
Rumah >Peranti teknologi >AI >Pasukan CMU Zhu Junyan membangunkan sistem pemeringkatan automatik untuk menilai kebaikan dan keburukan pelbagai model penjanaan AI.
Pasukan CMU Zhu Junyan membangunkan sistem pemeringkatan automatik untuk menilai kebaikan dan keburukan pelbagai model penjanaan AI.

- 王林ke hadapan
- 2023-05-09 21:09:071363semak imbas
Artikel ini diterbitkan semula daripada Lei Feng.com Jika anda perlu mencetak semula, sila pergi ke tapak web rasmi Lei Feng.com untuk memohon kebenaran.
Baru-baru ini, AI generatif sangat popular, dan terdapat begitu banyak model penjanaan imej pra-latihan baharu yang memeningkan untuk dilihat. Sama ada potret, landskap, kartun, unsur gaya artis tertentu dan banyak lagi, setiap model mempunyai sesuatu yang bagus untuk dijana.
Dengan begitu banyak model, bagaimanakah anda dengan cepat mencari model terbaik yang dapat memenuhi keinginan kreatif anda?
Baru-baru ini, Zhu Junyan, penolong profesor di Carnegie Mellon University, dan yang lain mencadangkan buat kali pertama algoritma carian model berasaskan kandungan, yang membolehkan anda mencari dengan satu klik Model penjanaan imej kedalaman padanan terbaik.

Alamat kertas: https://arxiv.org/pdf/2210.03116.pdf
Pada Modelverse, platform perkongsian dan carian model dalam talian yang dibangunkan oleh pasukan berdasarkan set algoritma carian model ini, anda boleh memasukkan teks, imej, lakaran dan model tertentu dan mencari model berkaitan yang paling sepadan atau serupa.
Alamat platform modelverse: https://modelverse.cs.cmu.edu/

Kapsyen: Input teks (seperti "haiwan Afrika"), imej (seperti landskap), lakaran (seperti lakaran kucing berdiri) atau model tertentu dan keluarkan bahagian atas Model yang berkaitan (baris kedua dan ketiga)
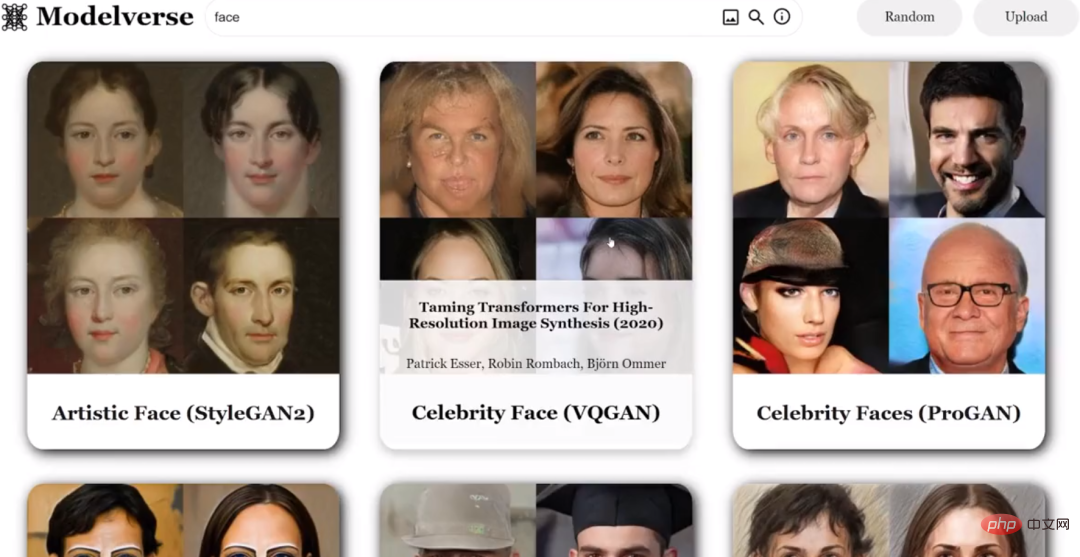
Sebagai contoh, jika anda memasukkan teks "muka", anda akan mendapat hasil berikut:
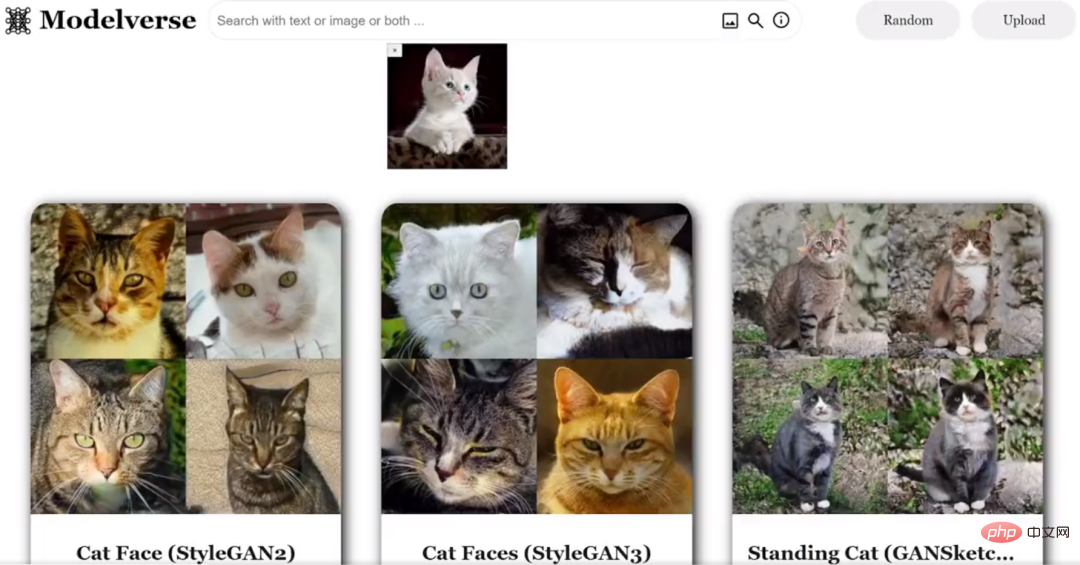
Masukkan imej kucing:
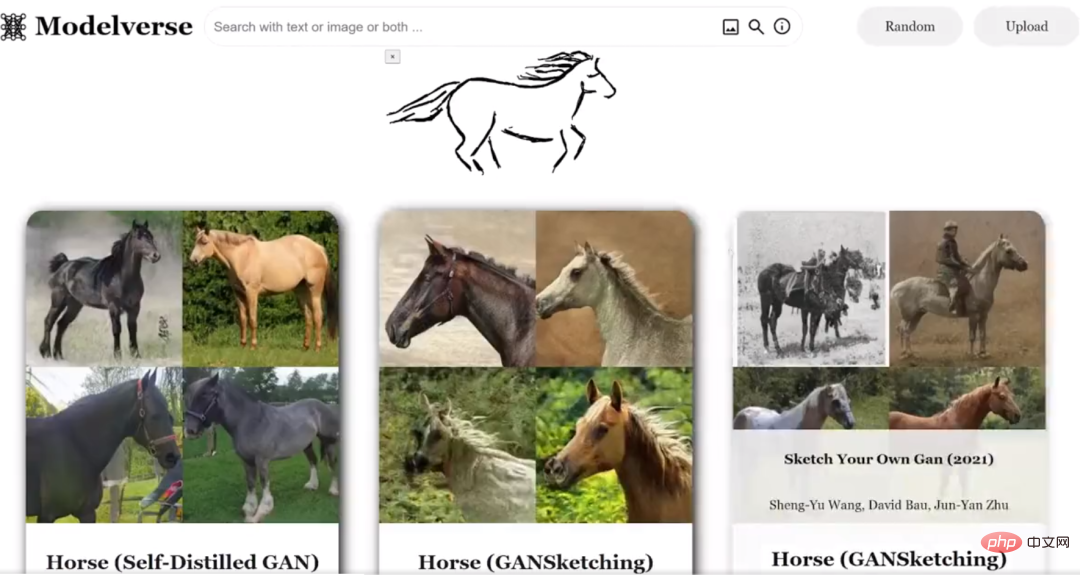
Masukkan lakaran kuda:
1 Carian model berasaskan kandungan
Seperti carian multimedia tradisional, carian model boleh membantu pengguna mencari yang satu yang paling sesuai dengan model keperluan khusus mereka. Walau bagaimanapun, tugas carian model berasaskan kandungan mempunyai kesukaran tersendiri:
Menentukan sama ada model boleh menjana imej tertentu ialah masalah yang sukar dari segi pengiraan, dan banyak model generatif dalam tidak menyediakan kaedah yang berkesan untuk menganggarkan ketumpatan, yang dengan sendirinya tidak menyokong penilaian persamaan rentas modal. Kaedah berasaskan pensampelan Monte Carlo akan menjadikan proses carian model sangat perlahan.
Untuk tujuan ini, pasukan Zhu Junyan mencadangkan sistem carian model baharu.
Setiap model generatif menghasilkan pengedaran imej, jadi pengarang mendekati masalah carian sebagai pengoptimuman yang memaksimumkan kebarangkalian menjana padanan kepada pertanyaan yang diberikan model. Seperti yang ditunjukkan dalam rajah di bawah, sistem terdiri daripada peringkat pra-caching (a, b) dan peringkat inferens (c).
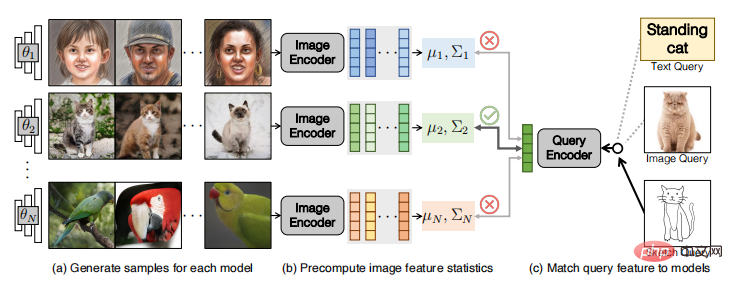
Kapsyen: Gambaran keseluruhan kaedah carian model
Diberikan model set , (a) mula-mula menjana 50K sampel untuk setiap model; (b) kemudian mengekod imej ke dalam ciri imej dan mengira statistik ciri urutan pertama dan kedua untuk setiap model. Statistik dicache dalam sistem untuk meningkatkan kecekapan; (c) semasa fasa inferens, pertanyaan daripada modaliti yang berbeza disokong, termasuk imej, lakaran, penerangan teks, model generatif lain atau gabungan jenis pertanyaan ini. Pengarang memperkenalkan anggaran di sini di mana pertanyaan dikodkan sebagai vektor ciri dan model dengan ukuran persamaan terbaik diperoleh dengan menilai persamaan antara ciri pertanyaan dan setiap statistik model.
2 Kesan carian model
Pengarang menilai algoritma dan menjalankan analisis eksperimen ablasi pada 133 model penjanaan dalam (termasuk GAN, model resapan dan model autoregresif) . Berbanding dengan garis dasar Monte Carlo, kaedah ini boleh mencapai carian yang lebih cekap, dengan peningkatan kelajuan 5 kali ganda dalam 0.08 milisaat, sambil mengekalkan ketepatan tinggi .
Dengan membandingkan hasil perolehan model, kami juga boleh mendapatkan gambaran kasar tentang model yang boleh menjana imej berkualiti lebih tinggi untuk input pertanyaan yang berbeza. Sebagai contoh, rajah di bawah menunjukkan perbandingan keputusan perolehan model.

Ilustrasi: Contoh hasil carian model
Barisan atas ialah Pertanyaan imej, masukkan lukisan hidupan pegun, dapatkan semula model gaya artistik yang berkaitan dan dapatkan model StyleGAN2 peringkat pertama dan model GAN bantuan Vision peringkat terakhir. Baris tengah ialah pertanyaan lakaran, input lakaran kuda dan gereja, dan dapatkan model seperti ADM dan ProGAN. Intinya ialah pertanyaan teks Masukkan "orang yang memakai cermin mata" dan "burung bercakap" untuk mendapatkan masing-masing model GANSketch dan model GAN Suling Sendiri.
Pengarang juga mendapati bahawa terdapat perbezaan dalam prestasi model dalam ruang ciri rangkaian yang berbeza. Seperti yang ditunjukkan dalam rajah di bawah, apabila memasukkan pertanyaan imej, keputusan menunjukkan bahawa ketiga-tiga rangkaian CLIP, DINO dan Inception semuanya mempunyai prestasi yang sama apabila memasukkan pertanyaan lakaran, CLIP menunjukkan prestasi yang lebih baik, manakala DINO dan Inception tidak sesuai untuk pertanyaan tertentu, mereka menunjukkan prestasi yang lebih baik pada model gaya artistik.
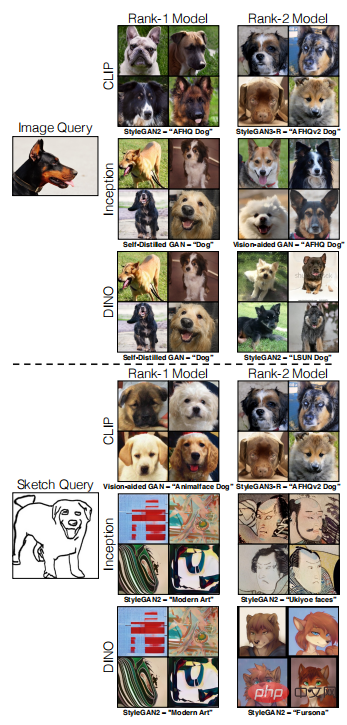
Kapsyen: Perbandingan pengambilan semula model berasaskan imej dan lakaran dalam ruang ciri rangkaian yang berbeza
Selain itu, algoritma carian model yang dicadangkan dalam kerja ini juga boleh menyokong pelbagai aplikasi, termasuk pertanyaan pengguna berbilang modal, pertanyaan model serupa, pembinaan semula dan penyuntingan imej sebenar, dsb.
Sebagai contoh, pertanyaan berbilang modal boleh membantu memperhalusi carian model Apabila hanya terdapat imej "Nicolas Cage", hanya model muka boleh diambil tetapi apabila "Nicolas Cage " juga digunakan Dengan "anjing" sebagai input, anda boleh mendapatkan semula model StyleGAN-NADA yang boleh menjana imej "anjing Nicolas Cage". (Seperti yang ditunjukkan di bawah)

Ilustrasi: Pertanyaan pengguna pelbagai mod
Apabila input ialah model muka, lebih banyak model generatif muka boleh diambil dan kategori kekal serupa. (Seperti yang ditunjukkan di bawah)

Nota ilustrasi: Pertanyaan model serupa
diberikan Untuk menentukan imej pertanyaan wajah sebenar, menggunakan model yang lebih tinggi boleh mendapatkan pembinaan semula imej yang lebih tepat. Rajah di bawah ialah contoh pemetaan songsang imej bagi imej CelebA-HQ dan LSUN Church menggunakan model kedudukan yang berbeza.

Kapsyen: Tayangkan imej sebenar kepada model StyleGAN2 yang diambil semula.
Dalam tugas menyunting imej sebenar, prestasi model yang berbeza juga berbeza-beza. Dalam rajah di bawah, algoritma perolehan model berasaskan imej kedudukan teratas digunakan untuk memetakan imej sebenar secara songsang, dan kemudian diedit menggunakan GANspace untuk menukar muka berkerut dalam imej Ukiyoe kepada wajah tersenyum.
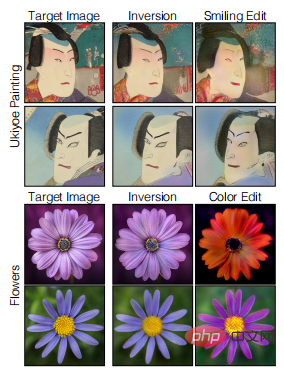
Kapsyen: Mengedit imej sebenar
Kajian ini telah membuktikan kebolehlaksanaan carian model; banyak ruang untuk penyelidikan ke dalam carian model untuk teks, audio atau penjanaan kandungan lain.
Tetapi pada masa ini, kaedah yang dicadangkan dalam karya ini masih mempunyai batasan tertentu. Contohnya, apabila menanyakan lakaran tertentu, kadangkala model bentuk abstrak akan dipadankan dan kadangkala apabila melakukan pertanyaan berbilang modal, hanya satu model boleh diambil dan sistem mungkin mengalami kesukaran memproses imej seperti anjing + "pertanyaan Multimodal besar seperti ". (Seperti yang ditunjukkan dalam gambar di bawah)
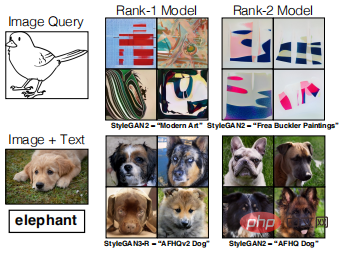
Nota gambar: Kes kegagalan
Selain itu, Pada platform carian modelnya, senarai model yang diambil tidak diisih secara automatik mengikut kesannya. Contohnya, model berbeza dinilai dan diberi kedudukan dari segi resolusi, kesetiaan, tahap pemadanan imej yang dijana, dsb. , supaya ia boleh menjadi lebih tepat Ia memudahkan pencarian semula pengguna dan juga boleh membantu pengguna lebih memahami kebaikan dan keburukan model yang dihasilkan pada masa ini Kami berharap untuk kerja susulan dalam bidang ini.
Atas ialah kandungan terperinci Pasukan CMU Zhu Junyan membangunkan sistem pemeringkatan automatik untuk menilai kebaikan dan keburukan pelbagai model penjanaan AI.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI