
Rumah >Peranti teknologi >AI >Google: LLM tidak dapat mencari ralat inferens, tetapi boleh membetulkannya
Google: LLM tidak dapat mencari ralat inferens, tetapi boleh membetulkannya

- 王林ke hadapan
- 2023-11-27 14:39:201201semak imbas
Tahun ini, model bahasa besar (LLM) telah menjadi tumpuan ramai dalam bidang kecerdasan buatan. LLM telah mencapai kemajuan yang ketara dalam pelbagai tugas pemprosesan bahasa semula jadi (NLP), terutamanya dalam penaakulan. Walau bagaimanapun, pada tugas penaakulan yang kompleks, prestasi LLM masih perlu dipertingkatkan
Bolehkah LLM menentukan bahawa terdapat kesilapan dalam penaakulannya sendiri? Baru-baru ini, kajian yang dijalankan secara bersama oleh University of Cambridge dan Google Research mendapati bahawa LLM tidak dapat mengesan ralat penaakulan dengan sendirinya, tetapi ia boleh menggunakan kaedah backtracking yang dicadangkan dalam kajian untuk membetulkan ralat

- Alamat kertas: https://arxiv.org/pdf/2311.08516.pdf
- Alamat set data: https://github.com/WHGTyen/BIG-Bench-Mistake
beberapa kontroversi, seseorang membangkitkan bantahan terhadap perkara ini. Sebagai contoh, di Berita Hacker, seseorang mengulas bahawa tajuk kertas itu dibesar-besarkan dan sedikit clickbait. Yang lain mengkritik kaedah yang dicadangkan dalam kertas kerja untuk membetulkan kesilapan logik sebagai berdasarkan padanan pola dan bukannya menggunakan kaedah logik Kaedah ini terdedah kepada kegagalan
Huang et al namun" Tegaskan: Pembetulan kendiri mungkin berkesan dalam meningkatkan gaya dan kualiti keluaran model, tetapi terdapat sedikit bukti bahawa LLM mempunyai keupayaan untuk mengenal pasti dan membetulkan ralat penaakulan dan logiknya sendiri tanpa maklum balas luaran. Sebagai contoh, kedua-dua Refleks dan RCI menggunakan hasil pembetulan kebenaran asas sebagai isyarat untuk menghentikan kitaran pembetulan diri.
- Pasukan penyelidik dari University of Cambridge dan Google Research mencadangkan idea baharu: membahagikan proses pembetulan diri kepada dua peringkat: penemuan ralat dan pembetulan output
- Penemuan ralat ialah kemahiran penaakulan asas yang telah digunakan dalam Ia telah dikaji dan diaplikasikan secara meluas dalam bidang falsafah, psikologi dan matematik dan telah menimbulkan konsep seperti pemikiran kritis, logik dan kesilapan matematik. Adalah munasabah untuk menganggap bahawa keupayaan untuk mengesan ralat juga harus menjadi keperluan penting untuk LLM. Walau bagaimanapun, keputusan kami menunjukkan bahawa LLM tercanggih pada masa ini tidak dapat mengesan ralat dengan pasti.
Pembetulan output melibatkan pengubahsuaian separa atau lengkap output yang dijana sebelum ini. Pembetulan kendiri bermaksud pembetulan dilakukan oleh model yang sama yang menghasilkan output. Walaupun LLM tidak mempunyai keupayaan untuk mengesan ralat, kertas ini menunjukkan bahawa jika maklumat tentang ralat itu diberikan (seperti melalui model ganjaran kecil yang diselia), LLM boleh membetulkan output menggunakan kaedah penjejakan ke belakang.
- Sumbangan utama artikel ini termasuk:
- Menggunakan kaedah reka bentuk gesaan rantai pemikiran, sebarang tugas boleh diubah menjadi tugas penemuan pepijat. Untuk tujuan ini, penyelidik mengumpul dan mengeluarkan set data maklumat trajektori jenis CoT BIG-Bench Mistake, yang dijana oleh PaLM dan menandakan lokasi ralat logik pertama. Penyelidik mengatakan BIG-Bench Mistake ialah set data pertama seumpamanya yang tidak terhad kepada masalah matematik.
- Untuk menguji keupayaan inferens LLM terkini, penyelidik menanda arasnya berdasarkan set data baharu. Didapati bahawa sukar bagi SOTA LLM semasa untuk mengesan ralat, walaupun ia adalah ralat objektif dan jelas. Mereka membuat spekulasi bahawa ketidakupayaan LLM untuk mengesan ralat adalah sebab utama mengapa LLM tidak dapat membetulkan kesilapan penaakulan sendiri, tetapi aspek ini memerlukan penyelidikan lanjut.
- Artikel ini mencadangkan untuk menggunakan kaedah backtracking untuk membetulkan output dan menggunakan maklumat kedudukan yang salah untuk meningkatkan prestasi pada tugas asal. Penyelidikan telah menunjukkan bahawa kaedah ini boleh membetulkan output yang tidak betul dengan kesan minimum pada output yang sebaliknya betul.
Artikel ini menerangkan kaedah menjejak ke belakang sebagai satu bentuk "pembelajaran pengukuhan lisan", yang boleh mencapai peningkatan berulang bagi output CoT tanpa sebarang kemas kini berat. Para penyelidik mencadangkan bahawa menjejak ke belakang boleh digunakan dengan menggunakan pengelas terlatih sebagai model ganjaran, dan mereka juga secara eksperimen menunjukkan keberkesanan menjejak ke belakang di bawah ketepatan model ganjaran yang berbeza.
Set Data Kesilapan Bangku BESAR
 Bangku BESAR mengandungi 2186 set maklumat trajektori menggunakan gaya CoT. Setiap trajektori dijana oleh PaLM 2-L-Unicorn dan lokasi ralat logik pertama telah diberi penjelasan. Jadual 1 menunjukkan contoh trajektori di mana ralat berlaku dalam langkah 4
Bangku BESAR mengandungi 2186 set maklumat trajektori menggunakan gaya CoT. Setiap trajektori dijana oleh PaLM 2-L-Unicorn dan lokasi ralat logik pertama telah diberi penjelasan. Jadual 1 menunjukkan contoh trajektori di mana ralat berlaku dalam langkah 4
🎜🎜Trajektori ini adalah daripada 5 tugasan dalam set data BIG-Bench: pengisihan perkataan, menjejak objek yang dikocok, potongan logik, Aritmetik berbilang langkah dan bahasa Dyck. 🎜🎜
Untuk menjawab soalan setiap tugasan, mereka menggunakan kaedah reka bentuk segera CoT untuk memanggil PaLM 2. Untuk memisahkan trajektori CoT kepada langkah yang jelas, mereka menggunakan kaedah yang dicadangkan dalam "React: Synergizing reasoning and acting in language models" untuk menjana setiap langkah secara berasingan dan menggunakan baris baharu sebagai penanda henti
Apabila menjana semua trajektori, Dalam ini set data, apabila suhu = 0, ketepatan jawapan ditentukan oleh padanan tepat
Hasil penanda aras
Pada set data penemuan pepijat baharu, GPT-4-Turbo, GPT-4 dan Ketepatan GPT- 3.5-Turbo ditunjukkan dalam Jadual 4
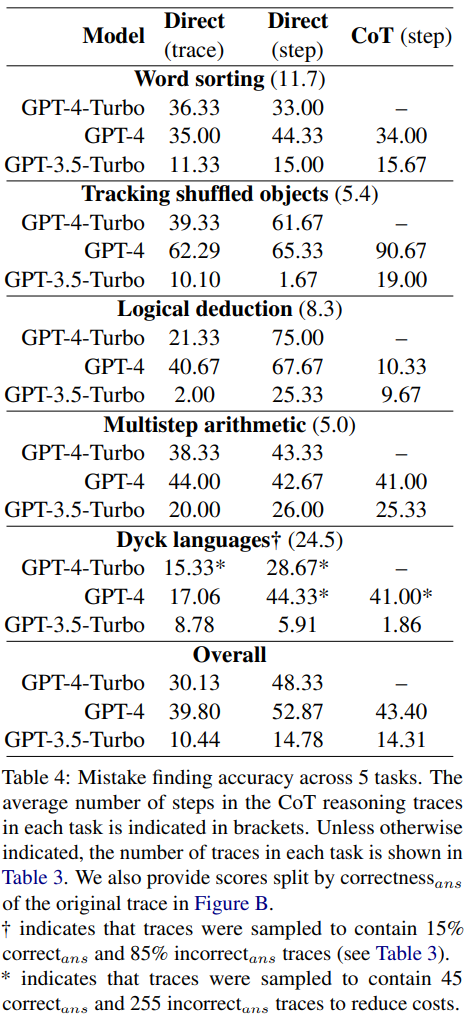
Setiap soalan mempunyai dua kemungkinan jawapan: sama ada betul atau salah. Jika ia adalah ralat, nilai N akan menunjukkan langkah di mana ralat pertama berlaku
Semua model telah dimasukkan dengan 3 gesaan yang sama. Mereka menggunakan tiga kaedah reka bentuk segera yang berbeza:
- Reka bentuk segera peringkat trek langsung
- Reka bentuk segera tahap langkah langsung
- Reka bentuk segera tahap langkah CoT
ditulis semula ialah: Perbincangan Berkaitan
Keputusan menunjukkan bahawa ketiga-tiga model menghadapi kesukaran menghadapi set data penemuan ralat baharu ini. GPT berprestasi terbaik, tetapi ia hanya boleh mencapai ketepatan keseluruhan 52.87 dalam reka bentuk segera peringkat langkah langsung.
Ini menunjukkan bahawa LLM tercanggih semasa menghadapi kesukaran mencari ralat, walaupun dalam kes yang paling mudah dan jelas. Sebaliknya, manusia boleh mencari kesilapan tanpa kepakaran khusus dan dengan konsistensi yang tinggi.
Penyelidik membuat spekulasi bahawa ketidakupayaan LLM untuk mengesan ralat adalah sebab utama mengapa LLM tidak dapat membetulkan kesilapan penaakulan sendiri. . Rajah 1 menunjukkan pertukaran ini
Para penyelidik percaya bahawa sebab untuk ini mungkin bilangan output model. Ketiga-tiga kaedah memerlukan penjanaan output yang semakin kompleks: kaedah reka bentuk segera yang menjana trajektori secara langsung memerlukan satu token, kaedah reka bentuk segera yang secara langsung menjana langkah memerlukan satu token setiap langkah, dan kaedah reka bentuk segera peringkat langkah CoT memerlukan satu token setiap langkah Pelbagai ayat. Jika terdapat sedikit kebarangkalian kadar ralat bagi setiap panggilan binaan, lebih banyak panggilan bagi setiap surih, lebih besar peluang model akan mengenal pasti sekurang-kurangnya satu ralat
Beberapa sampel dengan lokasi ralat sebagai proksi untuk ketepatan Reka Bentuk Segera
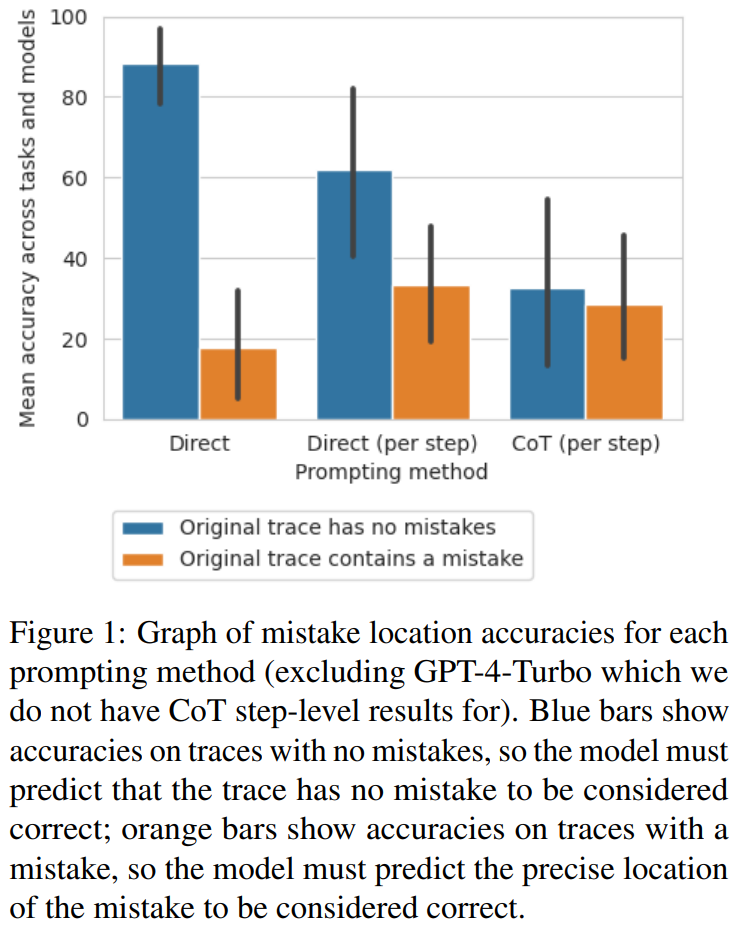
Para penyelidik meneroka sama ada kaedah reka bentuk segera ini boleh menentukan ketepatan trajektori dan bukannya kedudukannya yang salah.
Mereka mengira purata skor F1 berdasarkan sama ada model boleh meramal dengan betul sama ada terdapat ralat dalam trajektori. Sekiranya terdapat ralat, trajektori yang diramalkan oleh model dianggap sebagai "jawapan yang salah". Jika tidak, trajektori yang diramalkan oleh model dianggap sebagai "jawapan betul"Menggunakan betul_an dan salah_an sebagai label positif dan ditimbang mengikut bilangan kejadian setiap label, penyelidik mengira purata skor F1, dan hasilnya adalah ditunjukkan dalam Jadual 5.
Skor F1 berwajaran ini menunjukkan bahawa mencari ralat melalui gesaan adalah strategi yang lemah untuk menentukan ketepatan jawapan akhir.
Backtracking
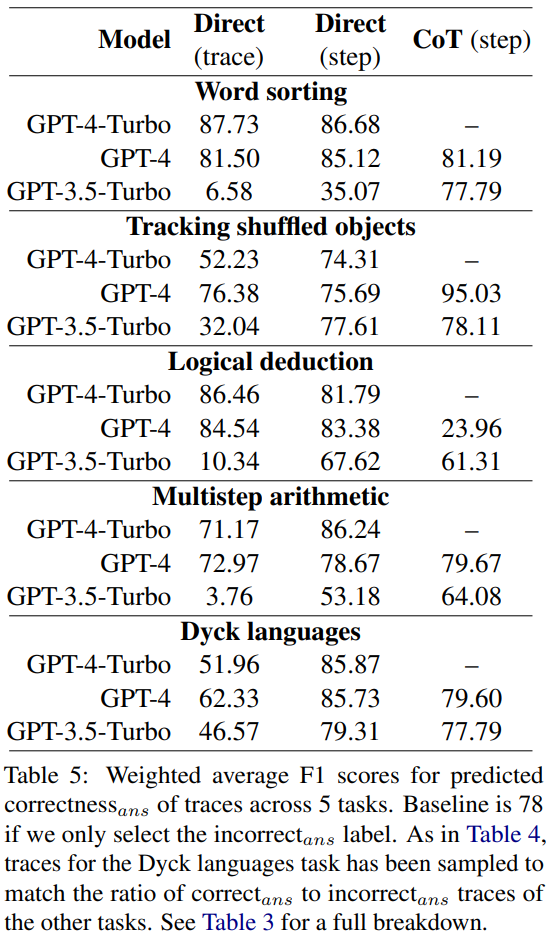 Huang et al menegaskan bahawa LLM tidak boleh membetulkan sendiri ralat logik tanpa maklum balas luaran. Walau bagaimanapun, dalam banyak aplikasi dunia nyata, selalunya tiada maklum balas luaran yang tersedia Dalam kajian ini, penyelidik menggunakan alternatif: pengelas ringan yang dilatih pada sejumlah kecil data maklum balas. Sama seperti model ganjaran dalam pembelajaran pengukuhan tradisional, pengelas ini boleh mengesan sebarang ralat logik dalam trajektori CoT sebelum menyalurkannya kembali kepada model penjana untuk meningkatkan output. Jika anda ingin memaksimumkan peningkatan, anda boleh melakukan berbilang lelaran.
Huang et al menegaskan bahawa LLM tidak boleh membetulkan sendiri ralat logik tanpa maklum balas luaran. Walau bagaimanapun, dalam banyak aplikasi dunia nyata, selalunya tiada maklum balas luaran yang tersedia Dalam kajian ini, penyelidik menggunakan alternatif: pengelas ringan yang dilatih pada sejumlah kecil data maklum balas. Sama seperti model ganjaran dalam pembelajaran pengukuhan tradisional, pengelas ini boleh mengesan sebarang ralat logik dalam trajektori CoT sebelum menyalurkannya kembali kepada model penjana untuk meningkatkan output. Jika anda ingin memaksimumkan peningkatan, anda boleh melakukan berbilang lelaran.
Penyelidik mencadangkan kaedah mudah untuk menambah baik output model dengan menjejaki semula lokasi ralat logik
- Model mula-mula menjana trajektori CoT awal. Dalam eksperimen, tetapkan suhu = 0.
- Kemudian gunakan model ganjaran untuk menentukan lokasi ralat dalam trajektori.
- Jika tiada ralat, beralih ke trek seterusnya. Jika terdapat ralat, gesa model sekali lagi untuk melakukan langkah yang sama, tetapi kali ini dengan suhu = 1, menghasilkan 8 output. Gesaan yang sama digunakan di sini bersama-sama dengan jejak separa semua langkah sebelum langkah yang salah.
- Dalam 8 output ini, tapis pilihan yang sama dengan ralat sebelumnya. Kemudian pilih yang mempunyai kebarangkalian logaritma tertinggi daripada output yang tinggal.
- Akhir sekali, gantikan langkah sebelumnya dengan langkah baru yang dijana semula, tetapkan semula suhu = 0, dan teruskan menjana baki langkah trajektori. . Sebaliknya, ia bergantung pada maklumat tentang ralat logik (seperti daripada model ganjaran terlatih), yang boleh ditentukan langkah demi langkah menggunakan model ganjaran. Ralat logik mungkin atau mungkin tidak muncul dalam trajektori correct_ans.
Kaedah jejak balik tidak bergantung pada mana-mana teks gesaan atau perkataan tertentu, sekali gus mengurangkan keutamaan yang berkaitan.
- Berbanding dengan kaedah yang memerlukan penjanaan semula keseluruhan trajektori, kaedah penjejakan belakang boleh mengurangkan kos pengiraan dengan menggunakan semula langkah yang diketahui secara logik yang betul.
- Kaedah penjejakan belakang secara langsung boleh meningkatkan kualiti langkah perantaraan, yang mungkin berguna dalam senario di mana langkah yang betul diperlukan (seperti menjana penyelesaian kepada masalah matematik), di samping meningkatkan kebolehtafsiran.
- Para penyelidik menggunakan set data BIG-Bench Mistake untuk menjalankan eksperimen untuk meneroka sama ada kaedah penjejakan belakang boleh membantu LLM membetulkan ralat logik. Sila lihat Jadual 6 untuk keputusan eksperimen
Δketepatan✓ merujuk kepada perbezaan ketepatan_ans pada set trajektori apabila jawapan asal adalah betul.
Untuk keputusan lintasan jawapan yang salah, ketepatan perlu dikira semula 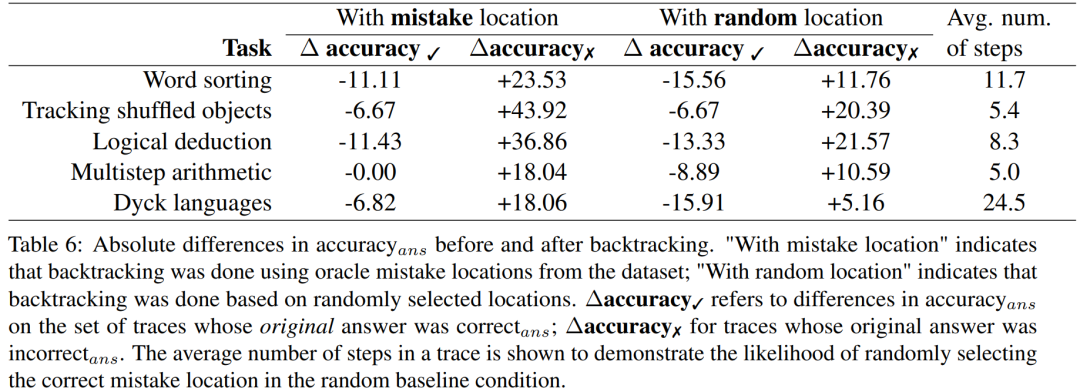
Untuk meneroka model ganjaran tahap ketepatan yang diperlukan apabila label yang baik tidak tersedia, mereka bereksperimen dengan menggunakan penjejakan ke belakang melalui model ganjaran simulasi, matlamat reka bentuk model ganjaran simulasi ini adalah untuk menghasilkan Label tahap ketepatan yang berbeza. Mereka menggunakan accuracy_RM untuk mewakili ketepatan model ganjaran simulasi di lokasi ralat yang ditentukan.
Apabila ketepatan_RM model ganjaran yang diberikan ialah X%, gunakan lokasi yang salah daripada BIG-Bench Mistake X% pada setiap masa. Untuk baki (100 − X)%, lokasi ralat diambil secara rawak. Untuk mensimulasikan gelagat pengelas biasa, lokasi ralat dijadikan sampel dalam cara yang sepadan dengan pengedaran set data. Para penyelidik juga menemui cara untuk memastikan lokasi sampel yang salah tidak sepadan dengan lokasi yang betul. Keputusan ditunjukkan dalam Rajah 2.
Dapat diperhatikan apabila kadar kerugian mencapai 65%, ketepatan Δ mula stabil. Malah, untuk kebanyakan tugasan, Δketepatan ✓ sudah melebihi Δketepatan ✗ apabila ketepatan_RM adalah kira-kira 60-70%. Ini menunjukkan bahawa walaupun ketepatan yang lebih tinggi membawa kepada hasil yang lebih baik, penjejakan ke belakang masih berfungsi walaupun tanpa label lokasi ralat standard emas
Atas ialah kandungan terperinci Google: LLM tidak dapat mencari ralat inferens, tetapi boleh membetulkannya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- php《7天魔鬼训练营》免费直播课程报名通知!!!!!!
- css盒子模型是什么?
- Apakah model OSI
- Pengaturcara berada dalam bahaya! Dikatakan bahawa OpenAI merekrut tentera penyumberan luar secara global dan melatih petani kod ChatGPT langkah demi langkah
- Yunshenchen dan Shengteng CANN bekerjasama untuk membuka kem latihan pembangunan anjing robot berkaki empat ROS