

칭화대학교와 Ideal은 자율주행 능력을 향상시키기 위한 시각적 대형 언어 모델인 DriveVLM을 제안했습니다.

자율주행 분야에서는 GPT/Sora 등 대형 모델의 방향도 연구자들이 모색하고 있습니다.
제너레이티브 AI에 비해 자율주행 역시 최근 AI에서 가장 활발한 연구개발 분야 중 하나입니다. 완전 자율주행 시스템을 구축하는 데 있어 가장 큰 과제는 악천후, 복잡한 도로 레이아웃, 예측할 수 없는 인간 행동 등 복잡하고 예측할 수 없는 시나리오를 포함하는 AI의 장면 이해입니다.
현재 자율주행 시스템은 일반적으로 3D 인식, 동작 예측, 계획 세 부분으로 구성됩니다. 특히 3D 인식은 주로 친숙한 물체를 감지하고 추적하는 데 사용되지만 희귀한 물체와 그 속성을 식별하는 능력은 제한적입니다. 반면 모션 예측 및 계획은 주로 물체의 궤적 동작에 중점을 두지만 일반적으로 물체와 차량 간의 관계를 무시합니다. . 이러한 제한은 복잡한 교통 시나리오를 처리할 때 자율 주행 시스템의 정확성과 안전성에 영향을 미칠 수 있습니다. 따라서 미래의 자율주행 기술은 다양한 유형의 물체를 더 잘 식별하고 예측하고, 차량의 주행 경로를 보다 효과적으로 계획하여 시스템의 지능성과 신뢰성을 향상시킬 수 있도록 더욱 발전해야 합니다
자율주행 달성의 핵심은 목표입니다 데이터 기반 접근 방식을 지식 기반 접근 방식으로 전환하려면 논리적 추론 기능을 갖춘 대규모 모델을 훈련해야 합니다. 그래야만 자율주행 시스템이 롱테일 문제를 진정으로 해결하고 L4 역량을 향해 나아갈 수 있습니다. 현재 GPT4, 소라 등 대형 모델이 계속해서 등장하면서 스케일 효과 역시 강력한 퓨샷/제로샷 능력을 발휘하며 새로운 개발 방향을 고민하게 만들었다.
Tsinghua University Cross Information Institute와 Li Auto의 최신 연구 논문에서 DriveVLM이라는 새로운 모델을 소개했습니다. 이 모델은 생성 인공 지능 분야에서 등장하는 시각적 언어 모델(VLM)에서 영감을 받았습니다. DriveVLM은 시각적 이해 및 추론 분야에서 탁월한 능력을 입증했습니다.
이 작업은 업계 최초로 자율주행 속도 제어 시스템을 제안한 것으로, 그 방법은 주류 자율주행 프로세스와 논리적 사고 능력을 갖춘 대규모 모델 프로세스를 완벽하게 결합하고, 성공적으로 구현한 최초의 사례입니다. -테스트를 위해 터미널에 모델을 확장합니다(Orin 플랫폼 기반).
DriveVLM은 시나리오 설명, 시나리오 분석, 계층적 계획이라는 세 가지 주요 모듈을 포함하는 CoT(사슬 연결) 프로세스를 다룹니다. 장면 설명 모듈에서 언어는 운전 환경을 설명하고 장면의 주요 개체를 식별하는 데 사용됩니다. 장면 분석 모듈은 이러한 주요 개체의 특성과 자율 차량에 미치는 영향을 심층적으로 연구하는 동시에 계층적 계획 모듈에서 점차적으로 계획을 수립합니다. 요소의 행동과 결정은 웨이포인트에 설명됩니다.
이러한 모듈은 기존 자율주행 시스템의 인식, 예측, 계획 단계에 해당하지만, 차이점은 과거에는 매우 어려웠던 객체 인식, 의도 수준 예측, 작업 수준 계획을 처리한다는 것입니다.
VLM은 시각적 이해 측면에서 뛰어난 성능을 발휘하지만 공간 기반 및 추론에 한계가 있으며 컴퓨팅 성능 요구 사항으로 인해 최종 추론 속도에 문제가 발생합니다. 따라서 저자는 DriveVLM과 기존 시스템의 장점을 결합한 하이브리드 시스템인 DriveVLMDual을 추가로 제안합니다. DriveVLM-Dual은 선택적으로 DriveVLM을 3D 개체 감지기, 점유 네트워크 및 모션 플래너와 같은 기존 3D 인식 및 계획 모듈과 통합하여 시스템이 3D 접지 및 고주파 계획 기능을 달성할 수 있도록 합니다. 이 이중 시스템 설계는 인간 두뇌의 느리고 빠른 사고 과정과 유사하며 운전 시나리오의 다양한 복잡성에 효과적으로 적응할 수 있습니다.
새로운 연구는 또한 장면 이해 및 계획(SUP) 작업의 정의를 더욱 명확하게 하고 장면 분석 및 메타 작업 계획에서 DriveVLM 및 DriveVLM-Dual의 기능을 평가하기 위한 몇 가지 새로운 평가 지표를 제안합니다. 또한 저자는 SUP 작업을 위한 내부 SUP-AD 데이터 세트를 구축하기 위해 광범위한 데이터 마이닝 및 주석 작업을 수행했습니다.
nuScenes 데이터세트와 자체 데이터세트에 대한 광범위한 실험은 특히 적은 수의 샷에서 DriveVLM의 우수성을 보여줍니다. 또한 DriveVLM-Dual은 최첨단 엔드 투 엔드 모션 계획 방법을 능가합니다.
논문 "DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models"

논문 링크: https://arxiv.org/abs/2402.12289
프로젝트 링크: https://tsinghua-mars- lab.github.io/DriveVLM/
DriveVLM의 전체 프로세스는 그림 1에 나와 있습니다.
연속 프레임 시각적 이미지를 인코딩하고 기능 정렬 모듈을 통해 LMM과 상호 작용합니다.
장면 설명에서 시작 VLM 모델을 생각하여 시간, 장면, 차선 환경 등의 정적인 장면을 먼저 안내한 다음 운전 결정에 영향을 미치는 주요 장애물을 안내합니다.
전통적인 3D 감지를 통해 주요 장애물을 분석하고 일치시킵니다. VLM이 이해하는 장애물, 장애물의 효과를 더욱 확인하고 환상을 제거하고, 이 장면의 주요 장애물의 특성과 그것이 운전에 미치는 영향을 설명합니다.
감속, 주차, 좌회전, 우회전 등 핵심 '메타 결정'을 제시하고, 메타 결정에 따른 운전 전략을 설명하고, 마지막으로 미래 운전 궤적을 제시합니다. 호스트 차량.
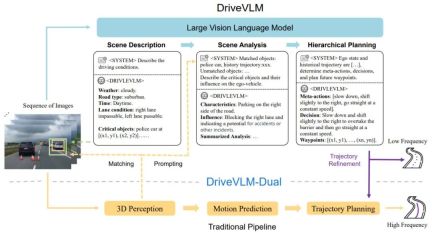
그림 1. DriveVLM 및 DriveVLM-이중 모델 파이프라인. 일련의 이미지는 대형 시각적 언어 모델(VLM)에 의해 처리되어 특별한 CoT(사고 연쇄) 추론을 수행하여 운전 계획 결과를 도출합니다. 대형 VLM에는 시각적 변환기 인코더와 LLM(대형 언어 모델)이 포함됩니다. 시각적 인코더는 이미지 태그를 생성한 다음 이러한 태그를 LLM과 정렬하고 마지막으로 LLM이 CoT 추론을 수행합니다. CoT 프로세스는 시나리오 설명, 시나리오 분석, 계층적 계획의 세 가지 모듈로 나눌 수 있습니다.
DriveVLM-Dual은 DriveVLM의 환경에 대한 포괄적인 이해와 의사결정 궤적 제안을 활용하여 기존 자율주행 파이프라인의 의사결정 및 계획 능력을 향상시키는 하이브리드 시스템입니다. 3D 인식 결과를 언어적 신호에 통합하여 3D 장면 이해를 향상시키고 실시간 모션 플래너를 통해 궤적 웨이포인트를 더욱 구체화합니다.
VLM은 롱테일 개체를 식별하고 복잡한 장면을 이해하는 데 능숙하지만 개체의 공간적 위치와 세부적인 동작 상태를 정확하게 이해하는 데 어려움을 겪는 경우가 많으며 이는 심각한 문제를 야기하는 단점입니다. 설상가상으로 VLM의 거대한 모델 크기로 인해 대기 시간이 길어져 자율 주행의 실시간 응답 기능이 저하됩니다. 이러한 문제를 해결하기 위해 저자는 DriveVLM과 기존 자율 주행 시스템이 협력할 수 있는 DriveVLM-Dual을 제안합니다. 이 새로운 접근 방식에는 두 가지 주요 전략이 포함됩니다. 주요 객체 분석과 3D 인식을 결합하여 고차원 운전 결정 정보를 제공하는 것과 고주파 궤적 개선입니다.
또한 복잡하고 롱테일 주행 시나리오를 처리하는 데 있어 DriveVLM 및 DriveVLMDual의 잠재력을 완전히 실현하기 위해 연구원들은 장면 이해 계획이라는 작업과 일련의 평가 지표를 공식적으로 정의했습니다. 또한 저자는 장면 이해 및 계획 데이터 세트를 관리하기 위해 데이터 마이닝 및 주석 프로토콜을 제안합니다.
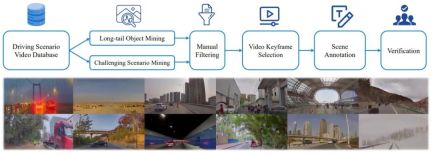
모델을 완전히 훈련하기 위해 저자는 자동화된 마이닝, 지각 알고리즘 사전 브러싱, GPT-4 대형 모델 요약 및 수동 주석의 조합을 통해 Drive LLM 주석 도구 및 주석 솔루션 세트를 새로 개발했습니다. 현재 모델은 이러한 효율적인 주석 체계를 통해 각 클립 데이터에 수십 개의 주석 내용이 포함되어 있습니다. -그림 2. SUP-AD 데이터 세트의 공지 샘플.

그림 3. 시나리오 이해 및 데이터 세트 계획을 구축하기 위한 데이터 마이닝 및 주석 파이프라인(위). 데이터 세트(아래)에서 무작위로 샘플링된 시나리오의 예는 데이터 세트의 다양성과 복잡성을 보여줍니다.
nuScenes 데이터세트는 각각 약 20초 동안 지속되는 1000개의 장면으로 구성된 대규모 도시 장면 주행 데이터세트입니다. 키프레임은 전체 데이터세트에 걸쳐 2Hz로 균일하게 주석이 추가됩니다. 여기서 저자는 검증 세분화에 대한 모델 성능을 평가하기 위한 지표로 변위 오류(DE)와 충돌률(CR)을 채택했습니다. 저자는 표 1과 같이 여러 대규모 시각적 언어 모델을 사용하여 DriveVLM의 성능을 시연하고 이를 GPT-4V와 비교합니다. DriveVLM은 Qwen-VL을 백본으로 활용하여 다른 오픈 소스 VLM에 비해 최고의 성능을 달성하고 응답성과 유연한 상호 작용이 특징입니다. 처음 두 개의 대형 모델은 오픈 소스였으며 미세 조정 교육에 동일한 데이터를 사용했습니다. GPT-4V는 신속한 엔지니어링을 위해 복잡한 프롬프트를 사용합니다. 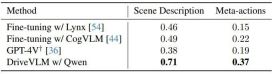
표 1. SUP-AD 데이터세트의 테스트 세트 결과. 여기에는 GPT-4V의 공식 API가 사용되며 Lynx 및 CogVLM의 경우 훈련 분할이 미세 조정에 사용됩니다.
표 2에서 볼 수 있듯이 DriveVLM-Dual은 VAD와 함께 사용하면 nuScenes 계획 작업에서 최첨단 성능을 달성합니다. 이는 새로운 방법이 복잡한 장면을 이해하기 위해 맞춤화되었지만 일반적인 장면에서도 잘 수행된다는 것을 보여줍니다. DriveVLM-Dual은 UniAD에 비해 크게 향상되었습니다. 평균 계획 변위 오류는 0.64미터 감소하고 충돌률은 51% 감소합니다.
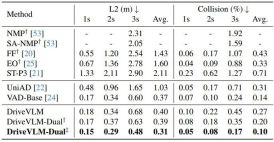
표 2. nuScenes 검증 데이터 세트에 대한 계획 결과. DriveVLM-Dual은 최적의 성능을 달성합니다. †Uni-AD를 이용한 인식 및 점유 예측 결과를 나타냅니다. ‡ 모든 모델이 자아 상태를 입력으로 사용하는 VAD 작업을 나타냅니다. 그림 4. DriveVLM의 정성적 결과. 주황색 곡선은 다음 3초 동안 모델이 계획한 미래 궤적을 나타냅니다. 
위 내용은 칭화대학교와 Ideal은 자율주행 능력을 향상시키기 위한 시각적 대형 언어 모델인 DriveVLM을 제안했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 Huggingface Smollm으로 개인 AI 조수를 만드는 방법Apr 18, 2025 am 11:52 AM
Huggingface Smollm으로 개인 AI 조수를 만드는 방법Apr 18, 2025 am 11:52 AMON-DEVICE AI의 힘을 활용 : 개인 챗봇 CLI 구축 최근에 개인 AI 조수의 개념은 공상 과학처럼 보였다. 기술 애호가 인 Alex, 똑똑하고 현지 AI 동반자를 꿈꾸는 것을 상상해보십시오.
 정신 건강을위한 AI는 스탠포드 대학교의 흥미로운 새로운 이니셔티브를 통해주의 깊게 분석됩니다.Apr 18, 2025 am 11:49 AM
정신 건강을위한 AI는 스탠포드 대학교의 흥미로운 새로운 이니셔티브를 통해주의 깊게 분석됩니다.Apr 18, 2025 am 11:49 AMAI4MH의 첫 출시는 2025 년 4 월 15 일에 열렸으며, 유명한 정신과 의사이자 신경 과학자 인 Luminary Dr. Tom Insel 박사는 킥오프 스피커 역할을했습니다. Insel 박사는 정신 건강 연구 및 테크노에서 뛰어난 작업으로 유명합니다.
 2025 WNBA 드래프트 클래스는 리그가 성장하고 온라인 괴롭힘과 싸우고 있습니다.Apr 18, 2025 am 11:44 AM
2025 WNBA 드래프트 클래스는 리그가 성장하고 온라인 괴롭힘과 싸우고 있습니다.Apr 18, 2025 am 11:44 AMEngelbert는 "WNBA가 모든 사람, 플레이어, 팬 및 기업 파트너가 안전하고 가치가 있으며 권한을 부여받는 공간으로 남아 있기를 원합니다. 아노
 파이썬 내장 데이터 구조에 대한 포괄적 인 가이드 - 분석 VidhyaApr 18, 2025 am 11:43 AM
파이썬 내장 데이터 구조에 대한 포괄적 인 가이드 - 분석 VidhyaApr 18, 2025 am 11:43 AM소개 Python은 특히 데이터 과학 및 생성 AI에서 프로그래밍 언어로 탁월합니다. 대규모 데이터 세트를 처리 할 때 효율적인 데이터 조작 (저장, 관리 및 액세스)이 중요합니다. 우리는 이전에 숫자와 st를 다루었습니다
 대안과 비교하여 OpenAi의 새로운 모델의 첫인상Apr 18, 2025 am 11:41 AM
대안과 비교하여 OpenAi의 새로운 모델의 첫인상Apr 18, 2025 am 11:41 AM다이빙하기 전에 중요한 경고 : AI 성능은 비 결정적이며 고도로 사용하는 것이 중요합니다. 간단히 말하면 마일리지는 다를 수 있습니다. 이 기사 (또는 다른) 기사를 최종 단어로 취하지 마십시오. 대신 에이 모델을 자신의 시나리오에서 테스트하십시오.
 AI 포트폴리오 | AI 경력을위한 포트폴리오를 구축하는 방법은 무엇입니까?Apr 18, 2025 am 11:40 AM
AI 포트폴리오 | AI 경력을위한 포트폴리오를 구축하는 방법은 무엇입니까?Apr 18, 2025 am 11:40 AM뛰어난 AI/ML 포트폴리오 구축 : 초보자 및 전문가를위한 안내서 인공 지능 (AI) 및 머신 러닝 (ML)의 역할을 확보하는 데 강력한 포트폴리오를 만드는 것이 중요합니다. 이 안내서는 포트폴리오 구축에 대한 조언을 제공합니다
 보안 운영에 대한 에이전트 AI가 무엇을 의미 할 수 있는지Apr 18, 2025 am 11:36 AM
보안 운영에 대한 에이전트 AI가 무엇을 의미 할 수 있는지Apr 18, 2025 am 11:36 AM결과? 소진, 비 효율성 및 탐지와 동작 사이의 넓은 차이. 이 중 어느 것도 사이버 보안에서 일하는 사람에게는 충격이되지 않습니다. 그러나 에이전트 AI의 약속은 잠재적 인 전환점으로 부상했다. 이 새로운 수업
 Google 대 Openai : AI 학생들을위한 AI 싸움Apr 18, 2025 am 11:31 AM
Google 대 Openai : AI 학생들을위한 AI 싸움Apr 18, 2025 am 11:31 AM장기 파트너십 대 즉각적인 영향? 2 주 전 Openai는 2025 년 5 월 말까지 미국과 캐나다 대학생들에게 Chatgpt Plus에 무료로 이용할 수있는 강력한 단기 제안으로 발전했습니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

PhpStorm 맥 버전
최신(2018.2.1) 전문 PHP 통합 개발 도구

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

SublimeText3 영어 버전
권장 사항: Win 버전, 코드 프롬프트 지원!

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

Dreamweaver Mac版
시각적 웹 개발 도구

