
GPU가 Llama 2와 같은 대규모 모델을 실행할 수 있습니까? 이 오픈소스 프로젝트를 사용해 보세요

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-10-23 14:29:011532검색
컴퓨팅 성능이 왕인 시대에 GPU가 대형 모델(LLM)을 원활하게 실행할 수 있을까요?
많은 사람들이 이 질문에 대한 정확한 답을 내리는데 어려움을 겪고 있고 GPU 메모리를 계산하는 방법을 모릅니다. GPU가 처리할 수 있는 LLM을 확인하는 것은 모델 크기를 확인하는 것만큼 쉽지 않기 때문에 모델은 추론 중에 많은 메모리(KV 캐시)를 차지할 수 있습니다. 예를 들어 llama-2-7b의 시퀀스 길이는 1000이고 1GB의 메모리가 필요합니다. 추가 메모리. 뿐만 아니라 모델 훈련 중에 KV 캐시, 활성화 및 양자화는 많은 메모리를 차지합니다.
위의 메모리 사용량을 미리 알 수 있는지 궁금하지 않을 수 없습니다. 최근에는 LLM 학습 또는 추론 중에 필요한 GPU 메모리 양을 계산하는 데 도움이 되는 새로운 프로젝트가 GitHub에 등장했습니다. 뿐만 아니라 이 프로젝트의 도움으로 자세한 메모리 분포 및 평가도 알 수 있습니다. 방법, 양자화 방법, 처리되는 최대 컨텍스트 길이 및 기타 문제를 해결하여 사용자가 자신에게 적합한 GPU 구성을 선택할 수 있도록 도와줍니다.
프로젝트 주소: https://github.com/RahulSChand/gpu_poor
이 프로젝트는 또한 대화형이며 아래와 같이 LLM을 실행하는 데 필요한 GPU 메모리를 계산할 수 있습니다. 빈칸을 채우는 것만큼 간단합니다. 사용자는 필요한 몇 가지 매개변수만 입력하고 마지막으로 파란색 버튼을 클릭하면 답이 나옵니다.
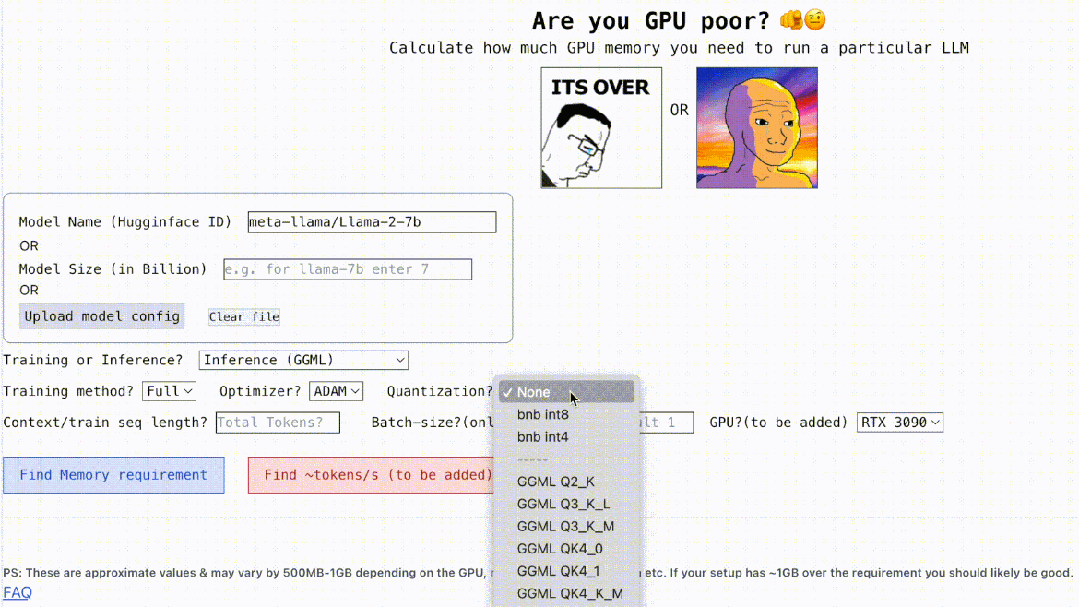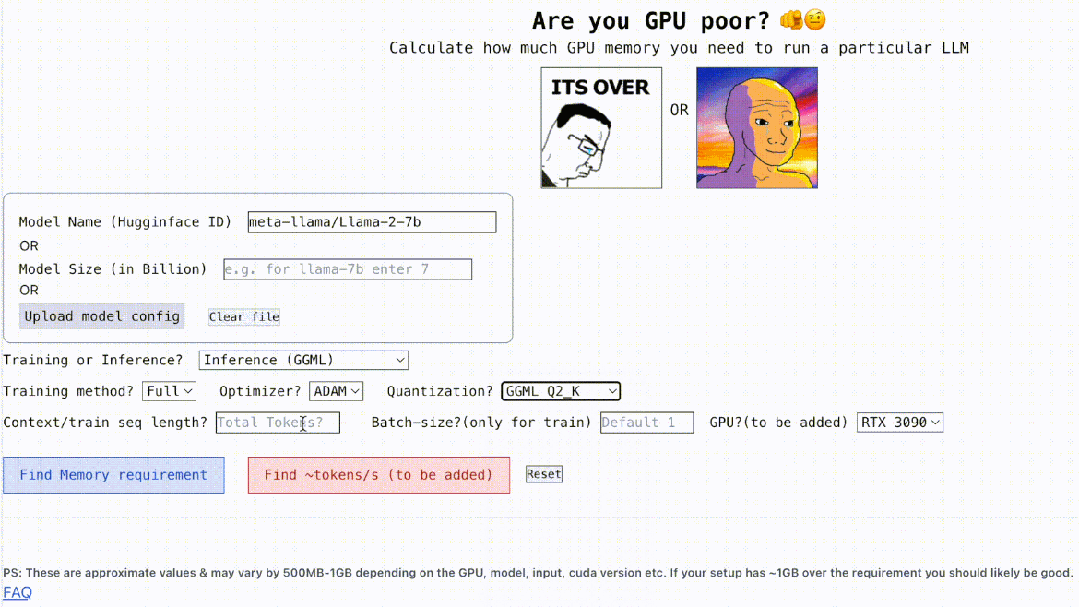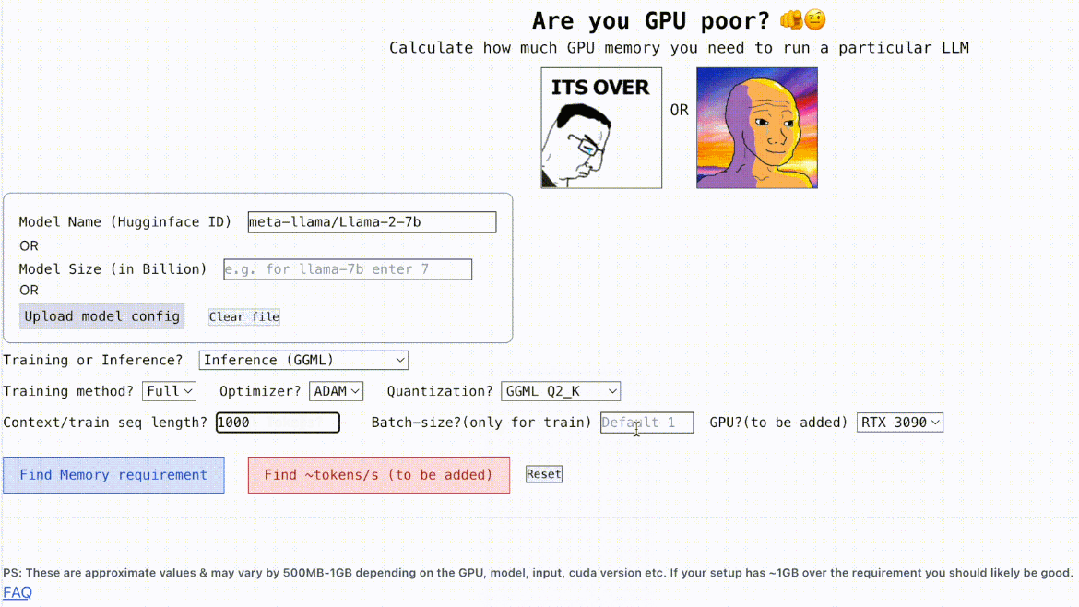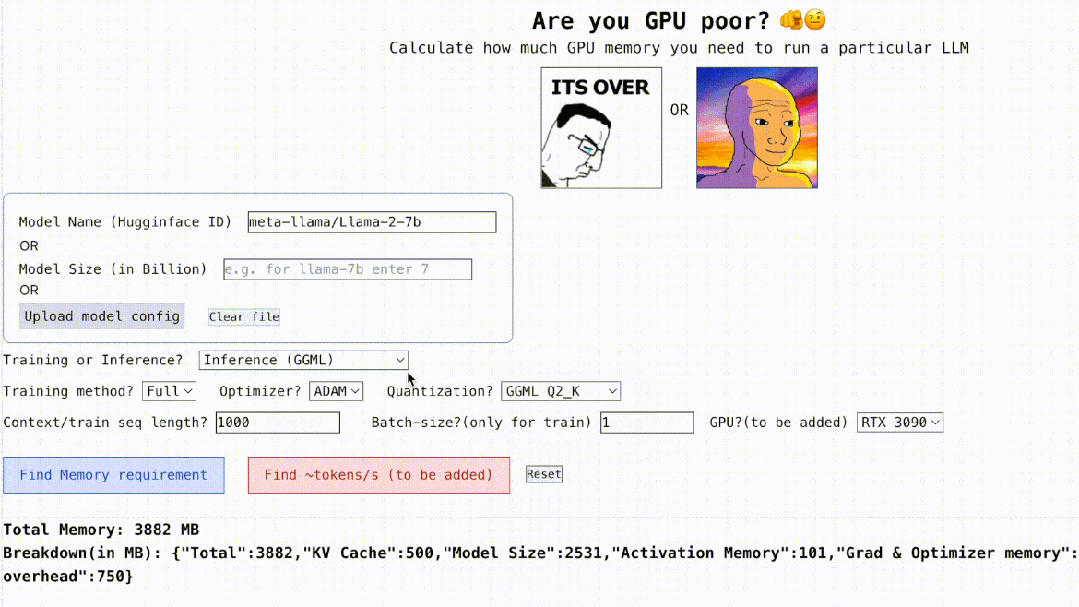
Interactive 주소: https://rahulschand.github.io/gpu_poor/
최종 출력 형식은 다음과 같습니다.
{"Total": 4000,"KV Cache": 1000,"Model Size": 2000,"Activation Memory": 500,"Grad & Optimizer memory": 0,"cuda + other overhead":500}
우리가 이 프로젝트를 하려는 이유는 저자 Rahul Shiv Chand는 다음과 같은 이유가 있다고 말했습니다.
- GPU에서 LLM을 실행할 때 모델을 조정하는 데 사용해야 하는 양자화 방법은 무엇입니까?
- GPU가 처리할 수 있는 최대 컨텍스트 길이는 얼마입니까? 어떤 미세 조정 방법이 귀하에게 더 적합합니까? LoRA? 아니면 QLoRA?
- 미세 조정 중에 사용할 수 있는 최대 배치는 무엇입니까?
- 어떤 작업이 GPU 메모리를 소비하고 LLM이 GPU에 적응할 수 있도록 조정합니까?
첫 번째 단계는 모델명, ID, 모델 사이즈를 처리하는 것입니다. Huggingface에 모델 ID(예: metal-llama/Llama-2-7b)를 입력할 수 있습니다. 현재 이 프로젝트에는 Huggingface에서 가장 많이 다운로드된 상위 3000개의 LLM에 대한 모델 구성이 하드코딩되어 저장되어 있습니다.
맞춤 모델을 사용하거나 Hugginface ID를 사용할 수 없는 경우 json 구성을 업로드하거나(프로젝트 예시 참조) 모델 크기만 입력해야 합니다(예: llama-2-7b는 70억입니다) ).
그리고 양자화가 옵니다. 현재 프로젝트는 bitandbytes(bnb) int8/int4 및 GGML(QK_8, QK_6, QK_5, QK_4, QK_2)을 지원합니다. 후자는 추론에만 사용되는 반면 bnb int8/int4는 훈련과 추론에 모두 사용될 수 있습니다.
마지막 단계는 추론 및 학습입니다. 추론 프로세스 중에 HuggingFace 구현을 사용하거나 vLLM 또는 GGML 방법을 사용하여 학습 프로세스 중에 추론에 사용되는 vRAM을 찾고, 전체 모델 미세 조정 또는 사용을 위해 vRAM을 찾습니다. LoRA(현재 프로젝트는 r=8로 하드코딩된 LoRA 구성), 미세 조정을 위한 QLoRA입니다.
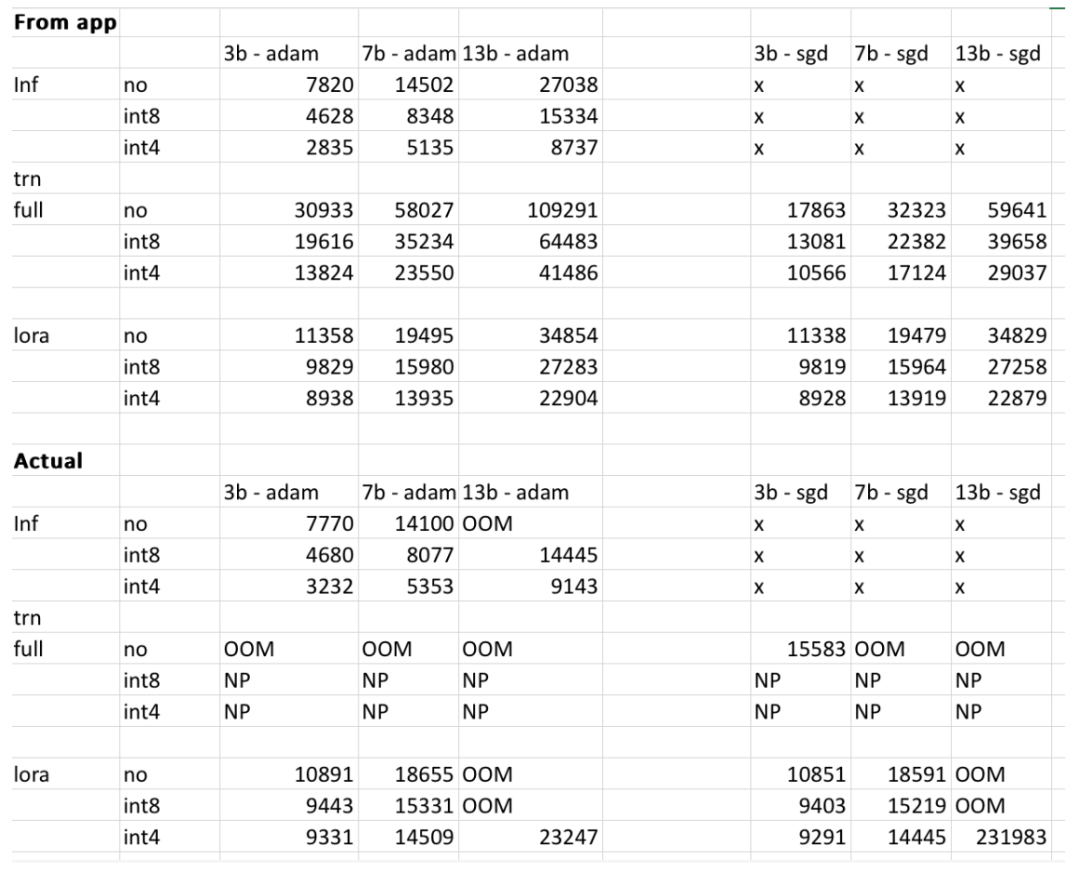
그러나 프로젝트 작성자는 사용자 모델, 입력 데이터, CUDA 버전, 수량화 도구 등에 따라 최종 결과가 달라질 수 있다고 밝혔습니다. 실험에서 저자는 이러한 요소들을 고려하여 최종 결과가 500MB 이내가 되도록 노력했습니다. 아래 표는 저자가 RTX 4090, 2060 GPU에서 얻은 메모리 사용량과 웹사이트에서 제공하는 3b, 7b, 13b 모델의 메모리 사용량을 비교 확인한 표입니다. 모든 값은 500MB 이내입니다.
위 내용은 GPU가 Llama 2와 같은 대규모 모델을 실행할 수 있습니까? 이 오픈소스 프로젝트를 사용해 보세요의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!