
지식 추출에 대해 이야기해 볼까요?

- PHPz앞으로
- 2023-11-13 20:13:02763검색
1. 소개
지식 추출은 일반적으로 풍부한 의미 정보가 포함된 태그 및 구문과 같은 구조화되지 않은 텍스트에서 구조화된 정보를 마이닝하는 것을 의미합니다. 이는 업계에서 콘텐츠 이해, 제품 이해 등의 시나리오에서 널리 사용됩니다. 사용자가 생성한 텍스트 정보에서 가치 있는 태그를 추출하여 콘텐츠나 제품에 적용합니다.
지식 추출은 일반적으로 추출된 태그나 문구의 추출을 동반합니다. 분류는 일반적으로 명명된 엔터티 인식 작업으로 모델링됩니다. 일반적인 명명된 엔터티 구성 요소를 식별하고 구성 요소를 지명, 사람 이름, 조직 이름 등으로 분류합니다. 도메인 관련 태그 단어 추출은 태그를 식별하고 결합합니다. 시리즈(Air Force One, Sonic 9), 브랜드(Nike, Li Ning), 유형(신발, 의류, 디지털), 스타일(INS 스타일, 복고풍 스타일, 북유럽 스타일) 등 도메인 정의 카테고리로 구분합니다. 등.
설명의 편의를 위해 아래에서는 정보가 풍부한 태그나 문구를 태그 단어로 통칭하겠습니다
2. 지식 추출 분류
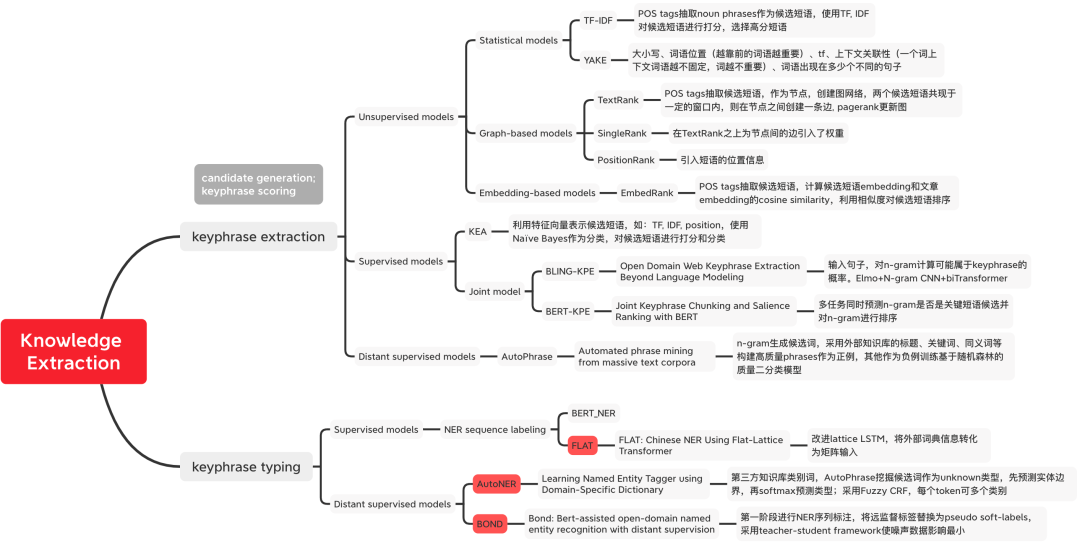 그림 1 지식 추출 방법의 분류
그림 1 지식 추출 방법의 분류
3. 태그 워드 마이닝
비지도 방법
통계 기반 방법
- TF-IDF(용어 빈도-역문서 빈도): 각 단어의 TF-IDF 점수를 계산합니다. 점수가 높을수록 포함된 정보의 양이 많아집니다.
재작성된 내용: 계산 방법: tfidf(t, d, D) = tf(t, d) * idf(t, D), 여기서 tf(t, d) = log(1 + freq(t) , d )), freq(t,d)는 현재 문서 d에 후보 단어 t가 나타나는 횟수를 나타내고, idf(t,D) = log(N/count(d∈D:t∈D))는 후보 단어 t를 나타냅니다. 얼마나 많은 문서에 나타납니까? 단어의 희귀성을 나타내는 데 사용됩니다. 단어가 하나의 문서에만 나타나는 경우 해당 단어가 드물고 특정 비즈니스 시나리오에서는 외부 도구를 사용할 수 있음을 의미합니다. 후보 단어를 분석하려면 먼저 품사 표시를 사용하여 명사를 선별하는 등의 선별 작업을 수행합니다.
YAKE[1]: 키워드 특징을 포착하기 위해 5가지 특징이 정의되며, 이를 경험적으로 결합하여 각 키워드에 점수를 할당합니다. 점수가 낮을수록 키워드가 더 중요합니다. 1) 대문자: 대문자로 된 용어(각 문장의 시작 단어 제외)는 소문자로 된 용어보다 중요하며 이는 중국어의 굵은 단어 수에 해당합니다. 2) 단어 위치: 텍스트의 각 단락 일부 단어; 3) 단어 빈도는 단어 발생 빈도를 계산합니다. 4) 단어 컨텍스트는 고정된 창 크기에 나타나는 다양한 단어의 수를 측정하는 데 사용됩니다. - 발생하면 단어의 중요성이 낮아집니다. 5) 단어가 다른 문장에 나타나는 횟수가 많을수록 더 중요합니다.Graph-Based Model
TextRank[2]: 먼저 텍스트에 대해 단어 분할 및 품사 태깅을 수행하고 중지 단어를 필터링하여 지정된 품사가 있는 단어만 남깁니다. 그래프를 구성합니다. 각 노드는 단어이고, 엣지는 단어 간의 관계를 나타내며, 이는 미리 정해진 크기의 이동 창 내에서 단어의 동시 발생을 정의하여 구성됩니다. PageRank를 사용하여 수렴할 때까지 노드 가중치를 역순으로 정렬하여 가장 중요한 k 단어를 후보 키워드로 표시하고 인접한 구문을 형성하는 경우 여러 키워드로 결합합니다. 문구에 대한 문구.Representation-Based Method Embedding-Based Model
Representation-based method는 후보 단어와 문서 간의 벡터 유사성을 계산하여 후보 단어의 순위를 매깁니다.
감독 방법
- 첫 번째 후보 단어 선별 후 태그 단어 분류 사용: 고전 모델 KEA[5]는 Naive Bayes를 분류자로 사용하여 네 가지 설계 특징을 사용하여 N-gram 후보 단어를 점수화합니다.
- 후보 단어 선별 및 태그 단어 인식의 공동 훈련: BLING-KPE[6]는 원본 문장을 입력으로 취하고 CNN과 Transformer를 사용하여 문장의 N-gram 구문을 인코딩하고 해당 구문이 다음과 같을 확률을 계산합니다. 태그 단어, 레이블 단어인지 여부는 수동으로 레이블이 지정됩니다. BERT-KPE[7] BLING-KPE 아이디어를 기반으로 문장의 벡터를 더 잘 표현하기 위해 ELMO를 BERT로 대체합니다.
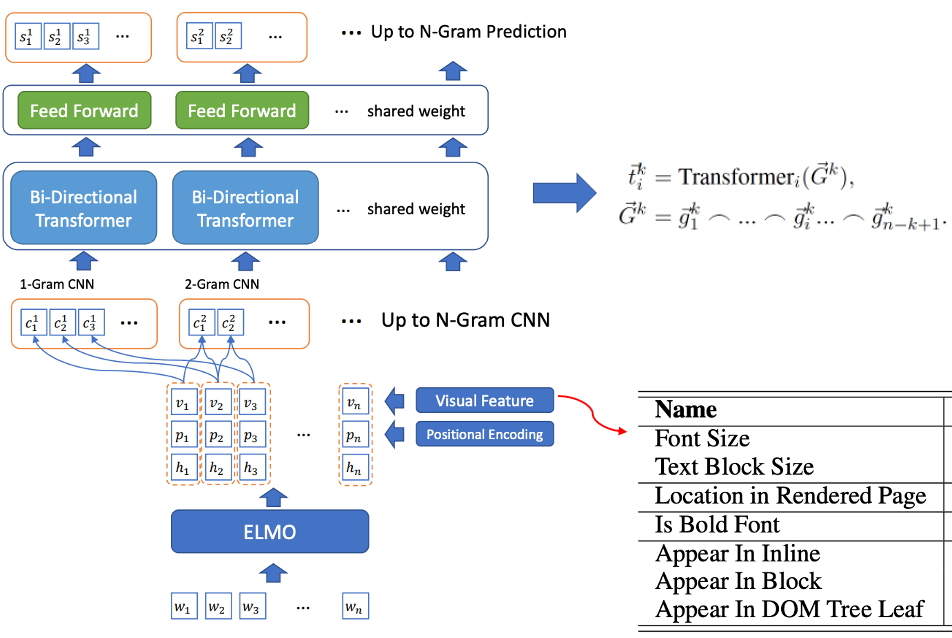 그림 2 BLING-KPE 모델 구조
그림 2 BLING-KPE 모델 구조
원격 감시 방법
AutoPhrase
이 기사에서는 다음 네 가지 조건이 동시에 충족되는 단어를 고품질 문구로 정의합니다.
- 인기: 문서에서 발생 빈도가 충분히 높습니다.
- 일치: 토큰 배열이 나타남 교체 후 다른 배열보다 빈도가 훨씬 높습니다. 즉, 공동 발생 빈도가
- 정보성: "이것은"과 같이 정보가 풍부하고 명확하게 표시됩니다. 정보가 없는 부정적인 예입니다. : 구문과 해당 하위 문자 구문은 완전해야 합니다.
- AutoPhrase 태그 마이닝 프로세스는 그림 3에 나와 있습니다. 먼저, 품사 태깅을 사용하여 빈도가 높은 N-gram 단어를 후보로 선별합니다. 그런 다음 원격 감독을 통해 후보 단어를 분류합니다. 마지막으로 위의 4가지 조건을 이용하여 고품질 문구를 필터링합니다(문구 품질 재평가)
그림 3 AutoPhrase 태그 마이닝 프로세스 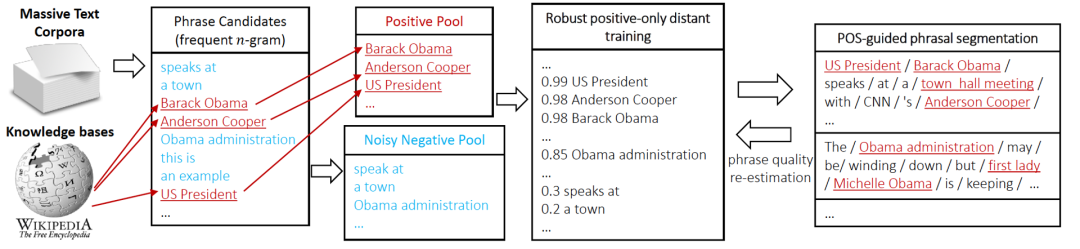 Positive Pool로 외부 지식 베이스에서 고품질 문구를 획득하고, Negative Pool로 다른 문구 예를 들어 논문의 실험 통계에 따르면 Negative example pool에는 10%의 고품질 문구가 있는데, 이는 지식 베이스에서 부정적인 예시로 분류되지 않기 때문입니다. 분류의 영향을 줄이기 위해 그림 4와 같은 랜덤 포레스트 앙상블 분류기를 사용합니다. 산업 응용 분야에서 분류기 훈련은 사전 훈련 모델 BERT [13]를 기반으로 하는 문장 간 관계 작업의 2분류 방법을 사용할 수도 있습니다.
Positive Pool로 외부 지식 베이스에서 고품질 문구를 획득하고, Negative Pool로 다른 문구 예를 들어 논문의 실험 통계에 따르면 Negative example pool에는 10%의 고품질 문구가 있는데, 이는 지식 베이스에서 부정적인 예시로 분류되지 않기 때문입니다. 분류의 영향을 줄이기 위해 그림 4와 같은 랜덤 포레스트 앙상블 분류기를 사용합니다. 산업 응용 분야에서 분류기 훈련은 사전 훈련 모델 BERT [13]를 기반으로 하는 문장 간 관계 작업의 2분류 방법을 사용할 수도 있습니다.
그림 4 AutoPhrase 태그 단어 분류 방법 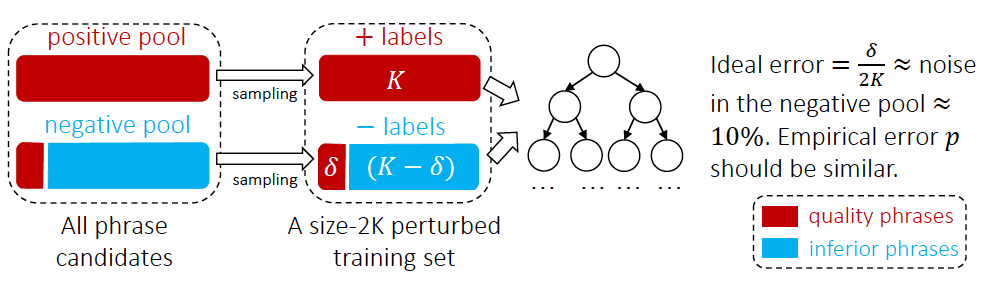 IV. 태그 단어 분류
IV. 태그 단어 분류
감독 방법
NER 시퀀스 주석 모델
Lattice LSTM[8]은 중국어 NER 작업을 위한 어휘 정보를 최초로 도입한 작업입니다. Lattice는 어휘 정보(사전)를 통해 문장을 일치시킬 때 어휘의 시작 문자와 끝 문자가 그리드 위치를 결정합니다. , 그림 5(a)와 같이 격자형 구조를 얻을 수 있습니다. Lattice LSTM 구조는 5(b)에 표시된 대로 어휘 정보를 기본 LSTM에 융합합니다. 예를 들어 "store"는 "people and drug store"를 융합합니다. "약국" 정보. 각 문자에 대해 Lattice LSTM은 어텐션 메커니즘을 사용하여 다양한 수의 단어 단위를 융합합니다. Lattice-LSTM은 NER 작업의 성능을 효과적으로 향상시키지만 RNN 구조는 장거리 종속성을 캡처할 수 없으며 동시에 동적 Lattice 구조는 GPU 병렬성을 완전히 수행할 수 없습니다. 이 두 가지 질문을 효과적으로 개선했습니다. 그림 5(c)와 같이 Flat 모델은 Transformer 구조를 통해 장거리 종속성을 포착하고 Lattice 구조를 통합하기 위해 Position Encoding을 설계한 후 문자와 일치하는 단어를 문장으로 이어붙인 후 각각의 문자와 단어를 Construct 2로 한다. 헤드 위치 인코딩 및 테일 위치 인코딩은 방향성 비순환 그래프에서 평평한 평면 격자 변환기 구조로 격자 구조를 평면화합니다.
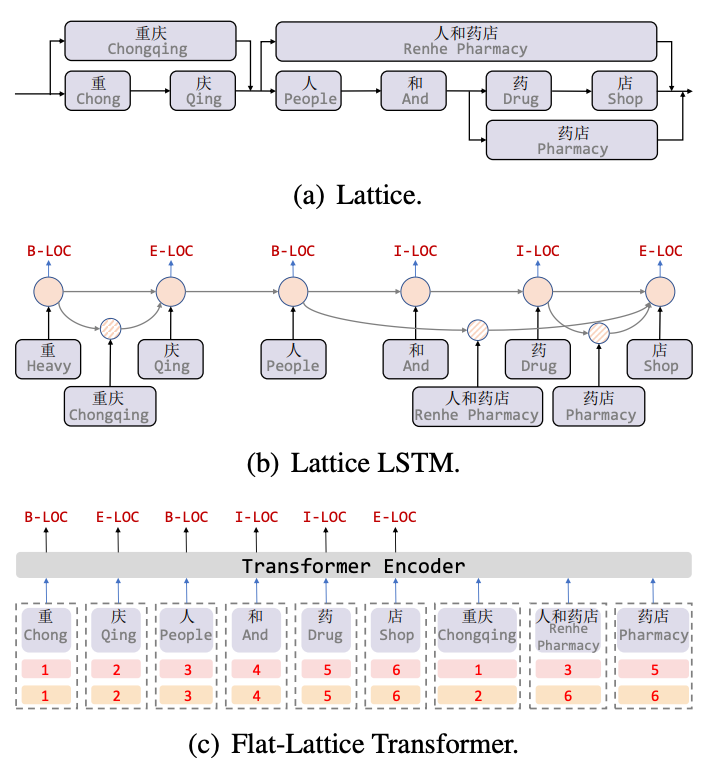 그림 5 어휘 정보를 도입한 NER 모델
그림 5 어휘 정보를 도입한 NER 모델
Far-supervised 방법
AutoNER
원격 감시 시 소음 문제를 해결하기 위해 BIOE 라벨링 방법을 대체하기 위해 Tie or Break의 개체 경계 식별 체계를 사용합니다. 그 중 Tie는 현재 단어와 이전 단어가 같은 엔터티에 속한다는 뜻이고, Break는 현재 단어와 이전 단어가 더 이상 같은 엔터티에 속하지 않는다는 뜻이다. 엔터티 분류 단계에서는 Fuzzy CRF를 사용해 처리한다.
그림 6 AutoNER 모델 구조 다이어그램 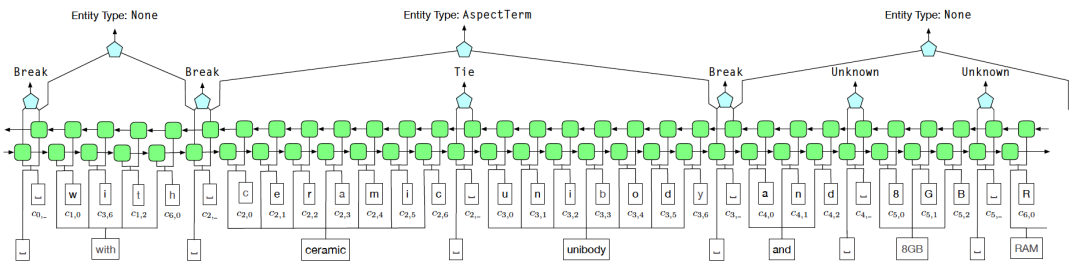
BOND
BOND[12]는 원격 감독 학습을 기반으로 하는 2단계 엔터티 인식 모델입니다. 첫 번째 단계에서는 장거리 레이블을 사용하여 사전 훈련된 언어 모델을 NER 작업에 적용합니다. 두 번째 단계에서는 학생 모델과 교사 모델이 먼저 1단계에서 훈련된 모델로 초기화된 다음 의사 - Teacher 모델에서 생성된 레이블은 Student 모델을 쌍으로 사용하는 데 사용됩니다. 원격 감독으로 인해 발생하는 소음 문제의 영향을 최소화하기 위한 교육을 수행합니다.
Pictures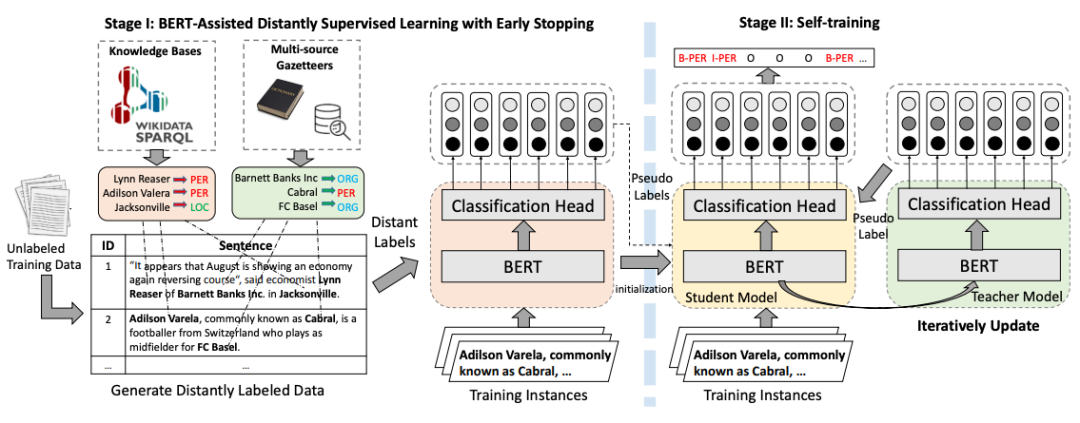 다시 작성해야 하는 내용은 다음과 같습니다. 그림 7 BOND 훈련 흐름도
다시 작성해야 하는 내용은 다음과 같습니다. 그림 7 BOND 훈련 흐름도
V. 요약
이 기사에서는 태그 단어 마이닝과 태그 단어의 두 가지 관점에서 지식 추출의 고전적인 방법을 소개합니다. 수동으로 주석을 단 데이터에 의존하는 비지도 및 원격 감독의 고전적인 방법인 TF-IDF 및 TextRank, 업계에서 널리 사용되는 AutoPhrase, AutoNER 등을 포함한 분류는 업계의 콘텐츠 이해, 사전 구성 및 쿼리 이해를 위한 NER.
【1】Campos R, MANGAravite V, Pasquali A, et al. Yake! 수집 독립적 자동 키워드 추출기[C]//정보 검색의 발전: 40차 IR 연구에 대한 유럽 회의, ECIR 2018, 프랑스 그르노블, 2018년 3월 26~29일, Proceedings 40. Springer International Publishing, 2018: https://github.com/LIAAD/yake
【2】Mihalcea R, Tarau P. Textrank: 텍스트로 정리하기[C]//자연어 처리의 경험적 방법에 관한 2004년 컨퍼런스 진행 2004: 404-411.
【3】Bennani-Smires K, Musat C, Hossmann A, et al. 문장 임베딩을 사용한 간단한 비지도 키 구문 추출[J] 】Witten I H, Paynter GW, Frank E, et al. KEA: Practical automatic keyphrase extract[C]//Proceedings of the third ACM conference on Digital library 1999: 254-255.
번역 내용:【6】Xiong L. , Hu C, Xiong C, 외. 언어 모델을 뛰어넘는 오픈 도메인 웹 키워드 추출[J]. arXiv preprint arXiv:1911.02671, 2019
【7】Sun, S., Xiong, C., Liu, Z., Liu, Z., & Bao, J. (2020) BERT를 사용한 공동 키프레이즈 청킹 및 현저성 순위. arXiv preprint arXiv:2004.13639.
다시 작성해야 하는 내용은 다음과 같습니다. [8] Zhang Y, Yang J. 격자 LSTM[C]를 사용한 중국어 명명 개체 인식. ACL 2018
【9】Li X, Yan H, Qiu X, et al. FLAT: 평면 격자 변압기를 사용하는 중국 NER[C] ACL 2020.
【10】Shang J, Liu J, Jiang M, et al. 대규모 텍스트 말뭉치의 자동 구문 마이닝[J] 지식 및 데이터 엔지니어링에 관한 IEEE 거래, 2018, 30(10): 1825-1837.
【11】 Shang J, Liu L, Ren X, et al. . 도메인별 사전을 사용하여 명명된 엔터티 태거 학습[C].
【12]Liang C, Yu Y, Jiang H, et al. Bond: 원격 감독을 통한 Bert 지원 개방형 도메인 명명된 엔터티 인식[ C] //지식 발견 및 데이터 마이닝에 관한 제26회 ACM SIGKDD 국제 컨퍼런스 진행. 2020: 1054-1064.
【13】Meituan 검색에서 NER 기술 탐색 및 실습, https://zhuanlan.zhihu.com/ p /163256192
위 내용은 지식 추출에 대해 이야기해 볼까요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!