
Rumah >Peranti teknologi >AI >Klasifikasi imej dengan pembelajaran beberapa tangkapan menggunakan PyTorch
Klasifikasi imej dengan pembelajaran beberapa tangkapan menggunakan PyTorch

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-09 10:51:051576semak imbas
Dalam beberapa tahun kebelakangan ini, model berasaskan pembelajaran mendalam telah menunjukkan prestasi yang baik dalam tugas seperti pengesanan objek dan pengecaman imej. Mengenai set data klasifikasi imej yang mencabar seperti ImageNet, yang mengandungi 1,000 klasifikasi objek berbeza, sesetengah model kini melebihi tahap manusia. Tetapi model ini bergantung pada proses latihan yang diawasi, mereka dipengaruhi dengan ketara oleh ketersediaan data latihan berlabel, dan kelas yang model dapat mengesan adalah terhad kepada kelas yang dilatih.
Memandangkan imej berlabel tidak mencukupi untuk semua kelas semasa latihan, model ini mungkin kurang berguna dalam tetapan dunia sebenar. Dan kami mahu model itu dapat mengenali kelas yang tidak pernah dilihat semasa latihan, kerana hampir mustahil untuk melatih imej semua objek berpotensi. Masalah di mana kita akan belajar daripada beberapa sampel dipanggil pembelajaran Few-Shot.
Apakah pembelajaran beberapa pukulan?

Pembelajaran beberapa pukulan ialah subbidang pembelajaran mesin. Ia melibatkan pengkelasan data baharu dengan hanya beberapa sampel latihan dan data penyeliaan. Model yang kami cipta berfungsi dengan baik dengan hanya sebilangan kecil sampel latihan.
Pertimbangkan senario berikut: Dalam bidang perubatan, untuk beberapa penyakit luar biasa, mungkin tidak ada imej x-ray yang mencukupi untuk latihan. Untuk senario sedemikian, membina pengelas pembelajaran beberapa pukulan adalah penyelesaian yang sempurna.
Variasi dalam sampel kecil
Secara amnya, penyelidik mengenal pasti empat jenis:
- N-Shot Learning (NSL)
- Few-Shot Learning ( FSL)
- Pembelajaran Satu Pukulan (OSL)
- Pembelajaran Sifar Pukulan (ZSL)
Apabila kita bercakap tentang FSL, kita biasanya merujuk kepada N- klasifikasi cara-K-Shot. N mewakili bilangan kelas, dan K mewakili bilangan sampel yang akan dilatih dalam setiap kelas. Jadi Pembelajaran N-Shot dianggap sebagai konsep yang lebih luas daripada semua konsep lain. Boleh dikatakan Few-Shot, One-Shot dan Zero-Shot adalah sub-bidang NSL. Manakala pembelajaran zero-shot bertujuan untuk mengklasifikasikan kelas ghaib tanpa sebarang contoh latihan.
Dalam One-Shot Learning, hanya terdapat satu sampel bagi setiap kelas. Few-Shot mempunyai 2 hingga 5 sampel setiap kelas, yang bermaksud Few-Shot ialah versi One-Shot Learning yang lebih fleksibel.
Kaedah pembelajaran sampel kecil
Secara amnya, dua kaedah harus dipertimbangkan semasa menyelesaikan masalah Few Shot Learning:
Pendekatan Tahap Data (DLA)
Ini Strateginya adalah sangat mudah, jika tidak ada data yang mencukupi untuk mencipta model yang kukuh dan mengelakkan kekurangan dan overfitting, maka lebih banyak data harus ditambah. Oleh sebab itu, banyak masalah FSL boleh diselesaikan dengan memanfaatkan lebih banyak data daripada set data asas yang lebih besar. Ciri yang ketara bagi set data asas ialah ia tidak mempunyai kelas yang membentuk set sokongan kami untuk cabaran Few-Shot. Sebagai contoh, jika kita ingin mengklasifikasikan spesies burung tertentu, set data asas mungkin mengandungi gambar banyak burung lain.
Pendekatan Tahap Parameter (PLA)
Dari sudut perspektif tahap parameter, sampel Few-Shot Learning agak mudah untuk dilebihkan kerana ia biasanya mempunyai ruang dimensi tinggi yang besar. Mengehadkan ruang parameter, menggunakan regularisasi dan menggunakan fungsi kehilangan yang sesuai akan membantu menyelesaikan masalah ini. Sebilangan kecil sampel latihan akan digunakan oleh model untuk membuat generalisasi.
Prestasi boleh dipertingkatkan dengan membimbing model ke ruang parameter yang luas. Kaedah pengoptimuman biasa mungkin tidak menghasilkan keputusan yang tepat kerana kekurangan data latihan.
Atas sebab di atas, melatih model kami untuk mencari laluan terbaik melalui ruang parameter menghasilkan hasil ramalan yang terbaik. Pendekatan ini dipanggil meta-pembelajaran.
Algoritma pengelasan imej pembelajaran sampel kecil
Terdapat 4 kaedah pembelajaran sampel kecil yang biasa:
Pembelajaran meta bebas model Model-Pembelajaran Meta Agnostik
Prinsip meta-pembelajaran berasaskan kecerunan (GBML) ialah asas MAML. Dalam GBML, pelajar meta memperoleh pengalaman terdahulu dengan melatih model asas dan mempelajari ciri yang dikongsi merentas semua perwakilan tugas. Setiap kali terdapat tugasan baharu untuk dipelajari, pelajar meta diperhalusi menggunakan pengalaman sedia ada dan jumlah minimum data latihan baharu yang disediakan oleh tugasan baharu itu.
Secara amnya, jika kita memulakan parameter secara rawak dan mengemas kininya beberapa kali, algoritma tidak akan menumpu kepada prestasi yang baik. MAML cuba menyelesaikan masalah ini. MAML menyediakan permulaan yang boleh dipercayai bagi pelajar meta-parameter dengan hanya beberapa langkah kecerunan dan tanpa pemasangan berlebihan, supaya tugasan baharu boleh dipelajari secara optimum dan cepat.
Langkah-langkahnya adalah seperti berikut:
- Pelajar meta mencipta salinan C sendiri pada permulaan setiap episod dan
- C dilatih pada episod ini (dengan bantuan model asas),
- C membuat ramalan pada set pertanyaan,
- kerugian yang dikira daripada ramalan ini digunakan untuk mengemas kini C,
- seperti Ini berterusan sehingga semua episod latihan selesai.

Kelebihan terbesar teknik ini ialah ia dianggap bebas daripada pilihan algoritma meta-pembelajaran. Oleh itu, kaedah MAML digunakan secara meluas dalam banyak algoritma pembelajaran mesin yang memerlukan penyesuaian pantas, terutamanya rangkaian neural dalam.
Rangkaian Padanan
Kaedah pembelajaran metrik pertama yang dicipta untuk menyelesaikan masalah FSL ialah Rangkaian Padanan (MN).
Set data asas yang besar diperlukan apabila menggunakan kaedah rangkaian padanan untuk menyelesaikan masalah Pembelajaran Sedikit Tangkapan. .
Selepas membahagikan set data ini kepada beberapa episod, untuk setiap episod, rangkaian yang sepadan melakukan perkara berikut:
- Setiap imej daripada set sokongan dan set pertanyaan disalurkan kepada CNN yang mengeluarkan pembenaman ciri untuk mereka
- imej pertanyaan menggunakan model yang dilatih pada set sokongan untuk mendapatkan jarak kosinus ciri terbenam, diklasifikasikan oleh softmax
- kehilangan silang entropi hasil pengelasan oleh Kemas kini propagasi belakang CNN menampilkan model benam
Rangkaian padanan boleh belajar membina benam imej dengan cara ini. MN dapat mengklasifikasikan foto menggunakan kaedah ini tanpa pengetahuan khusus tentang kategori tersebut. Ia hanya membandingkan beberapa contoh kelas.
Memandangkan kategori berbeza dari episod ke episod, rangkaian yang sepadan mengira atribut imej (ciri) yang penting untuk perbezaan kategori. Apabila menggunakan pengelasan standard, algoritma memilih ciri yang unik untuk setiap kategori.
Rangkaian Prototaip
Serupa dengan rangkaian padanan ialah rangkaian prototaip (PN). Ia meningkatkan prestasi algoritma melalui beberapa perubahan halus. PN mencapai hasil yang lebih baik daripada MN, tetapi proses latihan mereka pada asasnya adalah sama, hanya membandingkan beberapa pembenaman imej pertanyaan daripada set sokongan, tetapi rangkaian prototaip menyediakan strategi yang berbeza.
Kita perlu mencipta prototaip kelas dalam PN: pembenaman kelas yang dibuat dengan purata pembenaman imej dalam kelas. Hanya prototaip kelas ini kemudiannya digunakan untuk membandingkan benam imej pertanyaan. Apabila digunakan untuk masalah pembelajaran sampel tunggal, ia adalah setanding dengan rangkaian yang sepadan.
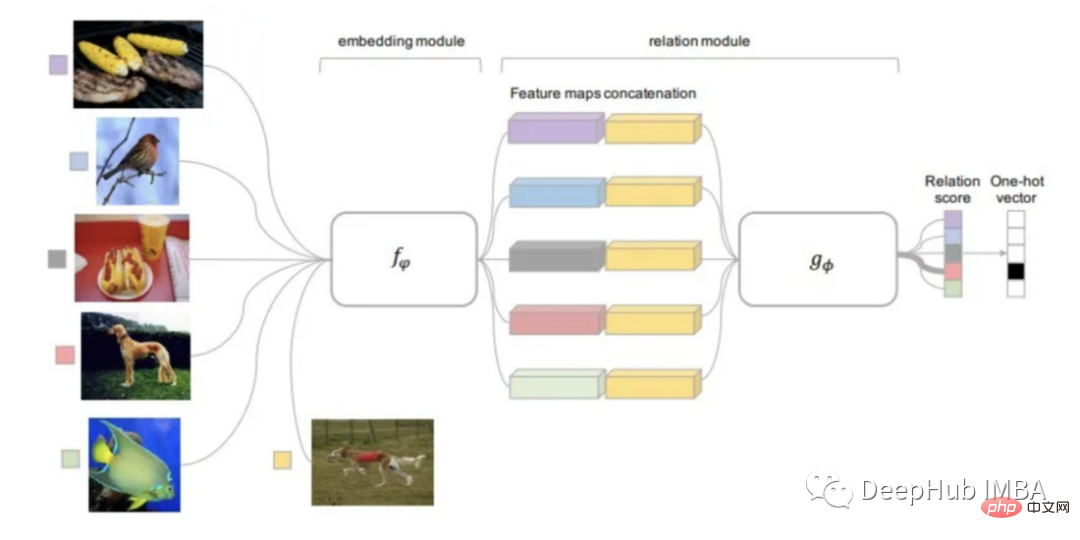
Rangkaian Perhubungan Rangkaian Perhubungan
Rangkaian perhubungan boleh dikatakan mewarisi hasil kajian terhadap semua kaedah yang dinyatakan di atas. RN adalah berdasarkan idea PN tetapi mengandungi peningkatan algoritma yang ketara.
Fungsi jarak yang digunakan oleh kaedah ini boleh dipelajari, bukannya mentakrifkannya terlebih dahulu seperti kajian terdahulu. Modul perhubungan terletak di atas modul benam, iaitu bahagian yang mengira benam dan prototaip kelas daripada imej input.
Input modul hubungan boleh dilatih (fungsi jarak) ialah pembenaman imej pertanyaan dengan prototaip setiap kelas dan output ialah skor hubungan setiap padanan kelas. Skor hubungan dilalui melalui Softmax untuk mendapatkan ramalan.
Menggunakan Open-AI Clip untuk pembelajaran sifar pukulan
KLIP (Pra-Latihan Imej-Bahasa Kontrastif) ialah alat untuk pelbagai (imej, teks ) Pada rangkaian saraf terlatih. Ia boleh meramalkan serpihan teks yang paling berkaitan untuk imej tertentu tanpa dioptimumkan secara langsung untuk tugasan (serupa dengan fungsi tangkapan sifar GPT-2 dan 3).
CLIP boleh mencapai prestasi ResNet50 asal pada "sampel sifar" ImageNet dan tidak memerlukan penggunaan mana-mana contoh berlabel Ia mengatasi beberapa cabaran utama dalam penglihatan komputer Di bawah kami menggunakan Pytorch untuk melaksanakan yang mudah Model pengelasan.
Perkenalkan pakej
! pip install ftfy regex tqdm
! pip install git+https://github.com/openai/CLIP.gitimport numpy as np
import torch
from pkg_resources import packaging
print("Torch version:", torch.__version__)Muat model
import clipclip.available_models() # it will list the names of available CLIP modelsmodel, preprocess = clip.load("ViT-B/32")
model.cuda().eval()
input_resolution = model.visual.input_resolution
context_length = model.context_length
vocab_size = model.vocab_size
print("Model parameters:", f"{np.sum([int(np.prod(p.shape)) for p in model.parameters()]):,}")
print("Input resolution:", input_resolution)
print("Context length:", context_length)
print("Vocab size:", vocab_size)prapemprosesan imej
Kami akan memasukkan 8 contoh imej dan penerangan teksnya kepada model , dan bandingkan persamaan antara ciri yang sepadan.
Tokenizer tidak sensitif huruf besar dan kecil dan kami bebas memberikan sebarang penerangan teks yang sesuai.
import os
import skimage
import IPython.display
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from collections import OrderedDict
import torch
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# images in skimage to use and their textual descriptions
descriptions = {
"page": "a page of text about segmentation",
"chelsea": "a facial photo of a tabby cat",
"astronaut": "a portrait of an astronaut with the American flag",
"rocket": "a rocket standing on a launchpad",
"motorcycle_right": "a red motorcycle standing in a garage",
"camera": "a person looking at a camera on a tripod",
"horse": "a black-and-white silhouette of a horse",
"coffee": "a cup of coffee on a saucer"
}original_images = []
images = []
texts = []
plt.figure(figsize=(16, 5))
for filename in [filename for filename in os.listdir(skimage.data_dir) if filename.endswith(".png") or filename.endswith(".jpg")]:
name = os.path.splitext(filename)[0]
if name not in descriptions:
continue
image = Image.open(os.path.join(skimage.data_dir, filename)).convert("RGB")
plt.subplot(2, 4, len(images) + 1)
plt.imshow(image)
plt.title(f"{filename}n{descriptions[name]}")
plt.xticks([])
plt.yticks([])
original_images.append(image)
images.append(preprocess(image))
texts.append(descriptions[name])
plt.tight_layout()Visualisasi keputusan adalah seperti berikut:

Kami menormalkan imej, melabel setiap input teks dan menjalankan penyebaran model ke hadapan untuk mendapatkan Ciri-ciri imej dan teks.
image_input = torch.tensor(np.stack(images)).cuda() text_tokens = clip.tokenize(["This is " + desc for desc in texts]).cuda() with torch.no_grad():
Kami menormalkan ciri dan mengira hasil darab titik setiap pasangan untuk melaksanakan pengiraan persamaan kosinus
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T
count = len(descriptions)
plt.figure(figsize=(20, 14))
plt.imshow(similarity, vmin=0.1, vmax=0.3)
# plt.colorbar()
plt.yticks(range(count), texts, fontsize=18)
plt.xticks([])
for i, image in enumerate(original_images):
plt.imshow(image, extent=(i - 0.5, i + 0.5, -1.6, -0.6), origin="lower")
for x in range(similarity.shape[1]):
for y in range(similarity.shape[0]):
plt.text(x, y, f"{similarity[y, x]:.2f}", ha="center", va="center", size=12)
for side in ["left", "top", "right", "bottom"]:
plt.gca().spines[side].set_visible(False)
plt.xlim([-0.5, count - 0.5])
plt.ylim([count + 0.5, -2])
plt.title("Cosine similarity between text and image features", size=20)
Sampel sifar Pengelasan imej
from torchvision.datasets import CIFAR100
cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True)
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
plt.figure(figsize=(16, 16))
for i, image in enumerate(original_images):
plt.subplot(4, 4, 2 * i + 1)
plt.imshow(image)
plt.axis("off")
plt.subplot(4, 4, 2 * i + 2)
y = np.arange(top_probs.shape[-1])
plt.grid()
plt.barh(y, top_probs[i])
plt.gca().invert_yaxis()
plt.gca().set_axisbelow(True)
plt.yticks(y, [cifar100.classes[index] for index in top_labels[i].numpy()])
plt.xlabel("probability")
plt.subplots_adjust(wspace=0.5)
plt.show()
dapat dilihat bahawa kesan klasifikasi masih sangat baik.
Atas ialah kandungan terperinci Klasifikasi imej dengan pembelajaran beberapa tangkapan menggunakan PyTorch. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI