Lajur AIxiv ialah lajur di mana kandungan akademik dan teknikal diterbitkan di laman web ini. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Penjanaan video tarian manusia ialah tugas sintesis video boleh dikawal yang menarik dan mencabar, bertujuan untuk menjana video berdasarkan urutan imej rujukan dan menjana Sasaran video berterusan realistik berkualiti tinggi. Dengan perkembangan pesat teknologi penjanaan video, terutamanya evolusi berulang model generatif, tugas penjanaan video menari telah mencapai kemajuan yang tidak pernah berlaku sebelum ini dan menunjukkan pelbagai potensi aplikasi. Kaedah sedia ada boleh dibahagikan secara kasar kepada dua kumpulan. Kumpulan pertama biasanya berdasarkan Generative Adversarial Networks (GANs), yang mengeksploitasi perwakilan berpandukan pose perantaraan untuk meledingkan penampilan rujukan dan menjana bingkai video yang munasabah daripada sasaran yang sebelum ini melencong. Walau bagaimanapun, kaedah berdasarkan rangkaian musuh generatif sering mengalami latihan yang tidak stabil dan keupayaan generalisasi yang lemah, mengakibatkan artifak yang jelas dan jitter antara bingkai. Kumpulan kedua menggunakan model resapan untuk mensintesis video realistik. Kaedah ini mempunyai kelebihan latihan yang stabil dan keupayaan pemindahan yang kuat, dan berprestasi lebih baik daripada kaedah berasaskan GAN termasuk Disco, MagicAnimate, Animate Anyone, Champ, dsb. Walaupun kaedah berdasarkan model penyebaran telah mencapai kemajuan yang ketara, kaedah sedia ada masih mempunyai dua had: Pertama, rangkaian rujukan tambahan (ReferenceNet) diperlukan untuk mengekod ciri imej rujukan dan menggabungkannya dengan 3D-UNet Penjajaran yang jelas daripada cabang tulang belakang meningkatkan kesukaran latihan dan parameter model; kedua, mereka biasanya menggunakan Transformer temporal untuk memodelkan pergantungan temporal antara bingkai video, tetapi kerumitan Transformer menjadi kuadratik dengan panjang masa yang dijanakan panjang masa bagi video yang dijana. Kaedah biasa hanya boleh menjana 24 bingkai video, mengehadkan kemungkinan penggunaan praktikal. Walaupun strategi tetingkap gelongsor pertindihan temporal boleh menjana video yang lebih panjang, pengarang pasukan mendapati kaedah ini mudah membawa kepada masalah peralihan yang tidak lancar dan penampilan yang tidak konsisten pada persimpangan segmen yang bertindih. Untuk menyelesaikan masalah ini, pasukan penyelidik dari Universiti Sains dan Teknologi Huazhong, Alibaba, dan Universiti Sains dan Teknologi China mencadangkan rangka kerja UniAnimate untuk mencapai penjanaan video manusia yang cekap dan jangka panjang. 
- Alamat kertas: https://arxiv.org/abs/2406.01188
- Laman utama projek: https://unianimate.github.io/
Rangka kerja UniAnimate mula-mula memetakan imej rujukan, menunjukkan panduan dan video hingar ke dalam ruang ciri, dan kemudian menggunakan
Model Penyebaran Video Bersatu (Model Penyebaran Video Bersatu) untuk memproses secara serentak imej rujukan dan penjajaran jelas cabang tulang belakang video dan tugasan video Denoising untuk penjajaran ciri yang cekap dan penjanaan video yang koheren.
Kedua, pasukan penyelidik juga mencadangkan input hingar bersatu yang menyokong input hingar rawak dan input hingar bersyarat berdasarkan bingkai pertama Input hingar rawak boleh menghasilkan video dengan imej rujukan dan urutan pose, dan berdasarkan Input hingar bersyarat bagi bingkai pertama (Penyamanan Bingkai Pertama) menggunakan bingkai pertama video sebagai input bersyarat untuk terus menjana video berikutnya. Dengan cara ini, inferens boleh dijana dengan menganggap bingkai terakhir segmen video sebelumnya sebagai bingkai pertama segmen seterusnya, dan seterusnya untuk mencapai penjanaan video yang panjang dalam satu rangka kerja.

Akhir sekali, untuk memproses jujukan panjang dengan lebih cekap, pasukan penyelidik meneroka seni bina pemodelan masa berdasarkan model angkasa lepas (Mamba) sebagai alternatif kepada Transformer siri masa intensif pengiraan asal. Eksperimen telah mendapati bahawa seni bina berdasarkan Mamba berjujukan boleh mencapai kesan yang serupa dengan Transformer berjujukan, tetapi memerlukan kurang overhed memori grafik. 🎜🎜🎜🎜
Dengan rangka kerja UniAnimate, pengguna boleh menjana video tarian manusia siri masa berkualiti tinggi. Perlu dinyatakan bahawa dengan menggunakan strategi First Frame Conditioning beberapa kali, video definisi tinggi selama satu minit boleh dihasilkan. Berbanding dengan kaedah tradisional, UniAnimate mempunyai kelebihan berikut:
- Tidak memerlukan rangkaian rujukan tambahan: Rangka kerja UniAnimate menghapuskan pergantungan pada rangkaian rujukan tambahan melalui model penyebaran video bersatu, mengurangkan kesukaran latihan nombor dan model daripada parameter.
- Memperkenalkan peta pose imej rujukan sebagai syarat rujukan tambahan, yang menggalakkan rangkaian untuk mempelajari korespondensi antara pose rujukan dan pose sasaran, dan mencapai penjajaran jelas yang baik.
- Jana video urutan panjang dalam rangka kerja bersatu: Dengan menambahkan input hingar bersatu, UniAnimate dapat menjana video jangka panjang dalam bingkai, tidak lagi tertakluk kepada kekangan masa kaedah tradisional.
- Sangat konsisten: Rangka kerja UniAnimate memastikan kesan peralihan yang lancar bagi video yang dijana dengan menggunakan bingkai pertama secara berulang sebagai syarat untuk menjana bingkai berikutnya, menjadikan video lebih konsisten dan koheren dalam penampilan. Strategi ini juga membolehkan pengguna menjana berbilang klip video dan memilih bingkai terakhir klip dengan hasil yang baik sebagai bingkai pertama klip yang dijana seterusnya, memudahkan pengguna berinteraksi dengan model dan melaraskan hasil penjanaan mengikut keperluan. Walau bagaimanapun, apabila menjana video panjang menggunakan strategi tetingkap gelongsor pertindihan siri masa sebelumnya, pemilihan segmen tidak boleh dilakukan kerana setiap video digandingkan antara satu sama lain dalam setiap langkah proses resapan.
Ciri-ciri di atas menjadikan rangka kerja UniAnimate cemerlang dalam mensintesis video tarian manusia yang berkualiti tinggi dan jangka panjang, memberikan kemungkinan baharu untuk rangkaian aplikasi yang lebih luas. 


Penjanaan video menari berdasarkan gambar gaya tanah liat. 



6 Hasilkan video tarian berdasarkan imej merentas domain yang lain. 
7. Hasilkan video menari selama satu minit.  Untuk video MP4 asal dan lebih banyak contoh video HD, sila rujuk halaman utama projek kertas itu https://unianimate.github.io/. Analisis perbandingan eksperimen1. Eksperimen perbandingan kuantitatif dengan kaedah sedia ada pada set data TikTok.
Untuk video MP4 asal dan lebih banyak contoh video HD, sila rujuk halaman utama projek kertas itu https://unianimate.github.io/. Analisis perbandingan eksperimen1. Eksperimen perbandingan kuantitatif dengan kaedah sedia ada pada set data TikTok. 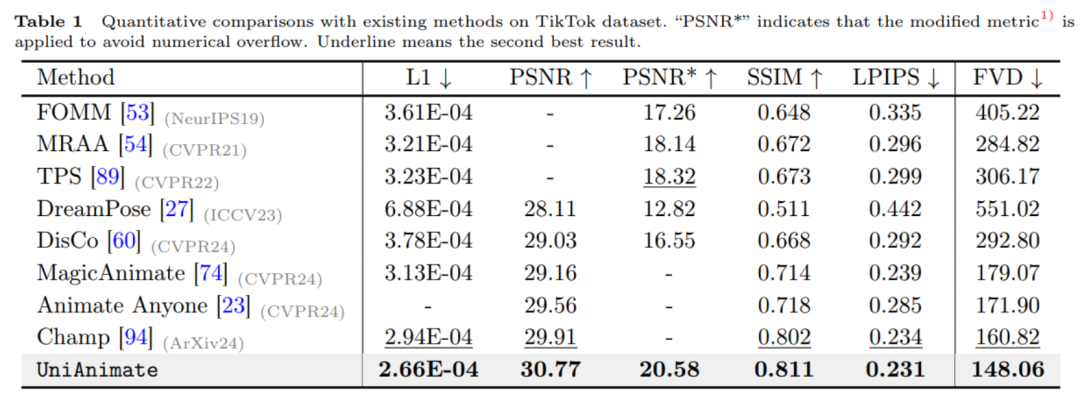
Seperti yang ditunjukkan dalam jadual di atas, kaedah UniAnimate mencapai hasil terbaik pada penunjuk imej seperti L1, PSNR, SSIM, LPIPS dan penunjuk video FVD, yang menunjukkan bahawa UniAnimate boleh menjana hasil kesetiaan tinggi. 2. Eksperimen perbandingan kualitatif dengan kaedah sedia ada. 
Ia juga boleh dilihat daripada eksperimen perbandingan kualitatif di atas bahawa berbanding dengan MagicAnimate dan Animate Anyone, kaedah UniAnimate boleh menjana hasil berterusan yang lebih baik tanpa artifak yang jelas, menunjukkan keberkesanan UniAnimate. 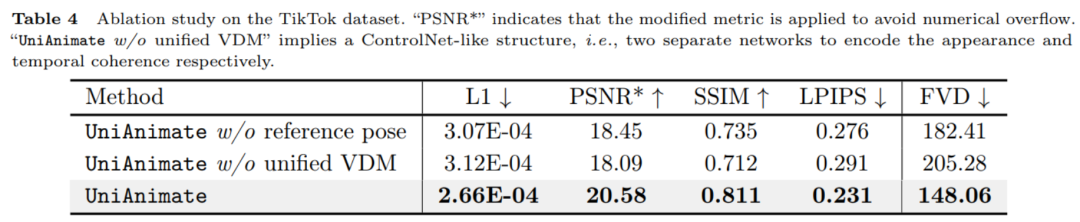
Seperti yang dapat dilihat daripada keputusan berangka dalam jadual di atas, pose rujukan dan model penyebaran video bersatu yang digunakan dalam UniAnimate memainkan peranan penting dalam meningkatkan prestasi. 4. Perbandingan strategi penjanaan video panjang. 
Seperti yang dapat dilihat daripada rajah di atas, strategi tetingkap gelongsor bertindih masa yang biasa digunakan untuk menjana video yang panjang boleh membawa kepada peralihan terputus dengan mudah bahagian bertindih masa, menjadikan hasil penjanaan Berbeza, purata langsung akan membawa kepada ubah bentuk atau herotan yang jelas, dan ketidakkonsistenan ini akan menyebabkan penyebaran ralat. Kaedah penjanaan sambungan video bingkai pertama yang digunakan dalam artikel ini boleh menjana peralihan yang lancar. Untuk lebih banyak hasil perbandingan eksperimen dan analisis, sila rujuk kertas asal. Secara keseluruhannya, hasil sampel UniAnimate dan hasil perbandingan kuantitatif sangat baik Kami menantikan aplikasi UniAnimate dalam pelbagai bidang, seperti penerbitan filem dan televisyen, realiti maya dan industri permainan, dan lain-lain, untuk membawa lebih ramai pengguna. imej manusia yang realistik dan menarik. Atas ialah kandungan terperinci Menyokong sintesis video definisi tinggi satu minit Huake et al mencadangkan rangka kerja baharu untuk penjanaan video tarian manusia, UniAnimate.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn



