
Rumah >Peranti teknologi >AI >Google mengeluarkan PaLM-E, model tujuan am terbesar dalam sejarah, yang mempunyai 562 bilion parameter, dipanggil otak paling berkuasa dalam Terminator, dan boleh berinteraksi dengan robot melalui imej
Google mengeluarkan PaLM-E, model tujuan am terbesar dalam sejarah, yang mempunyai 562 bilion parameter, dipanggil otak paling berkuasa dalam Terminator, dan boleh berinteraksi dengan robot melalui imej

- 王林ke hadapan
- 2023-05-09 20:28:091415semak imbas
"Mutasi" model bahasa besar yang pesat telah menjadikan hala tuju masyarakat manusia semakin fiksyen sains. Selepas menyalakan pokok teknologi ini, realiti "Terminator" nampaknya semakin hampir dengan kita.
Beberapa hari lalu, Microsoft baru sahaja mengumumkan rangka kerja percubaan yang boleh menggunakan ChatGPT untuk mengawal robot dan dron.
Sudah tentu Google tidak ketinggalan pada hari Isnin, pasukan dari Google dan Universiti Teknikal Berlin melancarkan model bahasa visual terbesar dalam sejarah - PaLM-E.

Alamat kertas: https://arxiv.org/abs/2303.03378
Sebagai model bahasa visual (VLM), PaLM-E bukan sahaja dapat memahami imej, tetapi juga memahami dan menjana bahasa, malah ia boleh menggabungkan kedua-duanya untuk memproses arahan robot Kompleks .
Selain itu, melalui gabungan model bahasa PaLM-540B dan model Pengubah visual ViT-22B, bilangan akhir parameter PaLM-E adalah setinggi 562 bilion.

Model "generalis" yang merangkumi bidang robotik dan bahasa penglihatan
PaLM-E , Nama penuh ialah Pathways Language Model with Embodied, iaitu model bahasa visual yang terkandung.
Kuasanya terletak pada keupayaannya untuk menggunakan data visual untuk meningkatkan keupayaan pemprosesan bahasanya.

Apa yang berlaku apabila kita melatih model bahasa visual terbesar dan menggabungkannya dengan robot? Hasilnya ialah PaLM-E, 562 bilion-parameter, universal, ahli generalis bahasa visual yang terkandung - merangkumi robotik, penglihatan dan bahasa
Menurut kertas itu, PaLM-E ialah LLM penyahkod sahaja yang mampu menjana pelengkapan teks secara autoregresif diberi awalan atau gesaan.
Data latihan ialah ayat berbilang modal yang mengandungi visual, anggaran keadaan berterusan dan pengekodan input teks.
Selepas latihan dengan gesaan imej tunggal, PaLM-E bukan sahaja boleh membimbing robot untuk menyelesaikan pelbagai tugas yang rumit, tetapi juga menjana bahasa untuk menerangkan imej.
Boleh dikatakan bahawa PaLM-E menunjukkan fleksibiliti dan kebolehsuaian yang belum pernah berlaku sebelum ini dan mewakili lonjakan besar ke hadapan, terutamanya dalam bidang interaksi manusia-komputer.
Lebih penting lagi, penyelidik menunjukkan bahawa latihan mengenai gabungan tugas hibrid yang berbeza bagi berbilang robot dan bahasa visual umum boleh membawa kepada pemindahan daripada bahasa visual kepada pembuatan keputusan yang terkandung Beberapa kaedah membenarkan robot menggunakan data dengan berkesan semasa merancang tugas.
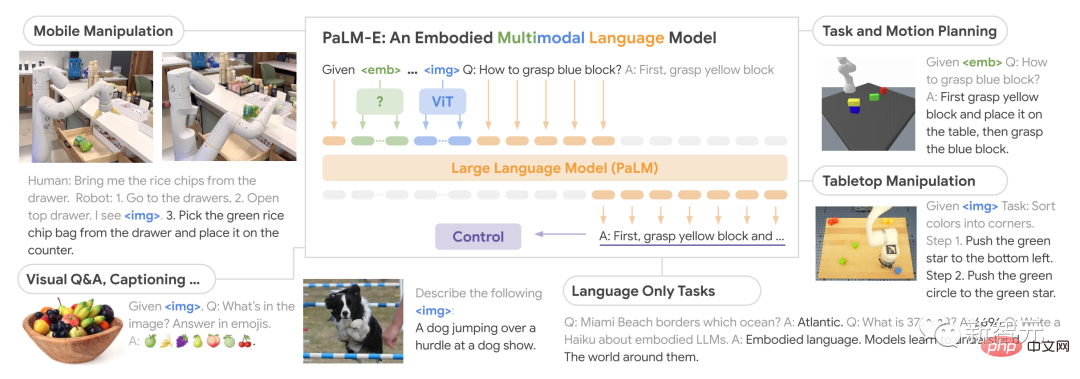
Selain itu, PaLM-E amat cemerlang kerana ia mempunyai keupayaan migrasi positif yang kukuh.
PaLM-E yang dilatih dalam domain yang berbeza, termasuk tugasan bahasa penglihatan umum berskala Internet, mencapai prestasi yang dipertingkatkan dengan ketara berbanding model robot yang melaksanakan tugasan tunggal.
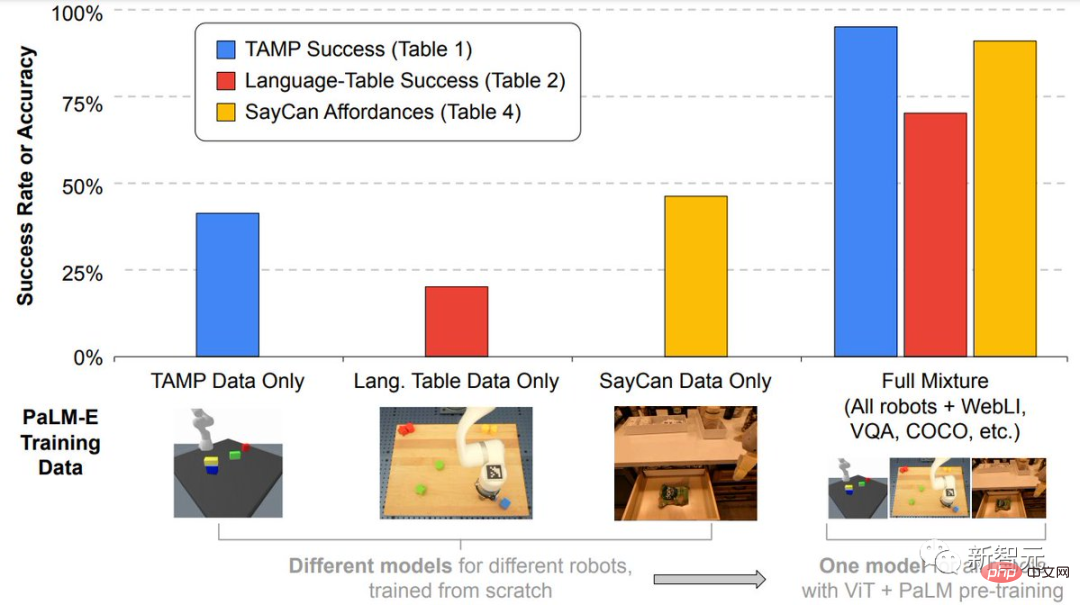
Pada skala model, penyelidik melihat kelebihan yang ketara.
Semakin besar model bahasa, semakin kuat keupayaan bahasa dikekalkan semasa latihan bahasa visual dan tugasan robot.
Dari perspektif skala model, PaLM-E dengan 562 bilion parameter mengekalkan hampir semua keupayaan bahasanya.
Walaupun hanya dilatih pada satu imej, PaLM-E menunjukkan keupayaan cemerlang dalam tugas seperti penaakulan rantaian pemikiran pelbagai mod dan penaakulan pelbagai imej.
Pada penanda aras OK-VQA, PaLM-E mencapai SOTA baharu.
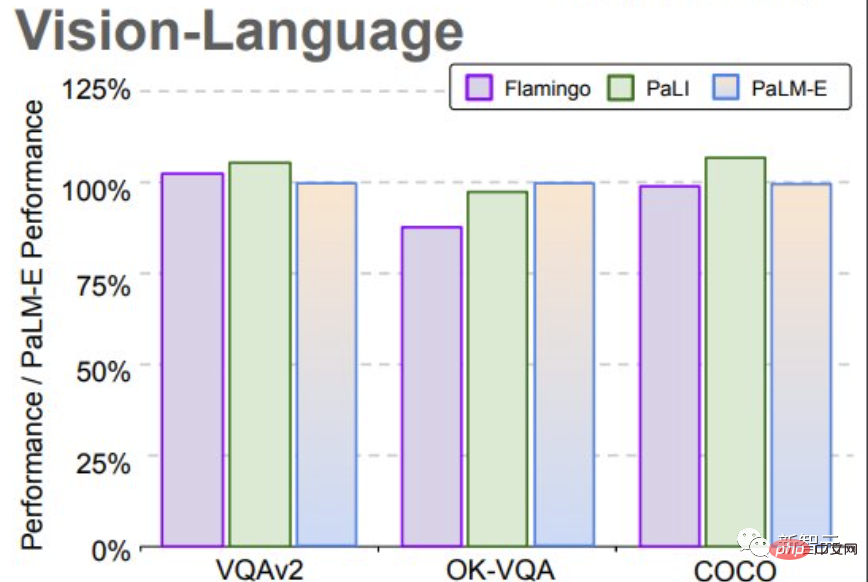
Hasil Penilaian
Dalam ujian, penyelidik menunjukkan cara Menggunakan PaLM -E untuk melaksanakan perancangan dan tugasan jangka panjang pada dua entiti berbeza.
Perlu diingat bahawa semua keputusan ini diperoleh menggunakan model yang sama yang dilatih pada data yang sama.
Dulu, robot biasanya memerlukan bantuan manusia untuk menyelesaikan tugasan jangka panjang. Tetapi kini, PaLM-E boleh melakukannya melalui pembelajaran bebas.

Contohnya, arahan seperti "Keluarkan kerepek kentang dari laci" termasuk beberapa langkah perancangan , dan maklum balas visual daripada kamera robot.
PaLM-E, yang telah dilatih hujung ke hujung, boleh merancang robot terus daripada piksel. Oleh kerana model itu disepadukan ke dalam gelung kawalan, robot itu tahan terhadap gangguan di sepanjang jalan semasa mengambil kerepek kentang.
Manusia: Beri saya sedikit kerepek kentang.
Robot: 1. Pergi ke laci 2. Buka laci atas 3. Angkat kerepek kentang hijau dari laci atas 4. Letakkan di atas kaunter .

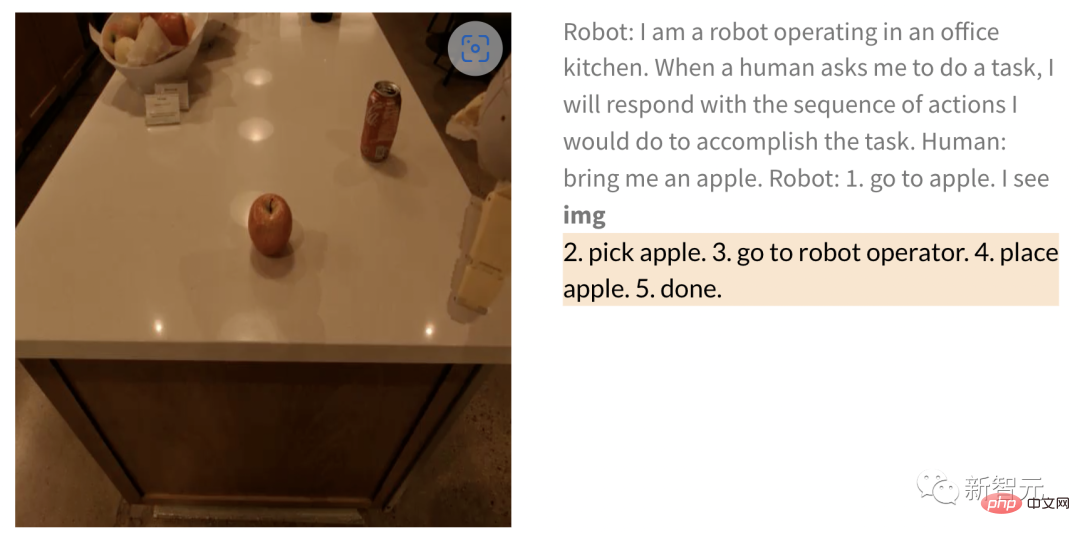
Begitu juga apabila meminta robot mendapatkan epal, selepas memberi gambar, langkah-langkah untuk robot untuk melaksanakan tugas adalah seperti berikut ——
Manusia: Dapatkan saya sebiji epal.
Robot: 1. Berjalan ke epal 2. Angkat epal 3. Bawa ke operator 4. Letakkan epal 5. Selesai.
Selain melaksanakan tugas jangka panjang, PaLM-E boleh membenarkan robot melaksanakan tugas perancangan , seperti menyusun blok bangunan.
Para penyelidik berjaya menjalankan perancangan berbilang peringkat berdasarkan input visual dan lisan, dan digabungkan dengan maklum balas visual jangka panjang, membolehkan model berjaya merancang tugas jangka panjang " Sort blok ke sudut yang berbeza mengikut warna."
Seperti yang ditunjukkan di bawah, dari segi susunan dan gabungan, robot berubah menjadi generalis dan menyusun blok binaan mengikut warna.
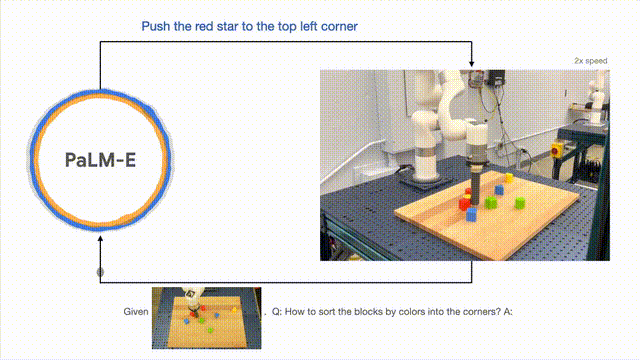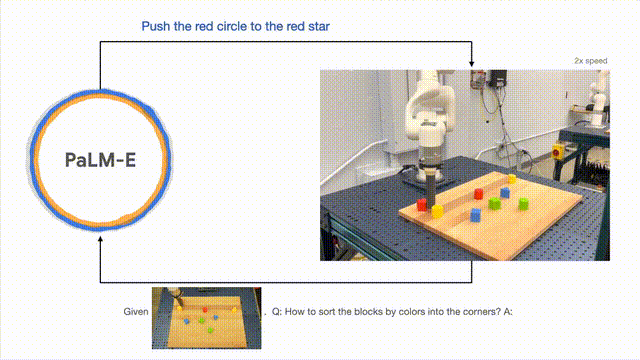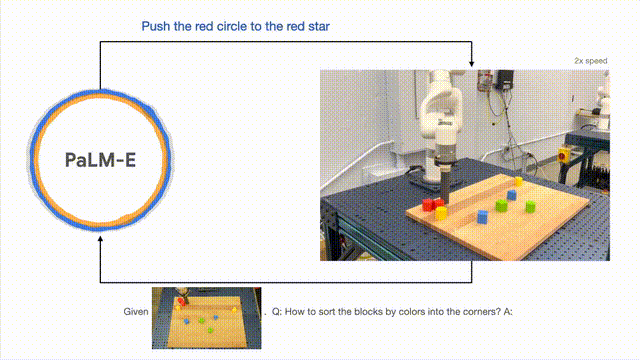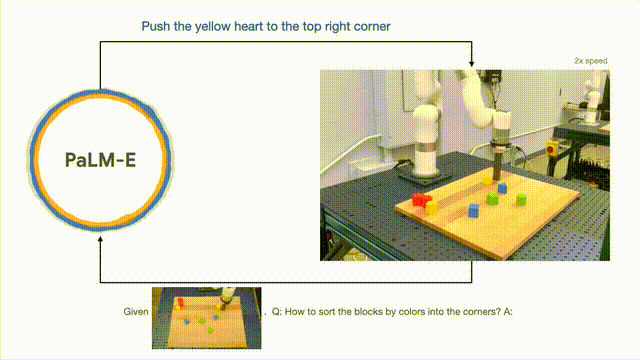
Dari segi generalisasi model, robot yang dikawal oleh PaLM-E boleh menggerakkan blok bangunan merah ke sebelah cawan kopi.
Perlu dinyatakan bahawa set data hanya mengandungi tiga demonstrasi dengan cawan kopi, tetapi tiada satu pun daripadanya termasuk blok bangunan merah.

Begitu juga, walaupun model itu tidak pernah melihat penyu sebelum ini, ia masih boleh menolak blok hijau kepada penyu dengan lancar . Di sebelah

Dari segi inferens pukulan sifar, PaLM-E boleh memberitahu jenaka yang diberikan imej, dan menunjukkan Kebolehan termasuk persepsi, dialog dan perancangan berasaskan visi.
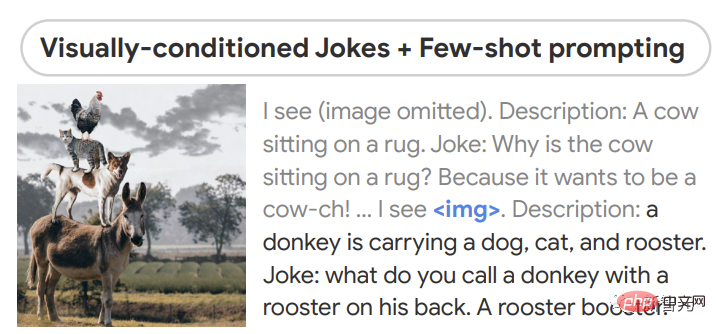
PaLM-E juga memahami hubungan antara berbilang gambar Contohnya, gambar 1 (kiri) dalam gambar Kedudukan mana dua (kanan).

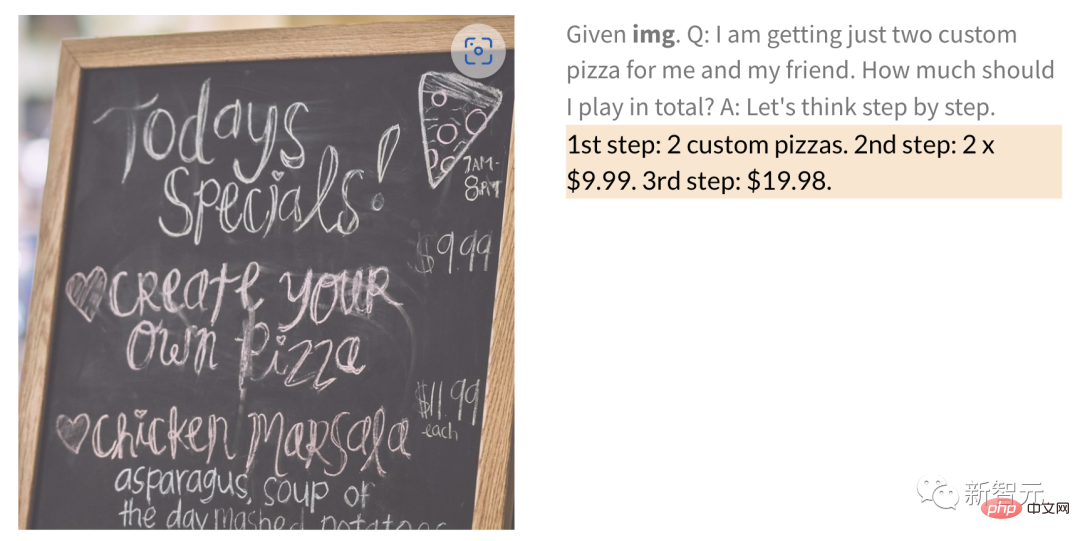
Selain itu, PaLM-E juga boleh melakukan operasi matematik yang diberi imej dengan digit tulisan tangan.
Contohnya, untuk gambar menu restoran tulisan tangan di bawah, berapa harga 2 pizza PaLM-E secara terus?
serta QA am dan anotasi serta tugasan lain.
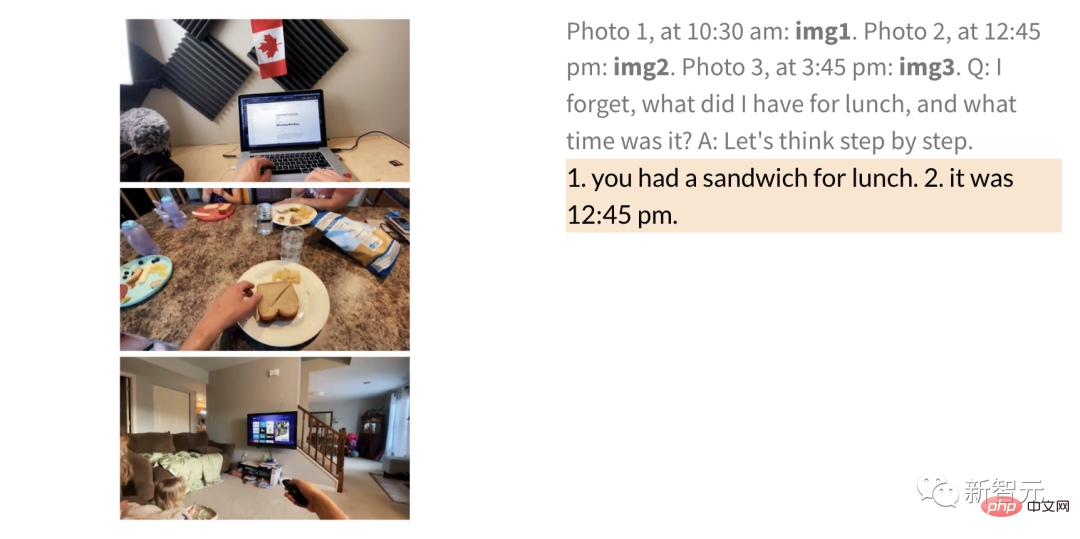
Akhir sekali, hasil penyelidikan juga menunjukkan bahawa model bahasa beku adalah pintu masuk kepada model terwujud universal yang mengekalkan bahasa mereka sepenuhnya kebolehan. Laluan yang berdaya maju untuk model modal.
Tetapi pada masa yang sama, penyelidik juga menemui jalan alternatif untuk menyahbekukan model, iaitu, meningkatkan saiz model bahasa dapat mengurangkan pelupaan bencana dengan ketara.
Atas ialah kandungan terperinci Google mengeluarkan PaLM-E, model tujuan am terbesar dalam sejarah, yang mempunyai 562 bilion parameter, dipanggil otak paling berkuasa dalam Terminator, dan boleh berinteraksi dengan robot melalui imej. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI