
비지도 학습을 위한 앙상블 방법: 유사성 행렬의 클러스터링

- PHPz앞으로
- 2023-11-13 17:53:06770검색
기계 학습에서 앙상블이라는 용어는 여러 모델을 병렬로 결합하는 것을 의미하며 군중의 지혜를 사용하여 주어진 최종 답변에 대해 더 나은 합의를 형성하는 것입니다.

지도 학습 분야에서 이 방법은 특히 RandomForest와 같은 매우 성공적인 알고리즘의 분류 문제에서 널리 연구되고 적용되었습니다. 각 개별 모델의 출력을 보다 강력하고 일관된 최종 출력으로 결합하기 위해 투표/가중치 시스템이 종종 사용됩니다.
비지도 학습의 세계에서는 이 작업이 훨씬 더 어려워집니다. 첫째, 이는 해당 분야 자체의 과제를 포함하기 때문에 우리 자신을 어떤 목표와도 비교할 수 있는 데이터에 대한 사전 지식이 없습니다. 둘째, 모든 모델의 정보를 결합하는 적절한 방법을 찾는 것이 여전히 문제이고 이를 수행하는 방법에 대한 합의가 없기 때문입니다.
이 기사에서는 이 주제에 대한 최선의 접근 방식, 즉 유사 행렬의 클러스터링에 대해 논의합니다.
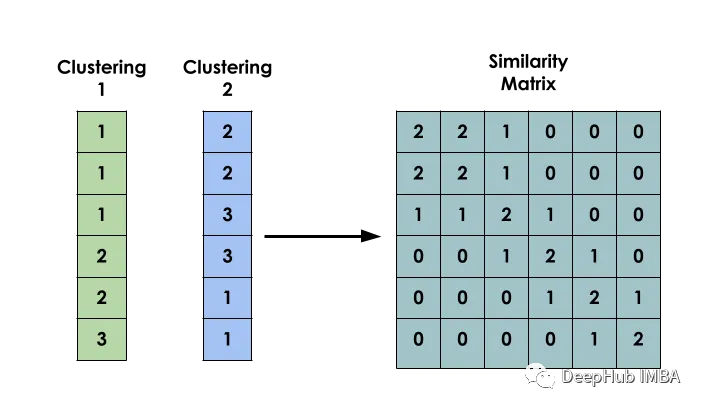
이 방법의 주요 아이디어는 데이터 세트 X가 주어지면 Si가 xi와 xj 간의 유사성을 나타내는 행렬 S를 만드는 것입니다. 이 매트릭스는 여러 모델의 클러스터링 결과를 기반으로 구성됩니다.
이진 동시 발생 행렬
입력 사이에 이진 동시 발생 행렬을 만드는 것은 모델 구축의 첫 번째 단계입니다

두 입력 i와 j가 동일한 클러스터에 속하는지 여부를 나타내는 데 사용됩니다.
import numpy as np from scipy import sparse def build_binary_matrix( clabels ): data_len = len(clabels) matrix=np.zeros((data_len,data_len))for i in range(data_len):matrix[i,:] = clabels == clabels[i]return matrix labels = np.array( [1,1,1,2,3,3,2,4] ) build_binary_matrix(labels)
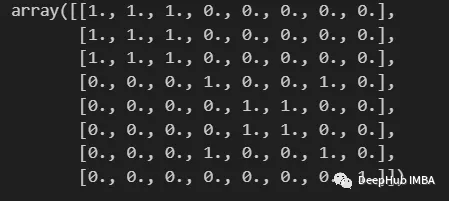
KMeans를 사용하여 유사성 행렬 구성
클러스터링을 이진화하는 함수를 구성했으며 이제 유사성 행렬을 구성하는 단계로 들어갈 수 있습니다.
여기에서는 M개의 서로 다른 모델에서 생성된 M개의 동시 발생 행렬 간의 평균값만 계산하는 일반적인 방법을 소개합니다. 우리는 이를 다음과 같이 정의합니다:

항목이 동일한 클러스터에 속하면 유사성 값은 1에 가까우며 항목이 다른 그룹에 속하면 유사성 값은 0에 가까울 것입니다
우리는 유사성을 구축합니다 K-Means 모델에 의해 생성된 레이블을 기반으로 하는 행렬입니다. MNIST 데이터 세트를 사용하여 수행되었습니다. 단순성과 효율성을 위해 PCA 축소 이미지 10,000개만 사용합니다.
from sklearn.datasets import fetch_openml from sklearn.decomposition import PCA from sklearn.cluster import MiniBatchKMeans, KMeans from sklearn.model_selection import train_test_split mnist = fetch_openml('mnist_784') X = mnist.data y = mnist.target X, _, y, _ = train_test_split(X,y, train_size=10000, stratify=y, random_state=42 ) pca = PCA(n_components=0.99) X_pca = pca.fit_transform(X)
모델 간의 다양성을 허용하기 위해 각 모델은 임의의 수의 클러스터로 인스턴스화됩니다.
NUM_MODELS = 500 MIN_N_CLUSTERS = 2 MAX_N_CLUSTERS = 300 np.random.seed(214) model_sizes = np.random.randint(MIN_N_CLUSTERS, MAX_N_CLUSTERS+1, size=NUM_MODELS) clt_models = [KMeans(n_clusters=i, n_init=4, random_state=214) for i in model_sizes] for i, model in enumerate(clt_models):print( f"Fitting - {i+1}/{NUM_MODELS}" )model.fit(X_pca)
다음 함수는 유사성 행렬을 생성하는 것입니다.
def build_similarity_matrix( models_labels ):n_runs, n_data = models_labels.shape[0], models_labels.shape[1] sim_matrix = np.zeros( (n_data, n_data) ) for i in range(n_runs):sim_matrix += build_binary_matrix( models_labels[i,:] ) sim_matrix = sim_matrix/n_runs return sim_matrix
이 함수 호출:
models_labels = np.array([ model.labels_ for model in clt_models ]) sim_matrix = build_similarity_matrix(models_labels)
최종 결과는 다음과 같습니다.
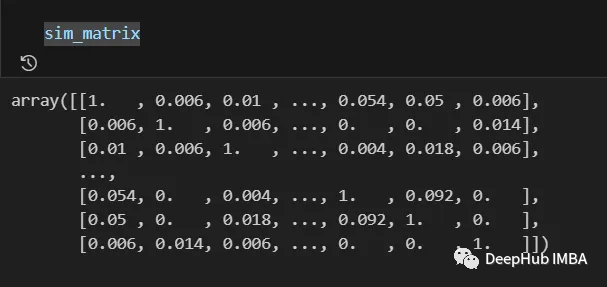
유사성 행렬의 정보는 마지막 단계 전에 여전히 후처리될 수 있습니다. , 로그, 다항식 적용과 같은 변환을 기다립니다.
우리의 경우 원래 의미를 변경하지 않고 다시 작성하겠습니다.
Pos_sim_matrix = sim_matrix
유사성 행렬 클러스터링
유사성 행렬은 모든 클러스터링 모델의 협력을 통해 구축된 지식을 표현하는 방법입니다.
이를 사용하여 동일한 클러스터에 속할 가능성이 높은 항목과 그렇지 않은 항목을 시각적으로 확인할 수 있습니다. 하지만 이 정보는 여전히 실제 클러스터로 변환되어야 합니다
이 작업은 유사성 매트릭스를 매개변수로 받을 수 있는 클러스터링 알고리즘을 사용하여 수행됩니다. 여기서는 SpectralClustering을 사용합니다.
from sklearn.cluster import SpectralClustering spec_clt = SpectralClustering(n_clusters=10, affinity='precomputed',n_init=5, random_state=214) final_labels = spec_clt.fit_predict(pos_sim_matrix)
표준 KMeans 모델과의 비교
우리 방법이 효과적인지 확인하기 위해 KMeans와 비교해 보겠습니다.
NMI, ARI, 클러스터 순도 및 클래스 순도 지표를 사용하여 표준 KMeans 모델을 평가하고 앙상블 모델과 비교할 것입니다. 또한 각 클러스터에 어떤 범주가 속하는지 시각화하기 위해 우발 행렬을 구성할 것입니다.
위의 값을 관찰하면 Ensemble 방식이 클러스터링 품질을 효과적으로 향상시킬 수 있음을 분명히 알 수 있습니다. 동시에 더 나은 분포 범주와 더 적은 "노이즈"를 통해 우발 행렬에서 보다 일관된 동작을 관찰할 수도 있습니다
위 내용은 비지도 학습을 위한 앙상블 방법: 유사성 행렬의 클러스터링의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!