
Rumah >Peranti teknologi >AI >Kertas markah tinggi daripada COLM, persidangan model besar pertama: Algoritma carian keutamaan PairS menjadikan penilaian teks model besar lebih cekap
Kertas markah tinggi daripada COLM, persidangan model besar pertama: Algoritma carian keutamaan PairS menjadikan penilaian teks model besar lebih cekap

- WBOYasal
- 2024-08-05 14:31:52906semak imbas

Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Penulis artikel semuanya dari Makmal Teknologi Bahasa Universiti Cambridge One ialah Liu Yinhong, pelajar kedoktoran tahun ketiga dan penyelianya ialah profesor Nigel Collier dan Ehsan Shareghi. Minat penyelidikannya ialah penilaian model dan teks yang besar, penjanaan data, dsb. Zhou Han, pelajar kedoktoran tahun kedua di Tongyi, dibimbing oleh profesor Anna Korhonen dan Ivan Vulić Minat penyelidikannya adalah dalam model besar yang cekap.
Model besar mempamerkan keupayaan mengikut arahan dan generalisasi tugas yang sangat baik ini datang daripada penggunaan data mengikut arahan dan pembelajaran pengukuhan maklum balas manusia (RLHF) dalam latihan LLM. Dalam paradigma latihan RLHF, model ganjaran diselaraskan dengan keutamaan manusia berdasarkan data perbandingan kedudukan. Ini meningkatkan penjajaran LLM dengan nilai kemanusiaan, dengan itu menjana respons yang lebih baik membantu manusia dan mematuhi nilai kemanusiaan.
Baru-baru ini, persidangan model besar pertama COLM baru sahaja mengumumkan keputusan penerimaan Salah satu karya yang mendapat markah tinggi menganalisis masalah bias skor yang sukar dielakkan dan diperbetulkan apabila LLM digunakan sebagai penilai teks, dan dicadangkan untuk menukar. masalah penilaian menjadi masalah kedudukan keutamaan, dan dengan itu mereka bentuk algoritma PairS, algoritma yang boleh mencari dan mengisih daripada pilihan berpasangan. Dengan memanfaatkan andaian ketidakpastian dan transitiviti LLM, PairS boleh memberikan kedudukan keutamaan yang cekap dan tepat dan menunjukkan konsistensi yang lebih tinggi dengan pertimbangan manusia pada pelbagai set ujian.

Pautan kertas: https://arxiv.org/abs/2403.16950
Tajuk kertas: Menyelaraskan dengan Penghakiman Manusia: The Role of Pairwise Preferences🜎 Language Preferences🜎🜎 Model Large https://github.com/cambridgeltl/PairS
- Apakah masalah dengan penilaian model besar?
Sebilangan besar karya baru-baru ini telah menunjukkan prestasi cemerlang LLM dalam menilai kualiti teks, membentuk paradigma baharu untuk penilaian tugas generatif tanpa rujukan, mengelakkan kos anotasi manusia yang mahal. Walau bagaimanapun, penilai LLM sangat sensitif terhadap reka bentuk segera dan mungkin dipengaruhi oleh pelbagai bias, termasuk berat sebelah kedudukan, berat sebelah verbositi dan berat sebelah konteks. Kecondongan ini menghalang penilai LLM daripada bersikap adil dan boleh dipercayai, yang membawa kepada ketidakkonsistenan dan ketidakselarasan dengan pertimbangan manusia.
Untuk mengurangkan ramalan berat sebelah LLM, kerja terdahulu membangunkan teknik penentukuran untuk mengurangkan berat sebelah dalam ramalan LLM. Kami mula-mula menjalankan analisis sistematik tentang keberkesanan teknik penentukuran dalam menjajarkan penganggar LLM mengikut arah. Seperti yang ditunjukkan dalam Rajah 2 di atas, kaedah penentukuran sedia ada masih tidak menjajarkan penganggar LLM dengan baik walaupun apabila data penyeliaan disediakan.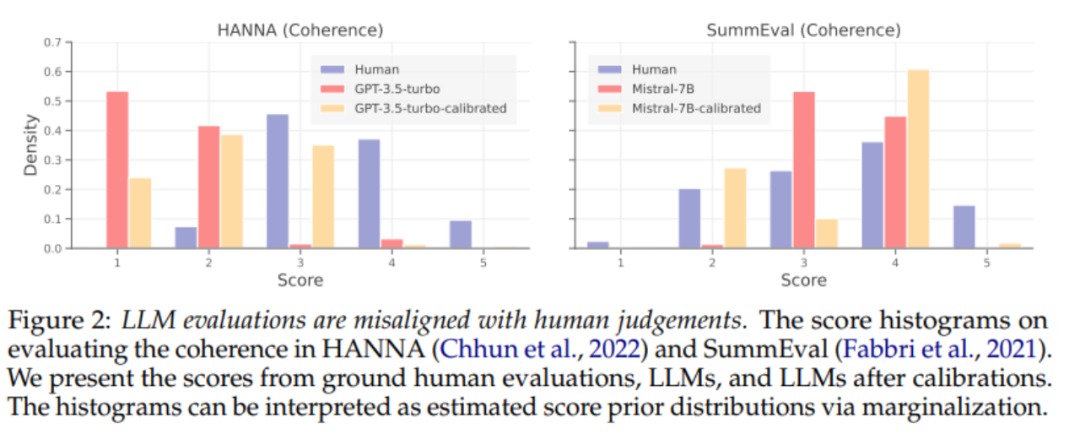 Seperti yang ditunjukkan dalam Formula 1, kami percaya bahawa sebab utama ketidakselarasan penilaian bukanlah keutamaan yang berat sebelah terhadap pengagihan skor penilaian LLM, tetapi salah penjajaran piawai penilaian, iaitu, penilai LLM Kemungkinan (kemungkinan) . Kami percaya bahawa penilai LLM akan mempunyai kriteria penilaian yang lebih konsisten dengan manusia apabila melakukan penilaian berpasangan, jadi kami meneroka paradigma penilaian LLM baharu untuk mempromosikan pertimbangan yang lebih sejajar.
Seperti yang ditunjukkan dalam Formula 1, kami percaya bahawa sebab utama ketidakselarasan penilaian bukanlah keutamaan yang berat sebelah terhadap pengagihan skor penilaian LLM, tetapi salah penjajaran piawai penilaian, iaitu, penilai LLM Kemungkinan (kemungkinan) . Kami percaya bahawa penilai LLM akan mempunyai kriteria penilaian yang lebih konsisten dengan manusia apabila melakukan penilaian berpasangan, jadi kami meneroka paradigma penilaian LLM baharu untuk mempromosikan pertimbangan yang lebih sejajar.
Inspirasi dibawakan oleh RLHF
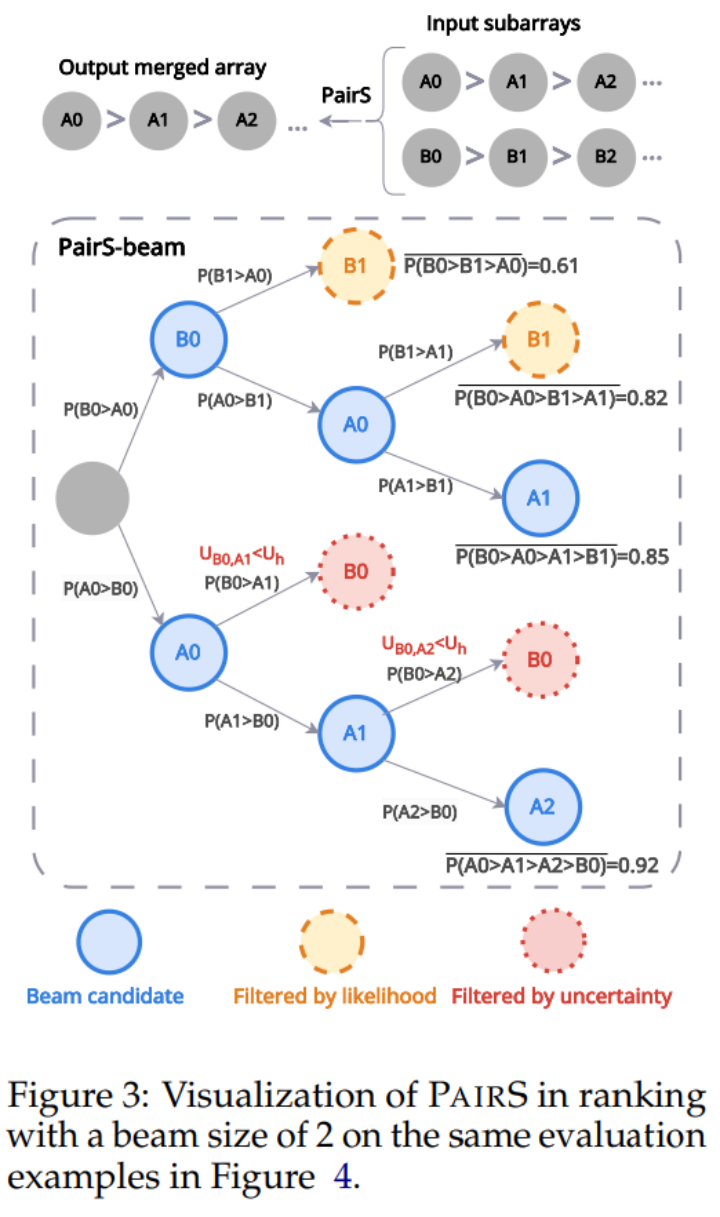
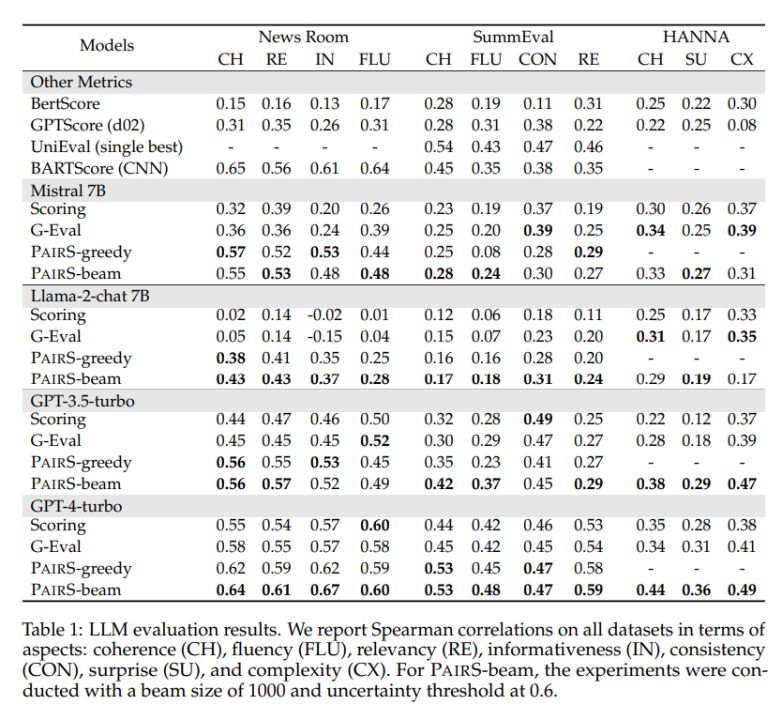
Seperti yang ditunjukkan dalam Rajah 1 di bawah, diilhamkan oleh penjajaran model ganjaran melalui data keutamaan dalam RLHF, kami percaya bahawa penilai LLM boleh diperolehi dengan menjana lebih banyak kedudukan keutamaan manusia -ramalan sejajar. Beberapa kerja baru-baru ini telah mula mendapatkan kedudukan keutamaan dengan meminta LLM melakukan perbandingan berpasangan. Walau bagaimanapun, menilai kerumitan dan skalabiliti kedudukan keutamaan telah banyak diabaikan. Mereka mengabaikan andaian transitiviti, menjadikan bilangan perbandingan O (N^2), menjadikan proses penilaian mahal dan tidak boleh dilaksanakan. PairS: Algoritma Carian Keutamaan Cekap Dalam kerja ini, kami mencadangkan dua algoritma carian keutamaan berpasangan (PairS-gredy dan PairS-beam). PairS-greedy ialah algoritma berdasarkan andaian transitiviti lengkap dan isihan gabungan, dan boleh mendapatkan pengisihan keutamaan global dengan hanya kerumitan O (NlogN). Andaian transitivity bermakna, sebagai contoh, untuk 3 calon, LLM sentiasa mempunyai jika A≻B dan B≻C, kemudian A≻C. Di bawah andaian ini kita boleh terus menggunakan algoritma kedudukan tradisional untuk mendapatkan kedudukan keutamaan daripada keutamaan berpasangan. Tetapi LLM tidak mempunyai transitiviti yang sempurna, jadi kami mereka bentuk algoritma PairS-beam. Di bawah andaian transitiviti yang lebih longgar, kami memperoleh dan memudahkan fungsi kemungkinan untuk kedudukan keutamaan. PairS-beam ialah kaedah carian yang melakukan carian rasuk berdasarkan nilai kebarangkalian dalam setiap operasi cantuman algoritma isihan cantum, dan mengurangkan ruang perbandingan berpasangan melalui ketidakpastian keutamaan. PairS-beam boleh melaraskan kerumitan kontras dan kualiti kedudukan, dan dengan cekap memberikan anggaran kemungkinan maksimum (MLE) kedudukan keutamaan. Dalam Rajah 3 di bawah kami menunjukkan contoh bagaimana PairS-beam melaksanakan operasi cantum. Hasil eksperimen Kami menguji pada berbilang set data perwakilan, termasuk tugas singkatan tertutup NewsRoom dan SummEval, dan tugas penjanaan cerita terbuka HANNA, dan membandingkan berbilang kaedah Baseline tunggal untuk LLM. penilaian, termasuk pemarkahan langsung tanpa pengawasan, G-Eval, GPTScore dan latihan diselia UniEval dan BARTScore. Seperti yang ditunjukkan dalam Jadual 1 di bawah, PairS mempunyai konsistensi yang lebih tinggi dengan penilaian manusia daripada mereka pada setiap tugas. GPT-4-turbo juga boleh mencapai kesan SOTA. Dalam artikel itu, kami juga membandingkan dua kaedah asas untuk kedudukan keutamaan, kadar kemenangan dan penilaian ELO. PairS boleh mencapai kedudukan keutamaan kualiti yang sama dengan hanya kira-kira 30% daripada bilangan perbandingan. Makalah ini juga memberikan lebih banyak cerapan tentang cara pilihan berpasangan boleh digunakan untuk mengira secara kuantitatif transitiviti penganggar LLM, dan cara penganggar berpasangan boleh mendapat manfaat daripada penentukuran. Untuk butiran penyelidikan lanjut, sila rujuk kertas asal. 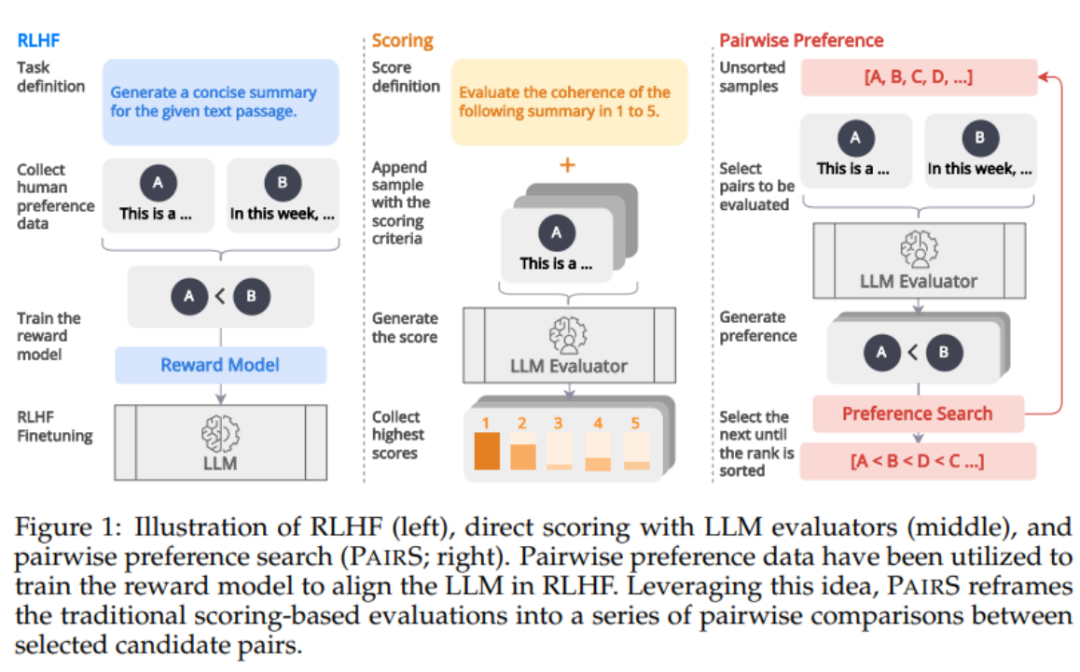
Atas ialah kandungan terperinci Kertas markah tinggi daripada COLM, persidangan model besar pertama: Algoritma carian keutamaan PairS menjadikan penilaian teks model besar lebih cekap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI