
Rumah >Peranti teknologi >AI >Tanda bintang melebihi 100,000! Selepas Auto-GPT, Transformer mencapai pencapaian baharu
Tanda bintang melebihi 100,000! Selepas Auto-GPT, Transformer mencapai pencapaian baharu

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-21 21:34:041363semak imbas
Pada tahun 2017, pasukan Google mencadangkan Transformer seni bina NLP yang terobosan dalam makalah "Perhatian Adalah Semua yang Anda Perlukan", dan ia telah menipu sejak itu.
Sejak bertahun-tahun, seni bina ini telah popular dengan syarikat teknologi besar seperti Microsoft, Google dan Meta. Malah ChatGPT, yang telah melanda dunia, dibangunkan berdasarkan Transformer.
Dan baru hari ini, rating bintang Transformer di GitHub melebihi 100,000!
Hugging Face, yang bermula sebagai program chatbot, menjadi terkenal sebagai bahagian tengah model Transformer, menjadi Komuniti sumber terbuka yang terkenal di dunia.
Untuk meraikan kejayaan ini, Hugging Face turut meringkaskan 100 projek berdasarkan seni bina Transformer.
Transformer meletupkan bulatan pembelajaran mesin
Pada Jun 2017, apabila Google mengeluarkan kertas "Attention Is All You Need", mungkin tiada siapa yang memikirkan seni bina pembelajaran mendalam ini Transformer Berapa banyak kejutan yang boleh dibawanya.
Sejak kelahirannya, Transformer telah menjadi raja asas dalam bidang AI. Pada 2019, Google juga memohon paten khusus untuknya.

Memandangkan Transformer menduduki kedudukan arus perdana dalam bidang NLP, ia juga telah mula menyeberang ke bidang lain, dan semakin banyak kerja telah dimulakan Cuba untuk mengarahkannya ke alam CV.
Ramai netizen sangat teruja melihat Transformer menempuh kejayaan ini.
"Saya telah menjadi penyumbang kepada banyak projek sumber terbuka yang popular, tetapi melihat Transformer mencapai 10 di GitHub Sepuluh ribu bintang , ia masih sangat istimewa!”
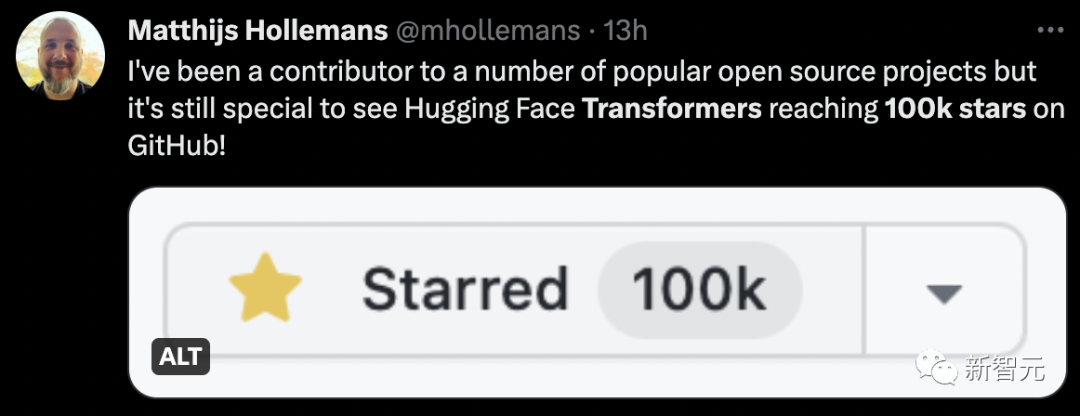
Beberapa masa lalu, bilangan bintang GitHub Auto-GPT melebihi daripada pytorch menyebabkan kekecohan besar.
Netizen pasti tertanya-tanya bagaimana Auto-GPT dibandingkan dengan Transformer?

Malah, Auto-GPT jauh mengatasi Transformer dan sudah mempunyai 130,000 bintang.
Pada masa ini, Tensorflow mempunyai lebih daripada 170,000 bintang. Dapat dilihat bahawa Transformer ialah perpustakaan pembelajaran mesin ketiga dengan penarafan bintang lebih 100,000 selepas kedua-dua projek ini.
Sesetengah netizen teringat bahawa apabila mereka mula-mula menggunakan perpustakaan Transformers, ia dipanggil "pytorch-pretrained-BERT".
50 Projek Hebat Berdasarkan Transformers
Transformers bukan sahaja kit alat yang menggunakan model pra-latihan, ia juga merupakan projek yang dibina di sekitar Transformers dan Komuniti Hagging Face Hub .
Dalam senarai di bawah, Hugging Face meringkaskan 100 projek hebat dan baru berdasarkan Transformer.

Di bawah, kami telah memilih 50 projek teratas untuk pengenalan:
gpt4all
gpt4all ialah ekosistem chatbot sumber terbuka. Ia dilatih mengenai koleksi besar data pembantu bersih, termasuk kod, cerita dan perbualan. Ia menyediakan model bahasa berskala besar sumber terbuka, seperti LLaMA dan GPT-J, untuk latihan secara pembantu.
Kata kunci: sumber terbuka, LLaMa, GPT-J, arahan, pembantu
pengesyor
Repositori ini mengandungi contoh dan amalan terbaik untuk membina sistem pengesyor, yang disediakan dalam bentuk buku nota Jupiter. Ia merangkumi beberapa aspek yang diperlukan untuk membina sistem pengesyoran yang berkesan: penyediaan data, pemodelan, penilaian, pemilihan dan pengoptimuman model, dan operasi.
Kata kunci: sistem pengesyoran, AzureML
lama-cleaner
Alat pembaikan imej berdasarkan teknologi Stable Diffusion. Anda boleh memadamkan sebarang objek, kecacatan atau orang yang tidak diingini daripada imej dan menggantikan apa-apa pada imej.
Kata kunci: tampalan, SD, Resapan Stabil
bakat
FLAIR ialah rangka kerja pemprosesan bahasa semula jadi PyTorch yang berkuasa yang boleh mengubah beberapa tugas penting: NER, analisis sentimen, penandaan sebahagian daripada pertuturan, teks dan benam dwi, dsb.
Kata kunci: NLP, pembenaman teks, pembenaman dokumen, bioperubatan, NER, PoS, analisis sentimen

mindsdb
MindsDB ialah platform pembelajaran mesin kod rendah. Ia secara automatik menyepadukan beberapa rangka kerja ML ke dalam tindanan data sebagai "jadual AI" untuk memudahkan penyepaduan AI dalam aplikasi dan menjadikannya boleh diakses oleh pembangun semua peringkat kemahiran.
Kata kunci: pangkalan data, kod rendah, jadual AI
langchain
Langchain direka untuk membantu dalam pembangunan yang serasi LLM dan aplikasi sumber pengetahuan lain. Perpustakaan membenarkan merantai panggilan ke aplikasi, mencipta urutan dalam banyak alatan.
Kata kunci: LLM, model bahasa besar, ejen, rantai
ParlAI
ParlAI ialah platform untuk perkongsian , a Rangka kerja Python untuk melatih dan menguji model dialog, daripada sembang domain terbuka, kepada dialog berorientasikan tugas, kepada menjawab soalan visual. Ia menyediakan lebih 100 set data, banyak model pra-latihan, satu set ejen dan beberapa penyepaduan di bawah API yang sama.
Kata kunci: dialog, chatbot, VQA, dataset, ejen
pengubah ayat
Rangka kerja ini Menyediakan cara yang mudah untuk mengira perwakilan vektor padat ayat, perenggan dan imej. Model-model ini adalah berdasarkan rangkaian berasaskan Transformer seperti BERT/RoBERTa/XLM-RoBERTa dan telah mencapai SOTA dalam pelbagai tugas. Teks dibenamkan dalam ruang vektor supaya teks yang serupa hampir dan boleh didapati dengan cekap melalui persamaan kosinus.
Kata kunci: perwakilan vektor padat, pembenaman teks, pembenaman ayat
ludwig
Ludwig ialah Rangka Kerja Pembelajaran mesin deklaratif, yang memudahkan untuk menentukan saluran paip pembelajaran mesin menggunakan sistem konfigurasi dipacu data yang mudah dan fleksibel. Ludwig menyasarkan pelbagai tugas AI, menyediakan sistem konfigurasi dipacu data, latihan, skrip ramalan dan penilaian, dan API pengaturcaraan.
Kata kunci: deklaratif, dipacu data, rangka kerja ML
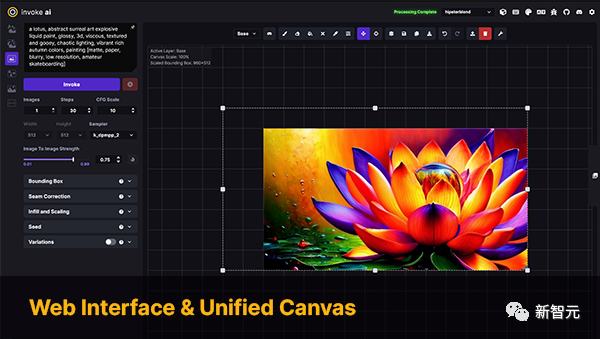
InvokeAI
InvokeAI ialah enjin untuk model Stable Diffusion, ditujukan kepada profesional, artis dan peminat. Ia memanfaatkan teknologi dipacu AI terkini melalui CLI serta WebUI.
Kata kunci: Stable Diffusion, WebUI, CLI
PaddleNLP
PaddleNLP ialah perpustakaan NLP yang mudah digunakan dan berkuasa, terutamanya untuk bahasa Cina. Ia menyokong berbilang zoo model pra-latihan dan menyokong pelbagai tugas NLP daripada penyelidikan kepada aplikasi perindustrian.
Kata kunci: pemprosesan bahasa semula jadi, Bahasa Cina, penyelidikan, industri
stanza
Rami Python NLP Kumpulan NLP Universiti Stanford perpustakaan. Ia menyokong menjalankan pelbagai alat pemprosesan bahasa semula jadi yang tepat dalam lebih daripada 60 bahasa, dan menyokong akses kepada perisian Java Stanford CoreNLP daripada Python.
Kata kunci: NLP, berbilang bahasa, CoreNLP
DeepPavlov
DeepPavlov ialah perpustakaan kecerdasan buatan perbualan sumber terbuka. Ia direka untuk pembangunan chatbots sedia pengeluaran, dan sistem dialog yang kompleks, serta penyelidikan dalam bidang NLP, khususnya sistem dialog.
Kata kunci: dialog, chatbot
alpaca-lora
Alpaca-lora termasuk penggunaan penyesuaian peringkat rendah ( kod LoRA) untuk menghasilkan semula keputusan Stanford Alpaca. Repositori ini menyediakan latihan (penalaan halus) dan skrip penjanaan.
Kata kunci: LoRA, penalaan halus parameter yang cekap
imagen-pytorch
Pelaksanaan sumber terbuka Imagen, Google's rangkaian neural teks-ke-imej sumber tertutup mengalahkan DALL-E2. imagen-pytorch ialah SOTA baharu untuk sintesis teks ke imej.
Kata kunci: Imagen, Vincent Picture
adapter-transformers
penyesuai-pengubah ialah lanjutan daripada perpustakaan Transformers yang menyepadukan penyesuai ke dalam model bahasa terkini dengan menggabungkan AdapterHub, repositori pusat modul penyesuai yang telah terlatih. Ia adalah pengganti drop-in untuk Transformers dan dikemas kini secara berkala untuk mengikuti perkembangan Transformers.
Kata kunci: Penyesuai, LoRA, penalaan halus parameter cekap, Hab
NeMo
NVIDIA NeMo adalah untuk melibatkan diri dalam pertuturan automatik Kit alat AI perbualan yang dibina oleh penyelidik dalam pengecaman (ASR), sintesis teks ke pertuturan (TTS), model bahasa besar dan pemprosesan bahasa semula jadi. Matlamat utama NeMo adalah untuk membantu penyelidik dari industri dan akademia menggunakan semula kerja terdahulu (kod dan model pra-latihan) dan menjadikannya lebih mudah untuk mencipta projek baharu.
Kata kunci: Dialog, ASR, TTS, LLM, NLP
Runhouse
Runhouse membenarkan untuk menggabungkan kod dan Menghantar data ke mana-mana komputer atau data yang mendasari dan terus berinteraksi dengan mereka secara normal daripada kod dan persekitaran sedia ada. Pembangun Runhouse menyebut:
Anda boleh menganggapnya sebagai pakej sambungan untuk penterjemah Python, yang boleh memintas mesin jauh atau mengendalikan data jauh.
Kata kunci: MLOp, infrastruktur, storan data, pemodelan
MONAI
MONAI ialah sebahagian daripada ekosistem PyTorch dan merupakan rangka kerja sumber terbuka berdasarkan PyTorch untuk pembelajaran mendalam dalam bidang pengimejan perubatan. Objektifnya ialah:
- Untuk membangunkan komuniti penyelidik akademik, industri dan klinikal yang bekerjasama secara umum; 🎜>
- Menyediakan kaedah yang dioptimumkan dan diseragamkan untuk penubuhan dan penilaian model pembelajaran mendalam.Kata kunci: pengimejan perubatan, latihan, penilaian
simpletransformers
Simple Transformers membolehkan anda melatih dan menilai model Transformer dengan cepat . Hanya 3 baris kod diperlukan untuk memulakan, melatih dan menilai model. Ia menyokong pelbagai jenis tugas NLP.
Kata kunci: rangka kerja, kesederhanaan, NLPJARVIS
JARVIS ialah GPT-4, dsb. Sistem LLM bergabung dengan model lain daripada komuniti pembelajaran mesin sumber terbuka, memanfaatkan sehingga 60 model hiliran untuk melaksanakan tugas yang dikenal pasti oleh LLM.
Kata kunci: LLM, ejen, HF Hub
transformers.js
 transformers.js ialah perpustakaan JavaScript yang bertujuan untuk menjalankan model daripada transformer terus dalam penyemak imbas.
transformers.js ialah perpustakaan JavaScript yang bertujuan untuk menjalankan model daripada transformer terus dalam penyemak imbas.
bumblebee
Bumblebee menyediakan pra-latihan di atas model rangkaian Neural Axon , Axon ialah perpustakaan rangkaian saraf untuk bahasa Elixir. Ia termasuk penyepaduan dengan model, membolehkan sesiapa sahaja memuat turun dan melaksanakan tugasan pembelajaran mesin dengan hanya beberapa baris kod.
Kata kunci: Elixir, Axonargilla
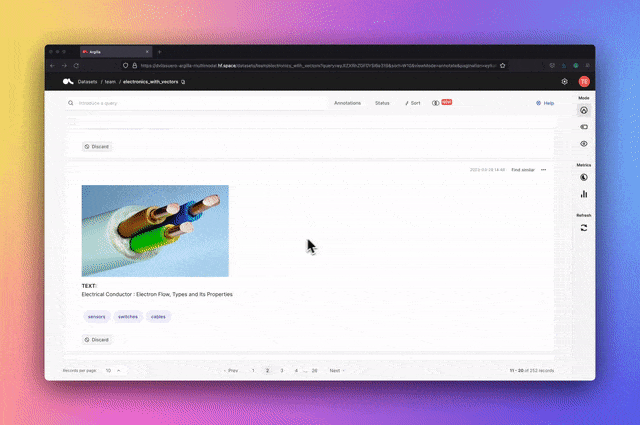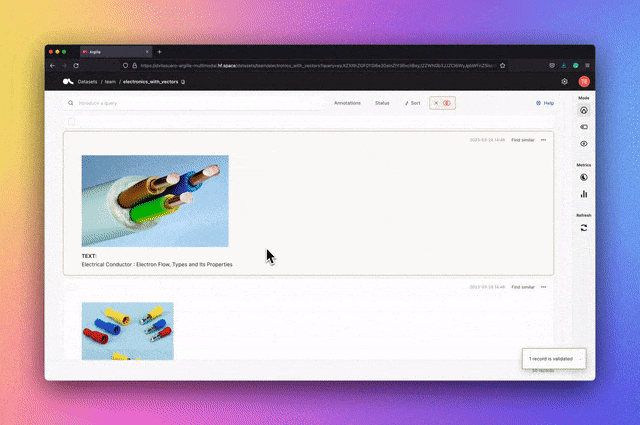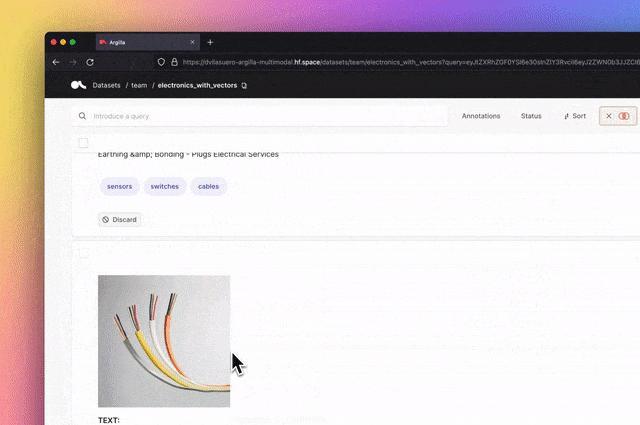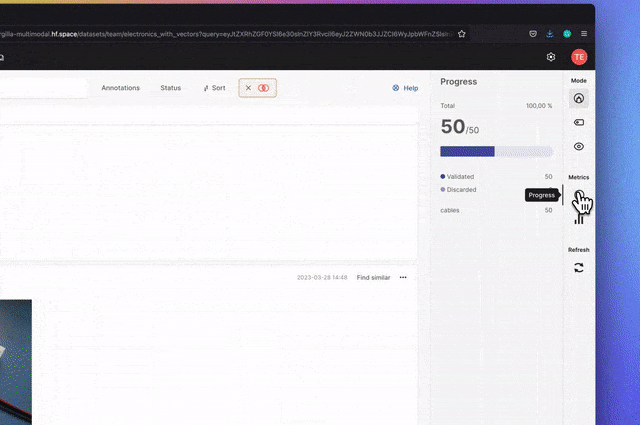
Argilla ialah alat yang menyediakan penandaan NLP lanjutan, pemantauan dan ruang kerja Terbuka platform sumber. Ia serasi dengan banyak ekosistem sumber terbuka seperti Muka Memeluk, Stanza, FLAIR, dsb.
Kata kunci: NLP, pelabelan, pemantauan, ruang kerja
timbunan jerami
 Haystack ialah rangka kerja NLP sumber terbuka yang boleh berinteraksi dengan data menggunakan model Transformer dan LLM. Ia menyediakan alat sedia pengeluaran untuk membina pembuatan keputusan yang rumit dengan cepat, menjawab soalan, carian semantik, aplikasi penjanaan teks dan banyak lagi.
Haystack ialah rangka kerja NLP sumber terbuka yang boleh berinteraksi dengan data menggunakan model Transformer dan LLM. Ia menyediakan alat sedia pengeluaran untuk membina pembuatan keputusan yang rumit dengan cepat, menjawab soalan, carian semantik, aplikasi penjanaan teks dan banyak lagi.
spaCy
 SpaCy ialah perpustakaan untuk pemprosesan bahasa semula jadi lanjutan dalam Python dan Cython. Ia dibina berdasarkan penyelidikan terkini dan direka dari bawah untuk digunakan dalam produk sebenar. Ia menyediakan sokongan untuk model Transformers melalui pakej spacy-transformers pihak ketiganya.
SpaCy ialah perpustakaan untuk pemprosesan bahasa semula jadi lanjutan dalam Python dan Cython. Ia dibina berdasarkan penyelidikan terkini dan direka dari bawah untuk digunakan dalam produk sebenar. Ia menyediakan sokongan untuk model Transformers melalui pakej spacy-transformers pihak ketiganya.
speechbrain
SpeechBrain ialah kit alat AI perbualan bersepadu sumber terbuka berdasarkan PyTorch. Matlamat kami adalah untuk mencipta kit alat tunggal, fleksibel dan mesra pengguna yang boleh digunakan untuk membangunkan teknologi pertuturan tercanggih dengan mudah, termasuk pengecaman pertuturan, pengenalan pembesar suara, peningkatan pertuturan, pemisahan pertuturan, pengecaman pertuturan, berbilang mikrofon pemprosesan isyarat dan sistem lain.
Kata kunci: dialog, pertuturan
skorch
Skorch ialah pembungkus untuk PyTorch dengan keserasian scikit-learn Perpustakaan rangkaian saraf . Ia menyokong model dalam Transformers, serta tokenizer daripada tokenizer.
Kata kunci: Scikit-Learning, PyTorch
bertviz
BertViz ialah alat interaktif untuk aplikasi seperti Visualize attention in Model bahasa pengubah seperti BERT, GPT2 atau T5. Ia boleh dijalankan dalam buku nota Jupiter atau Colab melalui API Python ringkas yang menyokong kebanyakan model Huggingface.
Kata kunci: Visualisasi, Transformers

mesh-transformer-jax
mesh-transformer-jax ialah perpustakaan haiku yang melaksanakan keselarian model Transformers menggunakan pengendali xmap/pjit dalam JAX.
Pustaka ini direka bentuk untuk skala kepada kira-kira 40B parameter pada TPUv3. Ia adalah perpustakaan yang digunakan untuk melatih model GPT-J.
Kata kunci: Haiku, model parallelism, LLM, TPUdeepchem
OpenNRE
Satu kaedah untuk pengekstrakan hubungan saraf Pakej Sumber Terbuka (NRE). Ia menyasarkan pelbagai pengguna, daripada orang baru, kepada pembangun, penyelidik atau pelajar.
Kata kunci: pengekstrakan hubungan saraf, rangka kerja
pycorrector
Alat pembetulan teks bahasa Cina. Kaedah ini menggunakan ralat pengesanan model bahasa, ciri pinyin dan ciri bentuk untuk membetulkan ralat teks bahasa Cina. Boleh digunakan untuk kaedah input Pinyin Cina dan strok.
Kata kunci: Bahasa Cina, alat pembetulan ralat, model bahasa, Pinyin
nlpaug
Perpustakaan ular sawa ini boleh membantu anda meningkatkan nlp untuk projek pembelajaran mesin. Ia ialah perpustakaan ringan dengan fungsi untuk menjana data sintetik untuk meningkatkan prestasi model, menyokong audio dan teks serta serasi dengan beberapa ekosistem (scikit-learn, pytorch, tensorflow).
Kata kunci: penambahan data, penjanaan data sintetik, audio, pemprosesan bahasa semula jadi
tekstur mimpi
tekstur mimpi ialah perpustakaan yang direka untuk membawa sokongan resapan yang stabil kepada Blender. Ia menyokong berbilang kes penggunaan seperti penjanaan imej, unjuran tekstur, lukisan masuk/keluar, ControlNet dan naik taraf.
Kata kunci: Stable-Diffusion, Blender

seldon-core
Teras Seldon menukar model ML anda (Tensorflow, Pytorch, H2o, dll.) atau pembalut bahasa (Python, Java, dll.) menjadi perkhidmatan mikro REST/GRPC pengeluaran. Seldon boleh mengendalikan penskalaan kepada beribu-ribu model pembelajaran mesin pengeluaran dan menyediakan ciri pembelajaran mesin lanjutan termasuk metrik lanjutan, log permintaan, penterjemah, pengesan terpencil, ujian A/B, kenari dan banyak lagi.
Kata kunci: perkhidmatan mikro, pemodelan, pembungkusan bahasa
open_model_zoo
Pustaka ini termasuk model pembelajaran mendalam yang dioptimumkan dan satu set tunjuk cara untuk mempercepatkan pembangunan aplikasi inferens pembelajaran mendalam berprestasi tinggi. Gunakan model pra-latihan percuma ini dan bukannya melatih model anda sendiri untuk mempercepatkan proses penggunaan pembangunan dan pengeluaran.
Kata kunci: model pengoptimuman, demonstrasi
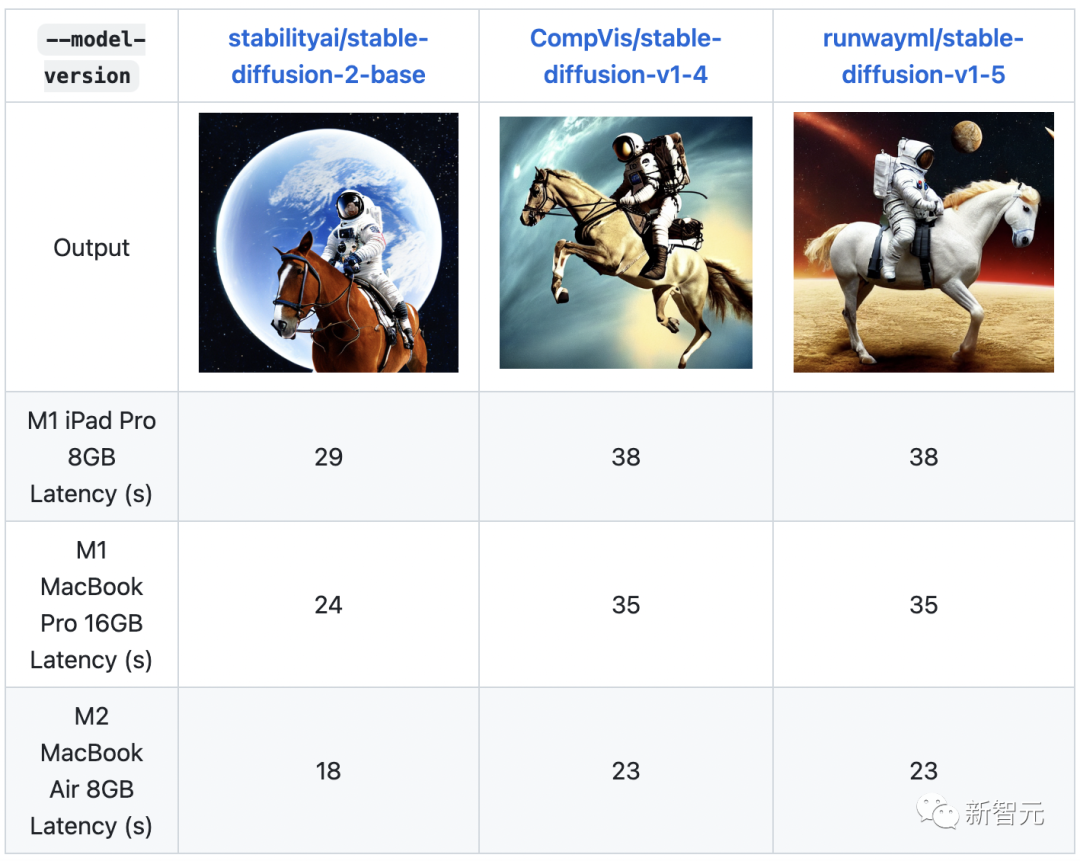
ml-stable-diffusion
ML-Stable-Diffusion is Apple's A repository yang membawa sokongan Stable Diffusion kepada Core ML pada peranti silikon Apple. Ia menyokong pusat pemeriksaan resapan yang stabil yang dihoskan pada Hab Wajah Memeluk.
Kata kunci: Resapan Stabil, cip Apple, Core ML
stable-dreamfusion
Stable-Dreamfusion ialah pelaksanaan pytorch teks kepada model 3D Dreamfusion, dikuasakan oleh teks Stable Diffusion kepada model 2D.
Kata kunci: Teks kepada 3D, Resapan Stabil

txtai
Txtai ialah platform sumber terbuka yang menyokong carian semantik dan aliran kerja didorong model bahasa. Txtai membina pangkalan data terbenam, yang merupakan gabungan indeks vektor dan pangkalan data hubungan, menyokong carian jiran terdekat SQL. Aliran kerja semantik menghubungkan model bahasa ke dalam aplikasi bersatu.
Kata kunci: carian semantik, LLM

djl
Deep Java Library (DJL) ialah rangka kerja Java agnostik berenjin terbuka, tahap tinggi untuk pembelajaran mendalam yang mudah digunakan oleh pembangun. DJL menyediakan pengalaman dan fungsi pembangunan Java asli seperti perpustakaan Java biasa yang lain. DJL menyediakan pengikatan Java untuk HuggingFace Tokenizer dan kit alat penukaran mudah untuk menggunakan model HuggingFace di Java.
Kata kunci: Java, seni bina

lm-evaluation-harness
Projek ini menyediakan rangka kerja bersatu untuk menguji model bahasa generatif pada sejumlah besar tugas penilaian yang berbeza. Ia menyokong lebih daripada 200 tugasan dan menyokong ekosistem yang berbeza: HF Transformers, GPT-NeoX, DeepSpeed dan OpenAI API.
Kata kunci: LLM, penilaian, beberapa sampel
gpt-neox
Repositori ini merekodkan penggunaan perpustakaan EleutherAI A untuk melatih model bahasa berskala besar pada GPU. Rangka kerja ini berdasarkan model bahasa Megatron NVIDIA dan dipertingkatkan dengan teknologi DeepSpeed dan beberapa pengoptimuman baharu. Fokusnya adalah pada model latihan dengan berbilion parameter.
Kata kunci: latihan, LLM, Megatron, DeepSpeed
muzic
Muzic ialah penyelidikan tentang projek muzik kecerdasan buatan, yang mampu memahami dan menjana muzik melalui pembelajaran mendalam dan kecerdasan buatan. Muzic dicipta oleh penyelidik di Microsoft Research Asia.
Kata kunci: pemahaman muzik, penjanaan muzik

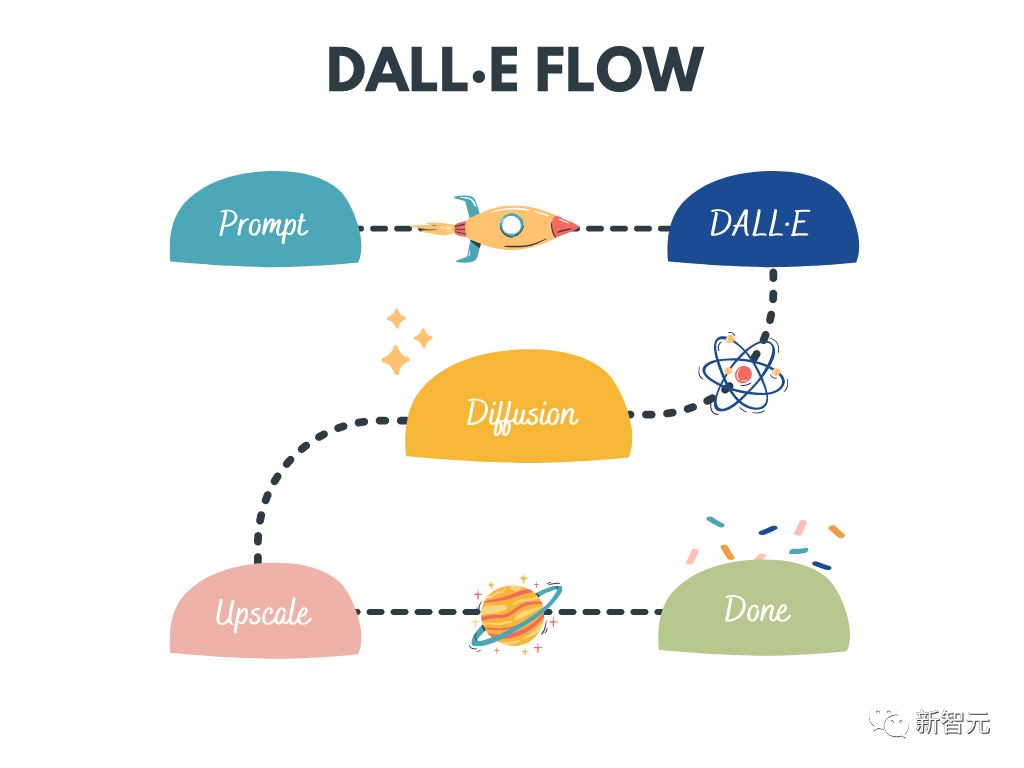
dalle-flow
DALL · E Flow ialah aliran kerja interaktif untuk menjana imej definisi tinggi daripada gesaan teks. Ia menggunakan DALL·E-Mega, GLID-3 XL dan Stable Diffusion untuk menjana imej calon, dan kemudian memanggil CLIP-as-service untuk menggesa mengisih imej calon. Calon pilihan diberikan kepada GLID-3 XL untuk penyebaran, yang sering memperkaya tekstur dan latar belakang. Akhirnya, calon dilanjutkan kepada 1024x1024 melalui SwinIR.
Kata kunci: penjanaan imej definisi tinggi, Stable Diffusion, DALL-E Mega, GLID-3 XL, CLIP, SwinIR
lightseq
LightSeq ialah pustaka latihan dan inferens berprestasi tinggi yang dilaksanakan dalam CUDA untuk pemprosesan dan penjanaan jujukan. Ia mampu mengira model NLP dan CV moden dengan cekap seperti BERT, GPT, Transformer, dll. Oleh itu, ia berguna untuk terjemahan mesin, penjanaan teks, klasifikasi imej dan tugas berkaitan urutan lain.
Kata kunci: latihan, inferens, pemprosesan jujukan, penjanaan jujukan

LaTeX- OCR
Matlamat projek ini adalah untuk mencipta sistem berasaskan pembelajaran yang mengambil imej formula matematik dan mengembalikan kod LaTeX yang sepadan.
Kata kunci: OCR, LaTeX, formula matematik
open_clip
OpenCLIP ialah pelaksanaan sumber terbuka CLIP OpenAI.
Matlamat repositori ini adalah untuk membolehkan latihan model dengan penyeliaan teks imej kontras dan mengkaji sifatnya seperti keteguhan kepada anjakan pengedaran. Titik permulaan projek ialah pelaksanaan CLIP yang sepadan dengan ketepatan model CLIP asal apabila dilatih pada set data yang sama.
Khususnya, model ResNet-50 yang dilatih pada 15 juta subset imej OpenAI YFCC sebagai asas kod mencapai ketepatan tertinggi sebanyak 32.7% pada ImageNet.
Kata kunci: KLIP, sumber terbuka, perbandingan, teks imej

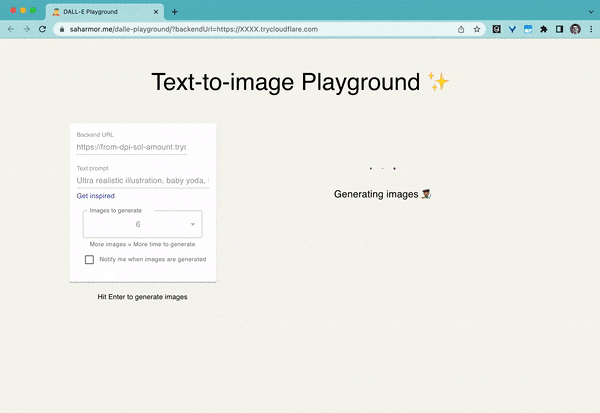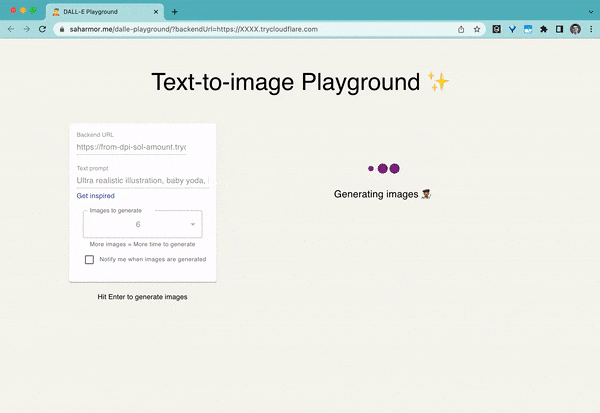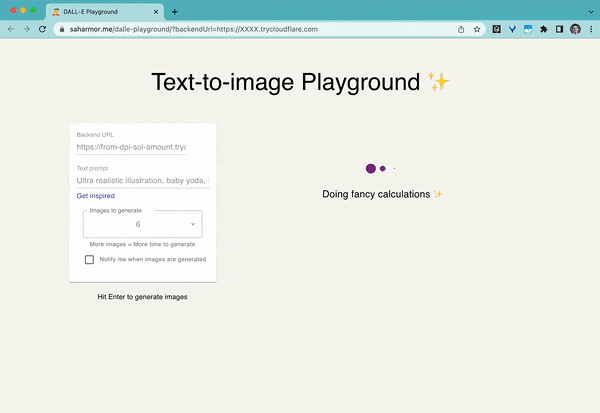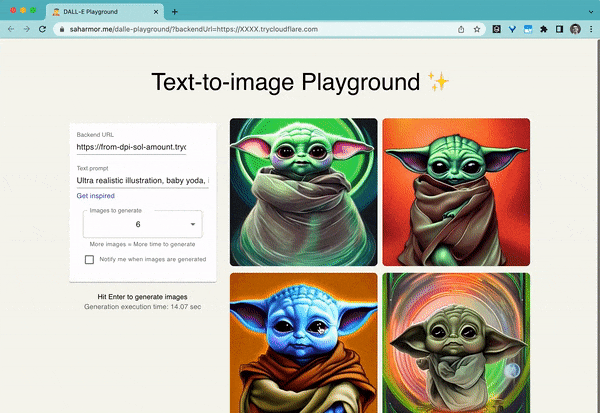
taman permainan dalle
Taman permainan untuk menjana imej daripada sebarang gesaan teks menggunakan Stable Diffusion dan Dall-E mini.
Kata kunci: WebUI, Stable Diffusion, Dall-E mini
FedML
FedML ialah perpustakaan pembelajaran dan analitik bersekutu yang membolehkan pembelajaran mesin selamat dan kolaboratif pada data yang diedarkan di mana-mana dan pada sebarang skala.
Kata kunci: pembelajaran bersekutu, analitik, pembelajaran mesin kolaboratif, terdesentralisasi
Atas ialah kandungan terperinci Tanda bintang melebihi 100,000! Selepas Auto-GPT, Transformer mencapai pencapaian baharu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI