir semua faedah DBMS, seperti ANSISQL, transaksi ACID, ketersediaan tinggi, pemulihan kerosakan, pemulihan titik dalam masa, kebolehprograman, kebolehskalaan, dsb. Pada masa yang sama, ia menyokong carian persamaan vektor dan vektor bagi jarak produk titik, jarak Hamming dan jarak Euclidean. Fungsi ini kini digunakan secara meluas dalam pengecaman muka, pengecaman produk dan carian semantik berasaskan teks. Dengan AIGC yang meletup, ciri ini menyediakan asas yang kukuh untuk chatbot berasaskan teks. Selain itu, enjin pengambilan vektor ADB-PG juga menggunakan arahan Intel SIMD untuk mencapai padanan persamaan vektor dengan sangat cekap.
Di bawah ini kami menggunakan contoh khusus untuk menggambarkan ADB- Bagaimana untuk menggunakan perolehan semula vektor dan pengambilan gabungan PG. Katakan terdapat pangkalan pengetahuan teks, yang membahagikan sekumpulan artikel kepada ketulan dan menukarnya ke dalam vektor benam sebelum memasuki pangkalan data Jadual ketulan mengandungi medan berikut: 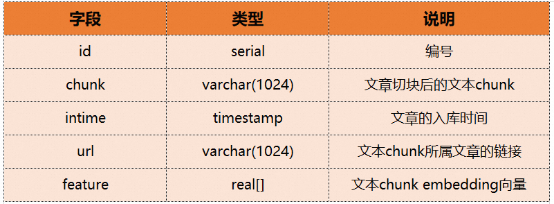
Kemudian DDL penciptaan jadual yang sepadan adalah seperti berikut: 

Pada masa yang sama, untuk mempercepatkan pertanyaan gabungan berstruktur vektor, kami juga perlu membuat indeks untuk lajur berstruktur yang biasa digunakan:

Apabila memasukkan data, kita boleh terus menggunakan sintaks sisipan dalam SQL:

Dalam ini contoh, jika kita ingin mencari artikel sumbernya melalui teks, maka kita boleh mencari terus melalui carian vektor SQL khusus adalah seperti berikut:
.
Begitu juga, jika keperluan kita adalah mencari bulan terkini Sumber artikel teks tertentu dalam. Kemudian kita boleh mencari terus melalui carian gabungan SQL khusus adalah seperti berikut:

<. . mudah seperti menggunakan pangkalan data tradisional tanpa sebarang ambang pembelajaran. pada masa yang sama kami juga telah membuat banyak pengoptimuman disasarkan untuk mendapatkan semula vektor pemampatan pembinaan selari indeks perolehan berbilang partisi dll. tidak akan diperincikan di sini.>
ADB-PG juga mempunyai keupayaan carian teks penuh yang kaya , menyokong keupayaan mendapatkan semula seperti keadaan gabungan yang kompleks dan kedudukan hasil sebagai tambahan, untuk set data bahasa Cina, ADB-PG juga menyokong fungsi pembahagian perkataan Cina, yang boleh memproses dan membahagikan teks bahasa Cina dengan cekap dan disesuaikan pada masa yang sama, ADB-; PG juga menyokong penggunaan indeks untuk mempercepatkan perolehan teks penuh. Keupayaan ini juga boleh digunakan sepenuhnya dalam senario perniagaan AIGC Contohnya, perniagaan boleh melakukan penarikan balik dua hala dokumen asas pengetahuan digabungkan dengan keupayaan mendapatkan semula vektor dan teks penuh yang disebutkan di atas.
Bahagian carian pangkalan data pengetahuan termasuk teks penuh kata kunci tradisional carian Dan perolehan ciri vektor, perolehan teks penuh kata kunci memastikan ketepatan pencarian ciri vektor menyediakan generalisasi dan pemadanan semantik, ia mengimbas kembali pengetahuan tentang pemadanan semantik, mengurangkan kadar tiada hasil, dan menyediakan. maklumat yang lebih kaya untuk model besar Konteks adalah kondusif untuk ringkasan dan induksi model bahasa yang besar.
5 RingkasanDigabungkan dengan kandungan yang dinyatakan sebelum ini dalam artikel ini, jika kita membandingkan Chatbot yang berpengetahuan.
ialah
orang kelas , Model bahasa besar boleh dilihat sebagai pengetahuan dan kebolehan penaakulan pembelajaran yang Chatbot peroleh daripada semua buku dan bahan awam dalam pelbagai bidang sebelum menamatkan pengajian di kolej. Oleh itu, berdasarkan model bahasa besar, Chatbot boleh menjawab soalan yang berkaitan dengan pengijazahannya Walau bagaimanapun, jika soalan itu melibatkan bidang profesional tertentu (maklumat yang berkaitan adalah hak milik kepada organisasi perusahaan dan bukan umum) atau konsep spesies baharu (ia. masih belum dikeluarkan apabila tamat pengajian di universiti) Kelahiran), adalah mustahil untuk menanganinya dengan tenang hanya dengan bergantung kepada pengetahuan yang diperoleh di sekolah (bersesuaian dengan model bahasa besar yang telah dilatih sebelumnya Anda perlu mempunyai saluran untuk terus memperoleh). pengetahuan baharu selepas tamat pengajian (seperti pangkalan data pembelajaran profesional berkaitan kerja), digabungkan dengan kebolehan pembelajaran dan penaakulan anda sendiri, untuk membuat respons profesional.
Chatbot yang sama perlu menggabungkan keupayaan pembelajaran dan penaakulan model bahasa besar dengan pangkalan data sehenti seperti ADB-PG yang mengandungi keupayaan mendapatkan semula vektor dan mendapatkan semula teks penuh (yang menyimpan proprietari dan maklumat terkini organisasi perusahaan). dokumen pengetahuan dan ciri vektor), dan boleh memberikan jawapan yang lebih profesional dan tepat pada masanya berdasarkan kandungan pengetahuan dalam pangkalan data apabila menjawab soalan.
Atas ialah kandungan terperinci Alibaba Cloud AnalyticDB (ADB) + LLM: Membina Chatbot khusus perusahaan dalam era AIGC. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI