
자율주행과 궤도예측에 관한 글은 이 글이면 충분합니다!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-02-28 19:20:031310검색
궤적 예측은 자율주행에서 중요한 역할을 합니다. 자율주행 궤적 예측은 차량의 주행 과정에서 다양한 데이터를 분석하여 차량의 미래 주행 궤적을 예측하는 것을 말합니다. 자율주행의 핵심 모듈인 궤도 예측의 품질은 후속 계획 제어에 매우 중요합니다. 궤적 예측 작업은 풍부한 기술 스택을 보유하고 있으며 자율 주행 동적/정적 인식, 고정밀 지도, 차선, 신경망 아키텍처(CNN&GNN&Transformer) 기술 등에 대한 익숙함이 필요합니다. 시작하기가 매우 어렵습니다! 많은 팬들은 가능한 한 빨리 궤도 예측을 시작하여 함정을 피하기를 희망합니다. 오늘은 궤도 예측을 위한 몇 가지 일반적인 문제와 입문 학습 방법을 살펴보겠습니다.
소개 관련 지식
1. 미리보기 논문은 순서대로 되어 있나요?
A: 먼저 설문조사, 문제 공식화 및 딥러닝 기반 방법에서의 순차 네트워크, 그래프 신경망 및 평가를 살펴보겠습니다.
2. 행동 예측 궤적 예측이란? 커플링과 행동은 일반적으로 차선 변경, 주차, 추월, 가속, 좌회전, 우회전 등 대상 자동차가 취할 수 있는 동작을 말합니다. 직진합니다. 궤적은 시간 정보가 포함된 특정 미래 위치 지점을 나타냅니다.
3. Argoverse 데이터 세트에 언급된 데이터 구성 요소 중 레이블과 타겟은 무엇을 의미하나요? 라벨은 예측할 기간 내의 실측값을 참조합니까? 오른쪽 표에서 OBJECT_TYPE 열은 일반적으로 자율주행차 자체를 나타냅니다. 데이터 세트는 일반적으로 각 장면에 대해 예측할 하나 이상의 장애물을 지정하며 이러한 예측 대상을 대상 또는 초점 에이전트라고 합니다. 일부 데이터 세트는 차량, 보행자 또는 자전거와 같은 각 장애물에 대한 의미 라벨도 제공합니다.
Q2: 차량과 보행자의 데이터 형식이 동일합니까? 예를 들어, 한 점 구름 점은 보행자를 나타내고, 수십 개의 점은 차량을 나타냅니다. A: 이런 종류의 궤적 데이터 세트는 실제로 보행자와 차량 모두의 물체 중심점의 xyz 좌표를 제공합니다.
Q3: argo1 및 argo2 데이터 세트는 하나의 예상 장애물만 지정합니다. 그렇죠? 다중 에이전트 예측을 수행할 때 이 두 데이터 세트를 어떻게 사용합니까? Argo1은 하나의 장애물만 지정하는 반면 argo2는 최대 20개까지 지정할 수 있습니다. 그러나 장애물이 하나만 지정되더라도 여러 장애물을 예측하는 모델의 기능에는 영향을 미치지 않습니다.
4. 경로 계획에서는 일반적으로 저속 및 정적 장애물을 고려합니다. 궤적 예측을 결합하는 역할은 무엇인가요? ? 주요 스냅샷?A: 자체 차량 계획 궤적으로 자체 차량 궤적을 "예측"합니다. uniad
5를 참조하세요. 궤적 예측에는 차량 동역학 모델에 대한 요구 사항이 높나요? 정확한 차량 동역학 모델을 구축하려면 수학과 자동차 이론만 필요합니까?A: nn 네트워크는 기본적으로 필요하지 않습니다. 규칙 기반을 이해해야 합니다
6. 막연한 초보자, 지식을 넓히려면 어디서부터 시작해야 할까요? (아직 코드 작성 방법을 모릅니다)A: 먼저 리뷰를 읽고 마인드맵을 정리하세요. 예를 들어 "자율주행차의 궤적 예측을 위한 기계학습: 포괄적인 설문조사, 과제 및 향후 연구 방향" 리뷰는 영어 원문
7으로 이동하세요. . 예측 및 의사결정 무엇이 중요합니까? 예측이 그다지 중요하지 않다고 생각하는 이유는 무엇입니까?
A1(stu): 默认预测属于感知吧,或者决策中隐含预测,反正没有预测不行。A2(stu): 决策该规控做,有行为规划,高级一点的就是做交互和博弈,有的公司会有单独的交互博弈组
현재 선도 기업의 경우 예측은 일반적으로 큰 인식 모듈에 속합니까? 기준 치수? A: 예측은 다른 자동차의 궤적을 기반으로 하고, 제어는 자동차의 궤적을 기반으로 하며 두 궤적도 서로 영향을 주기 때문에 일반적으로 예측은 규제를 기반으로 합니다.
A: 서로 영향을 미치기 때문에 어떤 곳에서는 예측과 의사결정이 하나의 그룹입니다. 예를 들어, 자신의 자동차가 계획한 궤적이 다른 자동차를 압박하려는 경우 일반적으로 다른 자동차가 양보합니다. 따라서 일부 작업에서는 자체 차량 계획을 다른 차량 모델 입력의 일부로 간주합니다. M2I(M2I: From Factored Marginal Trajectory Prediction to Interactive Prediction)를 참고하시면 됩니다. PiP: Planning-informed Trajectory Prediction for Autonomous Driving
9.argoverse의 차선 중심선 지도에 대해 알아볼 수 있습니다. 교차로 내부 차선이 없는 곳은 어떻게 찾나요?A: 수동으로 표시
10. 궤적 예측을 사용하여 논문을 작성하는 경우 어떤 논문의 코드를 기준으로 사용할 수 있나요? hivt를 기준으로 사용하는 경우가 많습니다11. 요즘은 궤적 예측이 기본적으로 지도에 의존합니다. 새로운 지도 환경으로 변경하면 더 이상 재교육이 필요하지 않나요?
A: 특정 일반화 능력이 있으며 재교육 없이도 효과는 나쁘지 않습니다12 다중 모드 출력의 경우 최상의 궤적을 선택할 때 확률 값이 가장 높은 것을 기준으로 합니까
.
르레
궤적 예측 기본 모듈
1. Argoverse 데이터 세트에서 HD-Map을 사용하는 방법을 모션 예측과 결합하여 주행 장면 그래프를 구축할 수 있나요?
A: 이 과정에서 모두 다룹니다. 2장을 참조하세요. 이 내용은 4장에서도 다룹니다. 이종 그래프와 동형 그래프의 차이점: 동형 그래프에는 한 가지 유형의 노드만 있습니다. 예를 들어 소셜 네트워크에서 노드에는 한 가지 유형의 "사람"만 있고 가장자리에는 한 가지 유형의 "지식"만 있다고 상상할 수 있습니다. 그리고 사람들은 서로를 알 수도 있고 모르기도 합니다. 하지만 사람, 좋아요, 트윗을 분류하는 것도 가능합니다. 그러면 지인을 통해 사람들이 연결될 수도 있고, 트윗의 좋아요를 통해 사람들이 연결될 수도 있으며, 트윗의 좋아요(메타 경로)를 통해 사람들이 연결될 수도 있습니다. 여기서 노드와 노드 간의 관계를 다양하게 표현하려면 이종 그래프의 도입이 필요합니다. 이종 그래프에는 다양한 유형의 노드가 있습니다. 노드 간 연결 관계(에지)에도 여러 유형이 있으며, 이러한 연결 관계(메타 경로)의 조합 유형도 더욱 다양해집니다. 심각성.
2.A-A 상호작용은 어떤 차량이 예측 차량과 상호작용하는지 고려합니까?
A: 특정 반경 내의 자동차를 선택할 수도 있고, 가장 가까운 이웃이 K개인 자동차를 고려할 수도 있습니다. 더욱 발전된 경험적 이웃 선별 전략을 생각해낼 수도 있으며, 모델이 둘 중 하나인지 여부를 학습하는 것도 가능합니다. 이웃
Q2: 반경을 선택하는 원칙이 있나요? 또한, 선택한 차량은 어느 시점에 도착했나요? A: 반경 선택에 대한 표준적인 답을 얻기는 어렵습니다. 이는 본질적으로 예측을 할 때 모델이 얼마나 많은 원격 정보를 필요로 하는지 묻는 것과 같습니다. 두 번째 질문에 대한 개인적인 규칙은 어떤 시점의 객체 간의 상호 작용을 모델링하려면 해당 시점의 객체의 상대적 위치를 기준으로 이웃을 선택해야 한다는 것입니다
Q3: 이 경우 과거 시간에 대해 모든 도메인을 모델링해야 합니까? 특정 범위 내의 주변 차량도 서로 다른 시간 단계에 따라 변경됩니다. 아니면 현재 순간의 주변 차량 정보만 고려해야 합니까? A: 어느 쪽이든 모델을 어떻게 설계하느냐에 따라 다릅니다. -end 모델의 예측 부분에 어떤 결함이 있나요?
A: 모션 포머의 작동 방식은 비교적 일반적입니다. 많은 논문에서 유사한 SA와 CA를 볼 수 있습니다. 현재 Sota의 모델 중 상당수는 상대적으로 무겁습니다. 예를 들어 디코더는 순환 개선을 갖습니다.A2: 이것이 수행하는 작업은 공동 예측이 아닌 한계 예측입니다. 2. 예측과 계획은 두 요소 간의 상호 작용을 명시적으로 고려하지 않고 별도로 수행됩니다. 에고와 주변 에이전트 게임 3. 대칭을 고려하지 않고 장면 중심 표현을 사용하므로 효과가 불가피합니다Q2: 한계 예측이란 무엇입니까
A: 자세한 내용은 장면 변환기를 참조하세요Q3: 세 번째 점, 장면 중심에는 대칭이 없다는 점을 고려하면 어떻게 이해합니까A: HiVT, QCNet, MTR++를 살펴보는 것이 좋습니다. 물론 대칭 디자인은 end-to-end 모델에서는 쉽지 않습니다. A2: 입력은 장면 데이터라는 것을 이해할 수 있지만, 각 대상을 중심 관점으로 주변 장면을 볼 수 있도록 네트워크에서 모델링됩니다. 이러한 방식으로 각 대상의 코딩을 중심으로 얻을 수 있습니다. 상호작용 4. 에이전트 중심이란 무엇입니까?A: 각 에이전트에는 고유한 로컬 지역이 있으며, 로컬 지역은 이 에이전트를 중심으로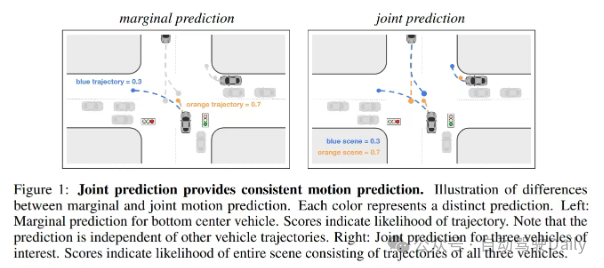
5. 궤적 예측에 요와 방향이 혼합되어 있습니다
A: 방향으로 이해될 수 있습니다.
6. 아르고버스 지도의 has_traffic_control 속성은 무엇을 의미하나요?
7. 궤적 예측에 대한 라플라스 손실과 휴버 손실의 장점과 단점은 무엇입니까?
A: 둘 다 시도해 보세요. 어느 쪽이 더 낫나요? 라플라스 손실이 효과적이려면 주의해야 할 몇 가지 세부 사항이 있습니다Q2: 매개변수를 조정해야 한다는 의미인가요? A: L1 손실과 비교하면 실제로 라플라스 손실은 스케일 매개변수를 하나 더 예측합니다Q3: 네, 그런데 이게 궤적 하나만 예측하면 무슨 소용이 있는지 모르겠네요. 중복처럼 느껴집니다. 불확실하다고 이해합니다. 맞는지는 모르겠습니다
A:如果你从零推导过最小二乘法就会知道,MSE其实是假设了方差为常数的高斯分布的NLL。同理,L1 loss也是假设了方差为常数的Laplace分布的NLL。所以说LaplaceNLL也可以理解为方差非定值的L1 loss。这个方差是模型自己预测出来的。为了使loss更低,模型会给那些拟合得不太好的样本一个比较大的方差,而给拟合得好的样本比较小的方差
Q4:那是不是可以理解为对于非常随机的数据集【轨迹数据存在缺帧 抖动】 就不太适合Laplace 因为模型需要去拟合这个方差?需要数据集质量比较高
A:这个说法我觉得不一定成立。从效果上来看,会鼓励模型优先学习比较容易拟合的样本,再去学习难学习的样本
Q5:还想请问下这句话(Laplace loss要效果好还是有些细节要注意的)如何理解 A:主要是预测scale那里。在模型上,预测location的分支和预测scale的分支要尽量解耦,不要让他们相互干扰。预测scale的分支要保证输出结果>0,一般人会用exp作为激活函数保证非负,但是我发现用ELU +1会更好。然后其实scale的下界最好不要是0,最好让scale>0.01或者>0.1啥的。以上都是个人看法。其实我开源的代码(周梓康大佬的github开源代码)里都有这些细节,不过可能大家不一定注意到。
给出链接:https://github.com/ZikangZhou/QCNet
https://github.com/ZikangZhou/HiVT
8. 有拿VAE做轨迹预测的吗,给个链接!
https://github.com/L1aoXingyu/pytorch-beginner/tree/master/08-AutoEncoder
9. 请问大伙一个问题,就是Polyline到底是啥?另外说polyline由向量Vector组成,这些Vector是相当于节点吗?
A:Polyline就是折线,折线就是一段一段的,每一段都可以看成是一段向量Q2:请问这个折线段和图神经网络的节点之间的边有关系吗?或者说Polyline这个折现向量相当于是图神经网络当中的节点还是边呀?A:一根折线可以理解为一个节点。轨迹预测里面没有明确定义的边,边如何定义取决于你怎么理解这个问题。Q3: VectorNet里面有很多个子图,每个子图下面有很多个Polyline,把Polyline当做向量的话,就相当于把Polyline这个节点变成了向量,相当于将节点进行特征向量化对吗?然后Polyline里面有多个Vector向量,就是相当于是构成这个节点的特征矩阵么?A: 一个地图里有很多条polyline;一个Polyline就是一个子图;一个polyline由很多段比较短的向量组成,每一段向量都是子图上的一个节点
10. 有的论文,像multipath++对于地图两个点就作为一个单元,有的像vectornet是一条线作为一个单元,这两种有什么区别吗?
A: 节点的粒度不同,要说效果的话那得看具体实现;速度的话,显然粒度越粗效率越高Q2:从效果角度看,什么时候选用哪种有没有什么原则?A: 没有原则,都可以尝试
11. 꼭 해야 한다면 점수의 매끄러움을 판단할 수 있는 방법이 있나요?
A: 0~19, 1~20 프레임 등의 흐르는 입력을 입력한 다음 해당 궤적을 비교해야 합니다. 두 프레임 사이의 점수 차이의 제곱을 통계적으로 계산할 수 있습니다
Q2: 토마스 선생님은 어떤 지표를 추천하시나요? 현재 1차 미분과 2차 미분을 사용하고 있습니다. 그러나 대부분의 1차 도함수와 2차 도함수는 0 근처에 집중되어 있습니다.
A: 연속 프레임의 해당 궤적 점수의 제곱 차이로 충분하다고 생각합니다. 예를 들어 n개의 연속 입력이 있는 경우 이를 합산하여 n으로 나눕니다. 하지만 장면은 실시간으로 바뀌고, 상호작용이 있거나 비교차점에서 교차점으로 점수가 갑자기 바뀌어야 합니다. 12. hivt의 궤적은 ×0.01+10과 같이 스케일링되지 않나요? 분포는 가능한 한 0에 가깝습니다. 나는 그것을 볼 때 어떤 방법을 사용하고 어떤 방법은 사용하지 않습니다. 상충관계를 어떻게 정의할 수 있나요?
A: 데이터를 표준화하세요. 다소 유용할 수도 있지만 그다지 많지는 않을 것입니다
13. 왜 HiVT에 있는 지도의 카테고리 속성이 연결 대신 숫자 속성에 추가되나요?
A: 추가와 연결은 큰 차이가 없지만 카테고리 임베딩과 수치 임베딩의 융합에서는 실제로 완전히 동일합니다.
Q2: 완전 동일성을 어떻게 이해해야 하나요? A: 두 개를 연결한 후 선형 레이어를 통과한 후 실제로는 선형 레이어를 통해 값을 포함하고 선형 레이어를 통해 카테고리를 포함한 다음 두 개의 카테고리를 포함하는 선형 레이어를 추가하는 것과 같습니다. 실제로는 의미가 없습니다. 이 선형 레이어는 nn.Embeddding14의 매개변수와 통합될 수 있습니다. 사용자는 실제로 배포되는 HiVT의 최소 하드웨어 요구 사항에 대해 더 관심을 가질 수 있습니다.
A: 잘 모르겠지만, 배운 정보에 따르면 NV인지, 어느 자동차 제조사가 HiVT를 사용하여 보행자를 예측하는지 모르므로 실제 배포는 확실히 가능합니다
15. 점유 네트워크 기반 예측 특별한 것이 있나요? 추천할만한 논문이 있나요?
A: 점유를 기반으로 한 미래 예측을 위한 가장 유망한 솔루션은 다음과 같습니다: https://arxiv.org/abs/2308.01471
16. 계획된 궤적 예측을 고려한 권장 논문이 있습니까? 다른 장애물을 예측할 때 자차의 계획된 궤적을 고려하는 것일까요?
A: 이 잠재적인 공개 데이터 세트는 어렵고 일반적으로 차량의 계획된 궤적을 제공하지 않습니다. 고대에는 PiP, Hong Kong Ke Haoran Song이라는 기사가있었습니다. M2I
17과 같은 조건부 예측에 관한 기사를 읽고 참고할 수 있는 예측 알고리즘의 성능 테스트에 적합한 시뮬레이션 프로젝트가 있습니까?
A(stu): This paper 토론이 있습니다: 자율 주행을 위한 오픈 소스 시뮬레이터에 대한 검토
18. Argoverse 데이터 세트를 사용하는 경우 이를 계산하는 방법은 무엇입니까? : 사용법과 관련이 있습니다. 예전에는 1070에서 hivt를 실행할 수 있었는데 이제는 일반 컴퓨터에서도 괜찮을 것 같습니다
원본 링크: https://mp.weixin.qq.com/ s/EEkr8g4w0s2zhS_jmczUiA
위 내용은 자율주행과 궤도예측에 관한 글은 이 글이면 충분합니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!