
Rumah >Peranti teknologi >AI >Apakah regularisasi dalam pembelajaran mesin?
Apakah regularisasi dalam pembelajaran mesin?

- 王林ke hadapan
- 2023-11-06 11:25:01992semak imbas
1. Pengenalan
Dalam bidang pembelajaran mesin, model yang berkaitan mungkin menjadi terlalu muat dan kurang muat semasa proses latihan. Untuk mengelakkan perkara ini daripada berlaku, kami menggunakan operasi penyelarasan dalam pembelajaran mesin agar sesuai dengan model pada set ujian kami. Secara umumnya, operasi penyelarasan membantu semua orang mendapatkan model terbaik dengan mengurangkan kemungkinan pemasangan berlebihan dan kekurangan.
Dalam artikel ini, kita akan memahami apa itu regularization, jenis regularization. Selain itu, kita akan membincangkan konsep berkaitan seperti bias, varians, underfitting dan overfitting.
Tiada lagi perkara karut, mari mulakan!
2. Bias dan Varians
Bias dan Varians adalah dua aspek yang digunakan untuk menggambarkan jurang antara model yang kita pelajari dan model sebenar
Apa yang perlu ditulis semula. ditakrifkan seperti berikut:
- Bias ialah perbezaan antara purata output semua model yang dilatih dengan semua set data latihan yang mungkin dan nilai output model sebenar.
- Varian ialah perbezaan antara nilai keluaran model yang dilatih pada set data latihan yang berbeza.
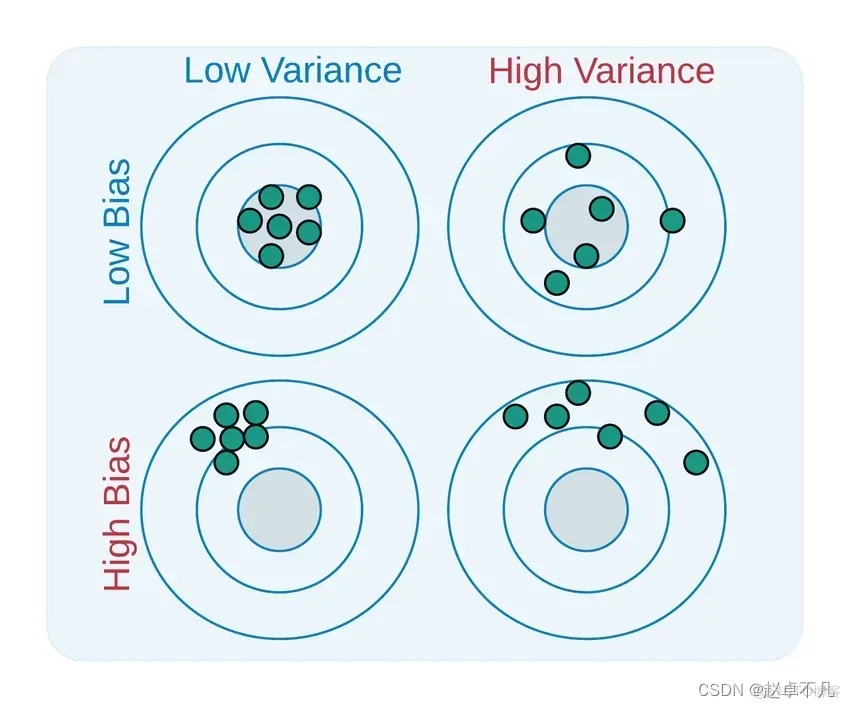
Bias mengurangkan sensitiviti model kepada titik data individu, sambil meningkatkan generalisasi data dan mengurangkan sensitiviti model kepada titik data terpencil. Masa latihan juga boleh dikurangkan kerana fungsi yang diperlukan adalah kurang kompleks. Bias yang tinggi menunjukkan bahawa fungsi sasaran diandaikan lebih dipercayai, tetapi kadangkala boleh menyebabkan model tidak sesuai
Variance (Variance) dalam pembelajaran mesin merujuk kepada ralat yang disebabkan oleh kepekaan model kepada perubahan kecil dalam data ditetapkan. Memandangkan terdapat variasi ketara dalam set data, algoritma memodelkan hingar dan outlier dalam set latihan. Keadaan ini sering dipanggil overfitting. Apabila dinilai pada set data baharu, ia tidak dapat memberikan ramalan yang tepat kerana model pada asasnya mempelajari setiap titik data
Model yang agak seimbang akan mempunyai pincang rendah dan varians rendah, manakala pincang tinggi dan varians tinggi akan membawa kepada underfitting dan overfitting.
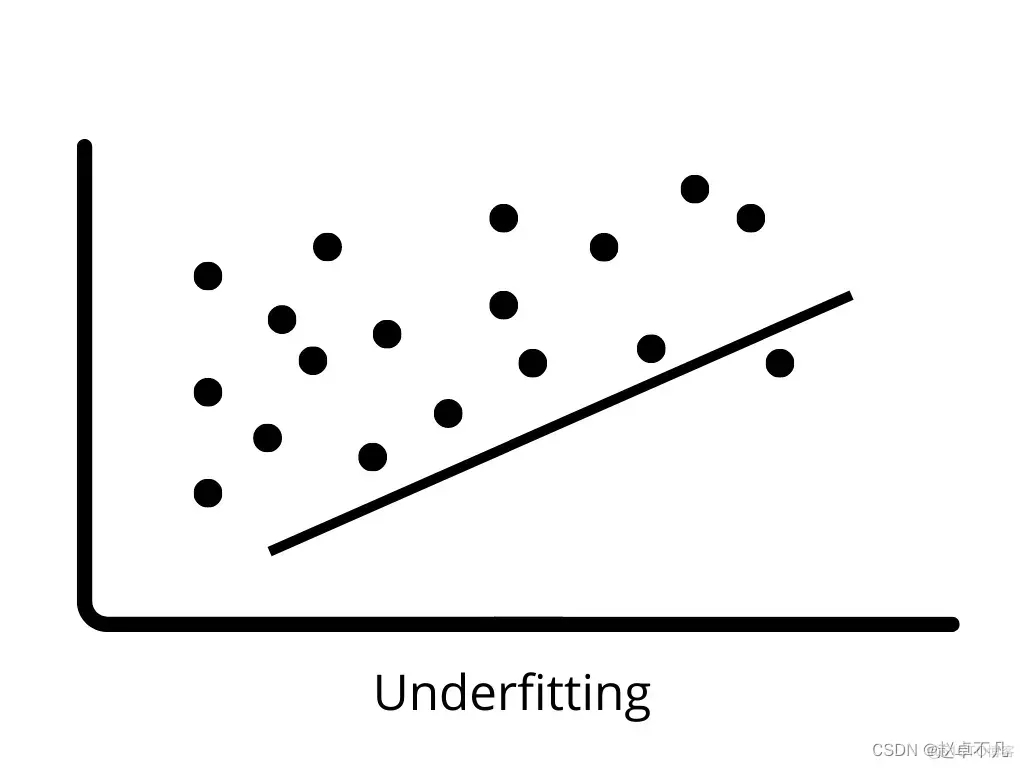
3. Underfitting
Underfitting berlaku apabila model tidak dapat mempelajari corak dalam data latihan dengan betul dan membuat generalisasi kepada data baharu. Model kurang sesuai berprestasi buruk pada data latihan dan boleh membawa kepada ramalan yang salah. Apabila bias tinggi dan varians rendah berlaku, underfitting cenderung berlaku
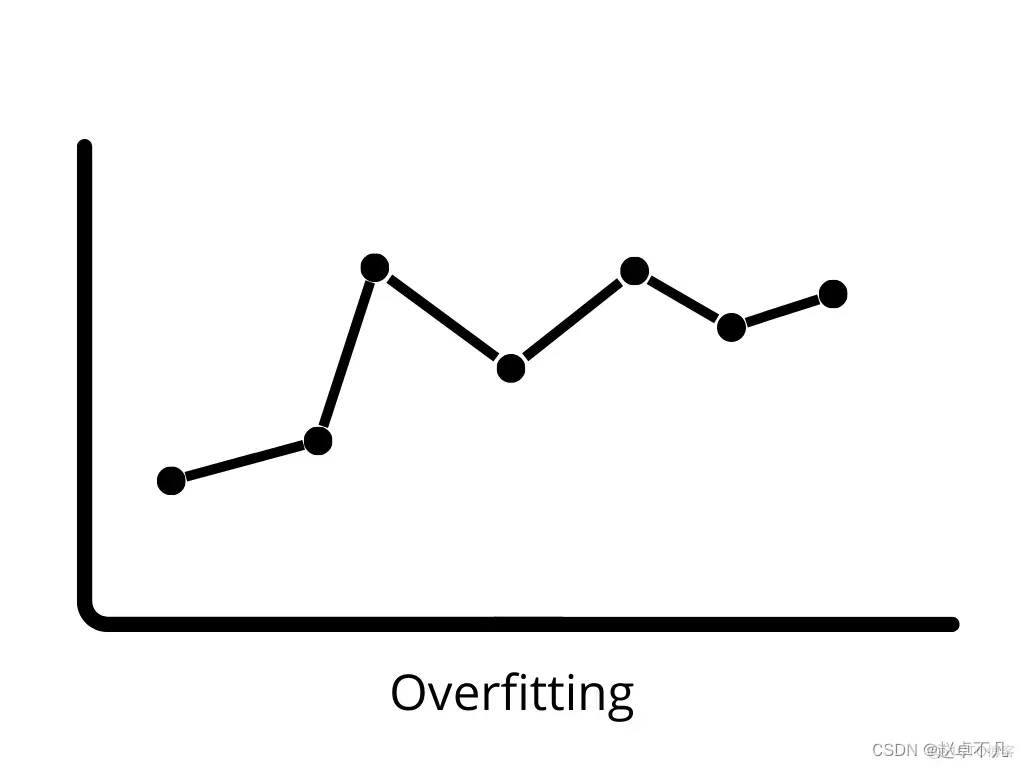
4. kurang pada data baharu, ia dipanggil overfitting. Dalam kes ini, model pembelajaran mesin dipasang pada hingar dalam data latihan, yang memberi kesan negatif terhadap prestasi model pada data ujian. Kecondongan rendah dan varians yang tinggi boleh menyebabkan pemasangan berlebihan.
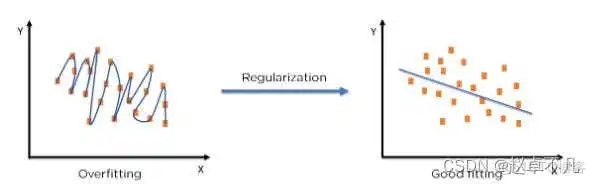
5. Konsep Regularization
Istilah "regularization" menerangkan kaedah menentukur model pembelajaran mesin untuk mengurangkan fungsi kehilangan terlaras atau mengelak daripada overfitting. . 6. Regresi L1
Berbanding dengan regresi kolar, pelaksanaan regularisasi L1 adalah terutamanya untuk menambah istilah penalti kepada fungsi kerugian Nilai penalti istilah ini ialah jumlah nilai mutlak semua pekali, seperti berikut:
Dalam model regresi Lasso, ini dicapai dengan meningkatkan tempoh penalti bagi nilai mutlak pekali regresi dengan cara yang serupa dengan regresi rabung. Di samping itu, regularisasi L1 mempunyai prestasi yang baik dalam meningkatkan ketepatan model regresi linear. Pada masa yang sama, oleh kerana regularisasi L1 menghukum semua parameter secara sama rata, ia boleh menjadikan beberapa pemberat menjadi sifar, sekali gus menghasilkan model jarang yang boleh mengalih keluar ciri tertentu (berat 0 adalah bersamaan dengan penyingkiran).
7. Regularisasi L2
L2 juga dicapai dengan menambahkan istilah penalti pada fungsi kerugian, yang sama dengan jumlah kuasa dua semua pekali. Seperti yang ditunjukkan di bawah:
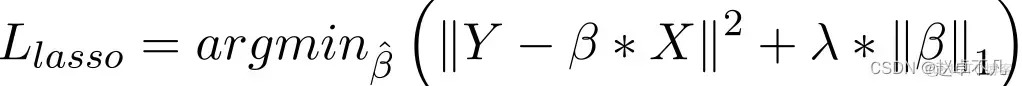
Secara umumnya, ia dianggap sebagai kaedah untuk diguna pakai apabila data menunjukkan multikolineariti (pembolehubah bebas sangat berkorelasi). Walaupun anggaran kuasa dua terkecil (OLS) dalam multikolineariti tidak berat sebelah, variansnya yang besar boleh menyebabkan nilai yang diperhatikan berbeza dengan ketara daripada nilai sebenar. L2 mengurangkan ralat anggaran regresi ke tahap tertentu. Ia biasanya menggunakan parameter pengecutan untuk menyelesaikan masalah multikolineariti. Regularisasi L2 mengurangkan perkadaran tetap pemberat dan melicinkan pemberat.
8. Ringkasan
Selepas analisis di atas, pengetahuan regularization yang berkaitan dalam artikel ini diringkaskan seperti berikut:
L1 regularization boleh menjana matriks yang sparse, sparse model yang sparse. , yang boleh Digunakan untuk pemilihan ciri;
L2 regularization boleh menghalang model overfitting, L1 juga boleh menghalang overfitting dan meningkatkan keupayaan generalisasi model
L1 (Lagrangian) parameters regularization. Taburan Laplace, yang boleh memastikan keterlanjuran model, iaitu, beberapa parameter adalah sama dengan 0 andaian
L2 (regresi rabung) ialah taburan sebelumnya bagi parameter ialah taburan Gaussian, yang boleh memastikan kestabilan; daripada model, iaitu Nilai parameter tidak akan terlalu besar atau terlalu kecil
Dalam aplikasi praktikal, jika ciri berdimensi tinggi dan jarang, penyelarasan L1 harus digunakan jika ciri berdimensi rendah dan padat , L2 regularization harus digunakan
Atas ialah kandungan terperinci Apakah regularisasi dalam pembelajaran mesin?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!