
Rumah >Peranti teknologi >AI >Bahasa, pemecahan robot, MIT dan lain-lain menggunakan GPT-4 untuk menjana tugas simulasi secara automatik dan memindahkannya ke dunia nyata
Bahasa, pemecahan robot, MIT dan lain-lain menggunakan GPT-4 untuk menjana tugas simulasi secara automatik dan memindahkannya ke dunia nyata

- PHPzke hadapan
- 2023-10-16 14:21:041779semak imbas

Dalam bidang robotik, melaksanakan strategi robotik sejagat memerlukan sejumlah besar data, dan mengumpul data ini di dunia nyata memakan masa dan susah payah. Walaupun simulasi menyediakan penyelesaian yang menjimatkan untuk menjana volum data yang berbeza pada peringkat kejadian dan contoh, peningkatan kepelbagaian tugas dalam persekitaran simulasi masih menghadapi cabaran disebabkan oleh jumlah tenaga kerja yang besar yang diperlukan (terutama untuk tugas yang kompleks). Ini menghasilkan tanda aras simulasi tiruan biasa yang biasanya mengandungi hanya puluhan hingga ratusan tugasan.
Bagaimana untuk menyelesaikannya? Dalam beberapa tahun kebelakangan ini, model bahasa yang besar telah terus membuat kemajuan yang ketara dalam pemprosesan bahasa semula jadi dan penjanaan kod untuk pelbagai tugas. Begitu juga, LLM telah digunakan pada pelbagai aspek robotik, termasuk antara muka pengguna, perancangan tugas dan gerakan, ringkasan log robot, reka bentuk kos dan ganjaran, mendedahkan keupayaan kukuh dalam kedua-dua tugasan berasaskan fizik dan penjanaan kod.
Dalam kajian baru-baru ini, penyelidik dari MIT CSAIL, Shanghai Jiao Tong University dan institusi lain meneroka dengan lebih lanjut sama ada LLM boleh digunakan untuk mencipta pelbagai tugas simulasi dan meneroka keupayaan mereka.
Secara khusus, para penyelidik mencadangkan rangka kerja GenSim berasaskan LLM, yang menyediakan mekanisme automatik untuk mereka bentuk dan mengesahkan susunan aset tugas dan kemajuan tugas. Lebih penting lagi, tugasan yang dihasilkan mempamerkan kepelbagaian yang hebat, mempromosikan generalisasi peringkat tugas bagi strategi robot. Tambahan pula, dari segi konsep, dengan GenSim, keupayaan penaakulan dan pengekodan LLM diperhalusi ke dalam strategi tindakan visual-bahasa melalui sintesis perantaraan data simulasi. Alamat

Paper: https://arxiv.org/pdf/2310.01361.pdf
Rangka kerja Gensim terdiri daripada tiga bahagian berikut:
- Tugas dan mekanisme segera untuk yang sepadan pelaksanaan kod;
- Kedua, pustaka tugasan yang menjana kod arahan berkualiti tinggi sebelum ini untuk pengesahan dan penalaan model bahasa, dan mengembalikannya sebagai set data tugasan yang komprehensif
- Akhir sekali, penggunaan bahasa-; talian paip latihan dasar pelbagai tugas yang ditala yang menjana data untuk meningkatkan generalisasi peringkat tugas.
Rangka kerja beroperasi melalui dua mod berbeza pada masa yang sama. Antaranya, dalam tetapan berorientasikan matlamat, pengguna mempunyai tugas tertentu atau ingin mereka bentuk kursus tugas. Pada masa ini, GenSim menggunakan pendekatan atas ke bawah, mengambil tugas yang dijangkakan sebagai input dan secara berulang menjana tugas berkaitan untuk mencapai matlamat yang diharapkan. Dalam persekitaran penerokaan, jika terdapat kekurangan pengetahuan awal tentang tugas sasaran, GenSim secara beransur-ansur meneroka kandungan di luar tugasan sedia ada dan menetapkan strategi asas yang bebas daripada tugas.
Dalam Rajah 1 di bawah, penyelidik memulakan perpustakaan tugasan yang mengandungi 10 tugasan yang disusun secara manual, menggunakan GenSim untuk melanjutkannya dan menjana lebih daripada 100 tugasan.

Para penyelidik juga mencadangkan beberapa metrik tersuai untuk mengukur secara progresif kualiti tugasan simulasi yang dijana, dan menilai beberapa LLM dalam tetapan berorientasikan matlamat dan penerokaan. Untuk perpustakaan tugasan yang dijana oleh GPT-4, mereka melakukan penalaan halus diselia pada LLM seperti GPT-3.5 dan Code-Llama, meningkatkan lagi prestasi penjanaan tugas LLM. Pada masa yang sama, kebolehcapaian tugasan diukur secara kuantitatif melalui latihan strategi, dan statistik tugasan atribut yang berbeza dan perbandingan kod antara model yang berbeza disediakan.
Bukan itu sahaja, para penyelidik juga melatih strategi robot berbilang tugas yang menyamaratakan dengan baik pada semua tugasan generasi dan meningkatkan prestasi sifar pukulan berbanding model yang dilatih hanya pada tugasan perancangan manusia. Latihan bersama dengan tugas penjanaan GPT-4 meningkatkan prestasi generalisasi sebanyak 50% dan memindahkan kira-kira 40% tugasan sifar kepada tugasan baharu dalam simulasi.
Akhirnya, penyelidik juga mempertimbangkan pemindahan simulasi kepada sebenar, menunjukkan bahawa pra-latihan pada tugas simulasi yang berbeza boleh meningkatkan keupayaan generalisasi dunia sebenar sebanyak 25%.
Ringkasnya, dasar yang dilatih mengenai tugas yang dihasilkan oleh LLM yang berbeza mencapai generalisasi peringkat tugasan yang lebih baik kepada tugasan baharu, menyerlahkan potensi melanjutkan tugasan simulasi melalui LLM untuk melatih dasar asas.
#🎜🎜 #Pengarah pengurusan produk Tenstorrent AI Shubham Saboo memberikan pujian tinggi kepada penyelidikan ini. Beliau berkata ini adalah penyelidikan terobosan mengenai GPT-4 yang digabungkan dengan robot, menggunakan LLM seperti GPT-4 untuk menjana autopilot tugasan robot simulasi menjadikan pembelajaran sampel sifar dan penyesuaian dunia sebenar robot menjadi realiti.

Pengenalan kaedah#####🎜🎜🎜 Seperti yang ditunjukkan dalam Rajah 2 di bawah, rangka kerja GenSim menjana persekitaran simulasi, tugasan dan demonstrasi melalui sintesis program. Saluran paip GenSim bermula daripada pencipta tugas, dan rantaian segera berjalan dalam dua mod, mod terarah matlamat dan mod penerokaan, bergantung pada tugas sasaran. Pustaka tugas dalam GenSim ialah komponen dalam memori yang digunakan untuk menyimpan tugasan berkualiti tinggi yang dijana sebelum ini Tugasan yang disimpan dalam pustaka tugas boleh digunakan untuk latihan dasar berbilang tugas atau LLM menyempurnakan.
 #🎜🎜 ###Task Creator🎜🎜 ###Task Creator🎜
#🎜🎜 ###Task Creator🎜🎜 ###Task Creator🎜
Seperti yang ditunjukkan dalam Rajah 3 di bawah, rantai bahasa akan mula-mula menjana penerangan tugas, dan kemudian menjana pelaksanaan yang berkaitan. Perihalan tugas termasuk nama tugas, sumber dan ringkasan tugas. Kajian ini menggunakan gesaan beberapa sampel dalam perancangan untuk menjana kod.
#Task Library🎜🎜##Task Library#🎜 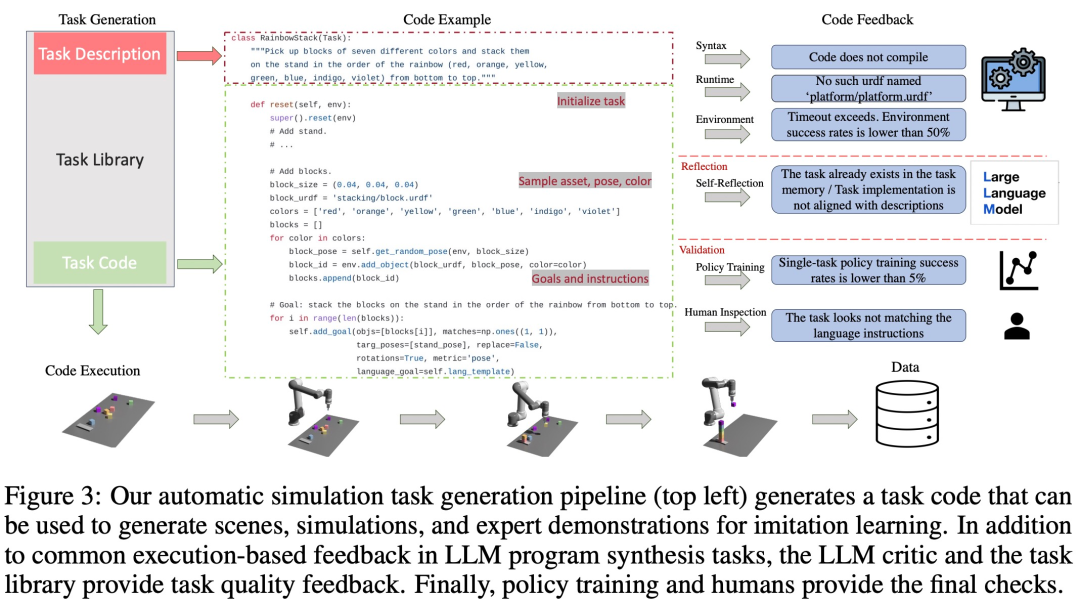 Pustaka tugas dalam rangka kerja GenSim menyimpan tugas yang dijana oleh pencipta tugas untuk menjana tugas baharu yang lebih baik dan melatih strategi pelbagai tugas. Pustaka tugasan dimulakan berdasarkan tugasan daripada penanda aras yang dibuat secara manual.
Pustaka tugas dalam rangka kerja GenSim menyimpan tugas yang dijana oleh pencipta tugas untuk menjana tugas baharu yang lebih baik dan melatih strategi pelbagai tugas. Pustaka tugasan dimulakan berdasarkan tugasan daripada penanda aras yang dibuat secara manual.
Pustaka tugas menyediakan pencipta tugasan dengan perihalan tugasan sebelumnya sebagai syarat untuk fasa penjanaan penerangan, menyediakan kod sebelumnya untuk fasa penjanaan kod dan menggesa tugasan penciptaan Pengkompil memilih tugas rujukan daripada perpustakaan tugasan sebagai contoh untuk menulis tugasan baharu. Selepas pelaksanaan tugas selesai dan semua ujian telah lulus, LLM digesa untuk "merefleksikan" pada tugasan baharu dan pustaka tugasan, dan membentuk keputusan komprehensif sama ada tugasan yang baru dijana perlu ditambahkan ke perpustakaan.
Seperti yang ditunjukkan dalam Rajah 4 di bawah, kajian juga mendapati bahawa GenSim mempamerkan gabungan peringkat tugasan dan tingkah laku ekstrapolasi yang menarik: #🎜 🎜 #
LLM Supervised Multitasking Strategy#🎜#
#🎜##🎜##🎜🎜 🎜🎜#Selepas menjana tugas, kajian ini menggunakan pelaksanaan tugas ini untuk menjana data demonstrasi dan melatih strategi operasi, menggunakan seni bina rangkaian penghantaran dwi-strim yang serupa dengan Shridhar et al (2022). 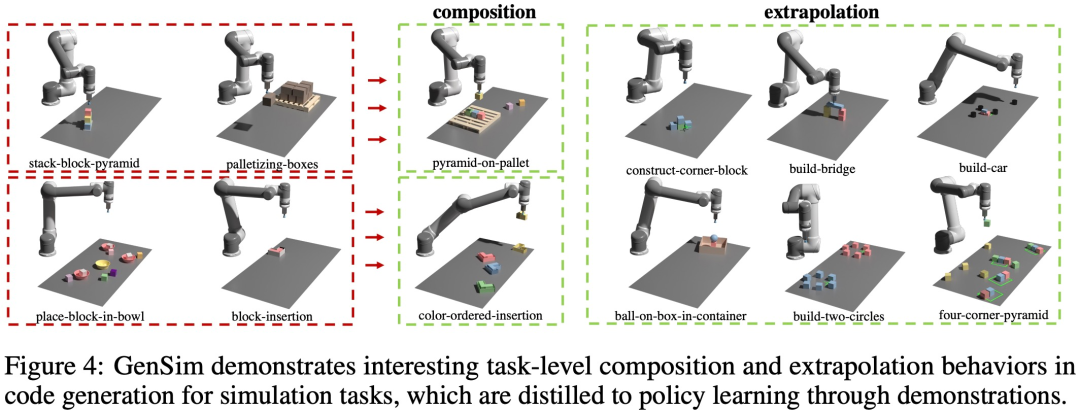
Eksperimen dan keputusan#🎜🎜🎜🎜🎜🎜🎜 #
Kajian ini mengesahkan rangka kerja GenSim melalui eksperimen dan menangani soalan khusus berikut: (1) Sejauh manakah LLM berkesan dalam mereka bentuk dan melaksanakan tugas simulasi? Bolehkah GenSim meningkatkan prestasi LLM dalam penjanaan tugas? (2) Bolehkah latihan mengenai tugas yang dihasilkan oleh LLM meningkatkan keupayaan generalisasi dasar? Adakah latihan dasar akan mendapat lebih banyak manfaat jika diberi lebih banyak tugas generasi? (3) Adakah pra-latihan tentang tugasan simulasi yang dijana oleh LLM memudahkan penggunaan dasar robot dunia sebenar?
Nilai keupayaan generalisasi tugas simulasi robot LLM  #🎜🎜🎜🎜🎜🎜🎜 seperti berikut Seperti yang ditunjukkan dalam Rajah 6, untuk mod penerokaan dan penjanaan tugas mod berorientasikan matlamat, rantaian segera dua peringkat bagi beberapa sampel dan perpustakaan tugasan boleh meningkatkan kadar kejayaan penjanaan kod dengan berkesan.
#🎜🎜🎜🎜🎜🎜🎜 seperti berikut Seperti yang ditunjukkan dalam Rajah 6, untuk mod penerokaan dan penjanaan tugas mod berorientasikan matlamat, rantaian segera dua peringkat bagi beberapa sampel dan perpustakaan tugasan boleh meningkatkan kadar kejayaan penjanaan kod dengan berkesan.
Task Level Generalization🎜🎜 # Pengoptimuman strategi beberapa pukulan untuk tugasan yang berkaitan. Seperti yang boleh diperhatikan dari sebelah kiri Rajah 7 di bawah, latihan bersama tugas yang dijana oleh LLM boleh meningkatkan prestasi dasar pada tugasan CLIPort asal sebanyak lebih daripada 50%, terutamanya dalam situasi data rendah (seperti 5 demo). Pengitraman dasar sifar kepada tugas yang tidak kelihatan. Seperti yang dapat dilihat dalam Rajah 7, dengan pra-latihan pada lebih banyak tugas yang dihasilkan oleh LLM, model kami boleh membuat generalisasi dengan lebih baik kepada tugas dalam penanda aras Ravens yang asal. Di bahagian tengah sebelah kanan Rajah 7, penyelidik juga telah melatih 5 tugasan pada sumber tugasan yang berbeza, termasuk tugasan tulisan manusia, LLM sumber tertutup dan LLM diperhalusi sumber terbuka, dan memerhatikan tugasan sifar pukulan yang serupa- generalisasi tahap. . Keputusan ditunjukkan dalam Jadual 1 di bawah Model pra-latihan pada 70 GPT-4 menjana tugasan menjalankan 10 eksperimen pada 9 tugasan dan mencapai kadar kejayaan purata 68.8%, yang lebih baik daripada pra-latihan pada tugasan CLIPort sahaja. Berbanding dengan model garis dasar, ia telah bertambah baik sebanyak lebih daripada 25%, dan berbanding dengan model yang telah dilatih pada hanya 50 tugasan, ia telah bertambah baik sebanyak 15%. Para penyelidik juga memerhatikan bahawa pra-latihan pada tugas simulasi yang berbeza meningkatkan keteguhan tugas kompleks jangka panjang. Sebagai contoh, model pra-latihan GPT-4 menunjukkan prestasi yang lebih mantap pada tugas binaan dunia sebenar.
Eksperimen Ablation Kadar kejayaan latihan simulasi. Dalam Jadual 2 di bawah, penyelidik menunjukkan kadar kejayaan latihan dasar tugasan tunggal dan berbilang tugas pada subset tugasan yang dijana dengan 200 tunjuk cara. Untuk latihan dasar mengenai tugas penjanaan GPT-4, kadar kejayaan tugas puratanya ialah 75.8% untuk tugasan tunggal dan 74.1% untuk berbilang tugas. Jana statistik tugasan. Dalam Rajah 9 (a) di bawah, penyelidik menunjukkan statistik tugasan bagi ciri-ciri berbeza bagi 120 tugasan yang dihasilkan oleh LLM. Terdapat keseimbangan yang menarik antara warna, aset, tindakan dan bilangan kejadian yang dijana oleh model LLM. Sebagai contoh, kod yang dijana mengandungi banyak adegan dengan lebih daripada 7 tika objek, serta banyak tindakan primitif pilih-dan-tempat dan aset seperti blok.




Atas ialah kandungan terperinci Bahasa, pemecahan robot, MIT dan lain-lain menggunakan GPT-4 untuk menjana tugas simulasi secara automatik dan memindahkannya ke dunia nyata. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- python如何处理excel数据
- spss数据分析方法有哪五种
- Latihan tersuai bagi model pembelajaran mendalam menggunakan teknik pembelajaran pemindahan
- Senarai teratas antarabangsa yang berwibawa bagi penghuraian semantik perbualan SParC dan CoSQL, model pra-latihan pengetahuan meja dialog pelbagai pusingan baharu tafsiran STAR
- Artikel pertama: Paradigma baharu untuk melatih model penghunian 3D berbilang paparan menggunakan label 2D sahaja