
Rumah >Peranti teknologi >AI >LLMLingua: Sepadukan LlamaIndex, mampatkan petunjuk dan menyediakan perkhidmatan inferens model bahasa besar yang cekap
LLMLingua: Sepadukan LlamaIndex, mampatkan petunjuk dan menyediakan perkhidmatan inferens model bahasa besar yang cekap

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-11-27 17:13:55951semak imbas
Kemunculan model bahasa besar (LLM) telah merangsang inovasi dalam pelbagai bidang. Walau bagaimanapun, peningkatan kerumitan gesaan, didorong oleh strategi seperti gesaan rantaian pemikiran (CoT) dan pembelajaran kontekstual (ICL), menimbulkan cabaran pengiraan. Gesaan yang panjang ini memerlukan sumber yang besar untuk membuat penaakulan dan oleh itu memerlukan penyelesaian yang cekap. Artikel ini akan memperkenalkan integrasi LLMLingua dengan LlamaIndex proprietari untuk melakukan inferens yang cekap
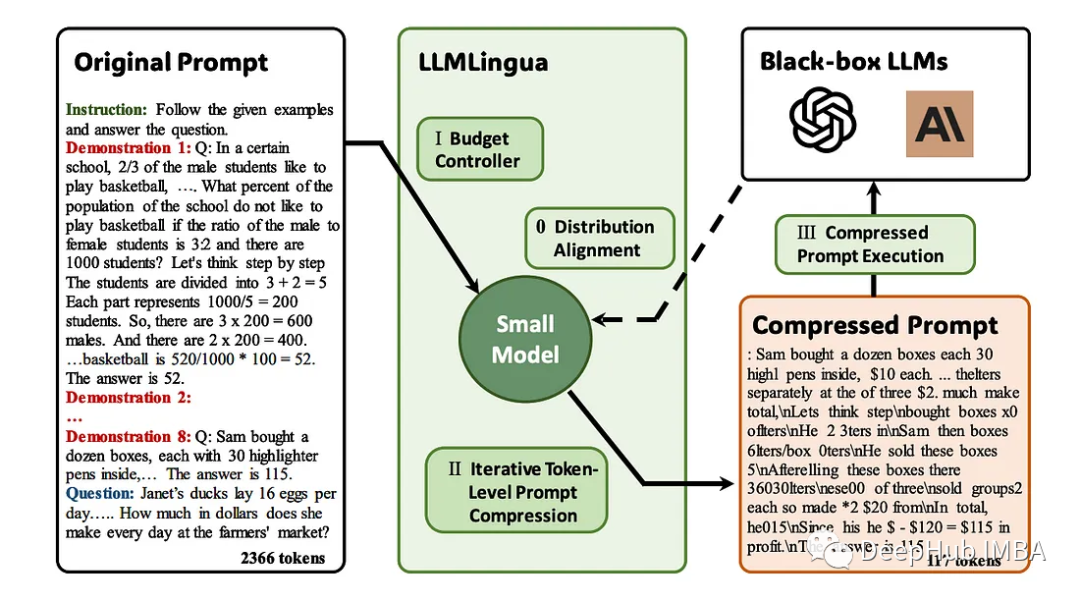
LLMLlingua ialah kertas kerja yang diterbitkan oleh penyelidik Microsoft di EMNLP 2023. LongLLMLingua ialah kaedah yang meningkatkan pemampatan dalam konteks yang panjang dan pantas . untuk keupayaan untuk memahami maklumat penting.
LLMLingua bekerja bersama-sama dengan llamindex
LLMLingua muncul sebagai penyelesaian perintis untuk gesaan verbose dalam aplikasi LLM. Pendekatan ini memberi tumpuan kepada memampatkan gesaan yang panjang sambil memastikan integriti semantik dan meningkatkan kelajuan inferens. Ia menggabungkan pelbagai strategi mampatan untuk menyediakan cara yang halus untuk mengimbangi panjang petunjuk dan kecekapan pengiraan.
Berikut ialah kelebihan penyepaduan LLMLingua dan LlamaIndex:
Penyepaduan LLMLingua dan LlamaIndex menandakan langkah penting untuk llm dalam pengoptimuman pantas. LlamaIndex ialah repositori khusus yang mengandungi pembayang pra-dioptimumkan yang disesuaikan untuk pelbagai aplikasi LLM, dan melalui penyepaduan ini LLMLingua boleh mengakses satu set pembayang khusus domain yang diperhalusi, dengan itu meningkatkan keupayaan pemampatan pembayangnya.
LLMLingua meningkatkan kecekapan aplikasi LLM melalui sinergi dengan perpustakaan petunjuk pengoptimuman LlamaIndex. Dengan memanfaatkan isyarat khusus LLAMA, LLMLingua boleh memperhalusi strategi pemampatannya untuk memastikan konteks khusus domain dipelihara sambil mengurangkan panjang isyarat. Kerjasama ini mempercepatkan inferens secara mendadak sambil mengekalkan nuansa domain utama
Penyepaduan LLMLingua dengan LlamaIndex meluaskan impaknya pada aplikasi LLM berskala besar. Dengan memanfaatkan petua pakar LLAMA, LLMLingua telah mengoptimumkan teknologi pemampatannya, mengurangkan beban pengiraan memproses petua yang panjang. Penyepaduan ini bukan sahaja mempercepatkan inferens tetapi juga memastikan pengekalan maklumat khusus domain kritikal.
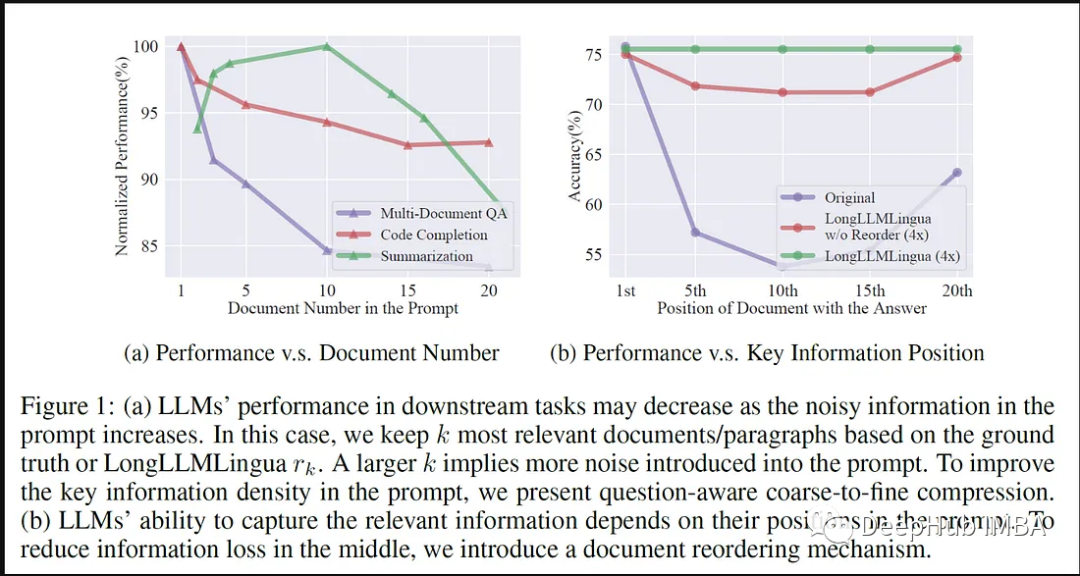
Aliran kerja antara LLMLingua dan LlamaIndex
Menggunakan LlamaIndex untuk melaksanakan LLMLingua memerlukan satu siri proses berstruktur, termasuk penggunaan perpustakaan inferens khusus untuk mencapai pembayang yang lebih pantas dan cekap
1 . Integrasi Rangka KerjaMula-mula anda perlu mewujudkan hubungan antara LLMLingua dan LlamaIndex. Ini termasuk hak akses, konfigurasi API dan mewujudkan sambungan untuk mendapatkan semula tepat pada masanya.
2. Mendapatkan semula petua pra-pengoptimuman
LlamaIndex berfungsi sebagai repositori khusus yang mengandungi petua pra-pengoptimuman yang disesuaikan untuk pelbagai aplikasi LLM. LLMLingua mengakses repositori ini, mendapatkan pembayang khusus domain dan menggunakan pembayang ini untuk pemampatan
3. Teknologi Pemampatan Petunjuk
LLMLingua menggunakan kaedah pemampatan pembayangnya untuk memudahkan pemampatan. Teknik ini memfokuskan pada memampatkan gesaan yang panjang sambil memastikan ketekalan semantik, dengan itu meningkatkan kelajuan inferens tanpa menjejaskan konteks atau perkaitan.
4. Perhalusi strategi pemampatan
LLMLingua memperhalusi strategi pemampatannya berdasarkan petua khusus yang diperolehi daripada LlamaIndex. Proses penghalusan ini memastikan bahawa nuansa khusus domain dipelihara sambil mengurangkan panjang segera dengan cekap.
5. Pelaksanaan dan Inferens
Selepas pemampatan menggunakan strategi tersuai LLMLingua dan digabungkan dengan pembayang pra-pengoptimuman LlamaIndex, pembayang yang terhasil boleh digunakan untuk tugasan inferens LLM. Pada peringkat ini, kami melakukan pembayang mampatan dalam rangka kerja LLM untuk membolehkan inferens sedar konteks yang cekap
6 Penambahbaikan dan penambahbaikan berulang
Pelaksanaan kod secara berterusan mengalami pemurnian berulang. Proses ini termasuk menambah baik algoritma mampatan, mengoptimumkan perolehan semula pembayang daripada LlamaIndex dan memperhalusi penyepaduan untuk memastikan konsistensi dan prestasi yang dipertingkatkan bagi pembayang termampat dan inferens LLM.
7. Pengujian dan pengesahan
Jika perlu, ujian dan pengesahan juga boleh dijalankan, supaya kecekapan dan keberkesanan integrasi LLMLingua dan LlamaIndex dapat dinilai. Metrik prestasi dinilai untuk memastikan pembayang mampatan mengekalkan integriti semantik dan meningkatkan kelajuan inferens tanpa menjejaskan ketepatan.
Pelaksanaan Kod
Kami akan mula mendalami pelaksanaan kod LLMLingua dan LlamaIndex
Pakej pemasangan:
# Install dependency. !pip install llmlingua llama-index openai tiktoken -q # Using the OAI import openai openai.api_key = "<insert_openai_key>"</insert_openai_key>
!wget "https://www.dropbox.com/s/f6bmb19xdg0xedm/paul_graham_essay.txt?dl=1" -O paul_graham_essay.txt
from llama_index import (VectorStoreIndex,SimpleDirectoryReader,load_index_from_storage,StorageContext, ) # load documents documents = SimpleDirectoryReader(input_files=["paul_graham_essay.txt"] ).load_data()
index = VectorStoreIndex.from_documents(documents) retriever = index.as_retriever(similarity_top_k=10) question = "Where did the author go for art school?" # Ground-truth Answer answer = "RISD" contexts = retriever.retrieve(question) contexts = retriever.retrieve(question) context_list = [n.get_content() for n in contexts] len(context_list) #Output #10
# The response from original prompt from llama_index.llms import OpenAI llm = OpenAI(model="gpt-3.5-turbo-16k") prompt = "\n\n".join(context_list + [question]) response = llm.complete(prompt) print(str(response)) #Output The author went to the Rhode Island School of Design (RISD) for art school.
from llama_index.query_engine import RetrieverQueryEngine from llama_index.response_synthesizers import CompactAndRefine from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor node_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder,"dynamic_context_compression_ratio": 0.3,}, )
通过LLMLingua进行压缩 打印2个结果对比: 打印的结果如下: 验证输出: LLMLingua与LlamaIndex的集成证明了协作关系在优化大型语言模型(LLM)应用程序方面的变革潜力。这种协作彻底改变了即时压缩方法和推理效率,为上下文感知、简化的LLM应用程序铺平了道路。 这种集成不仅可以提升推理速度,而且可以保证在压缩提示中保持语义的完整性。通过对基于LlamaIndex特定领域提示的压缩策略进行微调,我们平衡了提示长度的减少和基本上下文的保留,从而提高了LLM推理的准确性 从本质上讲,LLMLingua与LlamaIndex的集成超越了传统的提示压缩方法,为未来大型语言模型应用程序的优化、上下文准确和有效地针对不同领域进行定制奠定了基础。这种协作集成预示着大型语言模型应用程序领域中效率和精细化的新时代的到来。from llama_index.query_engine import RetrieverQueryEngine from llama_index.response_synthesizers import CompactAndRefine from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor node_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder,"dynamic_context_compression_ratio": 0.3,}, )
retrieved_nodes = retriever.retrieve(question) synthesizer = CompactAndRefine() from llama_index.indices.query.schema import QueryBundle # postprocess (compress), synthesize new_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=question) ) original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes]) compressed_contexts = "\n\n".join([n.get_content() for n in new_retrieved_nodes]) original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts) compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)
print(compressed_contexts) print() print("Original Tokens:", original_tokens) print("Compressed Tokens:", compressed_tokens) print("Comressed Ratio:", f"{original_tokens/(compressed_tokens + 1e-5):.2f}x")
next Rtm's advice hadn' included anything that. I wanted to do something completely different, so I decided I'd paint. I wanted to how good I could get if I focused on it. the day after stopped on YC, I painting. I was rusty and it took a while to get back into shape, but it was at least completely engaging.1] I wanted to back RISD, was now broke and RISD was very expensive so decided job for a year and return RISD the fall. I got one at Interleaf, which made software for creating documents. You like Microsoft Word? Exactly That was I low end software tends to high. Interleaf still had a few years to live yet. [] the Accademia wasn't, and my money was running out, end year back to thelot the color class I tookD, but otherwise I was basically myself to do that for in993 I dropped I aroundidence bit then my friend Par did me a big A rent-partment building New York. Did I want it Itt more my place, and York be where the artists. wanted [For when you that ofs you big painting of this type hanging in the apartment of a hedge fund manager, you know he paid millions of dollars for it. That's not always why artists have a signature style, but it's usually why buyers pay a lot for such work. [6] Original Tokens: 10719 Compressed Tokens: 308 Comressed Ratio: 34.80x
response = synthesizer.synthesize(question, new_retrieved_nodes) print(str(response)) #Output #The author went to RISD for art school.
总结
Atas ialah kandungan terperinci LLMLingua: Sepadukan LlamaIndex, mampatkan petunjuk dan menyediakan perkhidmatan inferens model bahasa besar yang cekap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- python人工智能是什么
- 人工智能的目的是让机器能够什么
- Seruan ICML untuk kertas melarang penggunaan model bahasa besar yang dikemukakan LeCun: Bolehkah model bersaiz kecil dan sederhana digunakan?
- Kajian menunjukkan model bahasa besar mempunyai masalah dengan penaakulan logik
- Terdapat bukti MIT menunjukkan bahawa model bahasa besar ≠ burung kakak tua secara rawak memang boleh mempelajari semantik.