
Rumah >Peranti teknologi >AI >Anda boleh belajar 'tanpa data yang sepadan'! Universiti Zhejiang dan lain-lain mencadangkan penyambungan perwakilan kontras berbilang mod C-MCR
Anda boleh belajar 'tanpa data yang sepadan'! Universiti Zhejiang dan lain-lain mencadangkan penyambungan perwakilan kontras berbilang mod C-MCR

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-11-20 11:54:151287semak imbas
Perwakilan kontras pelbagai mod (MCR) bertujuan untuk mengekod input daripada modaliti yang berbeza ke dalam ruang kongsi yang dijajarkan secara semantik
Dengan kejayaan besar model CLIP dalam domain visual-linguistik, semakin banyak perwakilan kontras Modal mula muncul dan mencapai peningkatan ketara pada banyak tugas hiliran, tetapi kaedah ini sangat bergantung pada data berpasangan berskala besar dan berkualiti tinggi
Untuk menyelesaikan masalah ini, penyelidik dari Universiti Zhejiang dan institusi lain mencadangkan Concatenated multimodal contrastive representation (C-MCR) adalah kaedah pembelajaran perwakilan kontrastif multimodal yang tidak memerlukan data berpasangan dan sangat cekap dalam latihan.

Sila klik pautan berikut untuk melihat kertas kerja: https://arxiv.org/abs/2305.14381
pautan laman utama projek C-MCR: https://c-mcr.github. /C- MCR/
Alamat model dan kod: https://github.com/MCR-PEFT/C-MCR
Kaedah ini menyambungkan pratetap yang berbeza melalui modal hab tanpa menggunakan sebarang data berpasangan perwakilan kontras, kami mempelajari perwakilan audio-visual dan teks awan titik 3D yang berkuasa, dan mencapai hasil SOTA pada pelbagai tugas seperti mendapatkan semula audio-visual, penyetempatan sumber bunyi dan klasifikasi objek 3D.
Pengenalan
Perwakilan kontras berbilang mod (MCR) bertujuan untuk memetakan data daripada modaliti berbeza ke dalam ruang semantik bersatu. Dengan kejayaan besar CLIP dalam bidang visual-linguistik, pembelajaran perwakilan kontras antara lebih banyak kombinasi modal telah menjadi topik penyelidikan yang hangat, menarik lebih banyak perhatian.
Walau bagaimanapun, keupayaan generalisasi bagi representasi kontrastif pelbagai mod sedia ada terutamanya mendapat manfaat daripada sebilangan besar pasangan data berkualiti tinggi. Ini sangat mengehadkan pembangunan perwakilan kontrastif pada modaliti yang kekurangan data berkualiti tinggi berskala besar. Sebagai contoh, korelasi semantik antara pasangan data audio dan visual selalunya samar-samar, dan data berpasangan antara awan titik 3D dan teks adalah terhad dan sukar diperoleh.
Walau bagaimanapun, kami telah memerhatikan bahawa gabungan mod yang kekurangan data berpasangan ini selalunya mempunyai sejumlah besar data berpasangan berkualiti tinggi dengan mod perantaraan yang sama. Sebagai contoh, dalam domain audio-visual, walaupun kualiti data audiovisual tidak boleh dipercayai, terdapat sejumlah besar data berpasangan berkualiti tinggi antara teks audio dan teks-visual.
Begitu juga, sementara ketersediaan data gandingan teks awan 3D adalah terhad, data imej awan dan teks imej titik 3D adalah banyak. Mod hab ini boleh mewujudkan hubungan lanjut antara mod.
Memandangkan modaliti dengan sejumlah besar data berpasangan selalunya sudah mempunyai perwakilan kontrastif yang telah dilatih, artikel ini secara langsung cuba menghubungkan perwakilan kontras antara modaliti yang berbeza melalui modaliti hab, dengan itu memberikan perwakilan yang lebih baik untuk modaliti yang kekurangan gandingan. data. Kombinasi membina ruang perwakilan kontras baharu.
Menggunakan Concatenated Multimodal Contrast Representation (C-MCR), anda boleh membina hubungan dengan sejumlah besar representasi kontrastif multimodal sedia ada melalui mod bertindih, dengan itu mempelajari hubungan penjajaran antara julat modaliti yang lebih luas. Proses pembelajaran ini tidak memerlukan sebarang data berpasangan dan sangat cekap
C-MCR mempunyai dua kelebihan utama:
Tumpuan adalah pada fleksibiliti:
membekalkan pembelajaran C-MCR. perwakilan berbeza yang tidak mempunyai gandingan langsung. Dari perspektif lain, C-MCR menganggap setiap ruang perwakilan kontras berbilang mod sedia ada sebagai nod, dan menganggap modaliti bertindih sebagai modaliti hab utama
dengan menyambungkan ruang perwakilan kontras berbilang mod terpencil, kami mampu untuk mengembangkan secara fleksibel pengetahuan penjajaran berbilang modal yang diperolehi dan melombong rangkaian perwakilan kontras antara mod yang lebih luas
2. Kecekapan:
Oleh kerana C-MCR sahaja Ia adalah perlu untuk membina sambungan perwakilan yang sedia ada ruang, jadi hanya dua pemeta mudah perlu dipelajari, dan parameter latihan dan kos latihan mereka sangat rendah.
Dalam percubaan ini, kami menggunakan teks sebagai hab untuk membandingkan ruang perwakilan teks visual (CLIP) dan teks-audio (CLAP), dan akhirnya memperoleh perwakilan visual-audio berkualiti tinggi
Begitu juga, oleh membandingkan teks-visual bersambung imej (CLIP) dan awan titik visual-3D (ULIP) untuk mewakili ruang, satu set perwakilan kontrastif teks awan titik 3D juga boleh diperoleh
Kaedah
Rajah 1 ( a) Aliran algoritma C-MCR diperkenalkan (mengambil penggunaan teks untuk menyambung CLIP dan CLAP sebagai contoh).
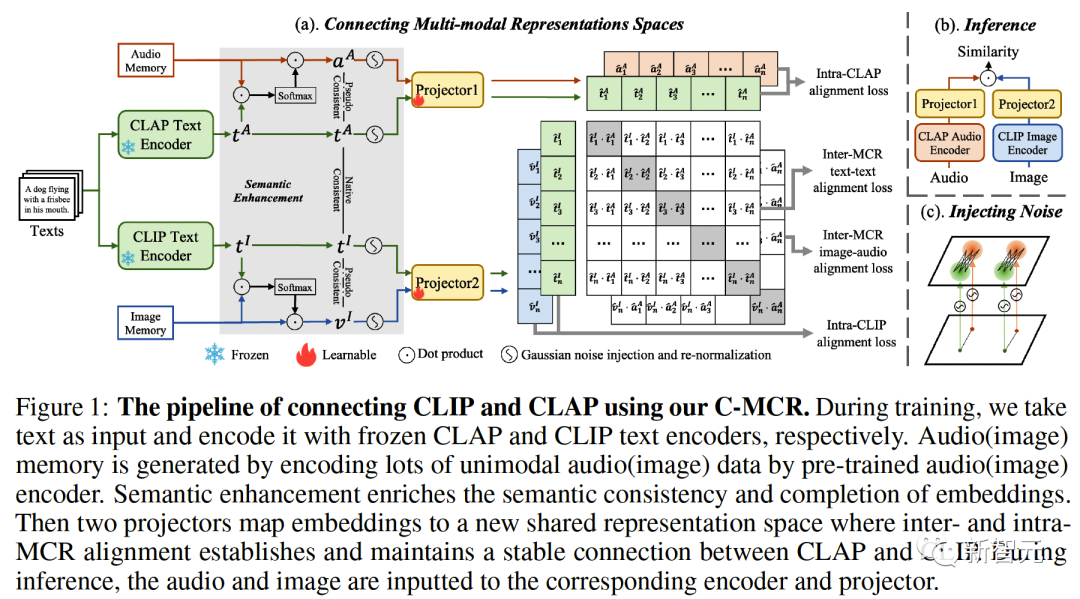
Data teks (modaliti bertindih) dikodkan ke dalam ciri teks oleh pengekod teks CLIP dan CLAP masing-masing:,.
Pada masa yang sama, terdapat juga sejumlah besar data mod tunggal tidak berpasangan yang masing-masing dikodkan ke dalam ruang CLIP dan CLAP, membentuk memori imej dan memori audio# 🎜🎜## 🎜🎜#
Peningkatan semantik ciri merujuk kepada proses menambah baik dan mengoptimumkan ciri untuk meningkatkan keupayaan ekspresi semantik mereka. Dengan melaraskan ciri-ciri yang sesuai, ia dapat menggambarkan dengan lebih tepat maksud yang ingin dinyatakan, seterusnya meningkatkan kesan ungkapan bahasa. Teknologi peningkatan semantik ciri mempunyai nilai aplikasi penting dalam bidang pemprosesan bahasa semula jadi, yang boleh membantu mesin memahami dan memproses maklumat teks, dan meningkatkan keupayaan mesin dalam pemahaman semantik dan penjanaan semantik#🎜 🎜 #Kita boleh mulakan dengan menambah baik maklumat semantik perwakilan untuk meningkatkan keteguhan dan kelengkapan sambungan spatial. Dalam hal ini, kita terlebih dahulu membincangkannya dari dua perspektif iaitu ketekalan semantik dan keutuhan semantik
Konsistensi semantik inter-modal
# 🎜 #CLIP dan CLAP telah mempelajari perwakilan imej-teks dan teks-audio sejajar yang boleh dipercayai.
Kami mengeksploitasi penjajaran modal yang wujud dalam CLIP dan CLAP untuk menjana ciri imej dan audio yang konsisten secara semantik dengan teks ke-i, yang membawa kepada kuantifikasi yang lebih baik Bandingkan modaliti jurang dalam ruang perwakilan dan secara lebih langsung menambang korelasi antara modaliti tidak bertindih:
# 🎜🎜## 🎜🎜 -integriti semantik modal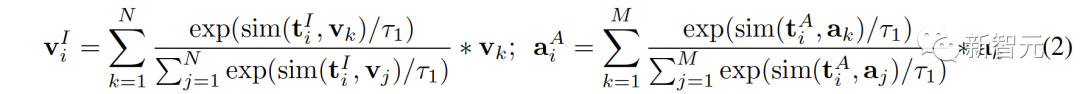
Ruang perwakilan yang berbeza akan mempunyai kecenderungan yang berbeza untuk ungkapan semantik data, jadi ruang perwakilan yang sama di bawah ruang yang berbeza akan mempunyai kecenderungan yang berbeza . Sesuatu teks pasti akan mempunyai penyelewengan dan kerugian semantik. Pincang semantik ini terkumpul dan diperkuatkan apabila menyambungkan ruang perwakilan.
Untuk meningkatkan integriti semantik setiap perwakilan, kami mencadangkan untuk menambah bunyi Gaussian sifar min pada perwakilan dan menormalkannya semula kepada hipersfera unit :# 🎜🎜#
Seperti yang ditunjukkan dalam Rajah 1 (c), dalam ruang perwakilan kontras, setiap perwakilan boleh dilihat Perwakilan ialah titik pada unit hipersfera. Menambah hingar Gaussian dan menormalkan semula membolehkan perwakilan mewakili bulatan pada sfera unit.
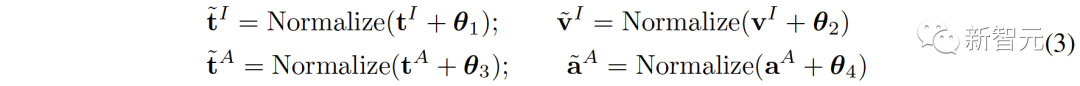
2 Penjajaran Antara-MCR#🎜🎜 #
Selepas penambahbaikan semantik perwakilan, kami menggunakan dua pemeta dan untuk memetakan semula perwakilan CLIP dan CLAP ke dalam ruang kongsi baharu#🎜🎜 ##🎜 ##🎜
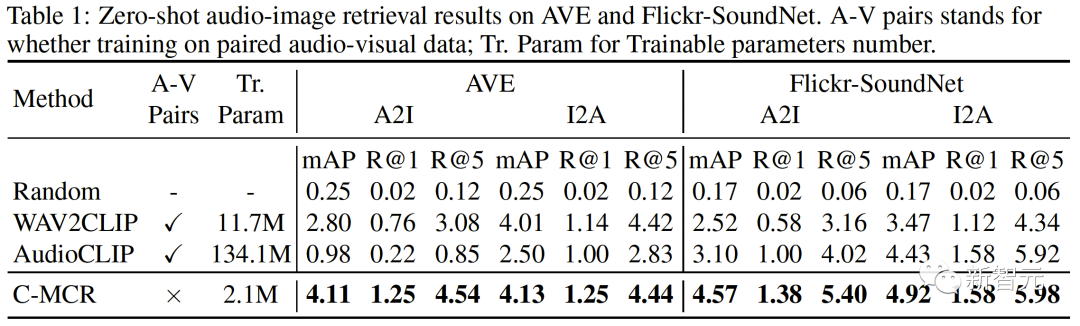
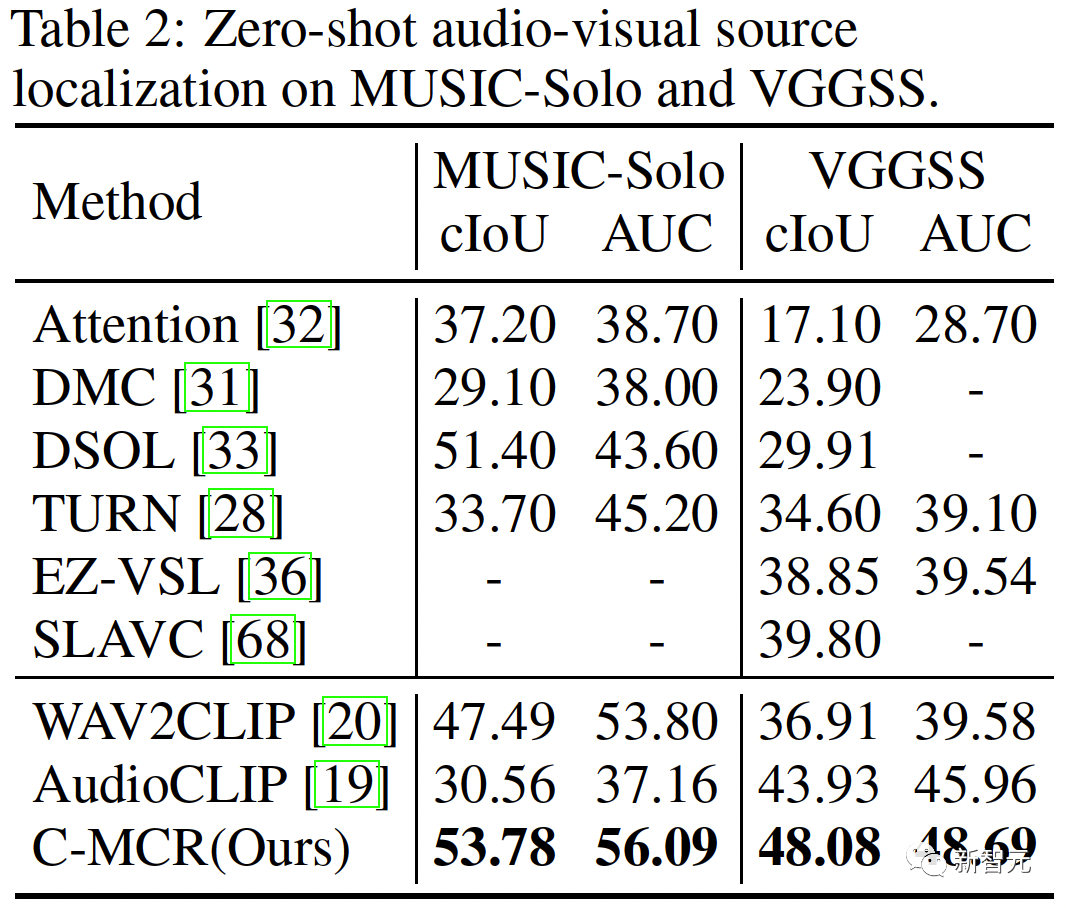
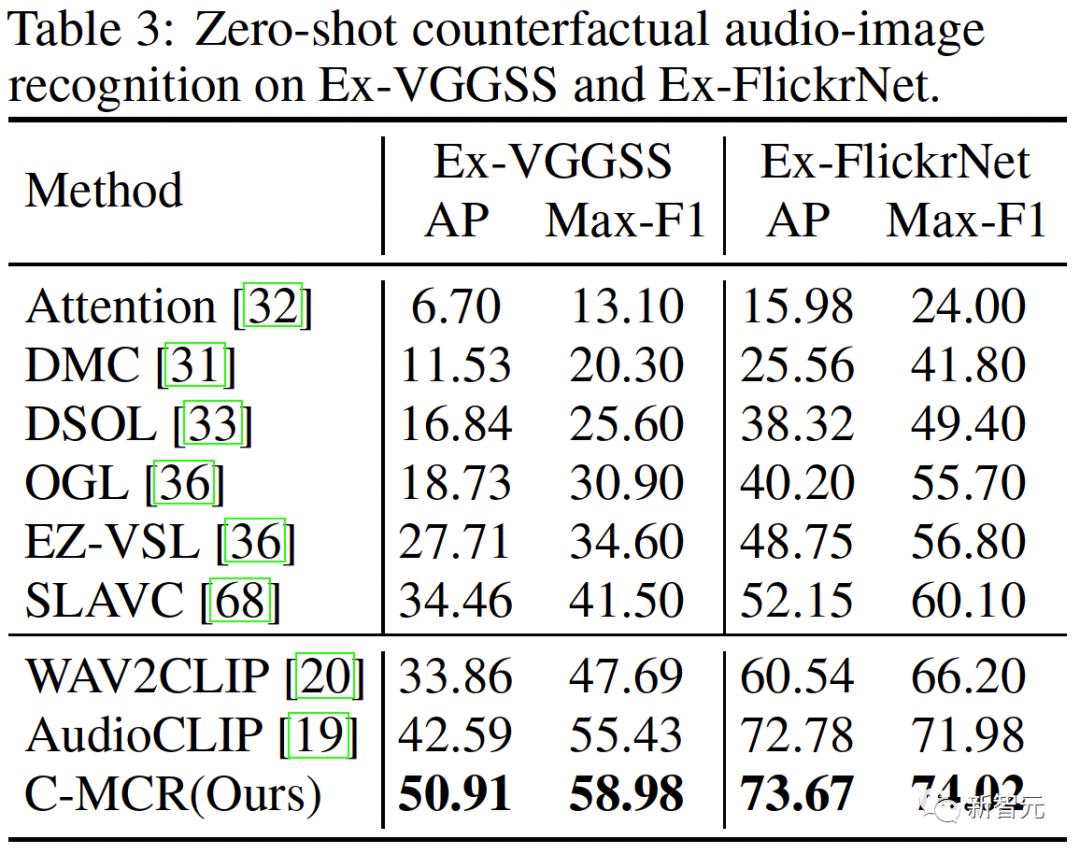
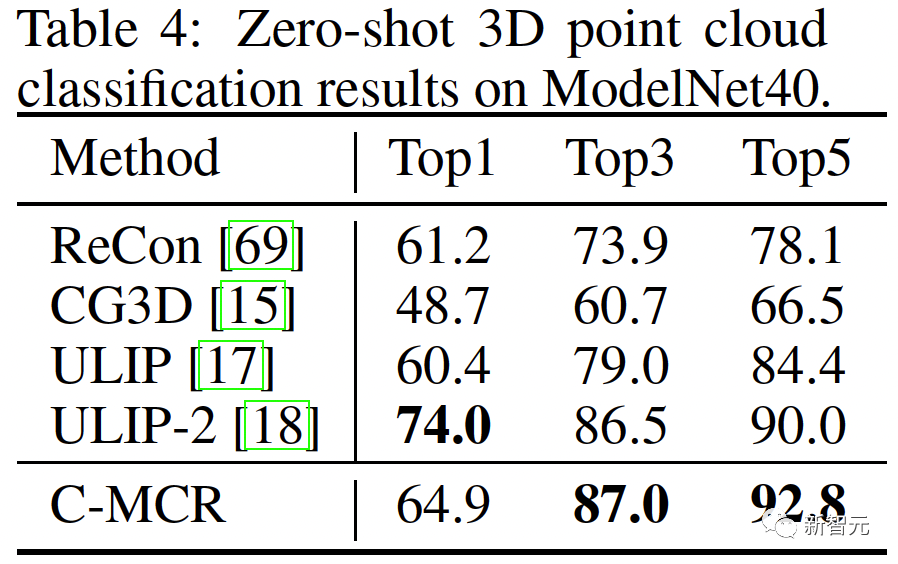
Ruang baharu perlu memastikan representasi yang serupa secara semantik daripada ruang berbeza adalah berdekatan antara satu sama lain. ( Untuk menyambungkan dua ruang perwakilan kontras dengan lebih komprehensif, kami menyelaraskan serentak ( #🎜##🎜 #3 Penjajaran Intra-MCR #🎜 juga ada di antara ruang🎜# fenomena jurang modaliti dalam ruang sambungan dan perwakilan kontras. Iaitu, dalam ruang perwakilan kontras, walaupun perwakilan modaliti yang berbeza diselaraskan secara semantik, ia diedarkan dalam subruang yang berbeza sama sekali. Ini bermakna sambungan yang lebih stabil yang dipelajari daripada ( Untuk menyelesaikan masalah ini, kami mencadangkan untuk menjajarkan semula perwakilan modal yang berbeza bagi setiap ruang perwakilan kontras. Secara khusus, kami mengalih keluar struktur pengecualian contoh negatif dalam fungsi kehilangan kontras untuk memperoleh fungsi kerugian untuk mengurangkan jurang modaliti. Fungsi kehilangan kontrastif biasa boleh dinyatakan sebagai: Selepas kita menghapuskan istilah pengecualian pasangan negatif, formula akhir Boleh dipermudahkan kepada: #🎜🎜🎜# secara audio dengan menggunakan teks -Ruang teks (CLAP) dan ruang teks-visual (CLIP) untuk mendapatkan perwakilan audio-visual, dan ruang imej awan titik 3D (ULIP) dan ruang teks imej (CLIP) yang dipautkan imej untuk mendapatkan perwakilan teks awan titik 3D . Hasil pengambilan imej audio sampel sifar pada AVE dan Flickr-SoundNet adalah seperti berikut: Hasil penyetempatan sumber bunyi sifar sampel pada MUSIC-Solo dan VGGSS adalah seperti berikut: Hasil pengecaman imej audio kontrafaktual sampel sifar dan Ex-VGGrSSNet adalah seperti berikut. : Hasil pengelasan titik 3D titik sifar pada ModelNet40 adalah seperti berikut:  ,
, ) yang berasal daripada teks yang sama secara semula jadi konsisten secara semantik dan boleh dianggap sebagai pasangan tag sebenar, manakala (,) berasal dari (
) yang berasal daripada teks yang sama secara semula jadi konsisten secara semantik dan boleh dianggap sebagai pasangan tag sebenar, manakala (,) berasal dari (
 ,)
,)
 (
( ,
, ) sangat konsisten, tetapi sambungan yang dipelajari daripadanya adalah tidak langsung untuk audio-visual. Walaupun konsistensi semantik pasangan (
) sangat konsisten, tetapi sambungan yang dipelajari daripadanya adalah tidak langsung untuk audio-visual. Walaupun konsistensi semantik pasangan ( ,
, ,
, #🎜) dan (🎜
#🎜) dan (🎜  ,
, ):
): 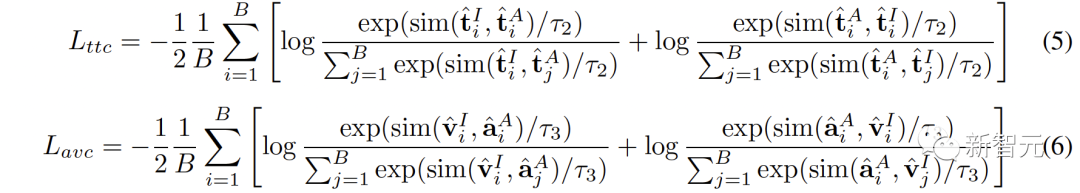 ): ,) mungkin tidak diwarisi dengan baik oleh audio-visual.
): ,) mungkin tidak diwarisi dengan baik oleh audio-visual. 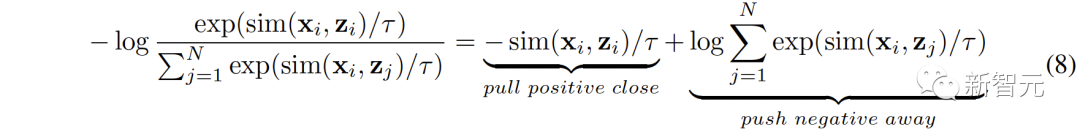
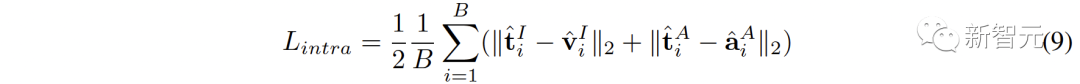
Eksperimen
Atas ialah kandungan terperinci Anda boleh belajar 'tanpa data yang sepadan'! Universiti Zhejiang dan lain-lain mencadangkan penyambungan perwakilan kontras berbilang mod C-MCR. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- tcp/ip参考模型分为哪几层?
- 路由选择是osi模型中什么层的主要功能
- Berapakah jenis model kotak css yang ada?
- Meta terus melempar AI untuk mempercepatkan langkah muktamad! Cip inferens AI pertama, superkomputer AI yang direka khas untuk latihan model besar
- Menggunakan model besar untuk mencipta paradigma baharu untuk latihan ringkasan teks