
Rumah >Peranti teknologi >AI >Fahami apa itu pembelajaran mesin dalam satu artikel
Fahami apa itu pembelajaran mesin dalam satu artikel

- WBOYke hadapan
- 2023-05-21 23:01:583575semak imbas
Dunia dipenuhi dengan data – imej, video, hamparan, audio dan teks yang dijana oleh manusia dan komputer membanjiri internet, menenggelamkan kita dalam lautan maklumat.
Secara tradisinya, manusia menganalisis data untuk membuat keputusan yang lebih termaklum dan berusaha untuk melaraskan sistem untuk mengawal perubahan dalam corak data. Walau bagaimanapun, apabila jumlah maklumat masuk meningkat, keupayaan kami untuk memahaminya berkurangan, meninggalkan kami dengan cabaran berikut:
Bagaimanakah kami menggunakan semua data ini untuk memperoleh makna secara automatik dan bukannya manual?
Di sinilah pembelajaran mesin dimainkan. Artikel ini akan memperkenalkan:
- Apakah pembelajaran mesin
- Elemen utama algoritma pembelajaran mesin
- Cara pembelajaran mesin berfungsi
- 6 fakta sebenar Mesin Aplikasi Pembelajaran di Dunia
- Cabaran dan Had Pembelajaran Mesin
Ramalan ini dibuat oleh mesin mempelajari corak daripada set data yang dipanggil "data latihan", dan ia boleh memacu pembangunan teknologi selanjutnya untuk meningkatkan kehidupan orang ramai.
1 Apakah Pembelajaran Mesin
Pembelajaran mesin ialah konsep yang membolehkan komputer belajar secara automatik daripada contoh dan pengalaman serta meniru pembuatan keputusan manusia tanpa diprogramkan secara eksplisit.
Pembelajaran mesin ialah satu cabang kecerdasan buatan yang menggunakan algoritma dan teknik statistik untuk belajar daripada data dan memperoleh corak serta cerapan tersembunyi.
Sekarang, mari kita terokai selok-belok pembelajaran mesin dengan lebih mendalam.
2 Elemen Utama Algoritma Pembelajaran Mesin
Terdapat puluhan ribu algoritma dalam pembelajaran mesin, yang boleh dikumpulkan mengikut gaya pembelajaran atau sifat masalah yang sedang diselesaikan. Tetapi setiap algoritma pembelajaran mesin mengandungi komponen utama berikut:
- Data latihan – merujuk kepada teks, imej, video atau maklumat siri masa yang mana sistem pembelajaran mesin mesti belajar . Data latihan sering dilabelkan untuk menunjukkan sistem ML tentang "jawapan yang betul", seperti kotak sempadan di sekeliling muka dalam pengesan muka, atau prestasi stok masa hadapan dalam peramal stok.
- bermaksud - ia merujuk kepada perwakilan yang dikodkan bagi objek dalam data latihan, seperti wajah yang diwakili oleh ciri seperti "mata". Mengekodkan sesetengah model adalah lebih mudah daripada yang lain, dan inilah yang mendorong pemilihan model. Sebagai contoh, rangkaian saraf membentuk satu perwakilan, dan menyokong mesin vektor yang lain. Kebanyakan kaedah moden menggunakan rangkaian saraf.
- Penilaian - Ini adalah tentang cara kita menilai atau mengenal pasti satu model berbanding model yang lain. Kami biasanya memanggilnya fungsi utiliti, fungsi kehilangan atau fungsi pemarkahan. Purata ralat kuasa dua (keluaran model berbanding output data) atau kemungkinan (kebarangkalian anggaran model yang diberi data yang diperhatikan) adalah contoh fungsi penilaian yang berbeza.
- Pengoptimuman - Ini merujuk kepada cara mencari ruang yang mewakili model atau menambah baik label dalam data latihan untuk mendapatkan penilaian yang lebih baik. Pengoptimuman bermaksud mengemas kini parameter model untuk meminimumkan nilai fungsi kehilangan. Ia membantu model meningkatkan ketepatannya pada kadar yang lebih pantas.
Di atas ialah klasifikasi terperinci bagi empat komponen algoritma pembelajaran mesin.
Fungsi Sistem Pembelajaran Mesin
Deskriptif: Sistem mengumpul data sejarah, menyusunnya dan kemudian membentangkannya dengan cara yang mudah difahami.
Fokus utama adalah untuk memahami perkara yang sudah berlaku dalam perusahaan dan bukannya membuat inferens atau ramalan daripada penemuannya. Analitis deskriptif menggunakan alat matematik dan statistik mudah seperti aritmetik, purata dan peratusan berbanding pengiraan kompleks yang diperlukan untuk analitik ramalan dan preskriptif.
Analisis deskriptif terutamanya menganalisis dan menyimpulkan data sejarah, manakala analisis ramalan memfokuskan pada meramal dan memahami kemungkinan situasi masa depan.
Menganalisis corak dan aliran data masa lalu dengan melihat data sejarah boleh meramalkan perkara yang mungkin berlaku pada masa hadapan.
Analisis preskriptif memberitahu kita cara bertindak, manakala analisis deskriptif memberitahu kita apa yang berlaku pada masa lalu. Analitik ramalan memberitahu kita perkara yang mungkin berlaku pada masa hadapan dengan belajar daripada masa lalu. Tetapi apabila kita mendapat gambaran tentang apa yang mungkin berlaku, apakah yang perlu kita lakukan?
Ini adalah analisis normatif. Ia membantu sistem menggunakan pengetahuan lepas untuk membuat beberapa pengesyoran tentang tindakan yang boleh diambil oleh seseorang. Analitis preskriptif boleh memodelkan senario dan menyediakan laluan untuk mencapai hasil yang diinginkan.
3 Cara pembelajaran mesin berfungsi
Pembelajaran algoritma ML boleh dibahagikan kepada tiga bahagian utama.
Proses Membuat Keputusan
Model pembelajaran mesin direka bentuk untuk mempelajari corak daripada data dan menggunakan pengetahuan ini untuk membuat ramalan. Persoalannya ialah: Bagaimanakah model membuat ramalan?
Proses ini sangat asas - cari corak dalam data input (berlabel atau tidak berlabel) dan gunakannya untuk memperoleh hasil.
Fungsi ralat
Model pembelajaran mesin direka bentuk untuk membandingkan ramalan yang mereka buat berdasarkan kebenaran. Matlamatnya adalah untuk memahami sama ada ia belajar ke arah yang betul. Ini menentukan ketepatan model dan mencadangkan cara kami boleh menambah baik latihan model.
Proses Pengoptimuman Model
Matlamat utama model adalah untuk memperbaik ramalan, yang bermaksud mengurangkan perbezaan antara hasil yang diketahui dan anggaran model yang sepadan.
Model perlu menyesuaikan diri dengan lebih baik kepada sampel data latihan dengan sentiasa mengemas kini pemberat. Algoritma berfungsi dalam gelung, menilai dan mengoptimumkan keputusan, mengemas kini pemberat, sehingga nilai maksimum diperoleh mengenai ketepatan model.
Jenis kaedah pembelajaran mesin
Pembelajaran mesin terutamanya merangkumi empat jenis.
1. Pembelajaran mesin diselia
Dalam pembelajaran diselia, seperti namanya, mesin belajar di bawah bimbingan.
Ini dilakukan dengan memberi komputer satu set data berlabel supaya mesin memahami apa input dan output yang sepatutnya. Di sini, manusia bertindak sebagai panduan, menyediakan model dengan data latihan berlabel (pasangan input-output) dari mana mesin mempelajari corak.
Setelah hubungan antara input dan output dipelajari daripada set data sebelumnya, mesin boleh meramalkan nilai output data baharu dengan mudah.
Di manakah kita boleh menggunakan pembelajaran diselia?
Jawapannya ialah: apabila kita tahu apa yang perlu dicari dalam data input dan apa yang kita mahu sebagai output.
Jenis utama masalah pembelajaran yang diselia termasuk masalah regresi dan klasifikasi.
2. Pembelajaran Mesin Tanpa Selia
Pembelajaran tanpa seliaan berfungsi betul-betul bertentangan dengan pembelajaran diselia.
Ia menggunakan data tidak berlabel - mesin perlu memahami data, mencari corak tersembunyi dan membuat ramalan dengan sewajarnya.
Di sini, mesin memberikan kita penemuan baharu selepas secara bebas memperoleh corak tersembunyi daripada data, tanpa manusia perlu menentukan perkara yang perlu dicari.
Jenis utama masalah pembelajaran tanpa penyeliaan termasuk pengkelompokan dan analisis peraturan persatuan.
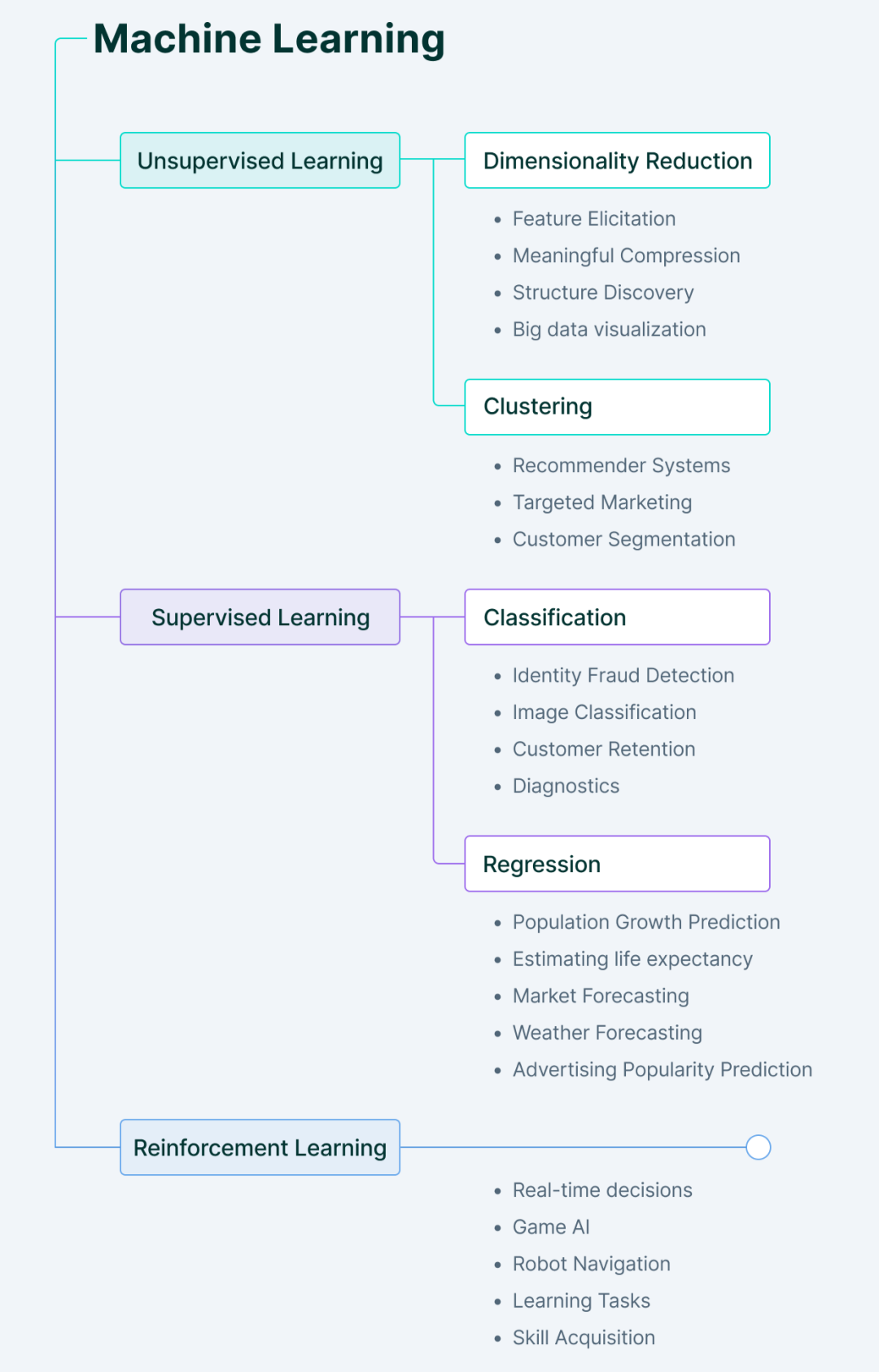
3. Pembelajaran Peneguhan
Pembelajaran peneguhan melibatkan agen yang belajar untuk berkelakuan dalam persekitaran dengan melakukan tindakan.
Berdasarkan keputusan tindakan ini, ia memberikan maklum balas dan menyesuaikan perjalanan masa hadapan - untuk setiap tindakan yang baik, ejen mendapat maklum balas positif, dan untuk setiap tindakan buruk, ejen mendapat maklum balas atau hukuman negatif.
Pembelajaran pengukuhan belajar tanpa sebarang data berlabel. Oleh kerana tiada data berlabel, ejen hanya boleh belajar berdasarkan pengalamannya sendiri.
4. Pembelajaran separuh penyeliaan
Separuh penyeliaan ialah keadaan antara pembelajaran diselia dan tidak diselia.
Ia mengambil aspek positif daripada setiap pembelajaran, iaitu menggunakan set data berlabel yang lebih kecil untuk membimbing pengelasan dan melaksanakan pengekstrakan ciri tanpa pengawasan daripada set data tidak berlabel yang lebih besar.
Kelebihan utama menggunakan pembelajaran separa penyeliaan ialah keupayaannya untuk menyelesaikan masalah apabila data berlabel tidak mencukupi untuk melatih model, atau apabila data itu tidak boleh dilabelkan kerana manusia tidak tahu apa yang perlu dilihat kerana di dalamnya.
Empat 6 Aplikasi Pembelajaran Mesin Dunia Sebenar
Pembelajaran mesin adalah nadi hampir setiap syarikat teknologi hari ini, termasuk perniagaan seperti Google atau enjin carian Youtube.
Di bawah, kami telah meringkaskan beberapa contoh aplikasi sebenar pembelajaran mesin yang mungkin anda kenali:
Kereta pandu sendiri
Kenderaan menghadapi pelbagai situasi di jalan raya.
Untuk kereta pandu sendiri berprestasi lebih baik daripada manusia, mereka perlu belajar dan menyesuaikan diri dengan perubahan keadaan jalan dan tingkah laku kenderaan lain.
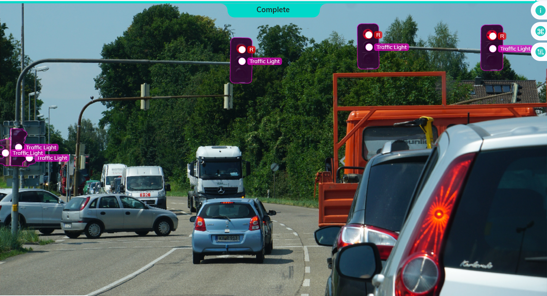
Kereta pandu sendiri mengumpul data tentang persekitarannya daripada penderia dan kamera, kemudian tafsirkannya dan bertindak balas dengan sewajarnya. Ia menggunakan pembelajaran diselia untuk mengenal pasti objek sekeliling, pembelajaran tanpa pengawasan untuk mengenal pasti corak dalam kenderaan lain, dan akhirnya mengambil tindakan sewajarnya dengan bantuan algoritma pengukuhan.
Analisis Imej dan Pengesanan Objek
Analisis imej digunakan untuk mengekstrak maklumat yang berbeza daripada imej.
Ia mempunyai aplikasi dalam bidang seperti memeriksa kecacatan pembuatan, menganalisis trafik kereta di bandar pintar atau enjin carian visual seperti Google Lens.
Idea utama ialah menggunakan teknik pembelajaran mendalam untuk mengekstrak ciri daripada imej dan kemudian menggunakan ciri ini pada pengesanan objek.
Customer Service Chatbots
Adalah perkara biasa hari ini untuk syarikat menggunakan AI chatbots untuk menyediakan sokongan dan jualan pelanggan. AI chatbots membantu perniagaan mengendalikan jumlah pertanyaan pelanggan yang tinggi dengan menyediakan sokongan 24/7, sekali gus mengurangkan kos sokongan dan menjana pendapatan tambahan serta pelanggan yang gembira.
Robotik AI menggunakan pemprosesan bahasa semula jadi (NLP) untuk memproses teks, mengekstrak kata kunci pertanyaan dan bertindak balas dengan sewajarnya.
Pengimejan dan Diagnostik Perubatan
Kebenarannya ialah: data pengimejan perubatan adalah sumber maklumat yang paling kaya dan paling kompleks.
Menganalisis beribu-ribu imej perubatan secara manual adalah tugas yang membosankan dan membuang masa yang berharga untuk ahli patologi yang boleh digunakan dengan lebih cekap.
Tetapi ini bukan sahaja tentang menjimatkan masa – ciri kecil seperti artifak atau nodul mungkin tidak dapat dilihat dengan mata kasar, menyebabkan kelewatan dalam diagnosis penyakit dan ramalan yang salah. Inilah sebabnya mengapa terdapat begitu banyak potensi menggunakan teknik pembelajaran mendalam yang melibatkan rangkaian saraf, yang boleh digunakan untuk mengekstrak ciri daripada imej.
Pengenalpastian Penipuan
Apabila sektor e-dagang berkembang, kita dapat melihat peningkatan dalam bilangan transaksi dalam talian dan kepelbagaian kaedah pembayaran yang tersedia. Malangnya, sesetengah orang mengambil kesempatan daripada keadaan ini. Penipu di dunia hari ini berkemahiran tinggi dan boleh menggunakan teknologi baharu dengan cepat.
Itulah sebabnya kami memerlukan sistem yang boleh menganalisis corak data, membuat ramalan yang tepat dan bertindak balas terhadap ancaman keselamatan siber dalam talian seperti percubaan log masuk palsu atau serangan pancingan data.
Sebagai contoh, sistem pencegahan penipuan boleh mengetahui sama ada pembelian adalah sah berdasarkan tempat anda membuat pembelian pada masa lalu atau berapa lama anda berada dalam talian. Begitu juga, mereka boleh mengesan jika seseorang cuba menyamar sebagai anda dalam talian atau melalui telefon.
Algoritma Pengesyoran
Kaitan algoritma pengesyoran ini adalah berdasarkan kajian data sejarah dan bergantung pada beberapa faktor, termasuk pilihan dan minat pengguna.
Syarikat seperti JD.com atau Douyin menggunakan sistem pengesyoran untuk memilih dan memaparkan kandungan atau produk yang berkaitan kepada pengguna/pembeli.
Lima Cabaran dan Had Pembelajaran Mesin
Underfitting dan Overfitting
Dalam kebanyakan kes, sebab prestasi lemah mana-mana algoritma pembelajaran mesin adalah Disebabkan oleh underfitting dan overfitting.
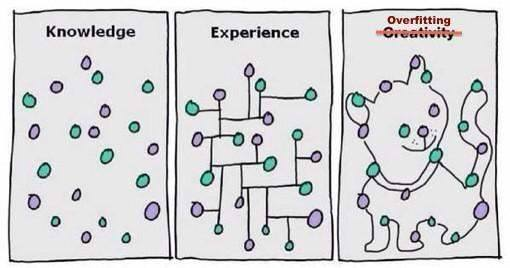
Mari kita pecahkan istilah ini dalam konteks melatih model pembelajaran mesin.
- Underfitting ialah senario di mana model pembelajaran mesin tidak dapat mempelajari hubungan antara pembolehubah dalam data mahupun meramal titik data baharu dengan betul. Dalam erti kata lain, sistem pembelajaran mesin tidak mengesan arah aliran merentas titik data.
- Pemasangan berlebihan berlaku apabila model pembelajaran mesin belajar terlalu banyak daripada data latihan, memberi perhatian kepada titik data yang sememangnya bising atau tidak berkaitan dengan julat set data. Ia cuba untuk menyesuaikan setiap titik pada lengkung dan oleh itu mengingati corak data.
Memandangkan model mempunyai sedikit fleksibiliti, ia tidak boleh meramal titik data baharu. Dalam erti kata lain, ia terlalu menumpukan pada contoh yang diberikan dan gagal untuk melihat gambaran yang lebih besar.
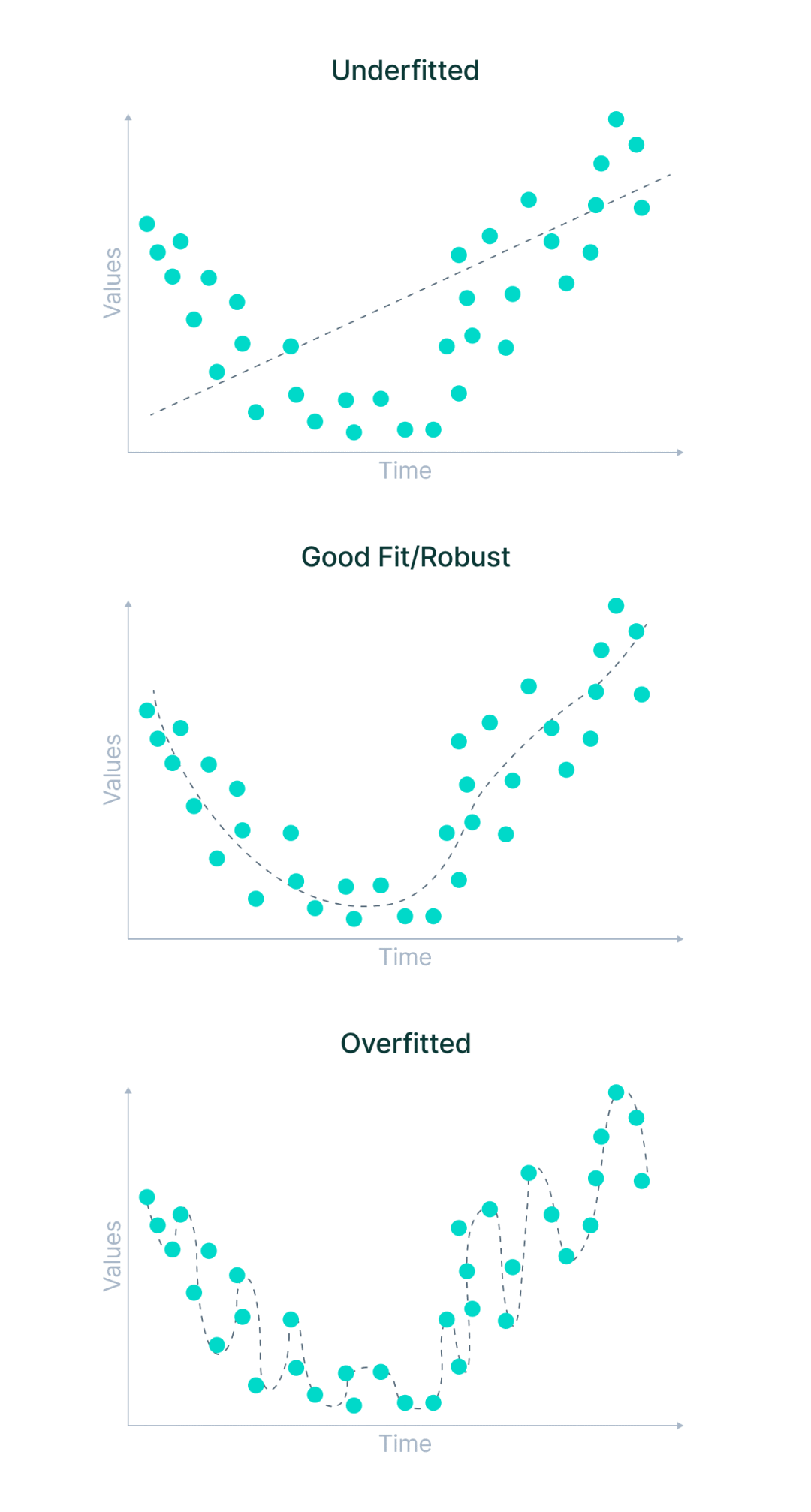
Apakah punca underfitting dan overfitting?
Kes yang lebih umum termasuk situasi di mana data yang digunakan untuk latihan tidak bersih dan mengandungi banyak bunyi bising atau nilai sampah, atau saiz data terlalu kecil. Walau bagaimanapun, terdapat beberapa sebab yang lebih spesifik.
Mari kita lihat perkara tersebut.
Underfitting mungkin berlaku kerana:
- Model telah dilatih dengan parameter yang salah dan data latihan tidak diperhatikan sepenuhnya
- Model terlalu mudah dan tidak mengingati ciri yang mencukupi
- Data latihan terlalu pelbagai atau kompleks
Pemasangan berlebihan boleh berlaku apabila:
- Model dilatih dengan parameter yang salah dan terlalu memerhati data latihan
- Model itu terlalu kompleks dan tidak terlatih terlebih dahulu pada data yang lebih pelbagai.
- Label data latihan terlalu ketat atau data asal terlalu seragam dan tidak mewakili pengedaran sebenar.

Dimensi
Ketepatan mana-mana model pembelajaran mesin adalah berkadar terus dengan dimensi set data. Tetapi ia hanya berfungsi sehingga ambang tertentu.
Dimensi set data merujuk kepada bilangan atribut/ciri yang terdapat dalam set data. Meningkatkan bilangan dimensi secara eksponen membawa kepada penambahan atribut tidak penting yang mengelirukan model, sekali gus mengurangkan ketepatan model pembelajaran mesin.
Kami memanggil kesukaran ini yang dikaitkan dengan melatih model pembelajaran mesin sebagai "kutukan dimensi".
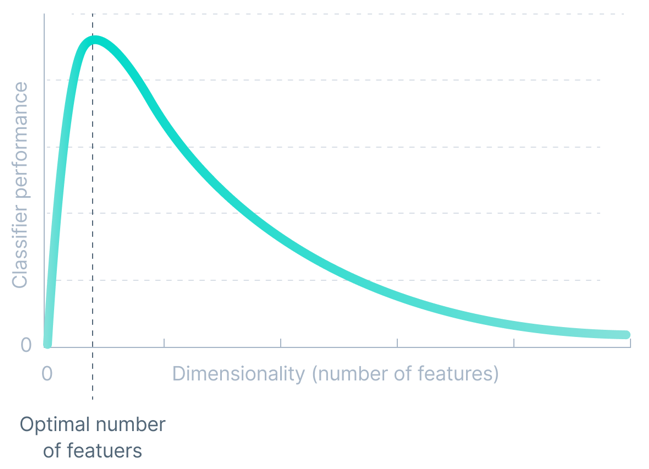
Kualiti Data
Algoritma pembelajaran mesin sensitif kepada data latihan berkualiti rendah.
Kualiti data mungkin terjejas disebabkan oleh hingar dalam data yang disebabkan oleh data yang salah atau nilai yang hilang. Walaupun ralat yang agak kecil dalam data latihan boleh membawa kepada ralat berskala besar dalam output sistem.
Apabila algoritma berprestasi buruk, ia biasanya disebabkan oleh isu kualiti data seperti data kuantiti/skew/bising yang tidak mencukupi atau ciri yang tidak mencukupi untuk menerangkan data.
Oleh itu, sebelum melatih model pembelajaran mesin, pembersihan data selalunya diperlukan untuk mendapatkan data berkualiti tinggi.
Atas ialah kandungan terperinci Fahami apa itu pembelajaran mesin dalam satu artikel. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI