




현재 자율주행차에는 라이더, 밀리미터파 레이더, 카메라 센서 등 다양한 정보 수집 센서가 탑재되어 있습니다. 현재의 관점에서 볼 때, 자율주행의 인식 작업에서 다양한 센서가 큰 발전 가능성을 보여주었습니다. 예를 들어, 카메라를 통해 수집된 2D 이미지 정보는 풍부한 의미론적 특징을 포착하고, LiDAR가 수집한 포인트 클라우드 데이터는 인식 모델에 객체의 정확한 위치 정보와 기하학적 정보를 제공할 수 있습니다. 다양한 센서에서 얻은 정보를 최대한 활용함으로써 자율주행 인지 과정에서 불확실성 요인의 발생을 줄이는 동시에 인지 모델의 감지 견고성을 향상시킬 수 있습니다. 오늘은 Megvii의 자율주행 인지 논문을 소개합니다. 올해 ICCV2023 Visual Conference에 채택되었습니다. 이 기사의 주요 특징은 PETR과 유사한 End-to-End BEV 인식 알고리즘입니다(인식 결과에서 중복 상자를 필터링하기 위해 더 이상 NMS 후처리 작업을 사용할 필요가 없습니다). ) 동시에 모델의 인식 성능을 향상시키기 위해 LiDAR의 포인트 클라우드 정보가 추가로 사용됩니다. 기사 및 공식 오픈 소스 창고에 대한 링크는 매우 좋습니다. 링크는 다음과 같습니다:
논문 링크: https:/ /arxiv.org/pdf/2301.01283.pdf- 코드 링크: https://github.com/junjie18/CMT
다음으로 CMT 인식 모델의 네트워크 구조에 대해 논의하겠습니다. 아래 그림과 같이 전반적인 소개:
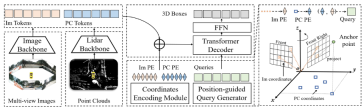 전체 알고리즘 블록 다이어그램에서 볼 수 있듯이 전체 알고리즘 모델에는 주로 다음이 포함됩니다. 세 부분
전체 알고리즘 블록 다이어그램에서 볼 수 있듯이 전체 알고리즘 모델에는 주로 다음이 포함됩니다. 세 부분
- 및 이미지 토큰
- 을 얻을 수 있습니다( Im Tokens)**위치 코딩 생성: 다양한 센서에서 수집된 데이터 정보에 대해 Im Tokens
- 해당 좌표 위치 코드 생성 Im PE, PC Tokens 해당 좌표 위치 코드 PC PE 생성 , 및 Object Queries는 해당 좌표 위치 코드Query EmbeddingTransformer Decoder+FFN 네트워크도 생성합니다. 입력은 Object Queries
- + Query Embedding이고 위치 인코딩된 Im 토큰 및 PC 토큰입니다. 교차 어텐션 계산에 사용되며 FFN은 최종 3D 상자 + 카테고리 예측 생성에 사용됩니다. 네트워크 자세히 소개 전체 구조가 끝난 후 위에서 언급한 세 가지 하위 부분을 자세히 소개합니다
Lidar 백본 네트워크 + 카메라 백본 네트워크 (이미지 백본 + Lidar 백본)
Lidar 백본 네트워크- 일반적으로 사용되는 Lidar 백본 네트워크 추출 포인트 클라우드 데이터 기능에는 다음 5가지 부분이 포함됩니다
- Voxel 기능 인코딩
- 3D Backbone(일반적으로 VoxelResBackBone8x 네트워크에서 사용)은 voxel feature 인코딩 결과에서 3D 특징을 추출
- 3D Backbone은 특징의 Z축을 추출하고 압축하여 BEV 공간의 특징을 얻음
- 2D Backbone을 사용하여 수행 BEV 공간에 투영된 기능에 맞는 추가 기능
- 2D 백본에서 출력되는 기능 맵의 채널 수가 이미지 출력과 다르기 때문에 채널 수가 일치하지 않으며 컨볼루션 레이어를 사용하여 번호를 정렬합니다. (본 글의 모델은 채널 개수 정렬이 이루어졌으나 원래의 포인트 클라우드 정보 추출 범주에 속하지 않습니다.)
- 일반적으로 추출에 사용되는 카메라 백본 네트워크 2D 이미지 기능에는 다음 두 부분이 포함됩니다.
- 출력: 16x 및 32x 다운샘플링 이미지 기능을 융합하여 16번 다운샘플링된 기능 맵을 얻습니다
Tensor([bs * N, 1024, H / 16, W / 16])Tensor([bs * N,2048,H / 16,W / 16])-
需要重新写的内容是:张量([bs * N,256,H / 16,W / 16])텐서([bs *N, 2048, H/16, W/16]) -
다시 작성해야 하는 콘텐츠는 다음과 같습니다: 텐서([bs * N, 256, H/16, W/16]) - 다시 작성된 콘텐츠: ResNet-50 네트워크를 사용하여 서라운드 이미지의 특징 추출🎜🎜🎜🎜출력: 16배 및 32배로 다운샘플링된 출력 이미지 특징🎜
입력 텐서:
텐서([bs * N, 3, H, W])Tensor([bs * N,3,H,W])输出张量:
Tensor([bs * N,1024,H / 16,W / 16])输出张量:``Tensor([bs * N,2048,H / 32,W / 32])`
需要进行改写的内容是:2D骨架提取图像特征
Neck(CEFPN)
텐서([bs * N, 1024, H / 16, W / 16])位置编码的生成
根据以上介绍,位置编码的生成主要包括三个部分,分别是图像位置嵌入、点云位置嵌入和查询嵌入。下面将逐一介绍它们的生成过程
- Image Position Embedding(Im PE)
Image Position Embedding的生成过程与PETR中图像位置编码的生成逻辑是一样的(具体可以参考PETR论文原文,这里不做过多的阐述),可以总结为以下四个步骤:
- 在图像坐标系下生成3D图像视锥点云
- 3D图像视锥点云利用相机内参矩阵变换到相机坐标系下得到3D相机坐标点
- 相机坐标系下的3D点利用cam2ego坐标变换矩阵转换到BEV坐标系下
- 将转换后的BEV 3D 坐标利用MLP层进行位置编码得到最终的图像位置编码
- Point Cloud Position Embedding(PC PE)
Point Cloud Position Embedding的生成过程可以分为以下两个步骤 -
在BEV空间的网格坐标点利用
pos2embed()
출력 텐서:텐서([bs * N, 1024, H/16, W/ 16] )
출력 텐서: ``Tensor([bs * N, 2048, H/32, W/32])` -
다시 작성해야 하는 내용은 다음과 같습니다: 2D 뼈대 추출 이미지 기능
Neck (CEFPN)
위치 코드 생성
위 소개에 따르면 위치 코드 생성은 주로 이미지 위치 임베딩과 포인트 클라우드의 세 부분으로 구성됩니다. 위치 임베딩과 쿼리 임베딩. 다음은 생성 과정을 하나씩 소개합니다Image Position Embedding(Im PE)Image Position Embedding의 생성 과정은 PETR의 이미지 위치 인코딩 생성 로직과 동일합니다(자세한 내용은 다음을 참조하세요). 여기서는 다루지 않을 원본 PETR 논문 너무 많은 노력이 필요함) 다음 네 단계로 요약할 수 있습니다.
다음에서 3D 이미지 절두체 점 구름 생성 이미지 좌표계
3D 이미지 절두체 포인트 클라우드 카메라 내부 매개변수 매트릭스를 사용하여 카메라 좌표계로 변환하여 3D 카메라 좌표계를 얻습니다.
카메라 좌표계의 3D 포인트는 다음을 사용하여 BEV 좌표계로 변환됩니다. cam2ego 좌표 변환 행렬
- Point Cloud Position Embedding(PC PE)
Point Cloud 생성 과정 Position Embedding은 다음 두 단계로 나눌 수 있습니다
BEV 공간의 그리드 좌표점 활용
차원 수평 및 수직 좌표 지점을 고차원 특징 공간으로 지정합니다pos2embed()# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
-
공간 변환을 위해 MLP(다층 퍼셉트론) 네트워크를 사용하여 채널 번호 정렬을 보장합니다
🎜쿼리 임베딩🎜🎜🎜🎜객체 쿼리, 이미지 토큰 및 Lidar 토큰 간의 계산을 유사하게 하려면 Lidar 및 카메라의 논리를 사용하여 특히 쿼리 임베딩을 생성합니다. = 이미지 위치 임베딩(아래 rv_query_embeds와 동일) + 포인트 클라우드 위치 임베딩(아래 bev_query_embeds와 동일) 🎜🎜🎜🎜🎜🎜🎜🎜bev_query_embeds 생성 로직🎜🎜🎜🎜논문의 Object Query는 원래 BEV 공간에서 초기화되므로 Point Cloud Position Embedding 생성 로직의 위치 인코딩 및 bev_embedding() 함수를 직접 재사용합니다. 예, 해당 키 코드는 다음과 같습니다. 🎜def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
🎜🎜🎜🎜🎜🎜🎜rv_query_embeds 생성 로직을 다시 작성해야 합니다🎜🎜🎜🎜앞서 언급한 내용에서 Object Query는 BEV 좌표계의 초기 지점입니다. 이미지 위치 임베딩의 생성 프로세스를 따르려면 먼저 BEV 좌표계의 3D 공간 점을 이미지 좌표계에 투영한 다음 이전 세대의 이미지 위치 임베딩 처리 논리를 사용하여 다음을 보장해야 합니다. 생성 프로세스의 논리는 동일합니다. 핵심 코드는 다음과 같습니다. 🎜def _rv_query_embed(self, ref_points, img_metas):pad_h, pad_w = pad_shape# 由归一化坐标点映射回正常的roi range下的3D坐标点ref_points = ref_points * (pc_range[3:] - pc_range[:3]) + pc_range[:3]points = torch.cat([ref_points, ref_points.shape[:-1]], dim=-1)points = bda_mat.inverse().matmul(points)points = points.unsqueeze(1)points = sensor2ego_mats.inverse().matmul(points)points =intrin_mats.matmul(points)proj_points_clone = points.clone() # 选择有效的投影点z_mask = proj_points_clone[..., 2:3, :].detach() > 0proj_points_clone[..., :3, :] = points[..., :3, :] / (points[..., 2:3, :].detach() + z_mask * 1e-6 - (~z_mask) * 1e-6)proj_points_clone = ida_mats.matmul(proj_points_clone)proj_points_clone = proj_points_clone.squeeze(-1)mask = ((proj_points_clone[..., 0] = 0)& (proj_points_clone[..., 1] = 0))mask &= z_mask.view(*mask.shape)coords_d = (1 + torch.arange(depth_num).float() * (pc_range[4] - 1) / depth_num)projback_points = (ida_mats.inverse().matmul(proj_points_clone))projback_points = torch.einsum("bvnc, d -> bvndc", projback_points, coords_d)projback_points = torch.cat([projback_points[..., :3], projback_points.shape[:-1]], dim=-1)projback_points = (sensor2ego_mats.matmul(intrin_mats).matmul(projback_points))projback_points = (bda_mat@ projback_points)projback_points = (projback_points[..., :3] - pc_range[:3]) / (pc_range[3:] - self.pc_range[:3])rv_embeds = self.rv_embedding(projback_points)rv_embeds = (rv_embeds * mask).sum(dim=1)return rv_embeds🎜위 변환을 통해 BEV 공간 좌표계의 점을 먼저 이미지 좌표계에 투영한 후 Image Position Embedding 생성을 위한 처리 로직을 사용하여 rv_query_embeds를 생성하는 과정이 완료됩니다. . 🎜🎜마지막 쿼리 임베딩 = rv_query_embeds + bev_query_embeds🎜🎜🎜🎜
Transformer Decoder+FFN 네트워크
- Transformer Decoder
여기의 계산 로직은 Transformer의 Decoder와 완전히 동일하지만 입력 데이터가 약간 다릅니다
- 첫 번째 요점은 메모리입니다. 여기서 메모리는 이미지입니다. 토큰 Lidar 토큰과 연결한 후의 결과(두 가지 양식의 융합으로 이해될 수 있음
- 두 번째 요점은 위치 인코딩입니다. 여기서 위치 인코딩은 rv_query_embeds와 bev_query_embeds 사이의 연결 결과이며, query_embed는 rv_query_embeds + bev_query_embeds입니다.
- FFN 네트워크
이 FFN 네트워크의 기능은 PETR의 기능과 정확히 동일합니다. 여기서는 너무 자세히 설명하지 않겠습니다. 논문의 실험 결과
먼저 CMT와 다른 자율주행 인식 알고리즘의 비교 실험이 나왔습니다. 논문의 저자는 nuScenes의 테스트 세트와 Val 세트를 비교했습니다.
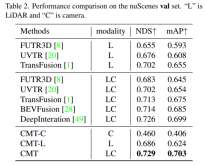
nuScenes 테스트 세트에 대한 각 인식 알고리즘의 인식 결과 비교표에서 Modality는 인식 알고리즘에 입력되는 센서 카테고리를 나타내고, C는 카메라 센서를 나타내며, 모델은 카메라 데이터만 공급합니다. LC는 LiDAR와 카메라 센서를 나타내며 모델은 여러 개의 Modal 데이터를 입력합니다. CMT-C 모델의 성능이 더 높다는 것을 알 수 있습니다. BEVDet 및 DETR3D 모델의 성능은 CenterPoint 및 UVTR과 같은 순수 LiDAR 인식 알고리즘 모델보다 높습니다. LiDAR 포인트 클라우드 데이터 및 카메라 데이터를 사용한 후 기존의 모든 단일 모달 방법을 능가하고 SOTA 결과를 얻었습니다. .nuScenes의 Val 세트에 대한 모델의 인식 결과 비교
실험 결과를 통해 LiDAR 포인트 클라우드 데이터와 카메라 데이터를 동시에 사용할 때 CMT-L의 인식 모델의 성능이 뛰어남을 알 수 있습니다. CMT는 FUTR3D, UVTR, TransFusion 및 BEVFusion과 같은 다중 모드 알고리즘과 같은 기존 다중 모드 인식 알고리즘을 크게 능가하여 값 세트에서 SOTA 결과를 달성했습니다 다음은 CMT 혁신의 절제 실험 부분입니다 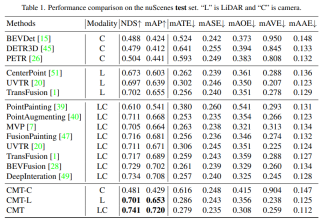
-
먼저 위치 인코딩 사용 여부를 결정하기 위해 일련의 절제 실험을 수행했습니다. 실험 결과를 통해 이미지와 LiDAR의 위치 인코딩을 동시에 사용할 경우 NDS 및 mAP 지표가 달성되는 것으로 나타났습니다. 다음으로, 절제 실험의 (c)와 (c)에서는 포인트 클라우드 백본 네트워크의 다양한 유형과 복셀 크기를 실험했습니다. (d)와 (e) 부분의 절제 실험에서 우리는 카메라 백본 네트워크의 유형과 입력 해상도의 크기에 대해 서로 다른 시도를 했습니다. 위 내용은 실험 내용에 대한 간략한 요약일 뿐입니다. 더 자세한 절제 실험을 알고 싶다면 원본 기사를 참조하세요
요약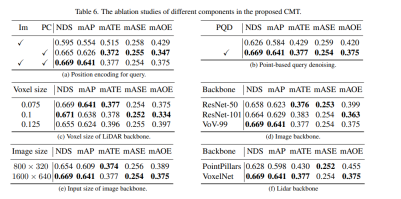
현재 모델의 지각 성능을 향상시키기 위해 다양한 양식을 융합하는 것이 인기 있는 연구 방향이 되었습니다(특히 다양한 센서가 장착된 자율주행차에서). 한편, CMT는 추가적인 후처리 단계가 필요하지 않고 nuScenes 데이터세트에서 최첨단 정확도를 달성하는 완전한 엔드투엔드 인식 알고리즘입니다. 이 글은 이 글을 자세히 소개한 글인데, 모두에게 도움이 되었으면 좋겠습니다
다시 작성해야 할 내용은 다음과 같습니다. 원문 링크: https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
위 내용은 크로스 모달 변환기: 빠르고 강력한 3D 물체 감지용의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 Huggingface Smollm으로 개인 AI 조수를 만드는 방법Apr 18, 2025 am 11:52 AM
Huggingface Smollm으로 개인 AI 조수를 만드는 방법Apr 18, 2025 am 11:52 AMON-DEVICE AI의 힘을 활용 : 개인 챗봇 CLI 구축 최근에 개인 AI 조수의 개념은 공상 과학처럼 보였다. 기술 애호가 인 Alex, 똑똑하고 현지 AI 동반자를 꿈꾸는 것을 상상해보십시오.
 정신 건강을위한 AI는 스탠포드 대학교의 흥미로운 새로운 이니셔티브를 통해주의 깊게 분석됩니다.Apr 18, 2025 am 11:49 AM
정신 건강을위한 AI는 스탠포드 대학교의 흥미로운 새로운 이니셔티브를 통해주의 깊게 분석됩니다.Apr 18, 2025 am 11:49 AMAI4MH의 첫 출시는 2025 년 4 월 15 일에 열렸으며, 유명한 정신과 의사이자 신경 과학자 인 Luminary Dr. Tom Insel 박사는 킥오프 스피커 역할을했습니다. Insel 박사는 정신 건강 연구 및 테크노에서 뛰어난 작업으로 유명합니다.
 2025 WNBA 드래프트 클래스는 리그가 성장하고 온라인 괴롭힘과 싸우고 있습니다.Apr 18, 2025 am 11:44 AM
2025 WNBA 드래프트 클래스는 리그가 성장하고 온라인 괴롭힘과 싸우고 있습니다.Apr 18, 2025 am 11:44 AMEngelbert는 "WNBA가 모든 사람, 플레이어, 팬 및 기업 파트너가 안전하고 가치가 있으며 권한을 부여받는 공간으로 남아 있기를 원합니다. 아노
 파이썬 내장 데이터 구조에 대한 포괄적 인 가이드 - 분석 VidhyaApr 18, 2025 am 11:43 AM
파이썬 내장 데이터 구조에 대한 포괄적 인 가이드 - 분석 VidhyaApr 18, 2025 am 11:43 AM소개 Python은 특히 데이터 과학 및 생성 AI에서 프로그래밍 언어로 탁월합니다. 대규모 데이터 세트를 처리 할 때 효율적인 데이터 조작 (저장, 관리 및 액세스)이 중요합니다. 우리는 이전에 숫자와 st를 다루었습니다
 대안과 비교하여 OpenAi의 새로운 모델의 첫인상Apr 18, 2025 am 11:41 AM
대안과 비교하여 OpenAi의 새로운 모델의 첫인상Apr 18, 2025 am 11:41 AM다이빙하기 전에 중요한 경고 : AI 성능은 비 결정적이며 고도로 사용하는 것이 중요합니다. 간단히 말하면 마일리지는 다를 수 있습니다. 이 기사 (또는 다른) 기사를 최종 단어로 취하지 마십시오. 대신 에이 모델을 자신의 시나리오에서 테스트하십시오.
 AI 포트폴리오 | AI 경력을위한 포트폴리오를 구축하는 방법은 무엇입니까?Apr 18, 2025 am 11:40 AM
AI 포트폴리오 | AI 경력을위한 포트폴리오를 구축하는 방법은 무엇입니까?Apr 18, 2025 am 11:40 AM뛰어난 AI/ML 포트폴리오 구축 : 초보자 및 전문가를위한 안내서 인공 지능 (AI) 및 머신 러닝 (ML)의 역할을 확보하는 데 강력한 포트폴리오를 만드는 것이 중요합니다. 이 안내서는 포트폴리오 구축에 대한 조언을 제공합니다
 보안 운영에 대한 에이전트 AI가 무엇을 의미 할 수 있는지Apr 18, 2025 am 11:36 AM
보안 운영에 대한 에이전트 AI가 무엇을 의미 할 수 있는지Apr 18, 2025 am 11:36 AM결과? 소진, 비 효율성 및 탐지와 동작 사이의 넓은 차이. 이 중 어느 것도 사이버 보안에서 일하는 사람에게는 충격이되지 않습니다. 그러나 에이전트 AI의 약속은 잠재적 인 전환점으로 부상했다. 이 새로운 수업
 Google 대 Openai : AI 학생들을위한 AI 싸움Apr 18, 2025 am 11:31 AM
Google 대 Openai : AI 학생들을위한 AI 싸움Apr 18, 2025 am 11:31 AM장기 파트너십 대 즉각적인 영향? 2 주 전 Openai는 2025 년 5 월 말까지 미국과 캐나다 대학생들에게 Chatgpt Plus에 무료로 이용할 수있는 강력한 단기 제안으로 발전했습니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

드림위버 CS6
시각적 웹 개발 도구

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

