Ini adalah pengalaman yang diperoleh oleh pengarang Sebastian Raschka selepas beratus-ratus percubaan.
Meningkatkan jumlah data dan parameter model diiktiraf sebagai cara paling langsung untuk meningkatkan prestasi rangkaian saraf. Pada masa ini, bilangan parameter model besar arus perdana telah berkembang kepada ratusan bilion, dan trend "model besar" menjadi lebih besar dan lebih besar akan menjadi lebih dan lebih sengit. Arah aliran ini telah membawa banyak cabaran kuasa pengkomputeran. Jika anda ingin memperhalusi model bahasa yang besar dengan ratusan bilion parameter, ia bukan sahaja mengambil masa yang lama untuk dilatih, tetapi juga memerlukan banyak sumber memori berprestasi tinggi. Untuk "menurunkan" kos penalaan halus model besar, penyelidik Microsoft membangunkan teknologi adaptif peringkat rendah (LoRA). Kehalusan LoRA ialah ia setara dengan menambah pemalam boleh tanggal pada model besar asal, dan badan utama model itu kekal tidak berubah. LoRA adalah plug-and-play, ringan dan mudah. Untuk memperhalusi versi tersuai model bahasa besar dengan cekap, LoRA ialah salah satu kaedah yang paling banyak digunakan, dan ia juga merupakan salah satu kaedah yang paling berkesan. Jika anda berminat dengan LLM sumber terbuka, LoRA adalah teknologi asas yang patut dipelajari dan tidak boleh dilepaskan. Sebastian Raschka, seorang profesor sains data di Universiti Wisconsin-Madison, turut menjalankan penerokaan komprehensif LoRA. Setelah meneroka bidang pembelajaran mesin selama bertahun-tahun, beliau sangat bersemangat untuk memecahkan konsep teknikal yang kompleks. Selepas beratus-ratus percubaan, Sebastian Raschka meringkaskan pengalamannya menggunakan LoRA untuk memperhalusi model besar dan menerbitkannya dalam majalah Ahead of AI. 
Atas dasar mengekalkan niat asal pengarang, laman web ini telah menyusun artikel ini: Bulan lepas, saya berkongsi artikel tentang eksperimen LoRA, yang kebanyakannya berdasarkan artikel yang diselenggarakan oleh rakan sekerja saya dan saya di Lightning Pustaka Lit-GPT sumber terbuka AI, membincangkan pengalaman utama dan pengajaran yang dipelajari daripada eksperimen saya. Selain itu, saya akan menjawab beberapa soalan lazim berkaitan teknologi LoRA. Jika anda berminat untuk memperhalusi model bahasa besar tersuai, saya harap cerapan ini akan membantu anda bermula dengan cepat. Ringkasnya, perkara utama yang saya bincangkan dalam artikel ini termasuk:
- Walaupun latihan LLM (atau semua model yang dilatih pada GPU) mempunyai rawak yang tidak dapat dielakkan, tetapi hasil latihan multi-lun masih sangat konsisten.
- Jika anda dihadkan oleh memori GPU, QLoRA menyediakan kompromi yang menjimatkan kos. Ia menjimatkan 33% memori dengan kos peningkatan 39% dalam masa jalan.
- Apabila memperhalusi LLM, pilihan pengoptimum bukanlah faktor utama yang mempengaruhi keputusan. Sama ada AdamW, SGD dengan penjadual, atau AdamW dengan penjadual, kesan pada keputusan adalah minimum.
- Walaupun Adam sering dianggap sebagai pengoptimum intensif memori kerana ia memperkenalkan dua parameter baharu untuk setiap parameter model, ini tidak menjejaskan keperluan memori puncak LLM dengan ketara. Ini kerana kebanyakan memori akan diperuntukkan untuk pendaraban matriks besar dan bukannya memegang parameter tambahan.
- Untuk set data statik, berbilang lelaran seperti berbilang pusingan latihan mungkin tidak berfungsi dengan baik. Ini selalunya membawa kepada terlalu kemas, memburukkan keputusan latihan.
- Jika anda ingin menggabungkan LoRA, pastikan ia digunakan pada semua lapisan, bukan hanya matriks Kunci dan Nilai, supaya dapat memaksimumkan prestasi model.
- Adalah penting untuk melaraskan kedudukan LoRA dan memilih nilai α yang sesuai. Sebagai petua, cuba tetapkan nilai α kepada dua kali ganda nilai kedudukan.
- Satu GPU dengan 14GB RAM boleh memperhalusi model besar dengan cekap dengan 7 bilion parameter dalam beberapa jam. Untuk set data statik, adalah mustahil untuk mengukuhkan LLM menjadi "semuanya" dan berfungsi dengan baik dalam semua tugasan asas. Menyelesaikan masalah ini memerlukan mempelbagaikan sumber data atau menggunakan teknologi selain LoRA.
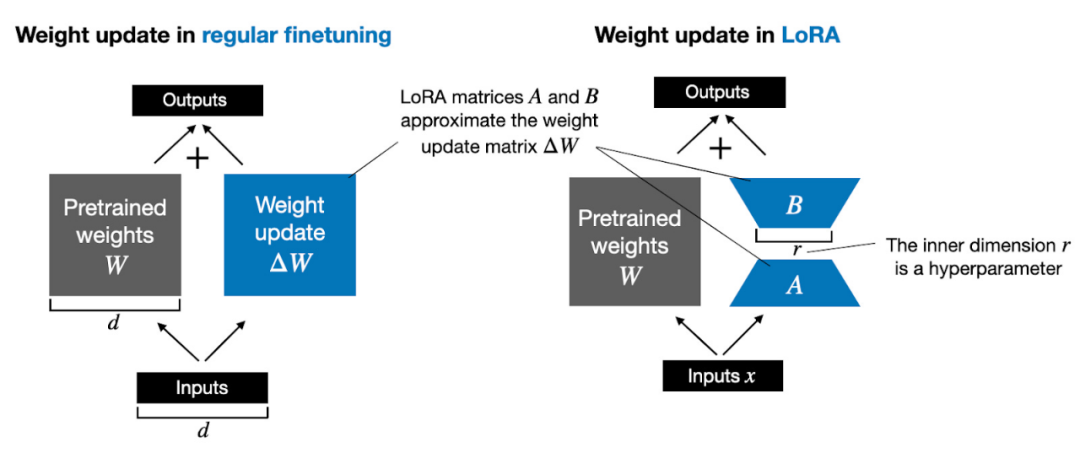
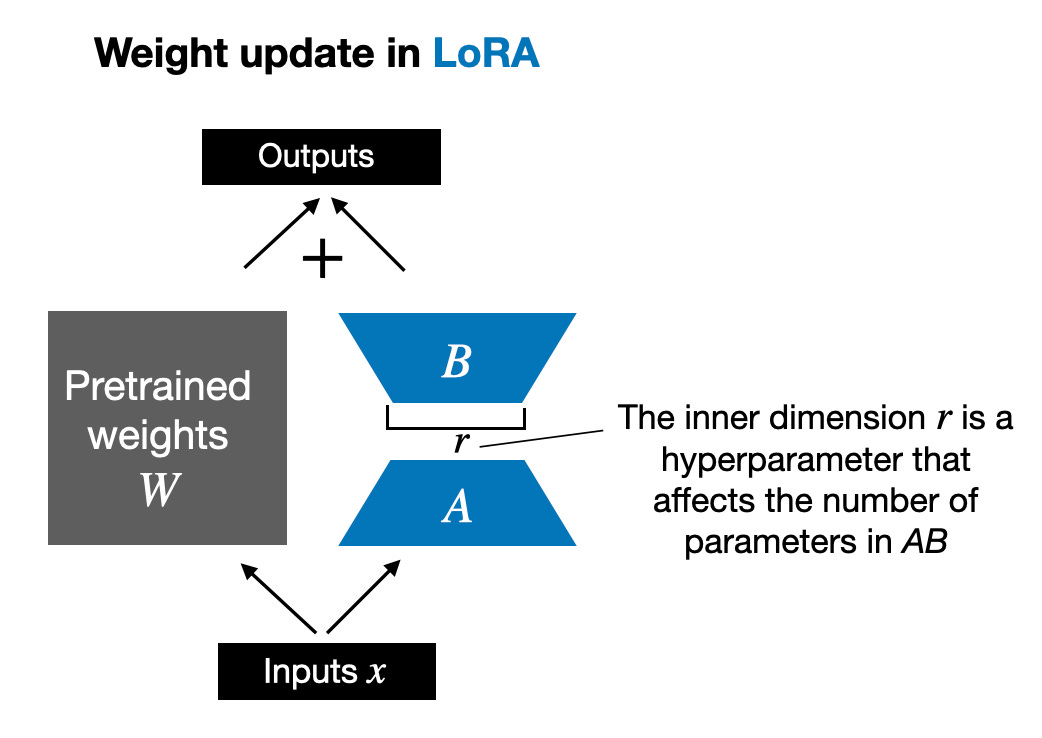
Selain itu, saya akan menjawab sepuluh soalan lazim tentang LoRA. Jika pembaca berminat, saya akan menulis satu lagi pengenalan yang lebih komprehensif tentang LoRA, termasuk kod terperinci untuk melaksanakan LoRA dari awal. Artikel hari ini terutamanya berkongsi isu utama dalam penggunaan LoRA. Sebelum kita bermula secara rasmi, mari kita tambahkan beberapa pengetahuan asas. Mengemas kini berat model semasa latihan adalah mahal kerana had memori GPU. Sebagai contoh, katakan kita mempunyai model bahasa parameter 7B, diwakili oleh matriks berat W. Semasa perambatan balik, model perlu mempelajari matriks ΔW, bertujuan untuk mengemas kini pemberat asal untuk meminimumkan nilai fungsi kehilangan. Berat dikemas kini seperti berikut: W_updated = W + ΔW. Jika matriks berat W mengandungi parameter 7B, maka matriks kemas kini berat ΔW juga mengandungi parameter 7B Mengira matriks ΔW adalah sangat pengiraan dan memakan memori. LoRA yang dicadangkan oleh Edward Hu et al menguraikan bahagian perubahan berat ΔW menjadi perwakilan peringkat rendah. Secara khusus, ia tidak memerlukan pengiraan eksplisit ΔW. Sebaliknya, LoRA mempelajari perwakilan terurai ΔW semasa latihan, seperti yang ditunjukkan dalam rajah di bawah Ini adalah rahsia LoRA menjimatkan sumber pengiraan.
Seperti yang ditunjukkan di atas, penguraian ΔW bermakna kita perlu menggunakan dua matriks LoRA A dan B yang lebih kecil untuk mewakili matriks ΔW yang lebih besar. Jika A mempunyai bilangan baris yang sama dengan ΔW dan B mempunyai bilangan lajur yang sama dengan ΔW, kita boleh menulis penguraian di atas sebagai ΔW = AB. (AB ialah hasil pendaraban matriks antara matriks A dan B.) Berapa banyak memori yang disimpan oleh pendekatan ini? Ia juga bergantung pada pangkat r, iaitu hiperparameter. Sebagai contoh, jika ΔW mempunyai 10,000 baris dan 20,000 lajur, 200,000,000 parameter perlu disimpan. Jika kita memilih A dan B dengan r=8, maka A mempunyai 10,000 baris dan 8 lajur, dan B mempunyai 8 baris dan 20,000 lajur, iaitu 10,000×8 + 8×20,000 = 240,000 parameter, iaitu kira-kira 830 kali kurang daripada 200,000. parameter. Sudah tentu, A dan B tidak dapat menangkap semua maklumat yang diliputi oleh ΔW, tetapi ini ditentukan oleh reka bentuk LoRA. Apabila menggunakan LoRA, kami menganggap bahawa model W ialah matriks besar dengan kedudukan penuh untuk mengumpul semua pengetahuan dalam set data pra-latihan. Apabila kami memperhalusi LLM, kami tidak perlu mengemas kini semua pemberat, kami hanya perlu mengemas kini kurang pemberat daripada ΔW untuk menangkap maklumat teras Beginilah cara kemas kini peringkat rendah dilaksanakan melalui matriks AB. Walaupun kerawak LLM, atau model yang dilatih pada GPU, tidak dapat dielakkan, LoRA telah digunakan untuk menjalankan berbilang eksperimen, dan keputusan penanda aras terakhir telah diuji dalam LLM. ujian yang berbeza Kepekatan menunjukkan konsistensi yang menakjubkan. Ini adalah asas yang baik untuk menjalankan kajian perbandingan yang lain.
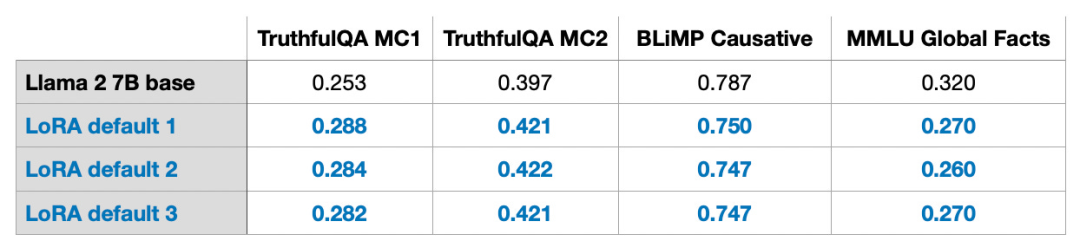
Sila ambil perhatian bahawa keputusan ini diperoleh di bawah tetapan lalai, menggunakan nilai kecil r=8. Butiran eksperimen boleh didapati dalam artikel saya yang lain. Pautan artikel: https://lightning.ai/pages/community/lora-insights/QLoRA Computation - Memory Tradeoff dicadangkan oleh Timer. Singkatan untuk LoRA kuantitatif. QLoRA ialah teknik untuk mengurangkan lagi jejak memori semasa penalaan halus. Semasa perambatan belakang, QLoRA mengkuantiskan pemberat yang telah dilatih menjadi 4-bit dan menggunakan pengoptimum halaman untuk mengendalikan puncak memori.
Saya mendapati bahawa saya boleh menjimatkan 33% memori GPU apabila menggunakan LoRA. Walau bagaimanapun, masa latihan meningkat sebanyak 39% disebabkan oleh pengkuantitian tambahan dan penyahkuansian berat model pralatihan dalam QLoRA.
LoRA lalai mempunyai ketepatan titik terapung 16 bit:
3
-
QLoRA dengan 4 digit titik terapung biasa nombor
Masa latihan ialah: 2.79j
Penggunaan memori ialah: 14.18GB
yang menunjukkan prestasi, model yang hampir tidak tercemar bahawa QLoRA boleh dilatih sebagai penyelesaian Alternatif LoRA yang melangkah lebih jauh untuk menyelesaikan kesesakan memori GPU biasa.
Penjadual kadar pembelajaran
Penjadual kadar pembelajaran akan mengurangkan kadar pembelajaran sepanjang proses latihan untuk mengoptimumkan penumpuan model dan mengelakkan nilai kerugian yang berlebihan.
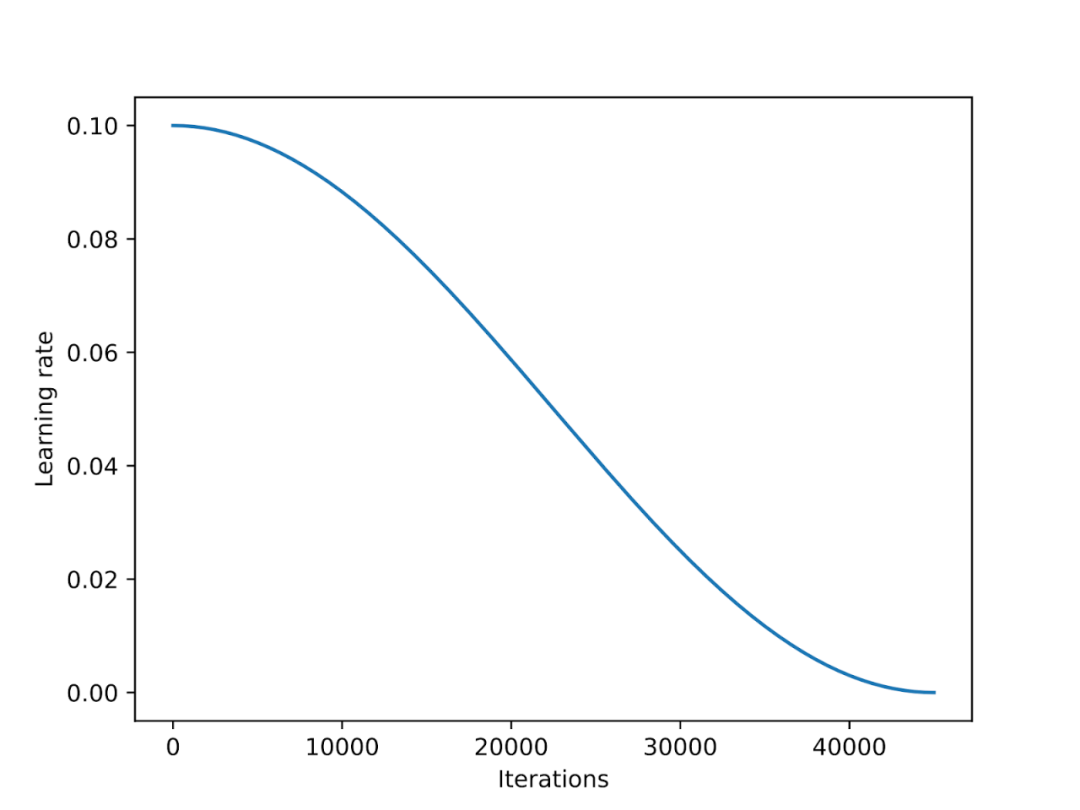
🎜🎜Penyepuhlindapan kosinus ialah penjadual yang mengikut keluk kosinus untuk melaraskan kadar pembelajaran. Ia bermula dengan kadar pembelajaran yang lebih tinggi dan kemudian menurun dengan lancar, secara beransur-ansur menghampiri 0 dalam corak seperti kosinus. Varian biasa penyepuhlindapan kosinus ialah varian separuh tempoh, di mana hanya separuh kitaran kosinus diselesaikan semasa latihan, seperti yang ditunjukkan dalam rajah di bawah. 🎜🎜🎜🎜🎜Dalam percubaan, saya menambahkan penjadual penyepuhlindapan kosinus pada skrip penalaan halus LoRA, yang meningkatkan prestasi SGD dengan ketara. Walau bagaimanapun, faedahnya kepada pengoptimum Adam dan AdamW adalah kecil, dan hampir tiada perubahan selepas menambahkannya. 🎜🎜🎜🎜
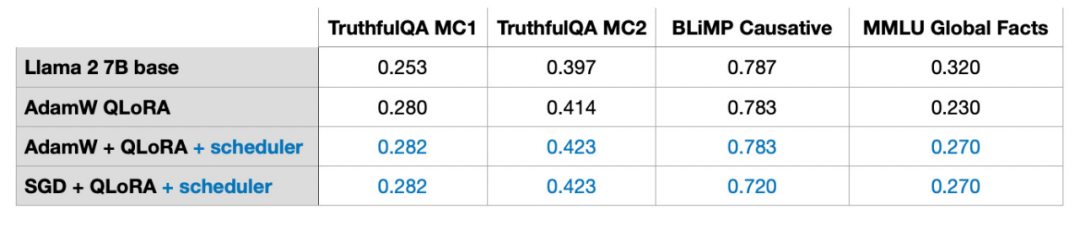
Dalam bahagian seterusnya, potensi kelebihan SGD berbanding Adam akan dibincangkan. Pengoptimum Adam dan AdamW popular dalam pembelajaran mendalam. Jika kita melatih model parameter 7B, menggunakan Adam boleh menjejaki parameter 14B tambahan semasa proses latihan, yang bersamaan dengan menggandakan bilangan parameter model apabila keadaan lain kekal tidak berubah. SGD tidak dapat mengesan parameter tambahan semasa latihan, jadi apakah kelebihan SGD dari segi memori puncak berbanding Adam? Dalam percubaan saya, melatih model Llama 2 parameter 7B menggunakan AdamW dan LoRA (tetapan lalai r=8) memerlukan 14.18 GB memori GPU. Melatih model yang sama dengan SGD memerlukan 14.15 GB memori GPU. Berbanding dengan AdamW, SGD hanya menjimatkan 0.03 GB memori, yang mempunyai kesan yang boleh diabaikan. Mengapa hanya menyimpan begitu banyak memori? Ini kerana LoRA telah banyak mengurangkan bilangan parameter dalam model apabila menggunakan LoRA. Contohnya, jika r=8, daripada kesemua 6,738,415,616 parameter model Llama 2 pada 7B, terdapat hanya 4,194,304 parameter LoRA yang boleh dilatih. Tengok nombor saja, 4,194,304 parameter mungkin masih banyak, tetapi sebenarnya parameter yang banyak ini hanya menduduki 4,194,304 × 2 × 16 bit = 134.22 megabit = 16.78 megabait (Kami melihat perbezaan 0.03 Gb = 30 Mb disebabkan oleh overhed tambahan dalam menyimpan dan menyalin keadaan pengoptimum.) 2 mewakili bilangan parameter tambahan yang disimpan oleh Adam, manakala 16 bit merujuk kepada berat model Ketepatan lalai.
Jika kita mengembangkan r matriks LoRA daripada 8 kepada 256, maka kelebihan SGD berbanding AdamW akan muncul:
- Menggunakan AdamW akan menduduki SGU
- 17.8 GB memori
17.8 GB akan Menduduki 14.46 GB
Oleh itu, apabila saiz matriks meningkat, memori yang disimpan oleh SGD akan memainkan peranan penting. Oleh kerana SGD tidak perlu menyimpan parameter pengoptimum tambahan, SGD boleh menjimatkan lebih banyak memori daripada pengoptimum lain seperti Adam apabila memproses model besar. Ini adalah kelebihan yang sangat penting untuk tugas latihan dengan ingatan terhad.
Latihan berulang
Dalam pembelajaran mendalam tradisional, kami sering mengulang set latihan beberapa kali, dan setiap lelaran dipanggil zaman. Sebagai contoh, apabila melatih rangkaian saraf konvolusi, anda biasanya menjalankannya selama beratus-ratus zaman. Jadi, adakah beberapa pusingan latihan berulang juga mempunyai kesan ke atas penalaan halus arahan?
Jawapannya tidak, apabila saya menggandakan bilangan lelaran pada set data penalaan halus arahan contoh Alpaca dengan data 50k, prestasi model menurun.
Jadi, saya membuat kesimpulan bahawa beberapa pusingan lelaran mungkin tidak kondusif untuk penalaan halus arahan. Saya memerhatikan tingkah laku yang sama dalam set penalaan halus arahan LIMA contoh 1k. Penurunan prestasi model mungkin disebabkan oleh pemasangan berlebihan, dan sebab khusus masih perlu diterokai lebih lanjut.
Menggunakan LoRA dalam lebih banyak lapisan
Jadual di bawah menunjukkan eksperimen di mana LoRA berfungsi hanya pada matriks terpilih (iaitu matriks Kunci dan Nilai dalam setiap Transformer). Selain itu, kami boleh mendayakan LoRA dalam matriks berat pertanyaan, lapisan unjuran, lapisan linear lain antara modul perhatian berbilang kepala dan lapisan output.
Jika kita menambah LoRA pada lapisan tambahan ini, bilangan parameter boleh dilatih meningkat lima kali ganda daripada 4,194,304 kepada 20,277,248 untuk model Llama 2 pada 7B. Menggunakan LoRA pada lebih banyak lapisan boleh meningkatkan prestasi model dengan ketara, tetapi juga memerlukan ruang memori yang lebih tinggi.
Selain itu, saya hanya meneroka dua tetapan ini: (1) LoRA dengan hanya pertanyaan dan matriks berat didayakan, (2) LoRA dengan semua lapisan didayakan, menggunakan LoRA dalam kombinasi dengan lebih banyak lapisan menghasilkan Kesan jenis yang layak kajian lanjut. Jika kita dapat mengetahui sama ada menggunakan LoRA dalam lapisan unjuran memberi manfaat kepada hasil latihan, maka kita boleh mengoptimumkan model dengan lebih baik dan meningkatkan prestasinya.
🎜🎜
Hiperparameter LoRA seimbang: R dan AlphaSeperti yang dinyatakan dalam kertas yang mencadangkan LoRA, LoRA memperkenalkan faktor penskalaan tambahan. Pekali ini digunakan untuk menggunakan pemberat LoRA dalam pra-latihan semasa perambatan ke hadapan. Sambungan itu melibatkan parameter pangkat r yang dibincangkan sebelum ini, serta satu lagi hiperparameter α (alfa), yang digunakan seperti berikut:
Seperti yang ditunjukkan oleh formula dalam rajah di atas, semakin besar nilai berat LoRA, lebih besar impaknya. Dalam percubaan sebelumnya, parameter yang saya gunakan ialah r=8, alpha=16, yang menghasilkan pengembangan 2x. Apabila mengurangkan berat untuk model besar dengan LoRA, adalah menjadi peraturan biasa untuk menetapkan alfa kepada dua kali r. Tetapi saya ingin tahu jika peraturan ini masih berlaku untuk nilai r yang lebih besar.
Saya juga mencuba r=32, r=64, r=128, dan r=512, tetapi mengabaikan proses ini untuk kejelasan, tetapi r=256 berfungsi dengan baik. Malah, memilih alpha=2r memang memberikan hasil yang optimum. Latih model parameter 7B pada GPU tunggal LoRA membolehkan kami memperhalusi model bahasa besar pada skala parameter 7B pada GPU tunggal. Dalam kes khusus ini, pemprosesan 17.86 GB (50k contoh latihan) data menggunakan pengoptimum AdamW mengambil masa kira-kira 3 jam pada A100 dengan tetapan terbaik untuk QLoRA (r=256, alpha=512) (di sini dataset Alpaca).
Dalam seluruh artikel ini, saya akan menjawab soalan lain yang mungkin anda ada. S1: Sejauh manakah penting set data? Set data adalah penting. Saya menggunakan set data Alpaca dengan 50k contoh latihan. Saya memilih Alpaca kerana ia sangat popular. Memandangkan artikel ini sudah sangat panjang, keputusan ujian pada lebih banyak set data tidak akan dibincangkan dalam artikel ini. Alpaca ialah set data sintetik yang boleh menjadi agak ketinggalan zaman mengikut piawaian hari ini. Kualiti data adalah kritikal. Sebagai contoh, pada bulan Jun, saya menulis siaran membincangkan set data LIMA, set data susun atur yang terdiri daripada hanya seribu contoh. Pautan artikel: https://magazine.sebastianraschka.com/p/ahead-of-ai-9-llm-tuning-and-datasetSeperti tajuk kertas yang mencadangkan LIMA: Untuk penjajaran, kurang adalah lebih Walaupun jumlah data dalam LIMA adalah kurang daripada Alpaca, model Llama 65B yang diperhalusi berdasarkan LIMA adalah lebih baik daripada hasil Alpaca. Menggunakan konfigurasi yang sama (r=256, alpha=512), saya memperoleh prestasi model yang serupa pada LIMA kepada Alpaca, yang mempunyai 50 kali ganda data. S2: Adakah LoRA sesuai untuk penyesuaian domain? Saya belum mempunyai jawapan yang jelas untuk soalan ini. Sebagai peraturan, pengetahuan biasanya diekstrak daripada set data pra-latihan. Biasanya, model bahasa biasanya menyerap pengetahuan daripada set data pra-latihan, dan peranan penalaan halus arahan adalah terutamanya untuk membantu LLM mengikut arahan dengan lebih baik. Memandangkan kuasa pengkomputeran merupakan faktor utama yang mengehadkan latihan model bahasa yang besar, LoRA juga boleh digunakan untuk melatih lebih lanjut LLM pra-latihan sedia ada pada set data khusus dalam bidang tertentu. Selain itu, perlu diingat bahawa percubaan saya termasuk dua penanda aras aritmetik. Dalam kedua-dua penanda aras, model yang diperhalusi dengan LoRA menunjukkan prestasi yang lebih teruk daripada model asas yang telah dilatih sebelumnya. Saya membuat spekulasi bahawa ini adalah kerana dataset Alpaca tidak kekurangan contoh aritmetik yang sepadan, menyebabkan model "melupakan" pengetahuan aritmetik. Kajian lanjut diperlukan untuk menentukan sama ada model "terlupa" pengetahuan aritmetik atau sama ada ia berhenti bertindak balas kepada arahan yang sepadan. Walau bagaimanapun, satu kesimpulan boleh dibuat di sini: "Apabila memperhalusi LLM, adalah idea yang baik untuk memastikan set data mengandungi contoh untuk setiap tugasan yang penting bagi kami." nilai? Untuk masalah ini, saya belum ada penyelesaian yang lebih baik. Penentuan nilai r optimum memerlukan analisis khusus masalah khusus berdasarkan keadaan khusus setiap LLM dan setiap set data. Saya membuat spekulasi bahawa nilai r yang terlalu besar akan mengakibatkan overfitting, manakala nilai r yang terlalu kecil mungkin tidak menangkap pelbagai tugas dalam set data. Saya mengesyaki lebih banyak jenis tugas yang terdapat dalam set data, lebih besar nilai r yang diperlukan. Sebagai contoh, jika saya hanya memerlukan model untuk melaksanakan operasi asas aritmetik dua digit, nilai kecil r mungkin mencukupi. Walau bagaimanapun, ini hanyalah hipotesis saya dan memerlukan kajian lanjut untuk mengesahkan. S4: Adakah LoRA perlu didayakan untuk semua lapisan? Saya hanya meneroka dua tetapan: (1) LoRA dengan hanya pertanyaan dan matriks berat didayakan, dan (2) LoRA dengan semua lapisan didayakan. Kesan penggunaan LoRA dalam kombinasi dengan lebih banyak lapisan adalah wajar untuk dikaji lebih lanjut. Jika kita dapat mengetahui sama ada menggunakan LoRA dalam lapisan unjuran memberi manfaat kepada hasil latihan, maka kita boleh mengoptimumkan model dengan lebih baik dan meningkatkan prestasinya. Jika kita mempertimbangkan pelbagai tetapan (lora_query, lora_key, lora_value, lora_projection, lora_mlp, lora_head), terdapat 64 kombinasi untuk diterokai.
S5: Bagaimana untuk mengelakkan overfitting? Secara umumnya, r yang lebih besar lebih berkemungkinan membawa kepada overfitting, kerana r menentukan bilangan parameter yang boleh dilatih. Jika model anda terlampau pasang, mula-mula pertimbangkan untuk menurunkan nilai r atau meningkatkan saiz set data. Selain itu, anda boleh cuba meningkatkan kadar pereputan berat AdamW atau pengoptimum SGD, atau meningkatkan nilai keciciran lapisan LoRA. Saya belum meneroka parameter keciciran LoRA dalam eksperimen (saya menggunakan kadar keciciran tetap 0.05 Parameter keciciran LoRA juga merupakan soalan yang patut dikaji).
S6: Adakah terdapat sebarang pengoptimum lain untuk dipilih? Sophia, dikeluarkan pada bulan Mei tahun ini, patut dicuba Sophia ialah pengoptimum pesanan kedua stokastik berskala untuk pra-latihan model bahasa.Menurut kertas berikut: "Sophia: Pengoptimum Pesanan Kedua Stokastik Berskala untuk Pra-latihan Model Bahasa", berbanding Adam, Sophia adalah dua kali lebih pantas dan boleh mencapai prestasi yang lebih baik. Ringkasnya, Sophia, seperti Adam, melaksanakan normalisasi melalui kelengkungan kecerunan dan bukannya varians kecerunan. Pautan kertas: https://arxiv.org/abs/2305.14342S7: Adakah terdapat faktor lain yang mempengaruhi penggunaan memori? Selain tetapan ketepatan dan pengkuantitian, saiz model, saiz kelompok dan bilangan parameter LoRA yang boleh dilatih, set data juga mempengaruhi penggunaan memori. Saiz blok Llama 2 ialah 4048 token, bermakna Llama boleh memproses urutan yang mengandungi 4048 token pada satu masa. Jika topeng ditambahkan pada token berikutnya, urutan latihan akan menjadi lebih pendek, yang boleh menjimatkan banyak memori. Sebagai contoh, set data Alpaca agak kecil, dengan panjang jujukan terpanjang ialah 1304 token. Apabila saya cuba menggunakan set data lain dengan panjang jujukan terpanjang iaitu 2048 token, penggunaan memori melonjak daripada 17.86 GB kepada 26.96 GB. S8: Berbanding dengan penalaan halus penuh dan RLHF, apakah kelebihan LoRA? Saya tidak mencuba RLHF, tetapi saya mencuba trim penuh. Penalaan halus penuh memerlukan sekurang-kurangnya 2 GPU, mengambil 36.66 GB setiap satu dan mengambil masa 3.5 jam untuk disiapkan. Walau bagaimanapun, keputusan ujian garis dasar yang lemah mungkin disebabkan oleh overfitting atau parameter suboptimum. S9: Bolehkah berat LoRA digabungkan? Jawapannya ya. Semasa latihan, kami memisahkan pemberat LoRA dan pemberat pra-latihan dan menyertainya pada setiap hantaran hadapan. Dengan mengandaikan bahawa di dunia nyata, terdapat aplikasi dengan beberapa set pemberat LoRA, dan setiap set pemberat sepadan dengan pengguna aplikasi, maka wajar untuk menyimpan pemberat ini secara berasingan untuk menjimatkan ruang cakera. Selain itu, pemberat pra-latihan dan pemberat LoRA boleh digabungkan selepas latihan untuk mencipta model tunggal. Dengan cara ini, kita tidak perlu menggunakan pemberat LoRA dalam setiap hantaran hadapan. weight += (lora_B @ lora_A) * scaling
Kita boleh mengemas kini pemberat menggunakan kaedah yang ditunjukkan di atas dan menjimatkan gabungan berat. Begitu juga, kita boleh terus menambah banyak set berat LoRA: weight += (lora_B_set1 @ lora_A_set1) * scaling_set1weight += (lora_B_set2 @ lora_A_set2) * scaling_set2weight += (lora_B_set3 @ lora_A_set3) * scaling_set3...
Saya tidak melakukan eksperimen untuk menilai kaedah ini, tetapi melalui skrip/merge_lora.py skrip Ia yang disediakan dalam Lithuania. sudah boleh. Pautan skrip: https://github.com/Lightning-AI/lit-gpt/blob/main/scripts/merge_lora.pyS10: Bagaimanakah prestasi lapisan demi- penyesuaian peringkat optimum lapisan? Untuk kesederhanaan, dalam rangkaian neural dalam biasanya kami akan menetapkan kadar pembelajaran yang sama untuk setiap lapisan. Kadar pembelajaran ialah hiperparameter yang perlu kita optimumkan, dan seterusnya, kita boleh memilih kadar pembelajaran yang berbeza untuk setiap lapisan (dalam PyTorch, ini bukan perkara yang sangat rumit). Namun dalam amalan ini jarang dilakukan kerana pendekatan ini menambahkan kos tambahan dan terdapat banyak parameter lain yang boleh dilaraskan dalam rangkaian saraf dalam. Sama seperti memilih kadar pembelajaran yang berbeza untuk lapisan yang berbeza, kita juga boleh memilih nilai LoRA r yang berbeza untuk lapisan yang berbeza. Saya belum mencubanya lagi, tetapi terdapat dokumen yang memperincikan kaedah ini: "Pengoptimuman LLM: Penyesuaian Kedudukan Optimum Lapisan (LORA)". Secara teori, pendekatan ini kelihatan menjanjikan, memberikan banyak skop untuk mengoptimumkan hiperparameter. Pautan kertas: https://medium.com/@tom_21755/llm-optimization-layer-wise-optimal-rank-adaptation-lora-1444dfbc8e6a pautan: https://Origina magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms?continueFlag=0c2e38ff6893fba31f1492d815bf928b🎜
Atas ialah kandungan terperinci Bukannya model besar tidak mampu melakukan penalaan halus global, cuma LoRA lebih menjimatkan kos dan tutorial sudah sedia.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!