
Rumah >Peranti teknologi >AI >Menggunakan model besar untuk mencipta paradigma baharu untuk latihan ringkasan teks
Menggunakan model besar untuk mencipta paradigma baharu untuk latihan ringkasan teks

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-10 09:43:382672semak imbas
1. Tugasan teks
Kandungan utama artikel ini ialah perbincangan tentang kaedah ringkasan teks generatif, memfokuskan pada paradigma latihan terkini menggunakan pembelajaran kontrastif dan model besar. Ia terutamanya melibatkan dua artikel, satu ialah BRIO: Bringing Order to Abstractive Summarization (2022), yang menggunakan pembelajaran kontrastif untuk memperkenalkan tugasan pemeringkatan dalam model generatif; yang satu lagi ialah On Learning to Summarize with Large Language Models as References (2023), dalam Based pada BRIO, model besar diperkenalkan lagi untuk menjana data latihan berkualiti tinggi.
2. Kaedah dan isu latihan ringkasan teks generatif
Latihan ringkasan teks generatif secara amnya menggunakan anggaran persamaan maksimum. Pertama, Pengekod digunakan untuk mengekod dokumen, dan kemudian Penyahkod digunakan untuk meramalkan secara rekursif setiap teks dalam ringkasan Sasaran yang sesuai ialah jawapan standard ringkasan yang dibina secara buatan. Matlamat menjana teks pada setiap kedudukan yang paling hampir dengan jawapan standard diwakili oleh fungsi pengoptimuman:
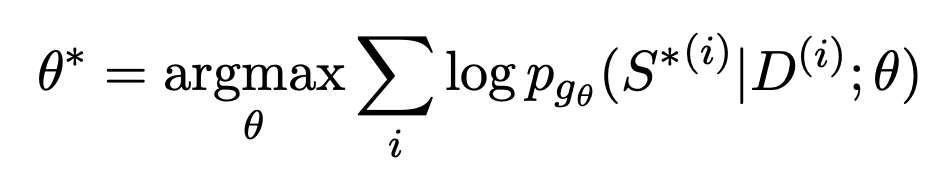
Masalah dengan pendekatan ini ialah, Latihan dan tugas sebenar hiliran tidak konsisten. Berbilang ringkasan boleh dijana untuk dokumen, dan ia mungkin berkualiti atau tidak berkualiti. MLE memerlukan sasaran pemasangan mestilah satu-satunya jawapan standard. Jurang ini juga menyukarkan model ringkasan teks untuk membandingkan kelebihan dan kekurangan dua ringkasan dengan kualiti yang berbeza secara berkesan. Sebagai contoh, satu eksperimen telah dijalankan dalam kertas BRIO Model ringkasan teks umum mempunyai hasil yang sangat buruk apabila menilai susunan relatif dua ringkasan dengan kualiti yang berbeza.
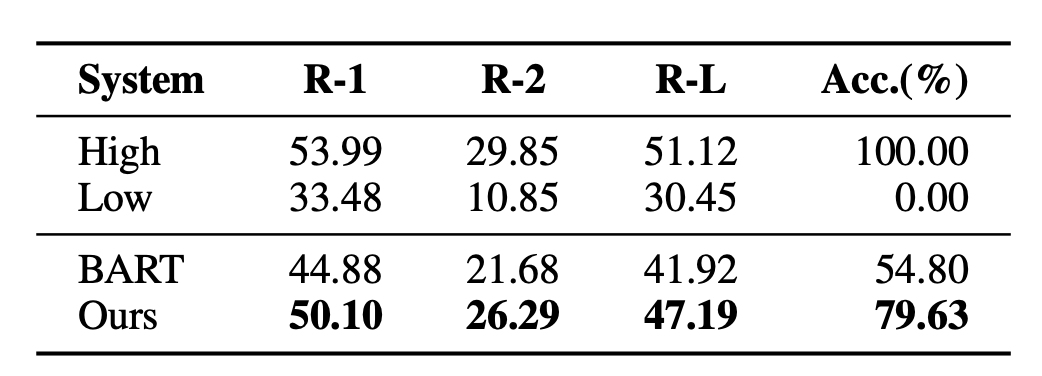
3. Model generatif memperkenalkan pembelajaran kontrastif peringkat
Untuk menyelesaikan masalah yang wujud dalam model ringkasan teks generatif tradisional , BRIO: Bringing Order to Abstractive Summarization (2022) mencadangkan untuk memperkenalkan lagi tugas pembelajaran kontrastif ke dalam model generatif untuk meningkatkan keupayaan model untuk menyusun ringkasan kualiti yang berbeza.
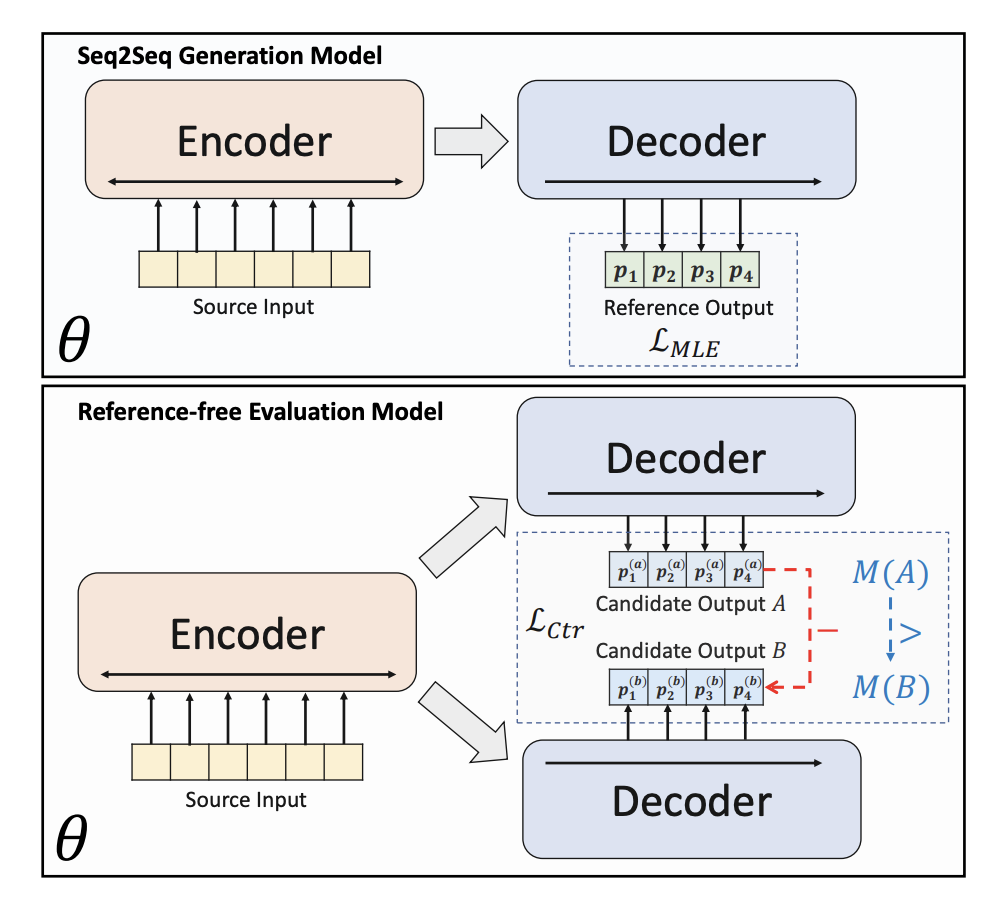
BRIO menggunakan latihan pelbagai tugas. Tugasan pertama menggunakan kaedah yang sama seperti model generatif tradisional, iaitu, menyesuaikan jawapan standard melalui MLE. Tugas kedua ialah tugas pembelajaran kontrastif, di mana model ringkasan teks pra-latihan menggunakan carian pancaran untuk menghasilkan dua hasil yang berbeza, dan ROUGE digunakan untuk menilai yang mana lebih baik antara dua hasil yang dijana dan jawapan standard untuk menentukan yang mana dua Menyusun abstrak. Kedua-dua keputusan ringkasan adalah input ke dalam Dekoder untuk mendapatkan kebarangkalian kedua-dua ringkasan Melalui kehilangan pembelajaran perbandingan, model boleh memberikan skor yang lebih tinggi kepada ringkasan berkualiti tinggi. Kaedah pengiraan kerugian pembelajaran perbandingan dalam bahagian ini adalah seperti berikut:
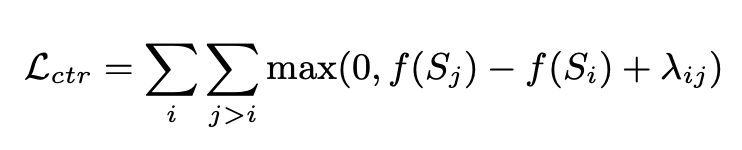
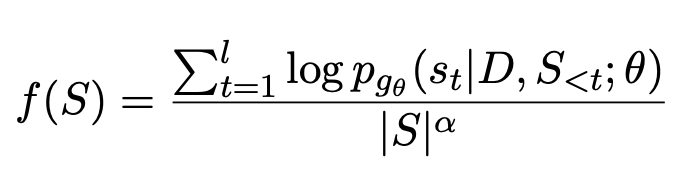
Telah didapati bahawa kualiti ringkasan yang dihasilkan menggunakan model besar seperti GPT adalah lebih baik daripada yang dihasilkan oleh manusia, jadi model besar seperti itu semakin popular. Dalam kes ini, menggunakan jawapan standard yang dijana secara buatan mengehadkan siling keberkesanan model. Oleh itu, On Learning to Summarize with Large Language Models as References (2023) mencadangkan untuk menggunakan model besar seperti GPT untuk menjana data latihan untuk membimbing pembelajaran model ringkasan.
Artikel ini mencadangkan 3 cara untuk menggunakan model besar untuk menjana sampel latihan.
Yang pertama ialah menggunakan ringkasan yang dijana oleh model besar secara langsung untuk menggantikan ringkasan yang dijana secara manual, yang setara dengan secara langsung menyesuaikan keupayaan penjanaan ringkasan model besar dengan model hiliran MLE.
Kaedah kedua ialah GPTScore, yang kebanyakannya menggunakan model besar yang telah dilatih untuk menjaringkan ringkasan yang dijana, menggunakan skor ini sebagai asas untuk menilai kualiti ringkasan, dan kemudian menggunakan kaedah yang serupa dengan BRIO untuk latihan pembelajaran perbandingan. GPTScore ialah kaedah yang dicadangkan dalam Gptscore: Evaluate as you want (2023) untuk menilai kualiti teks yang dijana berdasarkan model besar.

Kaedah ketiga ialah GPTRank Kaedah ini membenarkan model besar mengisih setiap ringkasan dan bukannya menskor secara langsung, dan biarkan model besar menentukan kedudukan ringkasan. . Penjelasan logik untuk mendapatkan hasil pengisihan yang lebih munasabah.

5. Ringkasan
Keupayaan model besar dalam penjanaan ringkasan semakin diiktiraf secara meluas Oleh itu, menggunakan model besar sebagai penjana sasaran pemasangan model ringkasan untuk menggantikan hasil anotasi manual akan menjadi trend pembangunan masa hadapan. Pada masa yang sama, menggunakan pembelajaran perbandingan kedudukan untuk melatih penjanaan ringkasan membolehkan model ringkasan melihat kualiti ringkasan dan mengatasi pemasangan titik asal, yang juga penting untuk menambah baik kesan model ringkasan.
Atas ialah kandungan terperinci Menggunakan model besar untuk mencipta paradigma baharu untuk latihan ringkasan teks. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI