
Rumah >Peranti teknologi >AI >Penyelidikan tentang kemungkinan membina model bahasa visual daripada satu set perkataan
Penyelidikan tentang kemungkinan membina model bahasa visual daripada satu set perkataan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-21 23:22:041495semak imbas
Penterjemah | Pada masa ini,
kecerdasan buatan pelbagai modtelah menjaditopik hangat yang dibincangkan di jalanan. Dengan keluaran GPT-4 baru-baru ini, kami melihat banyak kemungkinan aplikasi baharu dan teknologi masa hadapan yang tidak dapat dibayangkan hanya enam bulan lalu. Malah, model bahasa visual secara amnya berguna untuk banyak tugas yang berbeza. Sebagai contoh, anda boleh menggunakan CLIP
(Pra-latihan Bahasa-Imej Kontrastif,iaitu "Pra-latihan Bahasa-Imej Kontrastif", pautan: https://www.php.cn/link/b02d46e8a3d8d9fd6028f3f2c2495864Pengkelasan imej tangkapan sifar pada set data ghaibbiasa ; 🎜>Pada masa yang sama, model bahasa visual tidak sempurna dalam artikel ini dalam , kami mahu untuk meneroka batasan model ini, menyerlahkan di mana dan sebab model tersebut mungkin gagal Sebenarnya,
artikelini ialah penerangan ringkas/peringkat tinggi tentang kami yang baru diterbitkan kertas kerja Rancangan akan dalam bentuk kertas ICLR 2023 Lisan Diterbitkan artikel tentang kod sumber lengkap , cuma klik pada pautan https://www.php.cn/link/afb992000fcf79ef7a53fffde9c8e044 PengenalanApakah model bahasa visual Model bahasa visual mengeksploitasi hubungan antara data visual dan linguistik telah merevolusikan bidang dengan bekerjasama untuk melaksanakan pelbagai tugasan Walaupun banyak model bahasa visual telah diperkenalkan dalam kesusasteraan sedia ada, CLIP ( lwn. pra-latihan imej bahasa ) masih merupakan model yang paling terkenal dan digunakan secara meluas
Dengan membenamkan imej dan kapsyen dalam ruang vektor yang sama, model CLIP membenarkan<.> untuk melakukan
penaakulan rentas mod, membolehkan pengguna melaksanakan tugas seperti imej tangkapan sifar dengan ketepatan yang baik Tugasan seperti pengelasan dan perolehan teks-ke-imej Dan, model CLIP menggunakan kaedah pembelajaran kontrastif untuk mempelajari pembenaman imej dan kapsyen > Pembelajaran kontrastif membolehkan model CLIP belajar mengaitkan imej dengan kapsyen model CLIP dan lain-lain dengan meminimumkan jarak antara imej dalam perkongsian. ruang vektor. Hasil mengagumkan yang dicapai oleh model berasaskan kontras membuktikan bahawa pendekatan ini sangat berkesan digunakan dalam kumpulan perbandingan imej dan kapsyen, dan mengoptimumkan. model untuk memaksimumkan persamaan antara pembenaman pasangan teks imej yang sepadan dan mengurangkan persamaan antara pasangan teks imej lain dalam Persamaan kelompok. Rajah di bawah
menunjukkancontoh langkah batching dan latihan yang mungkin , Antaranya :
- Petak berwarna ungu mengandungi benaman untuk semua tajuk dan petak hijau mengandungi benaman untuk semua imej.
- Kuasa segi empat matriks mengandungi hasil darab titik semua benam imej dan semua benam teks dalam kelompok (dibaca sebagai "persamaan kosinus" kerana benam adalah dinormalkan).
- Segi empat sama biru mengandungi produk titik antara pasangan teks imej yang model mesti memaksimumkan persamaan, segi empat sama putih yang lain ialah persamaan yang ingin kita kurangkan (kerana setiap petak ini mengandungi persamaan dalam pasangan teks imej yang tidak sepadan, seperti imej kucing dan penerangan "kerusi vintaj saya" (kerusi vintaj saya).
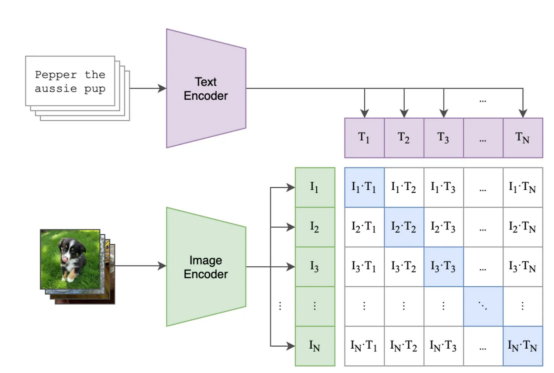
Kontras pra-latihan dalam model CLIP (di mana, Petak biru ialah pasangan teks imej yang mana kami ingin mengoptimumkan persamaan )
Selepas latihan, anda seharusnya dapat menjana ruang vektor A yang bermakna untuk mengekod imej dan tajuk sepadan dengan tajuk (mis. cari "anjing di pantai" (anjing di pantai) dalam album foto percutian musim panas 2017), Atau cari label teks yang lebih serupa dengan imej yang diberikan (cth. anda mempunyai sekumpulan imej anjing dan kucing anda dan anda mahu dapat mengenal pasti yang mana). Model bahasa visual seperti CLIP telah menjadi alat yang berkuasa untuk menyelesaikan tugas kecerdasan buatan yang kompleks dengan menyepadukan maklumat visual dan linguistik Keupayaan mereka untuk membenamkan kedua-dua jenis data ini dalam ruang vektor yang dikongsi telah membawa kepada hasil yang tidak pernah berlaku sebelum ini dalam pelbagai jenis. aplikasi. Ketepatan dan Prestasi CemerlangBolehkah Model Bahasa Visual Memahami Bahasa? jawab soalan ini tentang sama ada atau sejauh mana model mendalam boleh memahami bahasa,
Pada masa ini terdapatdi sini, matlamat kami adalah untuk mengkaji model bahasa visual dan keupayaan sintesisnya 🎜>Kami mula-mula mencadangkan set data baharu untuk menguji pemahaman komponen; penanda aras baharu ini dipanggil ARO (Atribusi,
Perhubungan,dan Pesanan: Atribut) Seterusnya, kami meneroka sebab kehilangan kontras mungkin terhad dalam kes ini , kami mencadangkan penyelesaian yang mudah tetapi menjanjikan untuk masalah ini seperti CLIP (dan BLIP baru-baru ini Salesforce) lakukan untuk memahami bahasa? Kami telah mengumpulkan satu set gubahan berasaskan atribut untuk tajuk (cth. "pintu merah dan lelaki berdiri"
mengandungi dua set data): Set data berbeza yang kami buat termasuk Perhubungan, Atribusi dan Susunan. Untuk setiap set data, kami menunjukkan contoh imej dan tajuk yang berbeza. Antaranya,
hanya satu tajuk yang betul, dan model mesti mengenal pasti ini
ini
sebagai tajuk yang betul. AtributUji pemahaman atributHasilnya ialah: "jalan berturap dan rumah putih" (
jalan berturap dan rumah putih- ) jalan putih dan rumah berturap” (白路和狠地的). Ujian hubungan pemahaman tentang hubungan Hasilnya : “kuda itu makan rumput" (kuda sedang makan rumput) dan "rumput sedang makan kuda" (
- Rumput sedang makan rumput). Akhir sekali, Order menguji fleksibiliti model selepas terganggu Keputusan : Kami merombak pengepala set data standard secara rawak (mis., MSCOCO). Bolehkah model bahasa visual mencari kapsyen yang betul untuk dipadankan dengan imej? Tugas itu nampak mudah, kita mahu model itu memahami perbezaan antara "kuda sedang makan rumput" dan "rumput itu makan rumput", bukan? Maksud saya, siapa yang pernah melihat rumput makan?
-
Nah, mungkin itu model BLIP, kerana ia tidak dapat memahami perbezaan antara "kuda itu makan rumput" dan "rumput itu makan rumput. ”:

Model BLIP tidak memahami perbezaan antara "rumput sedang makan rumput" dan "kuda sedang makan rumput" (di mana Mengandungi elemen daripada Set Data Genom Visual , Imej disediakan oleh pengarang )
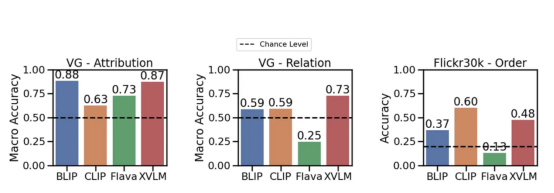
Sekarang , jom lihat eksperimenhasil:Beberapa model boleh melangkaui kemungkinan memahami perhubungan secara meluas (cth., makan——Makan). Walau bagaimanapun, KLIPModel berada dalam Atribut dan Perhubungan Aspek marginal adalah lebih tinggi sedikit daripada kemungkinan ini. Ini sebenarnya menunjukkan bahawa model bahasa visual masih bermasalah.
Model yang berbeza mempunyai atribut, perhubungan dan pesanan (Flick30k ) prestasi pada penanda aras. Yang menggunakan KLIP, BLIP dan model SoTA lain
Penilaian kehilangan semula dan kontrastif
Salah satu hasil utama kerja ini ialah kami mungkin memerlukan lebih daripada kehilangan kontrastif standard untuk mempelajari bahasa. Kenapa ini?
Mari kita mulakan dari awal: model bahasa visual sering dinilai dalam tugasan mendapatkan semula: ambil kapsyen dan cari imej yang dipetakan. Jika anda melihat set data yang digunakan untuk menilai model ini (mis., MSCOCO, Flickr30K), anda akan melihat bahawa ia selalunya mengandungi imej yang diterangkan dengan tajuk , yang Tajuk memerlukan pemahaman tentang gubahan (cth., "kucing oren di atas meja merah ": Kucing oren di atas meja merah). Jadi, jika tajuk adalah rumit, mengapa model tidak boleh mempelajari pemahaman gubahan?
[Penjelasan]Pendapatan semula pada set data ini tidak semestinya memerlukan pemahaman tentang komposisi.
Kami cuba memahami masalah dengan lebih baik dan menguji prestasi model dalam mendapatkan semula apabila merombak susunan perkataan dalam tajuk. Bolehkah kita mencari imej yang betul untuk tajuk "buku yang dilihat orang" ? Jika jawapannya ya ; bermakna , tidak memerlukan maklumat arahan untuk mencari imej yang betul.
Tugas model ujian kami ialah mendapatkan semula menggunakan tajuk yang dikacau. Walaupun kita berebut kapsyen, model boleh mencari imej yang sepadan dengan betul (dan sebaliknya). Ini menunjukkan bahawa tugas mendapatkan semula mungkin terlalu mudah , Imej yang disediakan oleh pengarang.
Kami telah menguji proses shuffle yang berbeza dan hasilnya positif: walaupun dengan 🎜>Teknologi yang luar biasa, prestasi perolehan semula pada dasarnya tidak akan terjejas.
Mari kita katakan sekali lagi: model bahasa visual mencapai perolehan berprestasi tinggi pada set data ini, walaupun apabila maklumat arahan tidak boleh diakses. Model ini mungkin berkelakuan seperti satu timbunan perkataan, di mana susunan tidak penting: jika model tidak perlu memahami susunan perkataan untuk berprestasi baik dalam perolehan semula, jadi apakah yang sebenarnya kita ukur dalam perolehan semula?
Apa yang perlu saya lakukan?
Sekarang kita tahu ada masalah, kita mungkin mahu mencari penyelesaian. Cara paling mudah ialah: biarkan model CLIP memahami bahawa "kucing di atas meja" dan "meja di atas kucing" adalah berbeza.
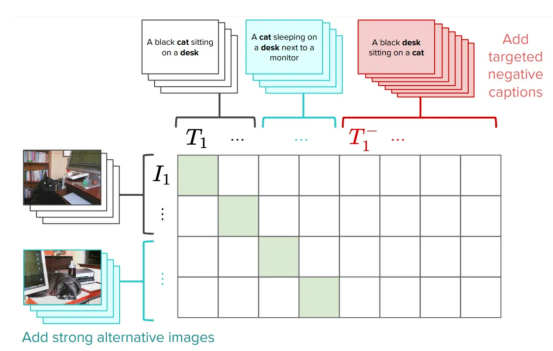
Malah, kami mencadangkan cara ialah penambahbaikan pada CLIP latihan dengan menambah negatif keras yang dibuat khusus untuk menyelesaikan masalah ini. Ini adalah penyelesaian yang sangat mudah dan cekap: ia memerlukan pengeditan yang sangat kecil kepada kehilangan CLIP asal tanpa menjejaskan prestasi keseluruhan (anda boleh membaca beberapa kaveat dalam kertas). Kami memanggil versi CLIP NegCLIP ini.
Pengenalan negatif keras dalam CLIPmodel (Kami menambah imej dan teks keras negatif , Imej disediakan oleh pengarang)
Pada asasnya, kami meminta model NegCLIPuntuk meletakkan imej kucing hitam di atas meja" (hitam kucing duduk di atas meja)berhampiran ayat, tetapi jauh dari ayat" meja hitam duduk di atas kucing" ( meja hitam duduk di atas kucing). Perhatikan bahawa yang terakhir dijana secara automatik dengan menggunakan teg POS. Kesan daripada pembaikan ini ialah ia sebenarnya meningkatkan prestasi penanda aras ARO tanpa menjejaskan prestasi pengambilan semula atau prestasi tugasan hiliran seperti pengambilan semula dan klasifikasi. Lihat rajah di bawah untuk mendapatkan hasil pada penanda aras yang berbeza (lihat artikel ini
kertas sepadanuntuk butiran).
NegCLIP model dan CLIP model pada penanda aras berbeza. Antaranya, penanda aras biru ialah penanda aras yang kami perkenalkan, dan penanda aras hijau datang daripada rangkaiandokumentasi( Imej disediakan oleh pengarang )
Seperti yang anda lihat, terdapat peningkatan yang besar di sini berbanding garis dasar ARO, Terdapat juga penambahbaikan marginal atau prestasi serupa pada tugas hiliran lain.
Pengaturcaraan
Mert( Pengarang utama kertas kerja) telah melakukan kerja yang hebat mencipta perpustakaan kecil untuk menguji model bahasa visual. Anda boleh menggunakan kodnya untuk meniru hasil kami atau bereksperimen dengan model baharu. Ia hanya memerlukan beberapa baris
untuk memuat turun set data dan mula berjalanP bahasa ython :
import clip from dataset_zoo import VG_Relation, VG_Attribution model, image_preprocess = clip.load("ViT-B/32", device="cuda") root_dir="/path/to/aro/datasets" #把 download设置为True将把数据集下载到路径`root_dir`——如果不存在的话 #对于VG-R和VG-A,这将是1GB大小的压缩zip文件——它是GQA的一个子集 vgr_dataset = VG_Relation(image_preprocess=preprocess, download=True, root_dir=root_dir) vga_dataset = VG_Attribution(image_preprocess=preprocess, download=True, root_dir=root_dir) #可以对数据集作任何处理。数据集中的每一项具有类似如下的形式: # item = {"image_options": [image], "caption_options": [false_caption, true_caption]}Selain itu, kami melaksanakan model NegCLIP(Ia sebenarnya salinan OpenCLIP yang dikemas kini), dan alamat muat turun kod lengkapnya ialah https://github.com/vinid/neg_clip. KesimpulanRingkasnya,
Model Bahasa VisualPada masa iniTerdapat banyak perkara yang boleh dilakukan . Seterusnya, Kami tidak sabar untuk melihat model masa depan seperti GPT4 boleh lakukan! Pengenalan PenterjemahZhu Xianzhong, editor komuniti 51CTO, blogger pakar 51CTO, pensyarah, guru komputer di sebuah universiti di Weifang, pengaturcaraan bebas komuniti Seorang veteran.
Tajuk asal:
Model Bahasa Visi Anda Mungkin Sebekas Kata , Pengarang: Federico Bianchi


Atas ialah kandungan terperinci Penyelidikan tentang kemungkinan membina model bahasa visual daripada satu set perkataan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI