
반드시 알아야 할 10가지 인공지능 알고리즘

- PHPz앞으로
- 2024-03-06 09:37:13736검색
인공지능 기술(AI)의 지속적인 인기와 함께 다양한 알고리즘이 이 분야의 발전을 촉진하는 데 중요한 역할을 하고 있습니다. 주택 가격을 예측하는 데 사용되는 선형 회귀 알고리즘부터 자율주행차를 구동하는 신경망에 이르기까지 이러한 알고리즘은 수많은 애플리케이션을 조용히 구동하고 운영합니다. 데이터 양이 증가하고 컴퓨팅 성능이 향상됨에 따라 인공지능 알고리즘의 성능과 효율성도 지속적으로 향상되고 있습니다. 이러한 알고리즘의 적용 범위는 의료 진단, 금융 위험 평가, 자연어 처리 등으로 점점 더 넓어지고 있습니다.

오늘은 인기 있는 인공지능 알고리즘( 선형 회귀, 로지스틱 회귀, 의사결정 트리, Naive Bayes, SVM(지원 벡터 머신), 앙상블 학습, K 최근접 이웃 알고리즘, K-평균 알고리즘, 신경망, 강화 학습 Deep Q-Networks), 작동 원리 탐색, 응용 시나리오 그리고 현실 세계에서의 적용은 다음과 같습니다.
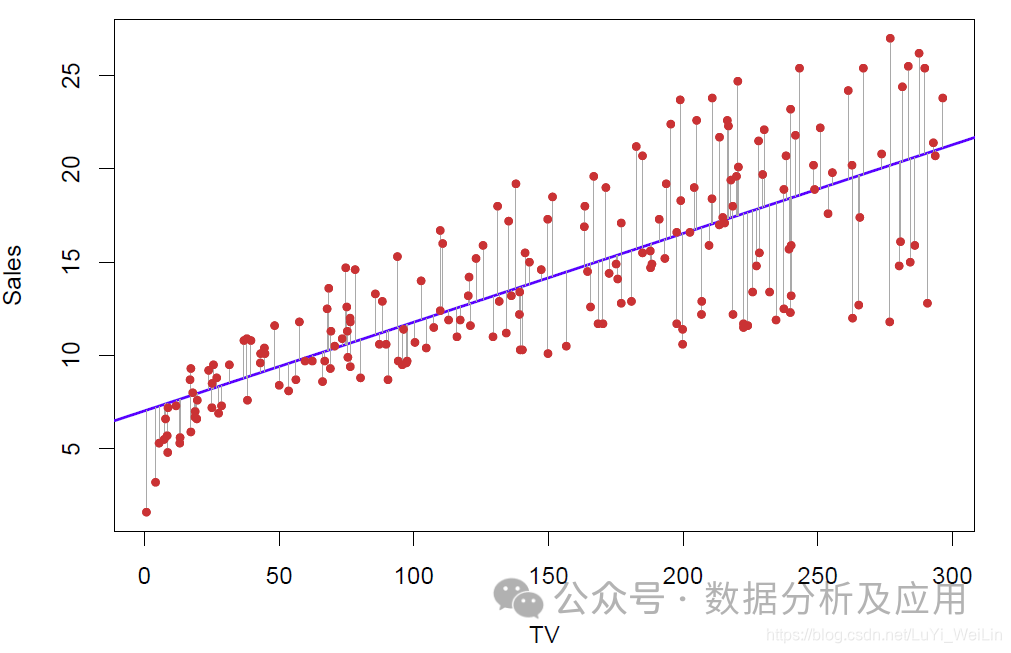
1. 선형 회귀:
선형 회귀의 원리는 데이터 포인트의 분포를 최대한 맞추는 최적의 직선을 찾는 것입니다.
모델 훈련은 알려진 입력 및 출력 데이터를 사용하여 일반적으로 예측 값과 실제 값 간의 차이를 최소화하여 모델을 최적화하는 것입니다.
장점: 간단하고 이해하기 쉽고, 계산 효율성이 높습니다.
단점: 비선형 관계를 처리하는 능력이 제한적입니다.
사용 시나리오: 주택 가격, 주가 예측 등 연속 값 예측 문제에 적합합니다.
샘플 코드(Python의 Scikit-learn 라이브러리를 사용하여 간단한 선형 회귀 모델 구축):
from sklearn.linear_model import LinearRegressionfrom sklearn.datasets import make_regression# 生成模拟数据集X, y = make_regression(n_samples=100, n_features=1, noise=0.1)# 创建线性回归模型对象lr = LinearRegression()# 训练模型lr.fit(X, y)# 进行预测predictions = lr.predict(X)
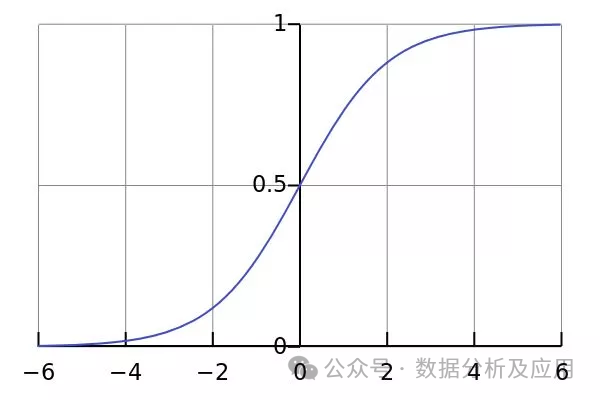
2 로지스틱 회귀:
모델 원리: 로지스틱 회귀는 A에 사용되는 방법입니다. 연속 입력을 개별 출력(일반적으로 이진)에 매핑하여 이진 분류 문제를 해결하는 기계 학습 알고리즘입니다. 분류 확률을 얻기 위해 로지스틱 함수를 사용하여 선형 회귀 결과를 (0,1) 범위로 매핑합니다.
모델 훈련: 알려진 분류의 샘플 데이터를 사용하여 모델의 매개변수를 최적화하여 예측 확률과 실제 분류 간의 교차 엔트로피 손실을 최소화함으로써 로지스틱 회귀 모델을 훈련합니다.
장점: 간단하고 이해하기 쉬우며 2분류 문제에 더 좋습니다.
단점: 비선형 관계를 처리하는 능력이 제한적입니다.
사용 시나리오: 스팸 필터링, 질병 예측 등과 같은 이진 분류 문제에 적합합니다.
샘플 코드(Python의 Scikit-learn 라이브러리를 사용하여 간단한 로지스틱 회귀 모델 구축):
from sklearn.linear_model import LogisticRegressionfrom sklearn.datasets import make_classification# 生成模拟数据集X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, random_state=42)# 创建逻辑回归模型对象lr = LogisticRegression()# 训练模型lr.fit(X, y)# 进行预测predictions = lr.predict(X)
3 모델 원칙: 의사결정 트리는 지도 학습입니다. 데이터 세트를 더 작은 하위 세트로 반복적으로 나누어 결정 경계를 구성하는 알고리즘입니다. 각 내부 노드는 특징 속성에 대한 판단 조건을 나타내고, 각 가지는 가능한 속성 값을 나타내며, 각 리프 노드는 카테고리를 나타냅니다.
모델 교육: 최상의 분할 속성을 선택하여 의사결정 트리를 구축하고 가지치기 기술을 사용하여 과적합을 방지합니다.
장점: 이해하고 설명하기 쉽고 분류 및 회귀 문제를 처리할 수 있습니다.
단점: 과적합되기 쉽고 노이즈와 이상치에 민감합니다.
사용 시나리오: 신용 카드 사기 감지, 일기 예보 등과 같은 분류 및 회귀 문제에 적합합니다.
샘플 코드(Python의 Scikit-learn 라이브러리를 사용하여 간단한 의사 결정 트리 모델 구축): 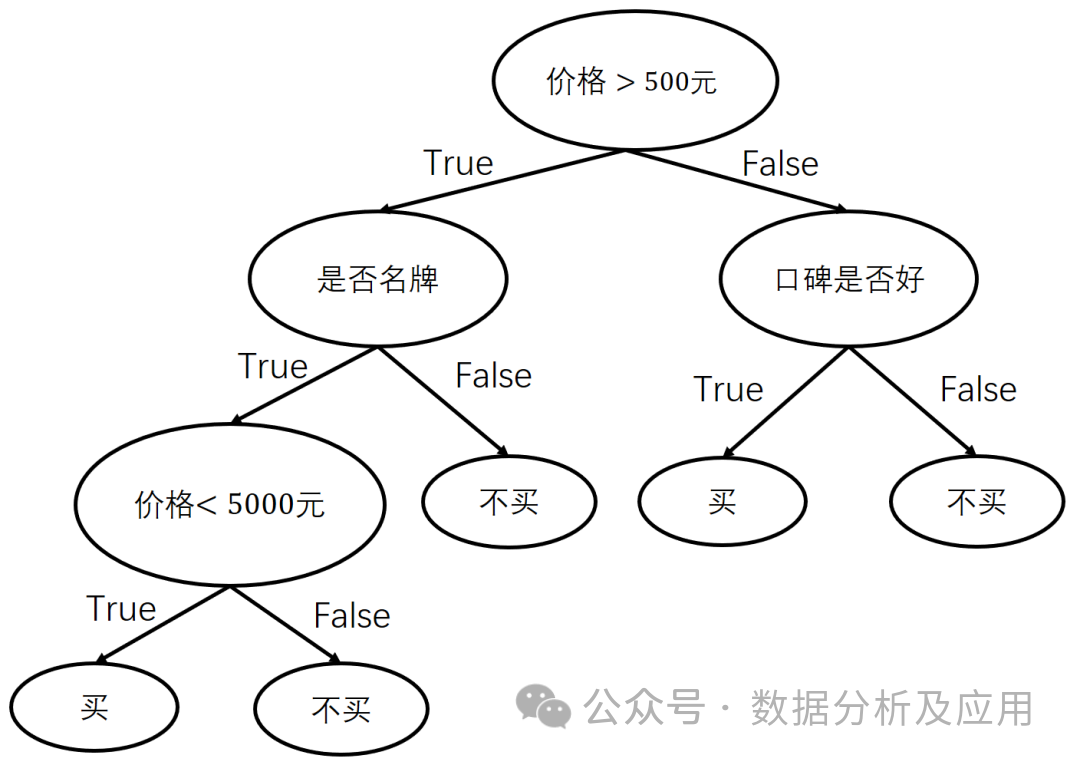
from sklearn.tree import DecisionTreeClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树模型对象dt = DecisionTreeClassifier()# 训练模型dt.fit(X_train, y_train)# 进行预测predictions = dt.predict(X_test)4, Naive Baye s:
모델 원칙: Naive Baye Si는 Bayes의 정리와 특징 조건부 독립 가정을 기반으로 한 분류 방법입니다. 각 카테고리에 속한 샘플의 속성값에 대해 확률론적 모델링을 수행한 후, 이러한 확률을 바탕으로 새로운 샘플이 속하는 카테고리를 예측합니다.
모델 훈련: 알려진 카테고리와 속성이 있는 샘플 데이터를 사용하여 Naive Bayes 분류기를 구축하여 각 카테고리의 사전 확률과 각 속성의 조건부 확률을 추정합니다.
장점: 간단하고 효율적이며 대규모 카테고리와 소규모 데이터 세트에 특히 효과적입니다.
단점: 기능 간의 종속성을 제대로 모델링하지 못합니다.
사용 시나리오: 텍스트 분류, 스팸 필터링 및 기타 시나리오에 적합합니다.
예제 코드(Python의 Scikit-learn 라이브러리를 사용하여 간단한 순진한 Bayes 분류기 구축): 
from sklearn.naive_bayes import GaussianNBfrom sklearn.datasets import load_iris# 加载数据集iris = load_iris()X = iris.datay = iris.target# 创建朴素贝叶斯分类器对象gnb = GaussianNB()# 训练模型gnb.fit(X, y)# 进行预测predictions = gnb.predict(X)
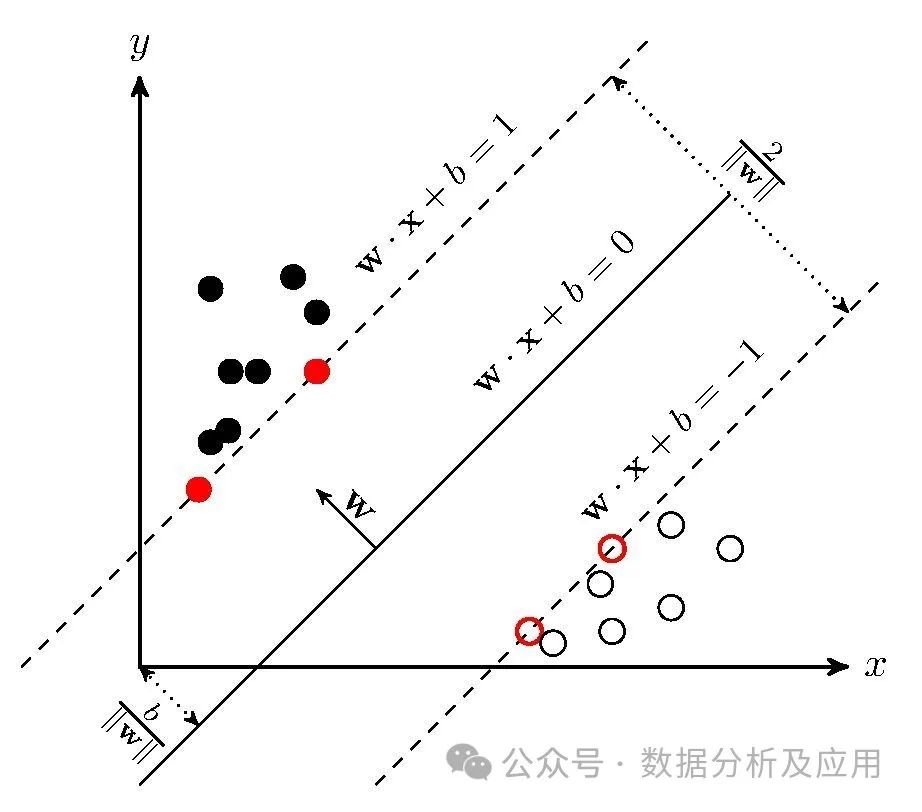
5、支持向量机(SVM):
模型原理:支持向量机是一种监督学习算法,用于分类和回归问题。它试图找到一个超平面,使得该超平面能够将不同类别的样本分隔开。SVM使用核函数来处理非线性问题。
模型训练:通过优化一个约束条件下的二次损失函数来训练SVM,以找到最佳的超平面。
优点:对高维数据和非线性问题表现良好,能够处理多分类问题。
缺点:对于大规模数据集计算复杂度高,对参数和核函数的选择敏感。
使用场景:适用于分类和回归问题,如图像识别、文本分类等。
示例代码(使用Python的Scikit-learn库构建一个简单的SVM分类器):
from sklearn import svmfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM分类器对象,使用径向基核函数(RBF)clf = svm.SVC(kernel='rbf')# 训练模型clf.fit(X_train, y_train)# 进行预测predictions = clf.predict(X_test)
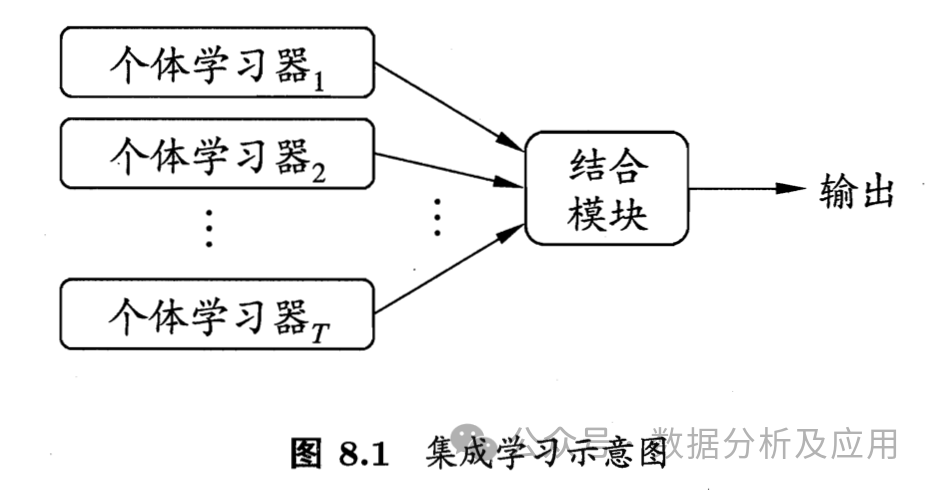
6、集成学习:
模型原理:集成学习是一种通过构建多个基本模型并将它们的预测结果组合起来以提高预测性能的方法。集成学习策略有投票法、平均法、堆叠法和梯度提升等。常见集成学习模型有XGBoost、随机森林、Adaboost等
模型训练:首先使用训练数据集训练多个基本模型,然后通过某种方式将它们的预测结果组合起来,形成最终的预测结果。
优点:可以提高模型的泛化能力,降低过拟合的风险。
缺点:计算复杂度高,需要更多的存储空间和计算资源。
使用场景:适用于解决分类和回归问题,尤其适用于大数据集和复杂的任务。
示例代码(使用Python的Scikit-learn库构建一个简单的投票集成分类器):
from sklearn.ensemble import VotingClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建基本模型对象和集成分类器对象lr = LogisticRegression()dt = DecisionTreeClassifier()vc = VotingClassifier(estimators=[('lr', lr), ('dt', dt)], voting='hard')# 训练集成分类器vc.fit(X_train, y_train)# 进行预测predictions = vc.predict(X_test)7、K近邻算法:
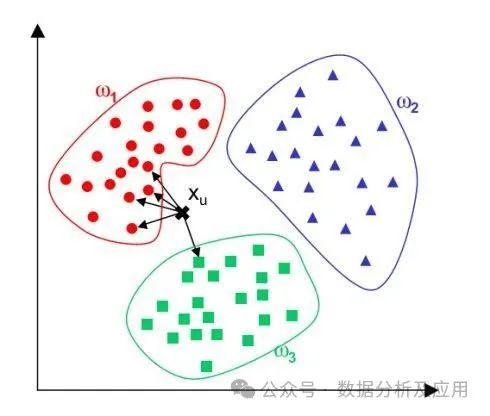
模型原理:K近邻算法是一种基于实例的学习,通过将新的样本与已知样本进行比较,找到与新样本最接近的K个样本,并根据这些样本的类别进行投票来预测新样本的类别。
模型训练:不需要训练阶段,通过计算新样本与已知样本之间的距离或相似度来找到最近的邻居。
优点:简单、易于理解,不需要训练阶段。
缺点:对于大规模数据集计算复杂度高,对参数K的选择敏感。
使用场景:适用于解决分类和回归问题,适用于相似度度量和分类任务。
示例代码(使用Python的Scikit-learn库构建一个简单的K近邻分类器):
from sklearn.neighbors import KNeighborsClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建K近邻分类器对象,K=3knn = KNeighborsClassifier(n_neighbors=3)# 训练模型knn.fit(X_train, y_train)# 进行预测predictions = knn.predict(X_test)
8、K-means算法:
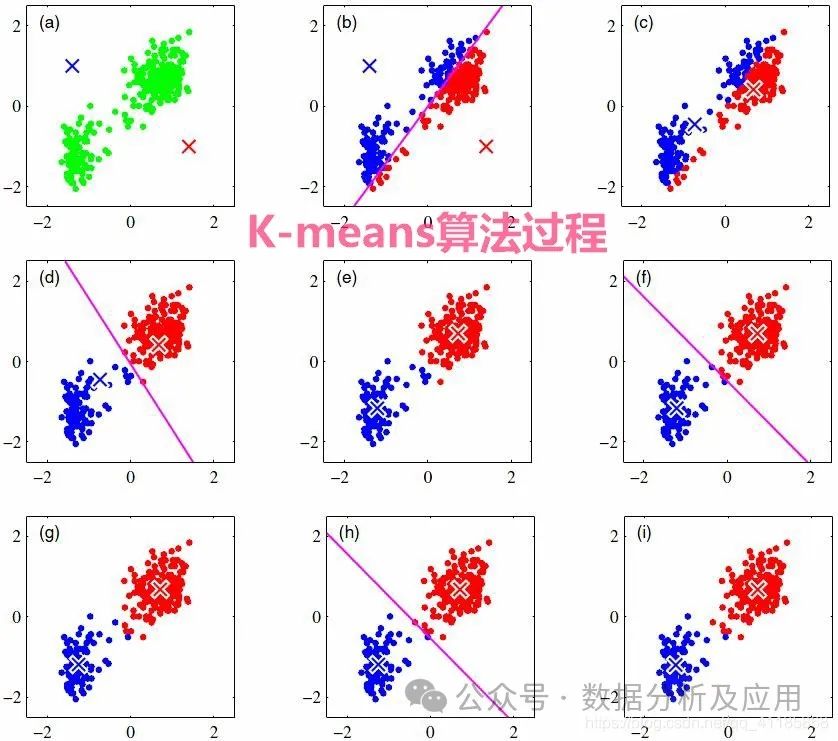
模型原理:K-means算法是一种无监督学习算法,用于聚类问题。它将n个点(可以是样本数据点)划分为k个聚类,使得每个点属于最近的均值(聚类中心)对应的聚类。
模型训练:通过迭代更新聚类中心和分配每个点到最近的聚类中心来实现聚类。
优点:简单、快速,对于大规模数据集也能较好地运行。
缺点:对初始聚类中心敏感,可能会陷入局部最优解。
使用场景:适用于聚类问题,如市场细分、异常值检测等。
示例代码(使用Python的Scikit-learn库构建一个简单的K-means聚类器):
from sklearn.cluster import KMeansfrom sklearn.datasets import make_blobsimport matplotlib.pyplot as plt# 生成模拟数据集X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)# 创建K-means聚类器对象,K=4kmeans = KMeans(n_clusters=4)# 训练模型kmeans.fit(X)# 进行预测并获取聚类标签labels = kmeans.predict(X)# 可视化结果plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')plt.show()
9、神经网络:
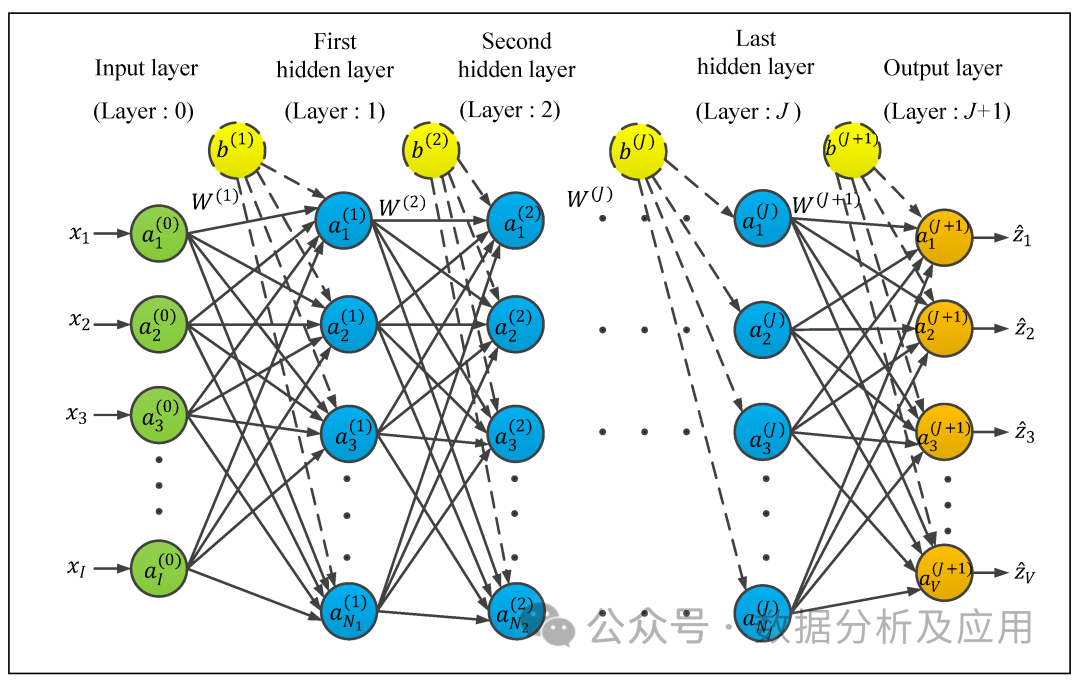
模型原理:神经网络是一种模拟人脑神经元结构的计算模型,通过模拟神经元的输入、输出和权重调整机制来实现复杂的模式识别和分类等功能。神经网络由多层神经元组成,输入层接收外界信号,经过各层神经元的处理后,最终输出层输出结果。
模型训练:神经网络的训练是通过反向传播算法实现的。在训练过程中,根据输出结果与实际结果的误差,逐层反向传播误差,并更新神经元的权重和偏置项,以减小误差。
优点:能够处理非线性问题,具有强大的模式识别能力,能够从大量数据中学习复杂的模式。
缺点:容易陷入局部最优解,过拟合问题严重,训练时间长,需要大量的数据和计算资源。
使用场景:适用于图像识别、语音识别、自然语言处理、推荐系统等场景。
示例代码(使用Python的TensorFlow库构建一个简单的神经网络分类器):
import tensorflow as tffrom tensorflow.keras import layers, modelsfrom tensorflow.keras.datasets import mnist# 加载MNIST数据集(x_train, y_train), (x_test, y_test) = mnist.load_data()# 归一化处理输入数据x_train = x_train / 255.0x_test = x_test / 255.0# 构建神经网络模型model = models.Sequential()model.add(layers.Flatten(input_shape=(28, 28)))model.add(layers.Dense(128, activation='relu'))model.add(layers.Dense(10, activation='softmax'))# 编译模型并设置损失函数和优化器等参数model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 训练模型model.fit(x_train, y_train, epochs=5)# 进行预测predictions = model.predict(x_test)
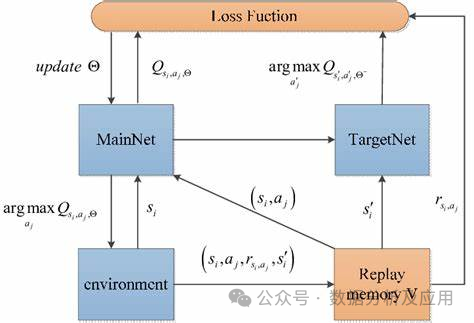
10.深度强化学习(DQN):
模型原理:Deep Q-Networks (DQN) 是一种结合了深度学习与Q-learning的强化学习算法。它的核心思想是使用神经网络来逼近Q函数,即状态-动作值函数,从而为智能体在给定状态下选择最优的动作提供依据。
模型训练:DQN的训练过程包括两个阶段:离线阶段和在线阶段。在离线阶段,智能体通过与环境的交互收集数据并训练神经网络。在线阶段,智能体使用神经网络进行动作选择和更新。为了解决过度估计问题,DQN引入了目标网络的概念,通过使目标网络在一段时间内保持稳定来提高稳定性。
优点:能够处理高维度的状态和动作空间,适用于连续动作空间的问题,具有较好的稳定性和泛化能力。
缺点:容易陷入局部最优解,需要大量的数据和计算资源,对参数的选择敏感。
使用场景:适用于游戏、机器人控制等场景。
示例代码(使用Python的TensorFlow库构建一个简单的DQN强化学习模型):
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense, Dropout, Flattenfrom tensorflow.keras.optimizers import Adamfrom tensorflow.keras import backend as Kclass DQN:def __init__(self, state_size, action_size):self.state_size = state_sizeself.action_size = action_sizeself.memory = deque(maxlen=2000)self.gamma = 0.85self.epsilon = 1.0self.epsilon_min = 0.01self.epsilon_decay = 0.995self.learning_rate = 0.005self.model = self.create_model()self.target_model = self.create_model()self.target_model.set_weights(self.model.get_weights())def create_model(self):model = Sequential()model.add(Flatten(input_shape=(self.state_size,)))model.add(Dense(24, activation='relu'))model.add(Dense(24, activation='relu'))model.add(Dense(self.action_size, activation='linear'))return modeldef remember(self, state, action, reward, next_state, done):self.memory.append((state, action, reward, next_state, done))def act(self, state):if len(self.memory) > 1000:self.epsilon *= self.epsilon_decayif self.epsilon
위 내용은 반드시 알아야 할 10가지 인공지능 알고리즘의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!