
Rumah >Peranti teknologi >AI >Teknologi baharu Adobe: Ia hanya mengambil masa 30 saat untuk menjana imej 3D dengan A100, menjadikan teks dan imej bergerak
Teknologi baharu Adobe: Ia hanya mengambil masa 30 saat untuk menjana imej 3D dengan A100, menjadikan teks dan imej bergerak

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-11-27 14:29:18923semak imbas
Pengenalan model resapan 2D telah memudahkan proses penciptaan kandungan imej dan membawa inovasi kepada industri reka bentuk 2D. Dalam beberapa tahun kebelakangan ini, model penyebaran ini telah berkembang menjadi penciptaan 3D, mengurangkan kos buruh dalam aplikasi seperti VR, AR, robotik dan permainan. Banyak kajian telah mula meneroka penggunaan model resapan 2D yang telah terlatih, serta kaedah NeRF yang menggunakan kehilangan Pensampelan Penyulingan Berskor (SDS). Walau bagaimanapun, kaedah berasaskan SDS biasanya memerlukan pengoptimuman sumber berjam-jam dan sering menyebabkan masalah geometri dalam grafik, seperti masalah Janus pelbagai segi
Sebaliknya, penyelidik boleh mencapai ini tanpa menghabiskan banyak masa untuk mengoptimumkan setiap sumber Pelbagai percubaan juga telah dibuat untuk mempelbagaikan model penyebaran 3D yang dihasilkan. Kaedah ini biasanya memerlukan mendapatkan model 3D/awan titik yang mengandungi data sebenar untuk latihan. Walau bagaimanapun, untuk imej sebenar, data latihan sedemikian sukar diperoleh. Memandangkan kaedah resapan 3D semasa biasanya berdasarkan latihan dua peringkat, ini menghasilkan ruang terpendam yang kabur dan sukar untuk didenoise pada set data 3D yang sangat pelbagai dan tidak dikelaskan, menjadikan pemaparan berkualiti tinggi sebagai cabaran yang mendesak.
Untuk menyelesaikan masalah ini, beberapa penyelidik telah mencadangkan model satu peringkat, tetapi kebanyakan model ini hanya menyasarkan kategori mudah tertentu dan mempunyai generalisasi yang lemah Oleh itu, matlamat penyelidik dalam artikel ini adalah untuk mencapai cepat, Penjanaan 3D yang realistik dan serba boleh. Untuk tujuan ini, mereka mencadangkan DMV3D. DMV3D ialah model penyebaran semua kategori peringkat tunggal baharu yang boleh menjana NeRF 3D secara langsung berdasarkan input teks model atau imej tunggal. Hanya dalam 30 saat pada GPU A100 tunggal, DMV3D boleh menjana pelbagai imej 3D kesetiaan tinggi.
 Khususnya, DMV3D ialah model resapan imej berbilang paparan 2D yang menyepadukan pembinaan semula dan pemaparan NeRF 3D ke dalam denoisernya dan dilatih dengan cara penyeliaan hujung ke hujung tanpa penyeliaan terus. Melakukannya mengelakkan masalah yang mungkin timbul dalam melatih pengekod NeRF 3D secara berasingan untuk penyebaran ruang terpendam (cth. model dua peringkat) dan kaedah yang membosankan untuk mengoptimumkan setiap objek (cth. SDS)
Khususnya, DMV3D ialah model resapan imej berbilang paparan 2D yang menyepadukan pembinaan semula dan pemaparan NeRF 3D ke dalam denoisernya dan dilatih dengan cara penyeliaan hujung ke hujung tanpa penyeliaan terus. Melakukannya mengelakkan masalah yang mungkin timbul dalam melatih pengekod NeRF 3D secara berasingan untuk penyebaran ruang terpendam (cth. model dua peringkat) dan kaedah yang membosankan untuk mengoptimumkan setiap objek (cth. SDS)
Intipati kaedah dalam kertas kerja ini. ialah pembinaan semula 3D berdasarkan rangka kerja resapan berbilang pandangan 2D. Pendekatan ini diilhamkan oleh kaedah RenderDiffusion, kaedah untuk penjanaan 3D melalui penyebaran pandangan tunggal. Walau bagaimanapun, had kaedah RenderDiffusion ialah data latihan memerlukan pengetahuan awal tentang kategori tertentu, dan objek dalam data memerlukan sudut atau pose tertentu, jadi generalisasinya adalah lemah dan ia tidak boleh menjana 3D untuk sebarang jenis objek
Menurut penyelidik, sebagai perbandingan, hanya satu set empat unjuran jarang berbilang pandangan yang mengandungi objek diperlukan untuk menerangkan objek 3D yang tidak terhalang. Data latihan ini berasal daripada imaginasi spatial manusia, yang membolehkan orang ramai membina objek 3D yang lengkap daripada pandangan satah di sekeliling beberapa objek. Imaginasi ini biasanya sangat tepat dan spesifik Namun, apabila menggunakan input ini, tugas pembinaan semula 3D di bawah pandangan jarang masih perlu diselesaikan. Ini adalah masalah lama yang sangat mencabar walaupun inputnya bising
Kaedah kami mampu mencapai penjanaan 3D berdasarkan satu imej/teks. Untuk input imej, mereka menetapkan pandangan yang jarang sebagai input bebas hingar dan melakukan denoising pada paparan lain yang serupa dengan lukisan imej 2D. Untuk mencapai penjanaan 3D berasaskan teks, penyelidik menggunakan keadaan teks berasaskan perhatian dan pengelas bebas jenis yang biasa digunakan dalam model resapan 2D.
Mereka hanya menggunakan penyeliaan ruang imej semasa latihan dan menggunakan set data besar yang terdiri daripada imej yang disintesis Objaverse dan imej tangkapan sebenar MVImgNet. Mengikut keputusan, DMV3D telah mencapai tahap SOTA dalam pembinaan semula 3D imej tunggal, mengatasi kaedah berasaskan SDS dan model penyebaran 3D sebelumnya. Selain itu, kaedah penjanaan model 3D berasaskan teks juga lebih baik daripada kaedah sebelumnya
Alamat kertas: https://arxiv.org/pdf/2311.09217.pdf
 Laman web rasmi alamat: https://justimyhxu.github.io/projects/dmv3d/
Laman web rasmi alamat: https://justimyhxu.github.io/projects/dmv3d/
- Mari kita lihat kesan imej 3D yang dihasilkan.

Gambaran keseluruhan kaedah
Bagaimana untuk melatih dan membuat kesimpulan model penyebaran 3D satu peringkat?
Para penyelidik mula-mula memperkenalkan rangka kerja resapan baharu yang menggunakan denoiser berasaskan pembinaan semula untuk menafikan imej berbilang paparan yang bising untuk penjanaan 3D. Kedua, mereka mencadangkan denoiser berbilang paparan berdasarkan LRM yang bersyarat pada resapan; langkah masa, dengan itu secara beransur-ansur menafikan imej berbilang paparan melalui pembinaan semula dan pemaparan 3D NeRF akhirnya, model itu disebarkan lagi untuk menyokong pelarasan teks dan imej, mencapai penjanaan kebolehkawalan.
Kandungan yang perlu ditulis semula ialah: resapan dan denoising berbilang paparan. Kandungan yang ditulis semula: Resapan pandangan berbilang sudut dan pengurangan hingar
Resapan berbilang pandangan. Pengedaran x_0 asal yang diproses dalam model resapan 2D ialah pengedaran imej tunggal dalam set data. Sebaliknya, kami mempertimbangkan pengedaran bersama imej berbilang paparan
, di mana setiap kumpulan ialah pemerhatian imej pemandangan 3D (aset) yang sama dari sudut pandangan C = {c_1, .. ., c_N}. Proses resapan adalah bersamaan dengan melakukan operasi resapan pada setiap imej secara bebas menggunakan jadual hingar yang sama, seperti yang ditunjukkan dalam persamaan (1) di bawah. Denoising berasaskan pembinaan semula. Songsangan proses resapan 2D pada asasnya adalah denoising. Dalam makalah ini, penyelidik mencadangkan untuk menggunakan pembinaan semula dan pemaparan 3D untuk mencapai denoising imej berbilang paparan 2D sambil mengeluarkan model 3D yang bersih untuk penjanaan 3D. Khususnya, mereka menggunakan modul pembinaan semula 3D E (・) untuk membina semula perwakilan 3D S daripada imej berbilang paparan yang bising
, dan menggunakan modul pemaparan boleh dibezakan R (・) untuk memaparkan imej ternyah, seperti yang ditunjukkan dalam yang berikut formula (2) seperti yang ditunjukkan. Penyusun berbilang pandangan berasaskan pembinaan semula
Para penyelidik membina denoiser berbilang pandangan berdasarkan LRM dan menggunakan tiga model bunyi bising pengubah untuk membersihkan semula -pesawat NeRF dijana, dan kemudian pemaparan NeRF tiga satah yang dibina semula digunakan sebagai output ternyah.
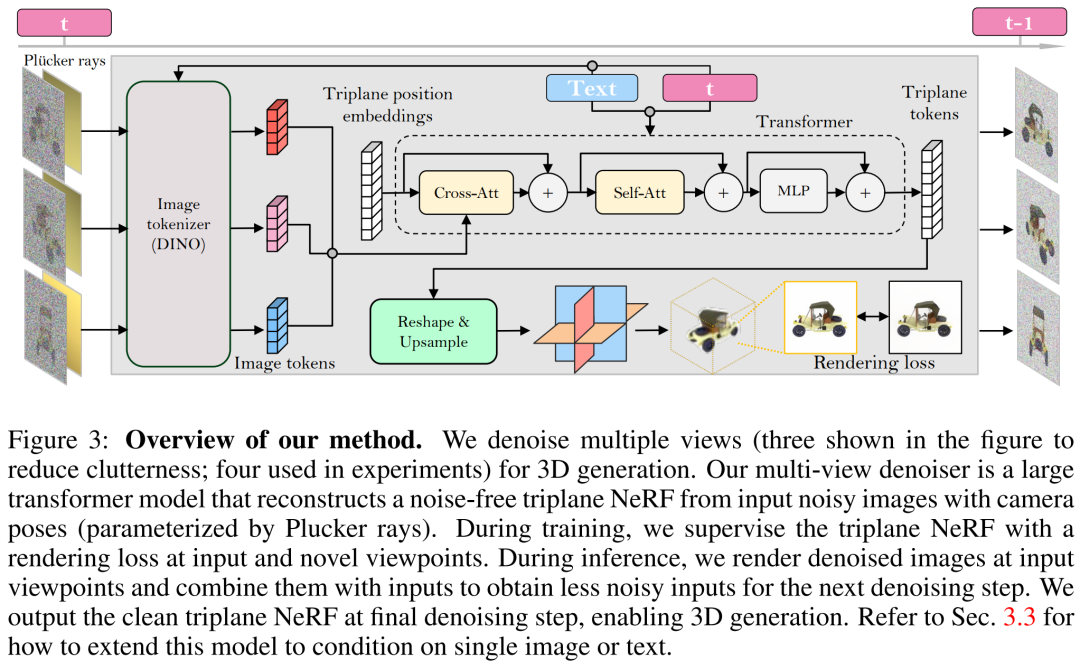
Pembinaan semula dan rendering. Seperti yang ditunjukkan dalam Rajah 3 di bawah, penyelidik menggunakan Pengubah Penglihatan (DINO) untuk menukar imej input
kepada token 2D, dan kemudian menggunakan pengubah untuk memetakan kedudukan tiga satah yang dipelajari yang dibenamkan kepada tiga satah terakhir untuk mewakili perwakilan 3D bagi bentuk dan rupa. Tiga satah yang diramalkan seterusnya digunakan untuk menyahkod ketumpatan volum dan warna melalui MLP untuk pemaparan volum boleh dibezakan. Pelarasan masa. Berbanding dengan DDPM (Denoising Diffusion Probabilistic Model) berasaskan CNN, model berasaskan pengubah kami memerlukan reka bentuk pelarasan temporal yang berbeza.
Apabila melatih model dalam artikel ini, penyelidik menegaskan bahawa pada set data parameter intrinsik dan ekstrinsik kamera yang sangat pelbagai (seperti MVImgNet), pelarasan kamera input perlu direka bentuk dengan berkesan untuk membantu model memahami kamera dan melakukan Penaakulan 3D
Apabila menulis semula kandungan, anda perlu menukar bahasa teks asal kepada bahasa Cina, tetapi makna teks asal tidak berubah
Kaedah di atas membolehkan model yang dicadangkan oleh penyelidik berfungsi sebagai model generatif tanpa syarat. Mereka menerangkan cara memanfaatkan penyebut bersyarat
untuk memodelkan taburan kebarangkalian bersyarat, dengan y mewakili teks atau imej, untuk mencapai penjanaan 3D yang boleh dikawal. Dari segi pelaziman imej, para penyelidik mencadangkan strategi yang mudah dan berkesan yang tidak memerlukan pengubahsuaian pada seni bina model
Pengkondisian teks. Untuk menambah pelaziman teks pada model mereka, para penyelidik menggunakan strategi yang serupa dengan Stable Diffusion. Mereka menggunakan pengekod teks CLIP untuk menjana pembenaman teks dan menyuntiknya ke dalam denoiser menggunakan perhatian silang.
Isi kandungan yang perlu ditulis semula ialah: latihan dan inferens
latihan. Semasa fasa latihan, kami mencuba langkah masa t secara seragam dalam julat [1, T] dan menambah hingar mengikut penjadualan kosinus. Mereka mencuba imej input menggunakan pose kamera rawak dan juga secara rawak mencuba sudut pandangan baharu tambahan untuk menyelia pemaparan untuk kualiti yang lebih baik.
Pengkaji menggunakan isyarat bersyarat y untuk meminimumkan objektif latihan
inferens. Semasa fasa inferens, kami memilih sudut pandangan yang mengelilingi objek secara sekata dalam bulatan untuk memastikan liputan yang baik bagi aset 3D yang terhasil. Mereka menetapkan sudut pasaran kamera pada 50 darjah untuk empat pandangan.
Hasil eksperimen
Dalam eksperimen, penyelidik menggunakan pengoptimum AdamW untuk melatih model mereka dengan kadar pembelajaran awal 4e^-4. Mereka menggunakan 3K langkah memanaskan badan dan pereputan kosinus untuk kadar pembelajaran ini, menggunakan imej input 256×256 untuk melatih model denoising dan menggunakan imej terpotong 128×128 untuk pemaparan diselia
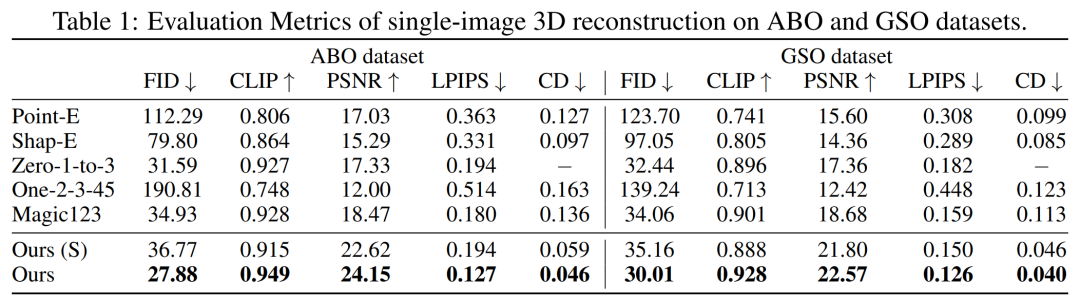
Mengenai set data yang diperlukan Ditulis semula sebagai: model penyelidik hanya perlu dilatih menggunakan imej pose berbilang pandangan. Oleh itu, mereka menggunakan imej berbilang paparan yang dihasilkan kira-kira 730k objek daripada set data Objaverse. Untuk setiap objek, mereka melakukan 32 paparan imej pada sudut pandangan rawak dengan FOV 50 darjah tetap dan pencahayaan seragam mengikut tetapan LRM Pertama, pembinaan semula imej tunggal. Para penyelidik membandingkan model penyaman imej mereka dengan kaedah sebelumnya seperti Point-E, Shap-E, Zero-1-to-3, dan Magic123 pada satu tugas pembinaan semula imej. Mereka menggunakan metrik seperti PSNR, LPIPS, skor persamaan CLIP dan FID untuk menilai kualiti pemaparan paparan baharu bagi semua kaedah.
Keputusan kuantitatif pada set ujian GSO dan ABO ditunjukkan dalam Jadual 1 di bawah. Model kami mengatasi semua kaedah asas dan mencapai SOTA baharu untuk semua metrik pada kedua-dua set data
Hasil yang dijana oleh model kami mempunyai butiran geometri dan penampilan yang lebih baik daripada garis dasar Kualiti tinggi, hasil ini boleh ditunjukkan secara kualitatif melalui Rajah 4 DMV3D ialah model satu peringkat dengan imej 2D sebagai sasaran latihan Sebaliknya, ia tidak memerlukan pengoptimuman individu bagi setiap aset dan boleh menghapuskan bunyi meresap dan menjana model NeRF 3D secara langsung. Secara keseluruhannya, DMV3D mampu menjana imej 3D dengan pantas dan memperoleh hasil pembinaan semula 3D imej tunggal terbaik
Ditulis semula seperti berikut: Para penyelidik juga menilai DMV3D pada hasil penjanaan 3D berasaskan teks. Para penyelidik membandingkan DMV3D dengan Shap-E dan Point-E, yang juga menyokong penaakulan pantas merentas semua kategori. Para penyelidik membenarkan ketiga-tiga model ini menjana berdasarkan 50 gesaan teks daripada Shap-E, dan menggunakan ketepatan CLIP dan purata ketepatan dua model ViT yang berbeza untuk menilai hasil penjanaan, seperti yang ditunjukkan dalam Jadual 2Mengikut data dalam jadual, DMV3D menunjukkan ketepatan yang terbaik. Seperti yang dapat dilihat daripada keputusan kualitatif dalam Rajah 5, berbanding dengan keputusan yang dihasilkan oleh model lain, grafik yang dihasilkan oleh DMV3D jelas mengandungi butiran geometri dan rupa yang lebih kaya, dan hasilnya juga lebih realistik
Diperlukan untuk ditulis semula Ya: Keputusan lain
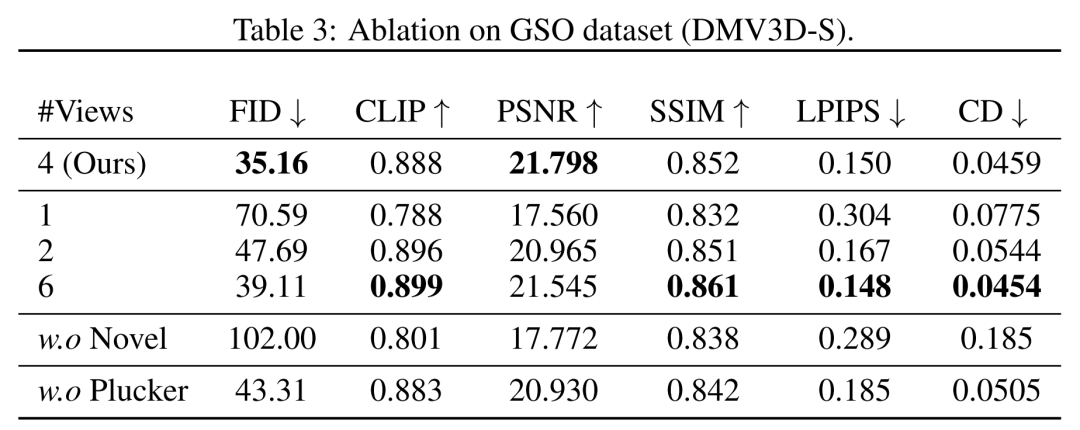
Dari segi pandangan, penyelidik menunjukkan perbandingan kuantitatif dan kualitatif model yang dilatih dengan bilangan paparan input yang berbeza (1, 2, 4, 6) dalam Jadual 3 dan Rajah 8.
Dari segi penjanaan berbilang contoh, sama dengan model resapan lain, model yang dicadangkan dalam contoh ini boleh menjana secara rawak dalam Rajah 1, yang menunjukkan Kebolehgeneralisasian keputusan yang dihasilkan oleh model.
DMV3D mempunyai fleksibiliti dan serba boleh yang luas dalam aplikasi, dan mempunyai potensi pembangunan yang kukuh dalam bidang aplikasi penjanaan 3D. Seperti yang ditunjukkan dalam Rajah 1 dan Rajah 2, kaedah artikel ini boleh mempromosikan objek sewenang-wenang dalam foto 2D kepada dimensi 3D dalam aplikasi penyuntingan imej melalui kaedah seperti segmentasi (seperti SAM)
Sila baca kertas asal untuk mengetahui lebih lanjut Banyak butiran teknikal dan keputusan percubaan


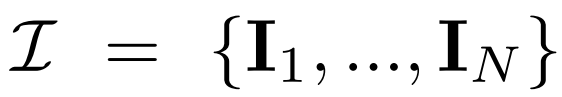
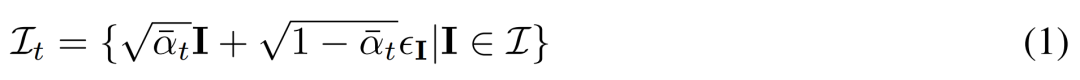
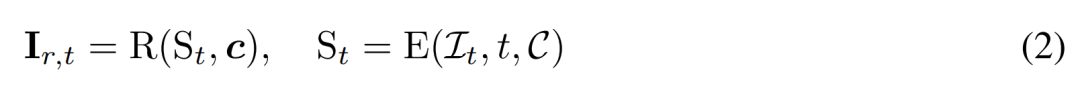
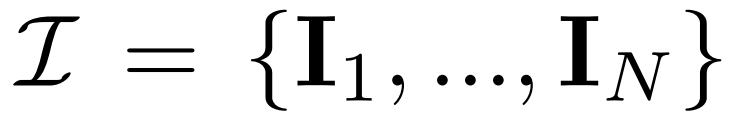
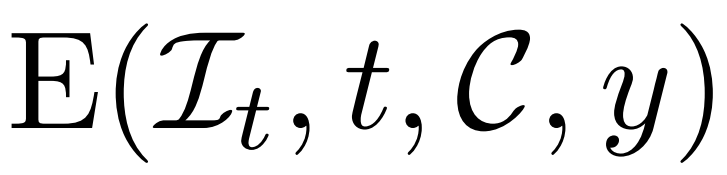
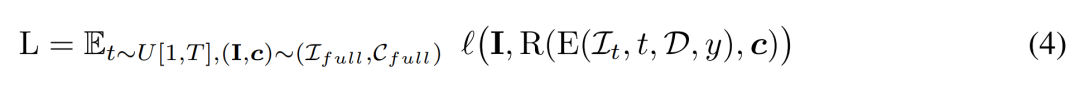
 Hasil yang dijana oleh model kami mempunyai butiran geometri dan penampilan yang lebih baik daripada garis dasar Kualiti tinggi, hasil ini boleh ditunjukkan secara kualitatif melalui Rajah 4
Hasil yang dijana oleh model kami mempunyai butiran geometri dan penampilan yang lebih baik daripada garis dasar Kualiti tinggi, hasil ini boleh ditunjukkan secara kualitatif melalui Rajah 4  Ditulis semula seperti berikut: Para penyelidik juga menilai DMV3D pada hasil penjanaan 3D berasaskan teks. Para penyelidik membandingkan DMV3D dengan Shap-E dan Point-E, yang juga menyokong penaakulan pantas merentas semua kategori. Para penyelidik membenarkan ketiga-tiga model ini menjana berdasarkan 50 gesaan teks daripada Shap-E, dan menggunakan ketepatan CLIP dan purata ketepatan dua model ViT yang berbeza untuk menilai hasil penjanaan, seperti yang ditunjukkan dalam Jadual 2
Ditulis semula seperti berikut: Para penyelidik juga menilai DMV3D pada hasil penjanaan 3D berasaskan teks. Para penyelidik membandingkan DMV3D dengan Shap-E dan Point-E, yang juga menyokong penaakulan pantas merentas semua kategori. Para penyelidik membenarkan ketiga-tiga model ini menjana berdasarkan 50 gesaan teks daripada Shap-E, dan menggunakan ketepatan CLIP dan purata ketepatan dua model ViT yang berbeza untuk menilai hasil penjanaan, seperti yang ditunjukkan dalam Jadual 2



Atas ialah kandungan terperinci Teknologi baharu Adobe: Ia hanya mengambil masa 30 saat untuk menjana imej 3D dengan A100, menjadikan teks dan imej bergerak. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!