
Rumah >Peranti teknologi >AI >RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap
RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-18 17:27:17663semak imbas
Memandangkan model bahasa berskala ke skala yang belum pernah berlaku sebelum ini, penalaan menyeluruh tugas hiliran menjadi mahal. Bagi menyelesaikan masalah ini, penyelidik mula memberi perhatian dan mengamalkan kaedah PEFT. Idea utama kaedah PEFT adalah untuk mengehadkan skop penalaan halus kepada set kecil parameter untuk mengurangkan kos pengiraan sambil masih mencapai prestasi terkini dalam tugas pemahaman bahasa semula jadi. Dengan cara ini, penyelidik boleh menjimatkan sumber pengkomputeran sambil mengekalkan prestasi tinggi, membawa tempat tumpuan penyelidikan baharu ke bidang pemprosesan bahasa semula jadi.
ROSA adalah teknik PEFT baru. -kaedah penalaan.
Artikel ini akan menyelidiki prinsip, kaedah dan keputusan RoSA, menerangkan cara prestasinya menandakan kemajuan yang bermakna. Bagi mereka yang ingin memperhalusi model bahasa besar dengan berkesan, RoSA menyediakan penyelesaian baharu yang lebih baik daripada penyelesaian sebelumnya.
Keperluan untuk penalaan halus yang cekap bagi parameter
NLP telah direvolusikan oleh model bahasa berasaskan pengubah seperti GPT-4. Model ini mempelajari perwakilan bahasa yang berkuasa dengan pra-latihan mengenai korpora teks besar. Mereka kemudiannya memindahkan perwakilan ini kepada tugas bahasa hiliran melalui proses yang mudah.
Apabila saiz model berkembang daripada berbilion kepada bertrilion parameter, penalaan halus membawa beban pengiraan yang besar. Sebagai contoh, untuk model seperti GPT-4 dengan 1.76 trilion parameter, penalaan halus boleh menelan belanja berjuta-juta dolar. Ini menjadikan penggunaan dalam aplikasi sebenar sangat tidak praktikal.
Kaedah PEFT meningkatkan kecekapan dan ketepatan dengan mengehadkan julat parameter penalaan halus. Baru-baru ini, pelbagai teknologi PEFT telah muncul yang menukar kecekapan dan ketepatan.
LoRA
Kaedah PEFT yang terkenal ialah penyesuaian peringkat rendah (LoRA). LoRA telah dilancarkan pada 2021 oleh penyelidik dari Meta dan MIT. Pendekatan ini didorong oleh pemerhatian mereka bahawa pengubah mempamerkan struktur peringkat rendah dalam matriks kepalanya. LoRA dicadangkan untuk memanfaatkan struktur peringkat rendah ini untuk mengurangkan kerumitan pengiraan dan meningkatkan kecekapan dan kelajuan model.
LoRA hanya memperhalusi vektor k tunggal pertama, manakala parameter lain kekal tidak berubah. Ini hanya memerlukan O(k) parameter tambahan untuk ditala, bukannya O(n).
Dengan memanfaatkan struktur peringkat rendah ini, LoRA boleh menangkap isyarat bermakna yang diperlukan untuk generalisasi tugas hiliran dan mengehadkan penalaan halus kepada vektor tunggal teratas ini, menjadikan pengoptimuman dan inferens lebih cekap.
Percubaan menunjukkan bahawa LoRA boleh memadankan prestasi diperhalusi sepenuhnya pada penanda aras GLUE sambil menggunakan lebih daripada 100 kali lebih sedikit parameter. Walau bagaimanapun, apabila saiz model terus berkembang, mendapatkan prestasi yang kukuh melalui LoRA memerlukan peningkatan pangkat k, mengurangkan penjimatan pengiraan berbanding dengan penalaan halus sepenuhnya.
Sebelum RoSA, LoRA mewakili kaedah PEFT yang terkini, dengan hanya penambahbaikan sederhana menggunakan teknik seperti pemfaktoran matriks yang berbeza atau menambah sebilangan kecil parameter penalaan halus tambahan.
Penyesuaian Teguh (RoSA)
Penyesuaian Teguh (RoSA) memperkenalkan kaedah penalaan halus yang cekap parameter baharu. RoSA diilhamkan oleh analisis komponen utama yang teguh (PCA teguh), dan bukannya bergantung semata-mata pada struktur peringkat rendah.
Dalam analisis komponen utama tradisional, matriks data PCA yang teguh melangkah lebih jauh dan menguraikan X menjadi L peringkat rendah yang bersih dan S jarang "tercemar/korup".
RoSA mengambil inspirasi daripada ini dan menguraikan penalaan halus model bahasa menjadi:
Matriks penyesuaian (L) peringkat rendah seperti LoRA, diperhalusi untuk menghampiri isyarat berkaitan tugas yang dominan
Ketinggian Matriks penalaan halus (S) yang jarang mengandungi sebilangan kecil parameter yang ditala halus secara terpilih yang mengekodkan isyarat sisa yang terlepas oleh L.
Memodelkan komponen jarang sisa secara eksplisit membolehkan RoSA mencapai ketepatan yang lebih tinggi daripada LoRA sahaja.
RoSA membina L dengan melakukan penguraian peringkat rendah matriks kepala model. Ini akan mengekodkan perwakilan semantik asas yang berguna untuk tugas hiliran. RoSA kemudiannya memperhalusi secara selektif m parameter paling penting atas setiap lapisan kepada S, manakala semua parameter lain kekal tidak berubah. Langkah ini menangkap isyarat sisa yang tidak sesuai untuk pemasangan peringkat rendah.
Bilangan parameter penalaan halus m ialah susunan magnitud yang lebih kecil daripada pangkat k yang diperlukan oleh LoRA sahaja. Oleh itu, digabungkan dengan matriks kepala peringkat rendah dalam L, RoSA mengekalkan kecekapan parameter yang sangat tinggi.
RoSA juga menggunakan beberapa pengoptimuman lain yang mudah tetapi berkesan:
Sisa sambungan jarang: Sisa S ditambah terus ke output setiap blok pengubah sebelum ia melalui penormalan lapisan dan sublapisan suapan. Ini boleh mensimulasikan isyarat yang terlepas oleh L.
Topeng jarang bebas: Metrik yang dipilih dalam S untuk penalaan halus dijana secara bebas untuk setiap lapisan pengubah.
Struktur peringkat rendah yang dikongsi: Matriks U,V asas peringkat rendah yang sama dikongsi antara semua lapisan L, sama seperti dalam LoRA. Ini akan menangkap konsep semantik dalam subruang yang konsisten.
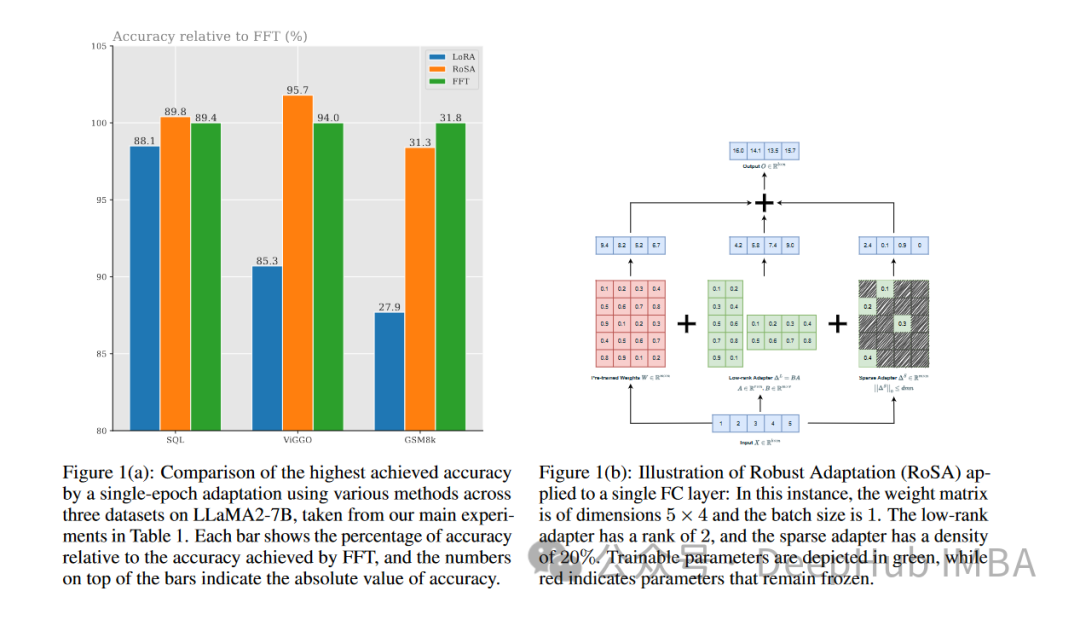
Pilihan seni bina ini menyediakan pemodelan RoSA dengan fleksibiliti serupa dengan penalaan halus penuh, sambil mengekalkan kecekapan parameter untuk pengoptimuman dan inferens. Menggunakan kaedah PEFT ini yang menggabungkan penyesuaian peringkat rendah yang teguh dan sisa yang sangat jarang, RoSA mencapai teknologi baharu bagi pertukaran kecekapan ketepatan. . Mereka menjalankan eksperimen menggunakan RoSA berdasarkan pembantu kecerdasan buatan LLM, menggunakan model parameter 12 bilion.
Pada setiap tugasan, RoSA menunjukkan prestasi yang lebih baik daripada LoRA apabila menggunakan parameter yang sama. Jumlah parameter kedua-dua kaedah adalah lebih kurang 0.3% daripada keseluruhan model. Ini bermakna terdapat kira-kira 4.5 juta parameter penalaan halus dalam kedua-dua kes untuk k = 16 untuk LoRA dan m = 5120 untuk RoSA.
RoSA juga sepadan atau melebihi prestasi garis dasar yang ditala halus tulen.
Pada penanda aras ANLI yang menilai keteguhan kepada contoh lawan, RoSA mendapat markah 55.6, manakala LoRA mendapat markah 52.7. Ini menunjukkan peningkatan dalam generalisasi dan penentukuran. 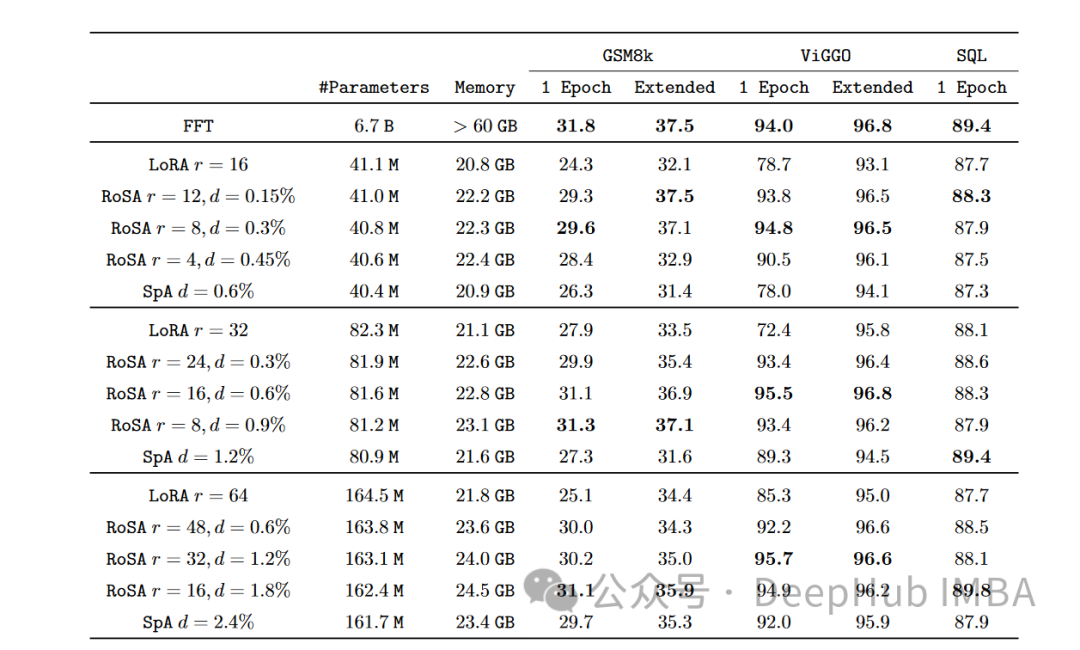
Untuk tugasan analisis sentimen SST-2 dan IMDB, ketepatan RoSA mencapai 91.2% dan 96.9%, manakala ketepatan LoRA mencapai 90.1% dan 95.3%.
Pada WIC, ujian nyahkekaburan deria perkataan yang mencabar, RoSA mencapai skor F1 93.5, manakala LoRA mencapai skor F1 91.7.
Di seluruh 12 set data, RoSA umumnya menunjukkan prestasi yang lebih baik daripada LoRA di bawah belanjawan parameter yang sepadan.
Terutamanya, RoSA mampu mencapai keuntungan ini tanpa memerlukan sebarang penalaan atau pengkhususan khusus. Ini menjadikan RoSA sesuai digunakan sebagai penyelesaian PEFT universal.
Ringkasan
Memandangkan skala model bahasa terus berkembang pesat, mengurangkan keperluan pengiraan untuk memperhalusinya merupakan masalah mendesak yang perlu diselesaikan. Teknik latihan penyesuaian yang cekap parameter seperti LoRA telah menunjukkan kejayaan awal tetapi menghadapi batasan yang wujud dalam anggaran peringkat rendah.
RoSA secara organik menggabungkan penguraian peringkat rendah yang teguh dan sisa penalaan halus yang sangat jarang untuk memberikan penyelesaian baharu yang meyakinkan. Ia sangat meningkatkan prestasi PEFT dengan mempertimbangkan isyarat yang terlepas daripada pemasangan peringkat rendah melalui sisa-sisa jarang terpilih. Penilaian empirikal menunjukkan peningkatan ketara ke atas LoRA dan garis dasar sparsity yang tidak terkawal pada set tugas NLU yang berbeza.
RoSA secara konsep mudah tetapi berprestasi tinggi, dan boleh memajukan lagi persimpangan kecekapan parameter, perwakilan penyesuaian dan pembelajaran berterusan untuk mengembangkan kecerdasan bahasa.
Atas ialah kandungan terperinci RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Parameter dipertingkatkan sedikit, dan indeks prestasi meletup! Google: Model bahasa besar menyembunyikan 'kemahiran misteri'
- Ketepatan GPT-3 dalam menyelesaikan masalah matematik telah meningkat kepada 92.5%! Microsoft mencadangkan MathPrompter untuk mencipta model bahasa 'sains' tanpa penalaan halus
- Satu lagi 'pemain kuat' telah ditambahkan ke medan AI, Meta mengeluarkan model bahasa berskala besar baru LLaMA
- Enam cara untuk membina chatbot AI dan model bahasa yang besar untuk meningkatkan keselamatan siber
- Syarikat domestik pertama, 360 Intelligent Brain lulus penilaian fungsi model bahasa besar AIGC yang dipercayai oleh Akademi Teknologi Maklumat dan Komunikasi China.