
Rumah >Peranti teknologi >AI >Terdapat bukti MIT menunjukkan bahawa model bahasa besar ≠ burung kakak tua secara rawak memang boleh mempelajari semantik.
Terdapat bukti MIT menunjukkan bahawa model bahasa besar ≠ burung kakak tua secara rawak memang boleh mempelajari semantik.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-23 08:01:051115semak imbas
Walaupun model bahasa pra-latihan (LLM) yang besar telah menunjukkan prestasi yang dipertingkatkan secara mendadak merentas pelbagai tugasan hiliran, adakah mereka benar-benar memahami semantik teks yang mereka gunakan dan hasilkan?
Komuniti AI telah lama berpecah-belah dalam isu ini. Satu tekaan ialah model bahasa yang dilatih semata-mata dalam bentuk bahasa (seperti pengedaran bersyarat token dalam korpus latihan) tidak akan memperoleh sebarang semantik. Sebaliknya, mereka hanya menjana teks berdasarkan korelasi statistik cetek yang diperoleh daripada data latihan, dengan keupayaan kemunculan kukuh mereka dikaitkan dengan saiz model dan data latihan. Mereka ini merujuk kepada LLM sebagai "nuri rawak".
Tetapi ada sesetengah pihak yang tidak bersetuju dengan pandangan ini. Kajian baru-baru ini menunjukkan bahawa kira-kira 51% daripada responden komuniti NLP bersetuju bahawa "beberapa model generatif yang dilatih semata-mata pada teks, dengan data yang mencukupi dan sumber pengiraan, boleh memahami sifat dalam beberapa cara yang bermakna (di luar korelasi statistik peringkat permukaan, melibatkan pemahaman semantik dan konsep di sebalik bahasa)”.
Untuk meneroka soalan yang tidak terjawab ini, penyelidik dari MIT CSAIL menjalankan kajian terperinci.

Alamat kertas: https://paperswithcode.com/paper/evidence-of- model-makna-dalam-bahasa
Model bahasa yang digunakan dalam kajian ini hanya dilatih untuk menjadi model bagi ramalan teks bagi token seterusnya, dan dua hipotesis dirumuskan:
- H1: LM yang dilatih semata-mata oleh ramalan token seterusnya pada teks pada asasnya terhad dengan mengulangi korelasi statistik peringkat permukaan dalam korpus latihan mereka;
- H2LM tidak boleh memberikan makna kepada teks yang dihadam dan dijana.
Untuk meneroka ketepatan kedua-dua hipotesis H1 dan H2, kajian ini menggunakan pemodelan bahasa untuk tugas sintesis program, iaitu, diberikan contoh input dan output formal spesifikasi Muat turun program sintesis. Kajian ini mengambil pendekatan ini terutamanya kerana makna (dan ketepatan) program ditentukan sepenuhnya oleh semantik bahasa pengaturcaraan.
Secara khusus, kajian ini melatih model bahasa (LM) pada korpus atur cara dan spesifikasinya, dan kemudian menggunakan pengelas linear untuk mengesan keadaan tersembunyi LM bagi perwakilan semantik daripada program tersebut. Kajian mendapati bahawa keupayaan pengesan untuk mengekstrak semantik adalah stokastik pada permulaan dan kemudian mengalami perubahan fasa semasa latihan yang sangat berkorelasi dengan keupayaan LM untuk menjana program yang betul tanpa melihat spesifikasi. Selain itu, kajian membentangkan hasil daripada eksperimen intervensi yang menunjukkan bahawa semantik diwakili dalam keadaan model (bukannya dipelajari melalui probe).
Sumbangan utama penyelidikan ini termasuklah:
1. Keputusan eksperimen menunjukkan terdapat beberapa masalah dalam LM yang melaksanakan tugasan meramalkan token seterusnya. Secara khusus, kajian menggunakan LM terlatih untuk menjana program yang diberikan beberapa contoh input-output, dan kemudian melatih pengesan linear untuk mengekstrak maklumat tentang keadaan program daripada keadaan model. Penyelidik mendapati bahawa perwakilan dalaman mengandungi pengekodan linear berikut: (1) semantik abstrak (tafsiran abstrak) - menjejaki input tertentu semasa pelaksanaan program pada masa hadapan yang sepadan dengan token program yang belum dijana; Semasa latihan, perwakilan linear semantik ini berkembang selari dengan keupayaan LM untuk menjana program yang betul semasa langkah latihan.
2. Kajian ini mereka bentuk dan menilai kaedah intervensi baru untuk meneroka sumbangan LM dan pengesan apabila mengekstrak makna daripada perwakilan. Secara khusus, kajian ini cuba menganalisis mana antara dua soalan berikut yang benar: (1) Perwakilan LM mengandungi transkrip tulen (sintaktik) manakala pengesan belajar mentafsir transkrip untuk membuat kesimpulan makna; ekstrak makna daripada keadaan semantik. Keputusan eksperimen menunjukkan bahawa perwakilan LM sebenarnya diselaraskan dengan semantik asal (bukannya hanya mengekod beberapa kandungan leksikal dan sintaksis), menunjukkan bahawa hipotesis H2 adalah salah.
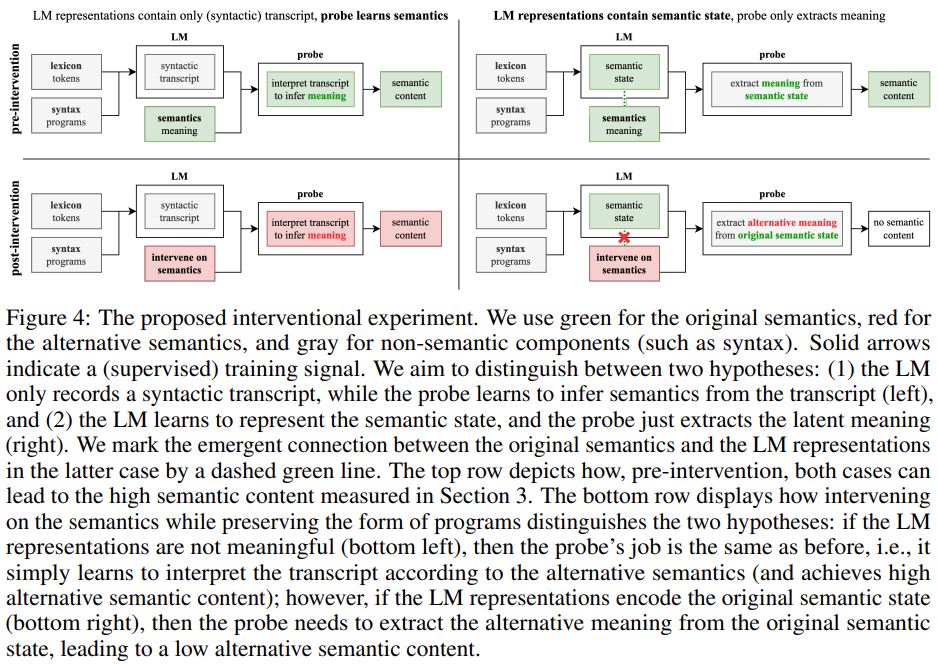
3. Kajian ini menunjukkan bahawa output LM adalah berbeza daripada pengedaran latihan, khususnya dalam LM cenderung untuk menjana program yang lebih pendek daripada yang terdapat dalam set latihan (dan masih betul). Walaupun keupayaan LM untuk mensintesis program yang betul telah bertambah baik, kebingungan LM terhadap program dalam set latihan kekal tinggi, menunjukkan bahawa hipotesis H1 adalah salah.
Secara keseluruhannya, kajian ini mencadangkan rangka kerja untuk mengkaji LM secara empirikal berdasarkan semantik bahasa pengaturcaraan. Pendekatan ini membolehkan kami mentakrif, mengukur dan bereksperimen dengan konsep daripada semantik formal yang tepat bagi bahasa pengaturcaraan asas, sekali gus menyumbang kepada pemahaman keupayaan muncul LM semasa.
Latar belakang penyelidikan
Penyelidikan ini menggunakan pengesanan semantik sebagai model makna program. Sebagai topik asas dalam teori bahasa pengaturcaraan, semantik formal mengkaji cara menetapkan semantik secara rasmi kepada rentetan dalam bahasa. Model semantik yang digunakan dalam kajian ini terdiri daripada mengesan pelaksanaan program: diberikan satu set input (iaitu tugasan pembolehubah), makna program (sintaktik) dikenal pasti dengan nilai semantik yang dikira daripada ungkapan, dan jejak dilaksanakan berdasarkan input Urutan nilai perantaraan yang dihasilkan oleh program.
Terdapat beberapa sebab penting untuk menggunakan trajektori pengesanan untuk model makna program: pertama, keupayaan untuk mengesan sekeping kod dengan tepat berkaitan secara langsung dengan keupayaan untuk mentafsir kod; pendidikan sains komputer juga menekankan pengesanan Ia merupakan kaedah penting untuk memahami pembangunan program dan mengesan ralat penaakulan ketiga, pembangunan program profesional bergantung pada penyahpepijat berasaskan pengesanan (dbugger).
Set latihan yang digunakan dalam kajian ini mengandungi 1 juta program Karel sampel rawak. Pada tahun 1970-an, lulusan Universiti Stanford Rich Pattis mereka bentuk persekitaran pengaturcaraan yang membolehkan pelajar mengajar robot untuk menyelesaikan masalah mudah Robot itu dipanggil robot Karel.
Kajian ini membina program rujukan sampel latihan melalui persampelan rawak, kemudian mengambil sampel 5 input rawak dan melaksanakan program untuk mendapatkan 5 output yang sepadan. LM dilatih untuk melakukan ramalan token seterusnya pada korpus sampel. Pada masa ujian, kajian ini hanya menyediakan awalan input dan output kepada LM dan menggunakan penyahkodan tamak untuk melengkapkan program. Rajah 1 di bawah menggambarkan penyiapan program rujukan sebenar dan LM terlatih.
Kajian ini melatih model Transformer siap pakai untuk melaksanakan ramalan token seterusnya pada set data. Selepas 64,000 langkah latihan dan kira-kira 1.5 zaman, LM yang dilatih akhirnya mencapai ketepatan penjanaan 96.4% pada set ujian. Setiap 2000 langkah latihan, kajian itu menangkap set data surih. Bagi setiap set data trajektori latihan, kajian ini melatih pengesan linear untuk meramalkan keadaan program yang diberikan keadaan model.
Kemunculan makna
Para penyelidik mengkaji hipotesis berikut: Dalam proses melatih model bahasa untuk melaksanakan ramalan token seterusnya, perwakilan keadaan semantik akan produk sampingan Muncul dalam keadaan model. Memandangkan model bahasa terlatih terakhir mencapai ketepatan penjanaan 96.4%, jika hipotesis ini ditolak, ia akan konsisten dengan H2, iaitu model bahasa telah belajar menggunakan statistik permukaan "hanya" untuk menjana program yang betul secara konsisten.
Untuk menguji hipotesis ini, penyelidik melatih pengesan linear untuk mengekstrak keadaan semantik daripada keadaan model sebagai 5 tugas 4 hala bebas (setiap berorientasikan input satu arah), seperti yang diterangkan. dalam Bahagian 2.2.
Maksud kemunculan dikaitkan secara positif dengan ketepatan penjanaan
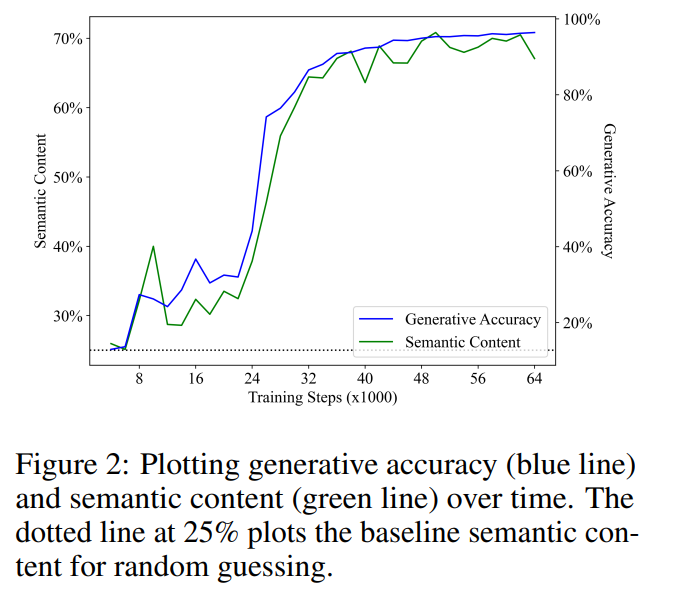
Rajah 2 menunjukkan keputusan utama. Pemerhatian pertama kami ialah kandungan semantik bermula daripada prestasi asas meneka rawak (25%) dan meningkat dengan ketara semasa latihan. Keputusan ini menunjukkan bahawa keadaan tersembunyi model bahasa sememangnya mengandungi pengekodan (linear) bagi keadaan semantik, dan yang paling penting, makna ini muncul dalam model bahasa yang digunakan semata-mata untuk melaksanakan ramalan token seterusnya pada teks.
Regresi linear bagi ketepatan penjanaan dan kandungan semantik menunjukkan korelasi linear yang kukuh dan ketara secara statistik semasa langkah latihan (R2 = 0.968, p < ; 0.001), iaitu variasi dalam LM keupayaan untuk mensintesis program yang betul hampir sepenuhnya dijelaskan oleh kandungan semantik lapisan tersembunyi LM. Ini menunjukkan bahawa, dalam skop persediaan percubaan kami, pembelajaran untuk memodelkan pengedaran program yang betul berkaitan secara langsung dengan makna program yang dipelajari, yang menafikan idea bahawa model bahasa tidak dapat menangkap makna (H2).
Perwakilan ialah ramalan semantik program masa hadapan
Bahagian sebelumnya membincangkan sama ada model bahasa boleh mewakili makna teks yang dihasilkannya. Hasil kertas kerja ini memberikan jawapan positif kepada persoalan bahawa model bahasa mampu (secara abstrak) menerangkan program yang dihasilkan. Walau bagaimanapun, jurubahasa tidak sama dengan pensintesis, dan keupayaan untuk memahami sahaja tidak mencukupi untuk menjana. Setakat kemunculan bahasa manusia, terdapat konsensus luas bahawa bahasa berasal daripada mesej bukan lisan dalam minda dan kemudian berubah menjadi ujaran yang mencerminkan konsep asal. Pengkaji membuat hipotesis bahawa proses penjanaan model bahasa terlatih mengikut mekanisme yang sama, iaitu perwakilan model bahasa mengekod semantik teks yang masih belum dihasilkan.
Untuk menguji hipotesis ini, mereka melatih pengesan linear menggunakan kaedah yang sama seperti di atas untuk meramalkan keadaan semantik masa hadapan yang diperoleh daripada keadaan model. Ambil perhatian bahawa memandangkan mereka menggunakan strategi penyahkodan yang tamak, keadaan semantik masa depan juga bersifat deterministik dan oleh itu tugas itu ditakrifkan dengan baik.
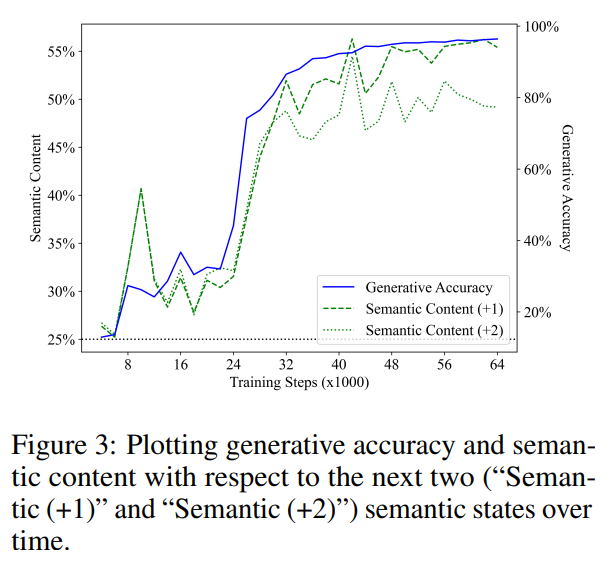
Rajah 3 menunjukkan prestasi pengesan linear dalam meramalkan keadaan semantik langkah 1 dan 2 pada masa hadapan (garis segmen hijau mewakili "Semantik (+1)", titik hijau baris mewakili "Semantik (+2)"). Sama seperti keputusan sebelumnya, prestasi pengesan bermula dari garis dasar meneka rawak dan kemudian bertambah baik dengan ketara dengan latihan, dan mereka juga mendapati bahawa kandungan semantik keadaan masa hadapan menunjukkan korelasi yang kuat dengan ketepatan penjanaan (garis biru) semasa langkah latihan. seks. Nilai R2 yang diperolehi oleh analisis regresi linear kandungan semantik dan ketepatan penjanaan masing-masing adalah 0.919 dan 0.900, sepadan dengan status semantik 1 langkah dan 2 langkah pada masa hadapan, dan nilai p kedua-duanya adalah kurang daripada 0.001.
Mereka juga menganggap andaian bahawa perwakilan model hanya mengekod keadaan semantik semasa, dan pengesan hanya bermula dari keadaan semantik semasa Ramalkan semantik masa hadapan negeri. Untuk menguji hipotesis ini, mereka mengira pengelas optimum yang memetakan kebenaran tanah menghadap arah dalam program semasa kepada salah satu daripada 4 arah menghadap dalam program akan datang.
Perlu diambil perhatian bahawa 3 daripada 5 operasi mengekalkan arah menghadap, dan token seterusnya diambil secara seragam. Oleh itu, mereka menjangkakan bahawa, untuk situasi 1 melangkah ke masa hadapan, pengelas optimum untuk meramalkan keadaan semantik masa depan harus mencapai ketepatan 60% dengan meramalkan bahawa arah menghadap kekal tidak berubah. Malah, dengan menyesuaikan set ujian secara langsung, mereka mendapati bahawa had atas meramalkan keadaan semantik masa hadapan daripada keadaan semantik semasa ialah 62.2% dan 40.7%, masing-masing (bersamaan dengan kes 1 dan 2 langkah ke masa hadapan). Sebagai perbandingan, pengesan adalah 68.4% dan 61.0% tepat pada meramalkan keadaan masa hadapan, memandangkan pengesan meramalkan keadaan semasa dengan betul.
Ini menunjukkan bahawa keupayaan pengesan untuk mengekstrak keadaan semantik masa hadapan daripada keadaan model tidak boleh disimpulkan semata-mata daripada perwakilan keadaan semantik semasa. Oleh itu, keputusan mereka menunjukkan bahawa model bahasa belajar untuk mewakili makna token yang belum dihasilkan, yang menolak idea bahawa model bahasa tidak dapat mempelajari makna (H2), dan juga menunjukkan bahawa proses penjanaan tidak berdasarkan statistik permukaan semata-mata. (H1).
Output yang dihasilkan adalah berbeza daripada pengedaran latihan
Seterusnya, penyelidik memberikan sanggahan dengan membandingkan pengedaran program yang dihasilkan oleh model bahasa terlatih dengan pengedaran program dalam set latihan Bukti untuk H1. Jika H1 memegang, mereka menjangkakan bahawa kedua-dua pengedaran harus kira-kira sama kerana model bahasa hanya mengulangi korelasi statistik teks dalam set latihan.
Rajah 6a menunjukkan purata panjang program yang dijana LM dari semasa ke semasa (garis biru pepejal), berbanding dengan purata panjang program rujukan dalam set latihan (garisan merah putus-putus) kontras . Mereka mendapati perbezaan yang ketara secara statistik, menunjukkan bahawa pengagihan output LM sememangnya berbeza daripada pengagihan program dalam set latihannya. Ini bercanggah dengan perkara yang dinyatakan dalam H1 bahawa LM hanya boleh meniru korelasi statistik dalam data latihannya.
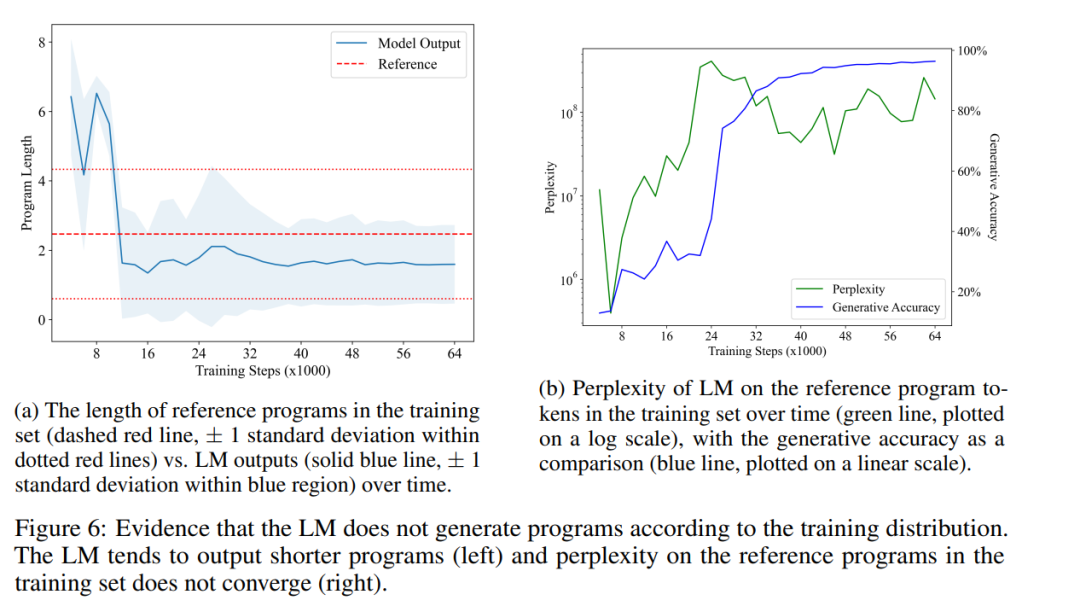
Akhirnya, mereka juga mengukur bagaimana kekeliruan LM pada program dalam set latihan berubah dari semasa ke semasa. Rajah 6b menunjukkan keputusannya. Seperti yang dapat dilihat, LM tidak pernah belajar untuk menyesuaikan agihan program dalam set latihan dengan baik, yang seterusnya menafikan H1. Ini mungkin kerana program sampel rawak dalam set latihan mengandungi banyak arahan tanpa operasi, manakala LM lebih suka menjana program yang lebih ringkas. Menariknya, peningkatan mendadak dalam kebingungan—apabila LM bergerak melangkaui peringkat peniruan—nampaknya membawa kepada peningkatan dalam ketepatan penjanaan (dan kandungan semantik). Memandangkan masalah kesetaraan program berkait rapat dengan semantik program, keupayaan LM untuk menjana atur cara yang pendek dan betul menunjukkan bahawa ia sememangnya telah mempelajari beberapa aspek semantik.
Untuk butiran, sila rujuk kertas asal.
Atas ialah kandungan terperinci Terdapat bukti MIT menunjukkan bahawa model bahasa besar ≠ burung kakak tua secara rawak memang boleh mempelajari semantik.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI