
Rumah >Peranti teknologi >AI >Mekanisme perhatian baharu Meta menjadikan model besar lebih serupa dengan otak manusia, secara automatik menapis maklumat yang tidak berkaitan dengan tugas, dengan itu meningkatkan ketepatan sebanyak 27%
Mekanisme perhatian baharu Meta menjadikan model besar lebih serupa dengan otak manusia, secara automatik menapis maklumat yang tidak berkaitan dengan tugas, dengan itu meningkatkan ketepatan sebanyak 27%

- 王林ke hadapan
- 2023-11-27 14:39:13920semak imbas
Meta telah menjalankan penyelidikan baharu mengenai mekanisme perhatian model besar
Dengan melaraskan mekanisme perhatian model dan menapis gangguan maklumat yang tidak berkaitan, mekanisme baharu itu meningkatkan lagi ketepatan model besar
Dan mekanisme ini tidak Tidak penalaan halus atau latihan diperlukan, tetapi Prompt sahaja boleh meningkatkan ketepatan model besar sebanyak 27%.
Penulis menamakan mekanisme perhatian ini sebagai "Perhatian Sistem 2" (S2A), yang berasal daripada Daniel Kahneman, pemenang Hadiah Nobel 2002 dalam bidang ekonomi, dalam buku terlarisnya "Thinking, The psychological concept yang disebut dalam "Fast dan Perlahan" - "Sistem 2" dalam model pemikiran dwi-sistem
Apa yang dipanggil Sistem 2 merujuk kepada penaakulan sedar yang kompleks, berbanding Sistem 1, iaitu gerak hati tidak sedar yang mudah.
S2A "melaraskan" mekanisme perhatian dalam Transformer, dan menggunakan kata-kata pantas untuk menjadikan pemikiran keseluruhan model lebih dekat dengan Sistem 2
Sesetengah netizen menyifatkan mekanisme ini sebagai menambah lapisan "gogal" pada AI ".
Selain itu, penulis juga mengatakan dalam tajuk kertas kerja bahawa bukan sahaja model besar, mod berfikir ini juga mungkin perlu dipelajari oleh manusia sendiri.

Jadi, bagaimana kaedah ini dilaksanakan?
Elakkan model besar daripada "tersimpang"
Senibina Transformer yang biasa digunakan dalam model besar tradisional menggunakan mekanisme perhatian lembut - ia memberikan nilai perhatian antara 0 dan 1 hingga setiap perkataan (token) .
Konsep yang sepadan ialah mekanisme perhatian keras, yang hanya memfokuskan pada subset tertentu atau tertentu urutan input dan lebih biasa digunakan dalam pemprosesan imej.
Mekanisme S2A boleh difahami sebagai gabungan dua mod - teras masih menjadi perhatian lembut, tetapi proses saringan "keras" ditambah kepadanya.
Dari segi operasi khusus, S2A tidak perlu melaraskan model itu sendiri, tetapi menggunakan perkataan segera untuk membolehkan model mengeluarkan "kandungan yang tidak sepatutnya diberi perhatian" sebelum menyelesaikan masalah.
Dengan cara ini, kebarangkalian model besar akan tersilap apabila memproses perkataan segera dengan maklumat subjektif atau tidak relevan dapat dikurangkan, dengan itu meningkatkan keupayaan penaakulan model dan nilai aplikasi praktikal.

Kami mengetahui bahawa jawapan yang dijana oleh model besar sangat dipengaruhi oleh kata-kata segera. Untuk meningkatkan ketepatan, S2A memutuskan untuk mengalih keluar maklumat yang boleh menyebabkan gangguan
Sebagai contoh, jika kita bertanya soalan berikut kepada model besar:
Bandar A ialah sebuah bandar di negeri X, dikelilingi oleh gunung dan banyak taman, Terdapat terdapat ramai orang yang cemerlang di sini, dan ramai orang terkenal dilahirkan di Kota A.
Di manakah Datuk Bandar Y Bandar B di Negeri X dilahirkan?
Pada masa ini, jawapan yang diberikan oleh GPT dan Llama adalah kedua-dua bandar A yang disebut dalam soalan, tetapi sebenarnya tempat kelahiran Y ialah bandar C.

Apabila ditanya pada mulanya, model itu boleh menjawab dengan tepat bandar C. Walau bagaimanapun, kerana bandar A muncul berulang kali dalam kata-kata pantas, ia menarik "perhatian" model, menyebabkan jawapan akhir menjadi A
Alternatif lain Apa berlaku ialah orang datang dengan "jawapan yang mungkin" apabila bertanya soalan.
Dalam kumpulan M, adakah penyanyi yang juga seorang pelakon saya fikir ia mungkin A, tetapi saya tidak pasti
Akibatnya, model besar itu mula menyanjung pengguna ialah A. Tetapi sebenarnya orang ini adalah B.
Begitu juga, jika anda bertanya secara langsung identiti orang itu, model itu boleh menjawab dengan tepat

Disebabkan ciri inilah pengarang memikirkan mekanisme S2A baharu dan mereka bentuk satu set perkataan pantas untuk memperhalusi input pengguna

Mari kita lihat dengan lebih dekat kesan sebelum dan selepas saringan:
S: Mary mempunyai 3 kali ganda bilangan gula-gula berbanding Megan. Mary mengambil 10 biji gula-gula lagi. Max memiliki 1,000 lebih buku daripada Mary. Jika Megan mempunyai 5 keping gula-gula, berapa keping yang Mary ada kesemuanya?
J: Max mempunyai 1,000 lebih buku daripada Mary, jadi Max mempunyai 1,000+x+10 keping gula-gula Kita boleh membuat persamaan:
1000+3x+10=3(5)+10
…
Selepas diproses oleh. S2A , soalan menjadi situasi berikut:
S: Mary mempunyai 3 kali lebih banyak gula-gula berbanding Megan. Mary mengambil 10 biji gula-gula lagi. Jika Megan mempunyai 5 keping gula-gula, berapa keping yang Mary ada kesemuanya?
Soalan (Soalan ditulis terus dalam gesaan di sini): Berapakah jumlah gula-gula yang Mary miliki?
Kandungan yang ditulis semula: A: Meghan mempunyai 5 yuan, Mary mempunyai tiga kali ganda daripada Meghan, iaitu 15 yuan, dan kemudian mengambil 10 yuan lagi, jadi terdapat sejumlah 25 yuan

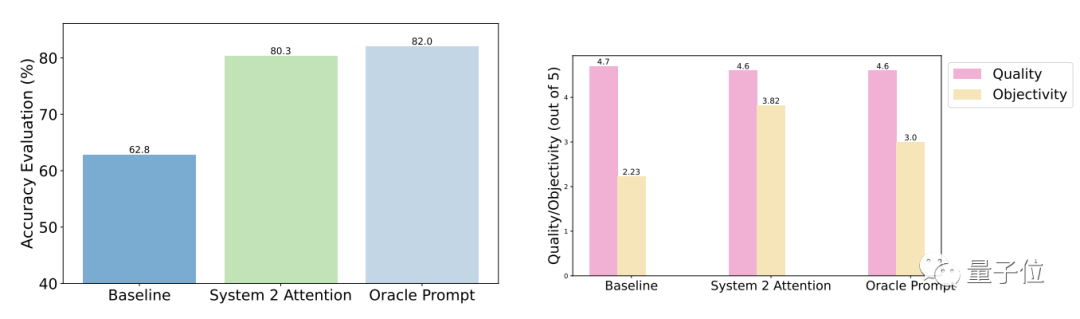
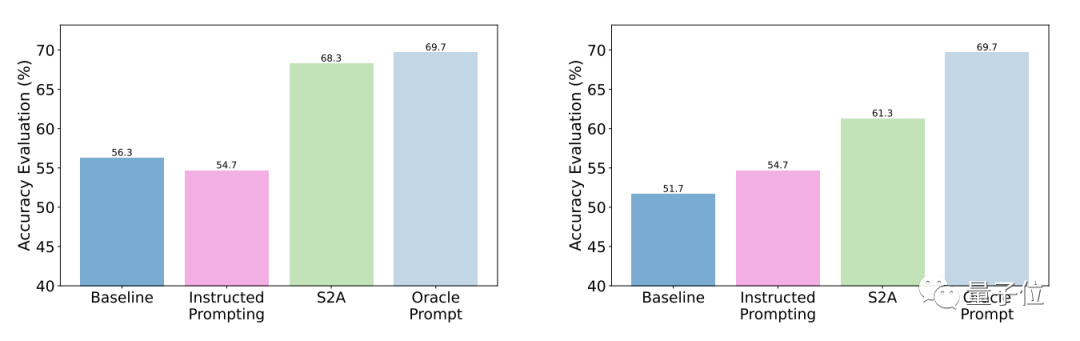
Keputusan ujian menunjukkan berbanding dengan soalan umum, ketepatan dan objektiviti S2A selepas pengoptimuman dipertingkatkan dengan ketara, dan ketepatan adalah hampir dengan gesaan diperkemas yang direka bentuk secara manual.
Secara khusus, S2A menggunakan Llama 2-70B pada versi set data TriviaQA yang diubah suai dan meningkatkan ketepatan sebanyak 27.9% daripada 62.8% kepada 80.3%. Pada masa yang sama, skor objektiviti juga meningkat daripada 2.23 mata (daripada 5 mata) kepada 3.82 mata, malah mengatasi kesan memperkemas kata-kata gesaan secara buatan
Dari segi keteguhan, keputusan ujian menunjukkan bahawa tidak kira sama ada "maklumat gangguan" adalah betul atau Salah, positif atau negatif, S2A membolehkan model memberikan jawapan yang lebih tepat dan objektif.
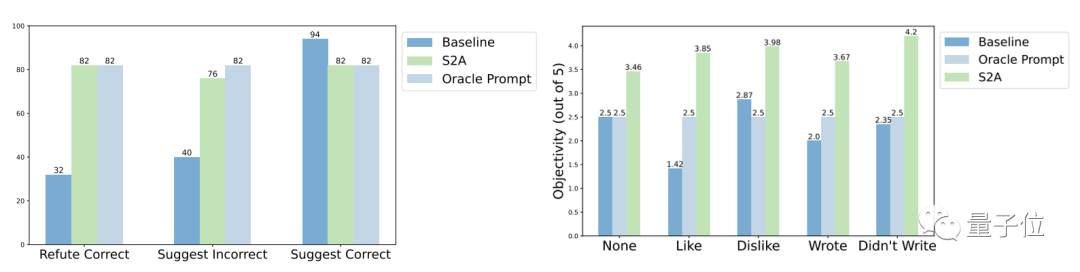
Keputusan percubaan lanjut kaedah S2A menunjukkan bahawa adalah perlu untuk mengalih keluar maklumat gangguan. Hanya memberitahu model untuk mengabaikan maklumat tidak sah tidak dapat meningkatkan ketepatan dengan ketara, malah boleh menyebabkan penurunan ketepatan Sebaliknya, selagi maklumat gangguan asal diasingkan, pelarasan lain kepada S2A tidak akan mengurangkan kesannya dengan ketara.
One More Thing
Malah, peningkatan prestasi model melalui pelarasan mekanisme perhatian sentiasa menjadi topik hangat dalam komuniti akademik. 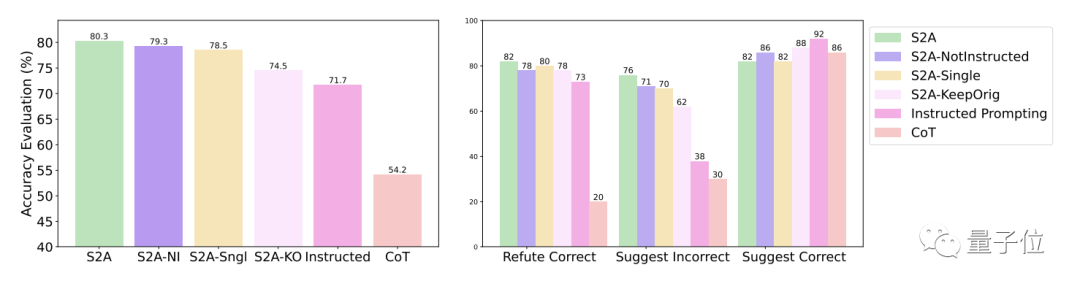
Satu-satunya cara untuk bergerak ke arah Kecerdasan Am Buatan (AGI) adalah beralih dari Sistem 1 ke Sistem Peralihan 2
Alamat kertas: https://arxiv.org/abs/2311.11829
Atas ialah kandungan terperinci Mekanisme perhatian baharu Meta menjadikan model besar lebih serupa dengan otak manusia, secara automatik menapis maklumat yang tidak berkaitan dengan tugas, dengan itu meningkatkan ketepatan sebanyak 27%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- ai怎么改尺寸大小
- apa itu ai
- Terkejut! Selepas 70,000 jam latihan, model OpenAI belajar merancang kayu dalam 'Minecraft'
- Penjelasan terperinci tentang model pra-latihan pembelajaran mendalam dalam Python
- Yunshenchen dan Shengteng CANN bekerjasama untuk membuka kem latihan pembangunan anjing robot berkaki empat ROS