
Rumah >Peranti teknologi >AI >UC Berkeley berjaya membangunkan model penaakulan visual umum yang besar, dan tiga sarjana kanan bergabung tenaga untuk mengambil bahagian dalam penyelidikan
UC Berkeley berjaya membangunkan model penaakulan visual umum yang besar, dan tiga sarjana kanan bergabung tenaga untuk mengambil bahagian dalam penyelidikan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-12-04 18:25:551232semak imbas
Sejauh mana anda boleh pergi dengan model visual (piksel) sahaja? Kertas kerja baharu daripada UC Berkeley dan Universiti Johns Hopkins meneroka masalah ini dan menunjukkan potensi model penglihatan besar (LVM) pada pelbagai tugas CV.
Sejak kebelakangan ini, model bahasa besar (LLM) seperti GPT dan LLaMA telah menjadi popular di seluruh dunia.
Membina Model Penglihatan Besar (LVM) adalah masalah yang amat membimbangkan. Apa yang kita perlukan untuk mencapainya? Idea yang disediakan oleh model bahasa visual seperti
LLaVA menarik dan patut diterokai, tetapi mengikut undang-undang alam haiwan, kita sudah tahu bahawa keupayaan visual dan keupayaan bahasa tidak berkaitan. Sebagai contoh, banyak eksperimen telah menunjukkan bahawa dunia visual primata bukan manusia sangat serupa dengan manusia, walaupun sistem bahasa mereka "sama" dengan manusia.
Sebuah kertas kerja baru-baru ini membincangkan jawapan kepada soalan lain, iaitu sejauh mana kita boleh pergi dengan piksel sahaja. Kertas kerja itu ditulis oleh penyelidik dari Universiti California, Berkeley dan Universiti Johns Hopkins

Pautan kertas: https://arxiv.org/abs/2312.00785
Laman utama projek: https://yutongbaii .com/lvm.html
Ciri-ciri utama LLM yang penyelidik cuba contohi dalam LVM: 1) Mengikut skala pertumbuhan data Untuk mengembangkan perniagaan, kita perlu mencari peluang pasaran baharu. Kami merancang untuk mengembangkan lagi barisan produk kami untuk memenuhi permintaan yang semakin meningkat. Pada masa yang sama, kami akan mengukuhkan strategi pemasaran dan meningkatkan kesedaran jenama. Dengan mengambil bahagian secara aktif dalam pameran industri dan aktiviti promosi, kami akan berusaha untuk membangunkan lebih banyak kumpulan pelanggan. Kami percaya bahawa melalui usaha ini kami boleh mencapai kejayaan yang lebih besar dan mencapai pertumbuhan yang berterusan, 2) Menentukan tugas secara fleksibel melalui gesaan (pembelajaran kontekstual).
Mereka menetapkan tiga komponen utama, iaitu data, seni bina dan fungsi kehilangan.
Dari segi data, penyelidik ingin memanfaatkan kepelbagaian ketara dalam data visual. Bermula dengan hanya imej mentah dan video yang tidak bernotasi, dan kemudian memanfaatkan pelbagai sumber data visual beranotasi yang dihasilkan sejak beberapa dekad yang lalu (termasuk pembahagian semantik, pembinaan semula kedalaman, titik utama, objek 3D berbilang paparan, dsb.). Mereka mentakrifkan format biasa - "ayat visual" - untuk mewakili anotasi berbeza ini tanpa memerlukan sebarang pengetahuan meta melebihi piksel. Jumlah saiz set latihan ialah 1.64 bilion imej/bingkai.
Dari segi seni bina, penyelidik menggunakan seni bina transformer yang besar (3 bilion parameter) untuk melatih data visual yang diwakili sebagai jujukan token, dan menggunakan tokenizer yang dipelajari untuk memetakan setiap imej kepada 256 vektor kuantiti rentetan token.
Dari segi fungsi kehilangan, penyelidik mendapat inspirasi daripada komuniti bahasa semula jadi, iaitu, pemodelan token topeng telah "memberi laluan" untuk menyusun kaedah ramalan autoregresif. Setelah imej, video dan imej beranotasi semuanya boleh diwakili sebagai jujukan, model terlatih boleh meminimumkan kehilangan entropi silang apabila meramalkan token seterusnya.
Melalui reka bentuk yang sangat mudah ini, penyelidik menunjukkan tingkah laku yang perlu diberi perhatian berikut:
Apabila saiz model dan saiz data meningkat, model secara automatik akan menunjukkan yang sesuai Untuk mengembangkan perniagaan, kita perlu mencari peluang pasaran baharu. Kami merancang untuk mengembangkan lagi barisan produk kami untuk memenuhi permintaan yang semakin meningkat. Pada masa yang sama, kami akan mengukuhkan strategi pemasaran dan meningkatkan kesedaran jenama. Dengan mengambil bahagian secara aktif dalam pameran industri dan aktiviti promosi, kami akan berusaha untuk membangunkan lebih banyak kumpulan pelanggan. Kami percaya bahawa dengan usaha ini kami boleh mencapai kejayaan yang lebih besar dan mencapai tingkah laku pertumbuhan yang berterusan
Banyak tugas visual yang berbeza kini boleh diselesaikan dengan mereka bentuk gesaan yang sesuai pada masa ujian. Walaupun bukan hasil prestasi tinggi seperti model terlatih khas, hakikat bahawa model penglihatan tunggal boleh menyelesaikan begitu banyak tugas adalah sangat menggalakkan
Sejumlah besar data tanpa pengawasan mengenai pelbagai tugas penglihatan Prestasi telah membantu dengan ketara;
Apabila memproses data luar pengedaran dan melaksanakan tugas baharu, terdapat tanda-tanda keupayaan penaakulan visual umum, tetapi kajian lanjut masih diperlukan
Pengarang bersama kertas kerja, John Hope Yutong Bai, seorang pelajar kedoktoran CS tahun empat di Kings College dan pelajar PhD yang melawat di Berkeley, menulis tweet untuk mempromosikan kerja mereka.
Sumber imej asal datang daripada akaun Twitter: https://twitter.com/YutongBAI1002/status/1731512110247473608
Antara tiga orang sarjana yang terakhir adalah penulis bidang. daripada CV di UC Berkeley . Profesor Trevor Darrell ialah pengarah bersama pengasas BAIR, Makmal Penyelidikan Kecerdasan Buatan Berkeley, Profesor Jitendra Malik memenangi Anugerah Perintis Komputer IEEE 2019, dan Profesor Alexei A. Efros amat terkenal dengan penyelidikan jiran terdekat.

Dari kiri ke kanan ialah Trevor Darrell, Jitendra Malik, Alexei A. Efros.
Pengenalan kaedah
Artikel menggunakan pendekatan dua peringkat: 1) melatih tokenizer visual yang besar (beroperasi pada satu imej), yang mampu menukar setiap imej kepada satu siri token visual; ayat visual Model pengubah autoregresif, setiap ayat diwakili sebagai satu siri token. Kaedah ini ditunjukkan dalam Rajah 2
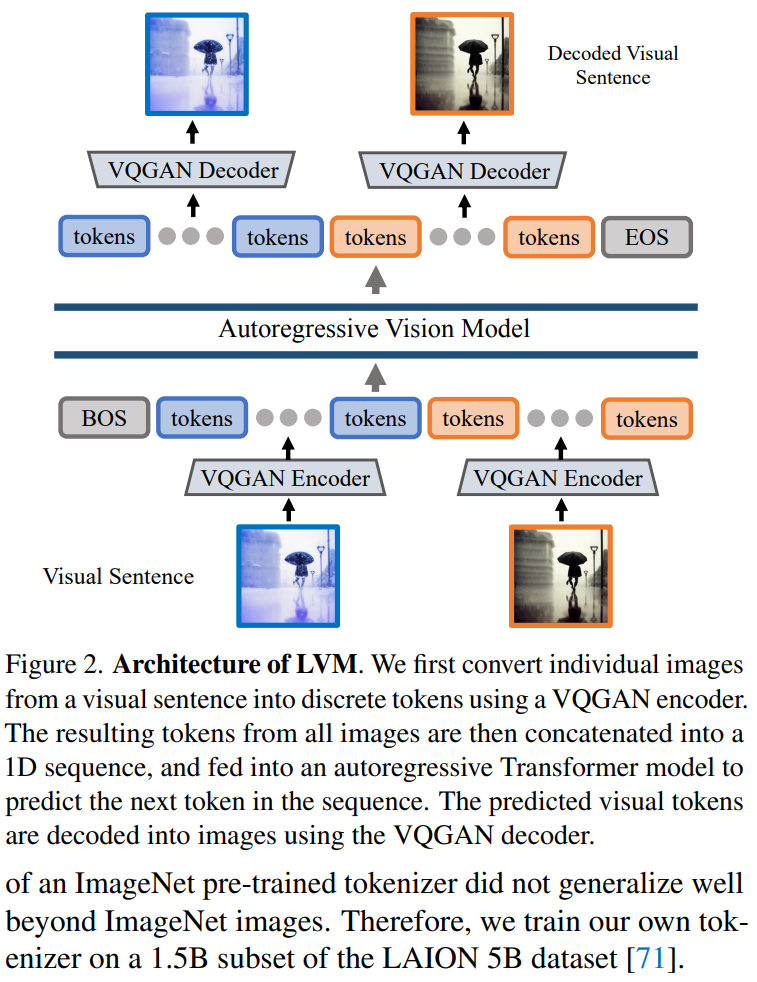
Tokenisasi Imej
Untuk menggunakan model Transformer pada imej, operasi biasa termasuk: membahagikan imej kepada tampalan dan menganggapnya sebagai jujukan A tokenizer, seperti VQVAE atau VQGAN, mengagregatkan ciri imej ke dalam grid token diskret. Artikel ini menggunakan kaedah yang terakhir, menggunakan model VQGAN untuk menjana token semantik.
Rangka kerja LVM termasuk mekanisme pengekodan dan penyahkodan dan juga mempunyai lapisan pengkuantitian, di mana pengekod dan penyahkod dibina dengan lapisan konvolusi. Pengekod dilengkapi dengan berbilang modul pensampelan rendah untuk mengecilkan dimensi ruang input, manakala penyahkod dilengkapi dengan satu siri modul pensampelan naik yang setara untuk memulihkan imej kepada saiz asalnya. Untuk imej tertentu, tokenizer VQGAN menghasilkan 256 token diskret.
Seni bina VQGAN dalam kertas ini mengguna pakai butiran pelaksanaan yang dicadangkan oleh Chang et al dan mengikut persediaan mereka. Secara khusus, faktor pensampelan rendah ialah f=16 dan saiz buku kod ialah 8192. Ini bermakna untuk imej bersaiz 256×256, tokenizer VQGAN akan menjana 16×16=256 token, dan setiap token boleh mengambil 8192 nilai yang berbeza. Di samping itu, artikel ini melatih tokenizer pada subset 1.5B set data LAION 5B
Pemodelan urutan ayat visual
Selepas menggunakan VQGAN untuk menukar imej kepada token diskret, artikel ini menggunakan token diskret dalam berbilang imej Gabungkan menjadi satu -urutan dimensi dan menganggap ayat visual sebagai urutan bersatu. Yang penting, tiada ayat visual diproses khas - iaitu, tiada token khas digunakan untuk menunjukkan tugas atau format tertentu.

Fungsi ayat visual adalah untuk memformat data visual yang berbeza ke dalam struktur jujukan imej bersatu
Butiran pelaksanaan. Selepas menandakan setiap imej dalam ayat visual menjadi 256 token, kertas ini menggabungkannya untuk membentuk urutan token 1D. Pada jujukan token visual, model Transformer dalam artikel ini sebenarnya sama dengan model bahasa autoregresif, jadi mereka menggunakan seni bina Transformer LLaMA.
Kandungan ini menggunakan panjang konteks sebanyak 4096 token, serupa dengan model bahasa. Tambahkan token [BOS] (permulaan ayat) pada permulaan setiap ayat visual dan token [EOS] (akhir ayat) pada akhir, dan gunakan penyambungan urutan semasa latihan untuk meningkatkan kecekapan
Artikel ini berprestasi baik pada keseluruhan dataset UVDv1 (4200 100 juta token), sejumlah 4 model dengan nombor parameter berbeza telah dilatih: 300 juta, 600 juta, 1 bilion dan 3 bilion.
Hasil eksperimen perlu ditulis semula
Kajian menjalankan eksperimen untuk menilai model Untuk mengembangkan perniagaan, kita perlu mencari peluang pasaran baharu. Kami merancang untuk mengembangkan lagi barisan produk kami untuk memenuhi permintaan yang semakin meningkat. Pada masa yang sama, kami akan mengukuhkan strategi pemasaran dan meningkatkan kesedaran jenama. Dengan mengambil bahagian secara aktif dalam pameran industri dan aktiviti promosi, kami akan berusaha untuk membangunkan lebih banyak kumpulan pelanggan. Kami percaya bahawa melalui usaha ini kami boleh mencapai kejayaan yang lebih besar dan mencapai pertumbuhan berterusan dalam keupayaan dan keupayaan kami untuk memahami dan menjawab pelbagai tugas.
Untuk mengembangkan perniagaan kita, kita perlu mencari peluang pasaran baharu. Kami merancang untuk mengembangkan lagi barisan produk kami untuk memenuhi permintaan yang semakin meningkat. Pada masa yang sama, kami akan mengukuhkan strategi pemasaran dan meningkatkan kesedaran jenama. Dengan mengambil bahagian secara aktif dalam pameran industri dan aktiviti promosi, kami akan berusaha untuk membangunkan lebih banyak kumpulan pelanggan. Kami percaya bahawa melalui usaha ini, kami boleh mencapai pencapaian yang lebih besar dan mencapai pertumbuhan yang mampan
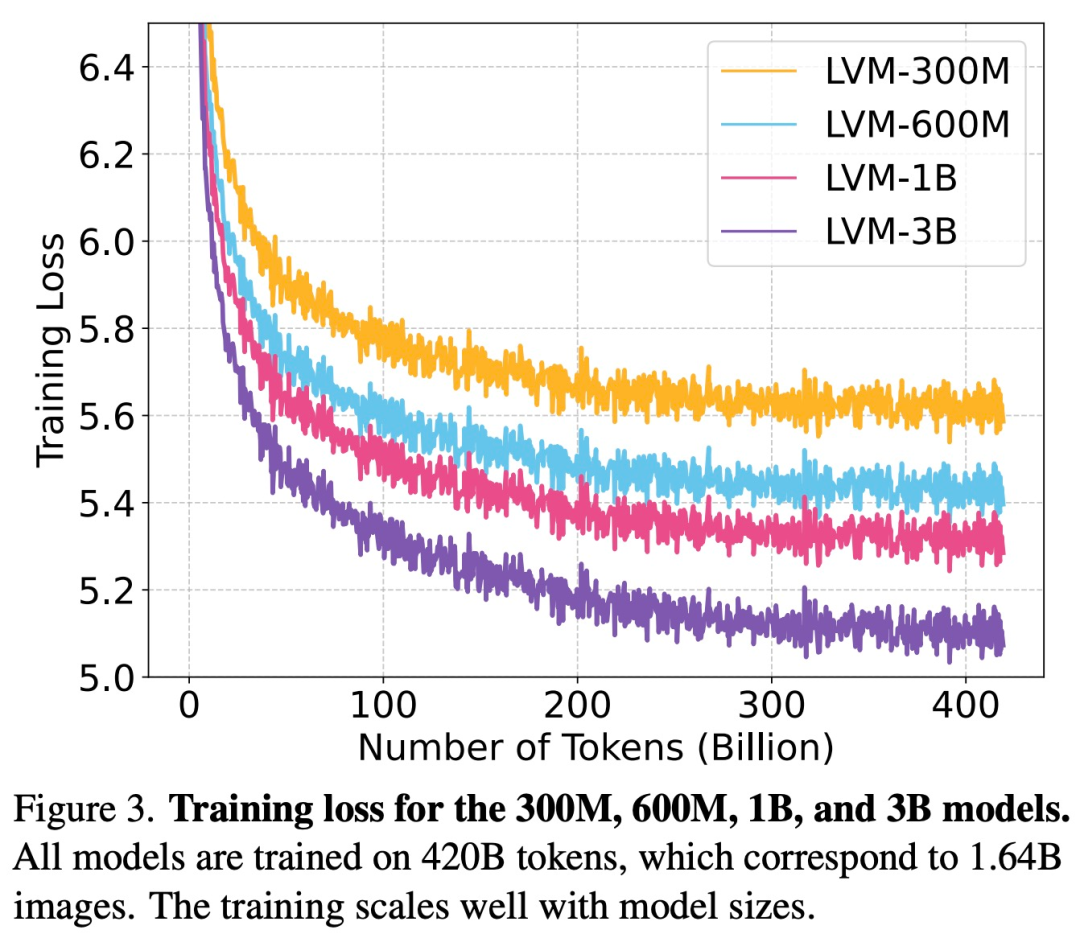
Seperti yang ditunjukkan dalam Rajah 3, kajian pertama kali meneliti kehilangan latihan LVM dengan saiz yang berbeza
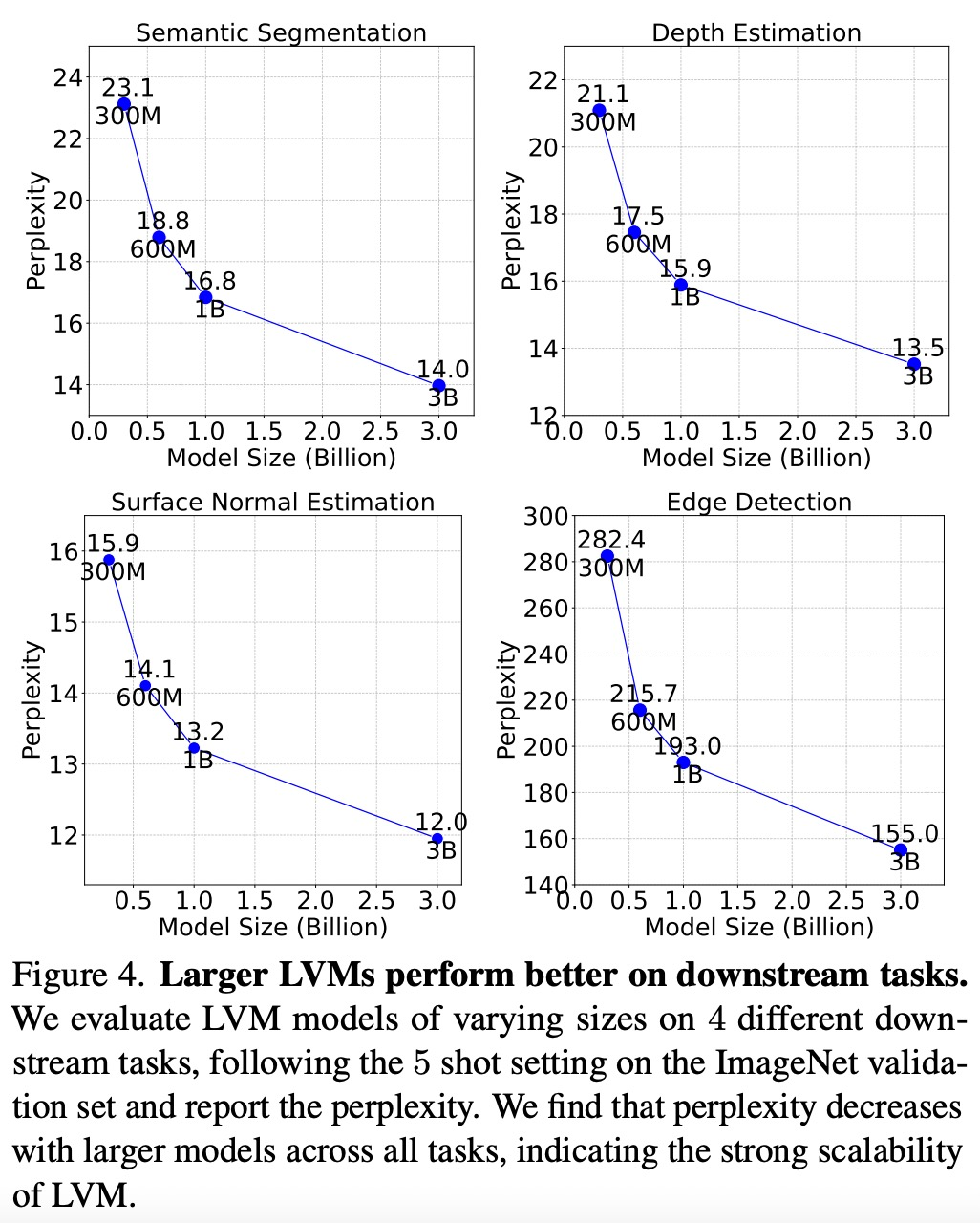
Seperti yang ditunjukkan dalam Rajah 4 di bawah menunjukkan bahawa model yang lebih besar mempunyai kerumitan yang lebih rendah merentas semua tugas, menunjukkan bahawa prestasi keseluruhan model boleh dipindahkan ke pelbagai tugas hiliran.
Seperti yang ditunjukkan dalam Rajah 5, setiap komponen data mempunyai kesan penting ke atas tugas hiliran. LVM bukan sahaja mendapat manfaat daripada data yang lebih besar, tetapi juga bertambah baik dengan kepelbagaian set data
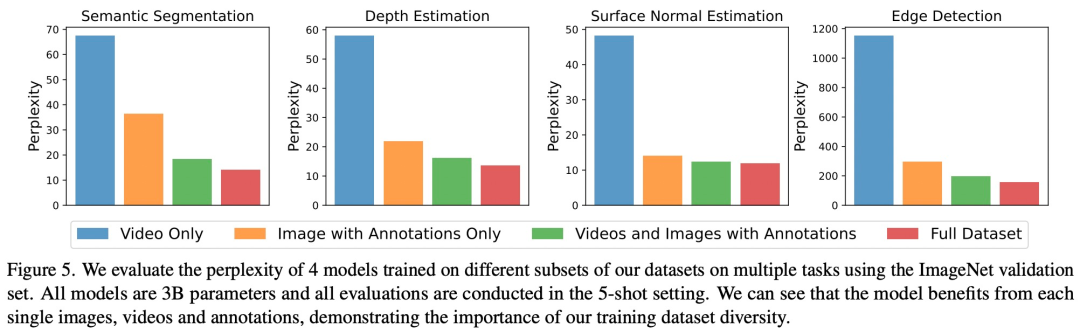
Menulis semula kandungan tanpa mengubah makna asal memerlukan penulisan semula bahasa kepada bahasa Cina. Ayat asal sepatutnya muncul
Untuk menguji keupayaan LVM memahami pelbagai gesaan, kajian ini mula-mula menjalankan eksperimen penilaian pada LVM pada tugas penaakulan urutan. Antaranya, prompt adalah sangat mudah: sediakan model dengan urutan 7 imej dan minta ia meramalkan imej seterusnya Keputusan eksperimen perlu ditulis semula seperti yang ditunjukkan dalam Rajah 6 di bawah:

Kajian ini juga akan memberi. senarai item dalam kategori Anggap ia sebagai urutan dan biarkan LVM meramalkan imej dari kategori yang sama Keputusan percubaan perlu ditulis semula seperti yang ditunjukkan dalam Rajah 15 di bawah:

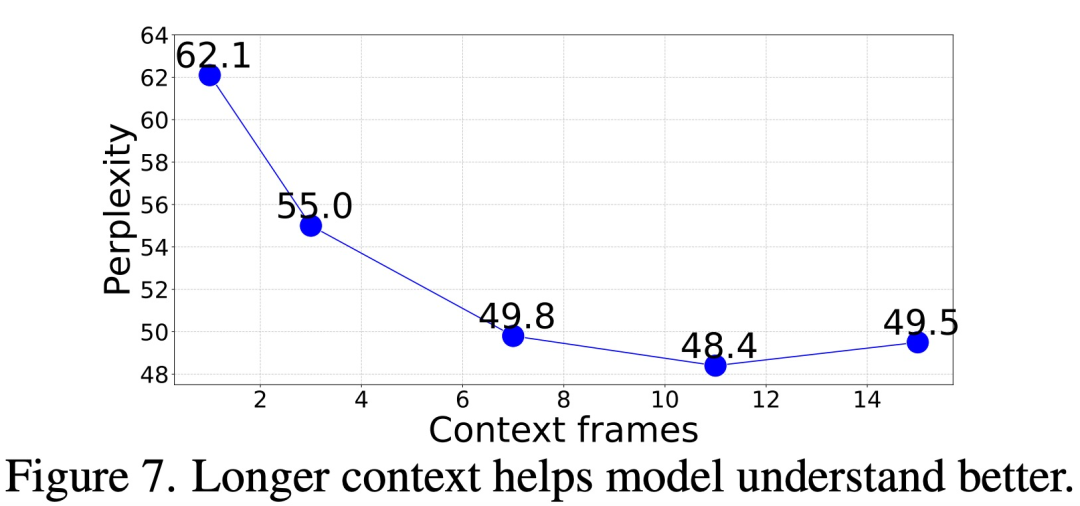
Jadi, berapa banyak konteks yang diperlukan untuk tepat. ramalkan bingkai seterusnya?
Dalam kajian ini, kami menilai kebingungan penjanaan bingkai model kami dengan memberikan gesaan kontekstual dengan panjang yang berbeza (1 hingga 15 bingkai). Keputusan menunjukkan bahawa kebingungan beransur-ansur bertambah baik apabila bilangan bingkai meningkat. Data khusus ditunjukkan dalam Rajah 7 di bawah. Kebingungan bertambah baik dengan ketara daripada bingkai 1 kepada bingkai 11, dan kemudian menjadi stabil (62.1 → 48.4)
Analogy Prompt
Kajian tahap lanjutan LVM ini juga menguji tahap lanjutan kuasa, dengan menilai struktur gesaan yang lebih kompleks seperti gesaan analogi
Rajah 8 di bawah menunjukkan hasil kualitatif Prompt Analogi untuk beberapa tugas:

Berdasarkan perbandingan dengan gesaan visual, dapat dilihat bahawa urutan LVM berprestasi lebih baik dalam hampir Semua tugasan lebih baik daripada kaedah sebelumnya

Tugas sintetik. Rajah 9 menunjukkan hasil penggabungan berbilang tugas menggunakan satu gesaan

Gesaan lain
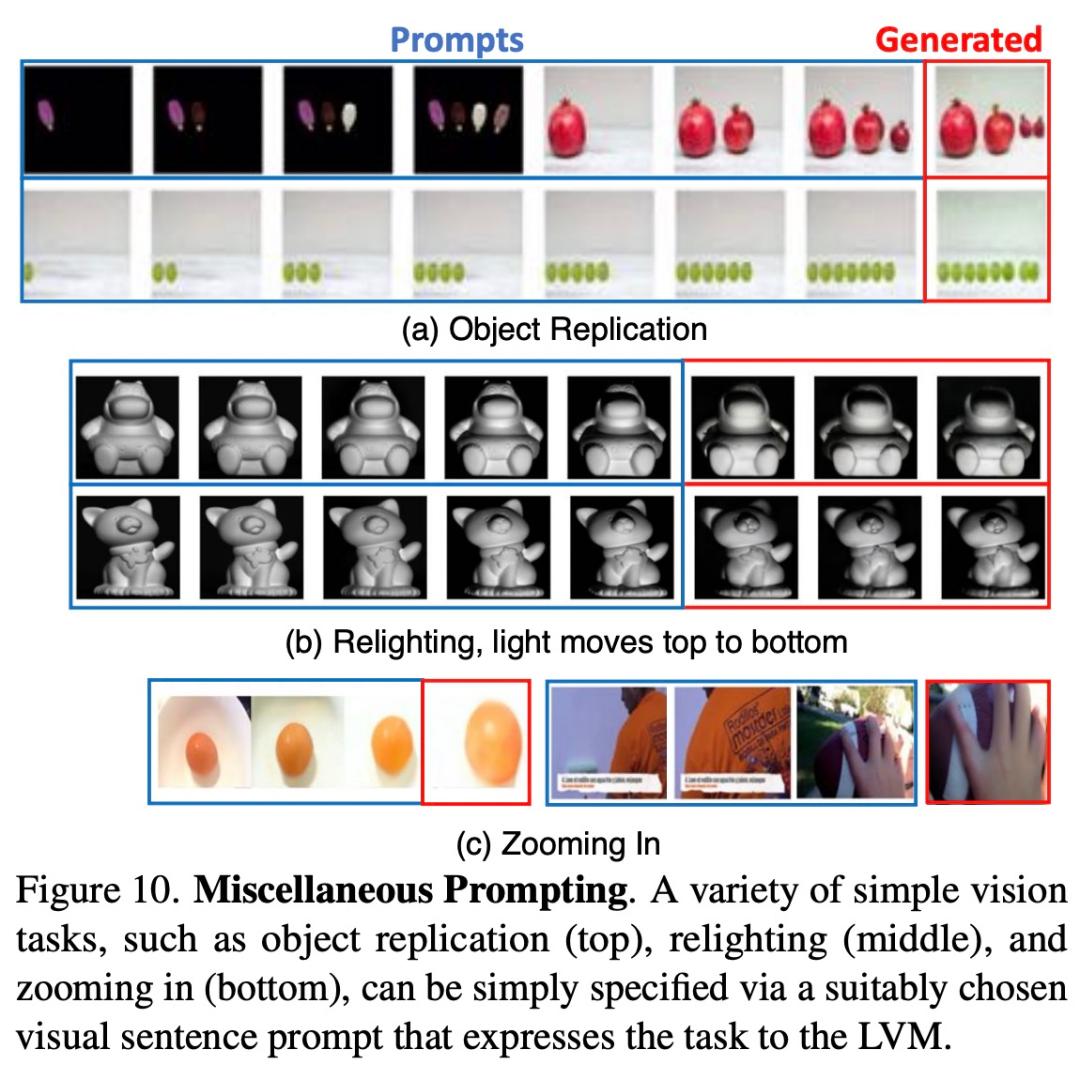
Para penyelidik cuba memerhati penskalaan model dengan memberinya pelbagai gesaan yang tidak pernah dilihatnya sebelum ini. kita perlu mencari peluang pasaran baharu. Kami merancang untuk mengembangkan lagi barisan produk kami untuk memenuhi permintaan yang semakin meningkat. Pada masa yang sama, kami akan mengukuhkan strategi pemasaran dan meningkatkan kesedaran jenama. Dengan mengambil bahagian secara aktif dalam pameran industri dan aktiviti promosi, kami akan berusaha untuk membangunkan lebih banyak kumpulan pelanggan. Kami percaya bahawa melalui usaha ini, kami boleh mencapai kejayaan yang lebih besar dan mencapai pertumbuhan yang berterusan. Rajah 10 di bawah menunjukkan beberapa gesaan sedemikian berfungsi dengan baik.
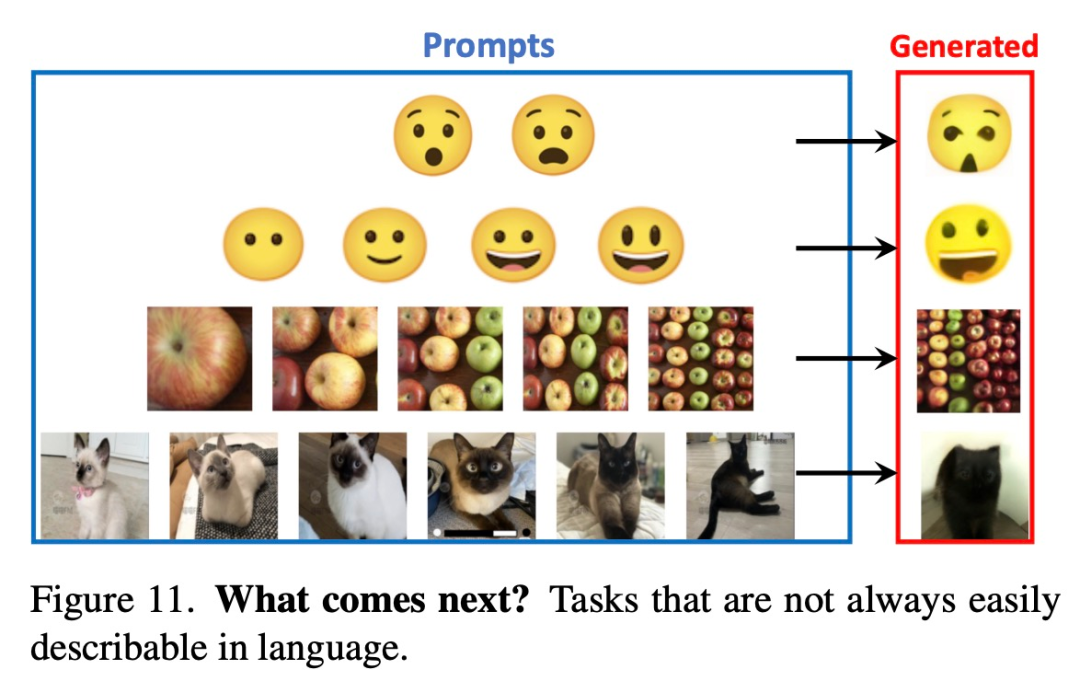
Rajah 11 di bawah menunjukkan beberapa gesaan yang sukar untuk diterangkan dengan perkataan akhirnya mungkin mengatasi LLM dalam tugasan ini.
Rajah 13 menunjukkan keputusan kualitatif awal pada masalah penaakulan visual tipikal dalam ujian IQ manusia bukan lisan

Baca artikel asal untuk butiran lanjut.
Atas ialah kandungan terperinci UC Berkeley berjaya membangunkan model penaakulan visual umum yang besar, dan tiga sarjana kanan bergabung tenaga untuk mengambil bahagian dalam penyelidikan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!