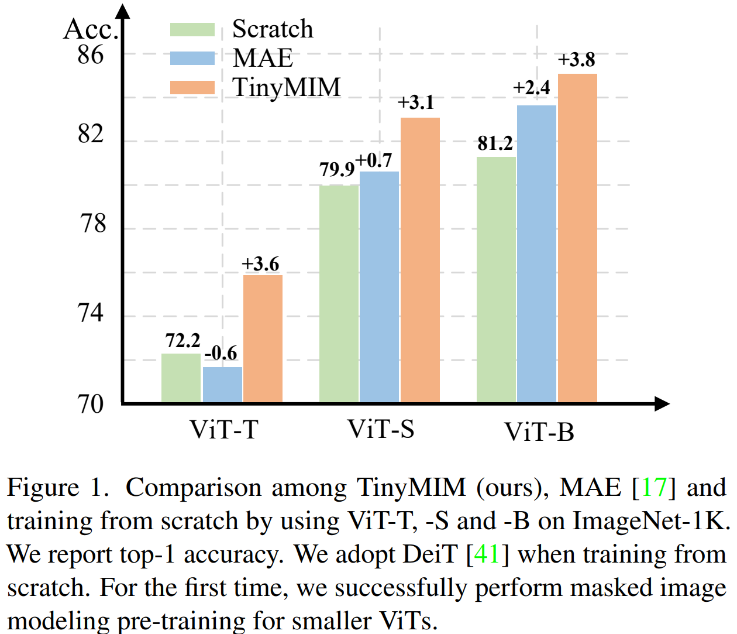
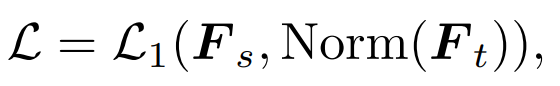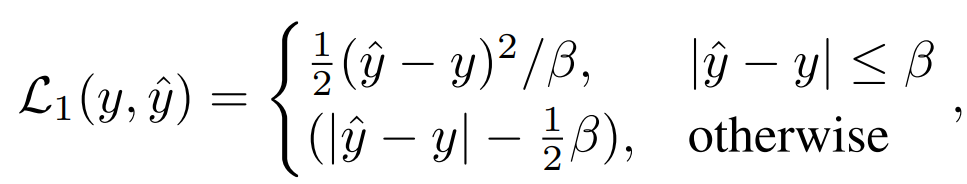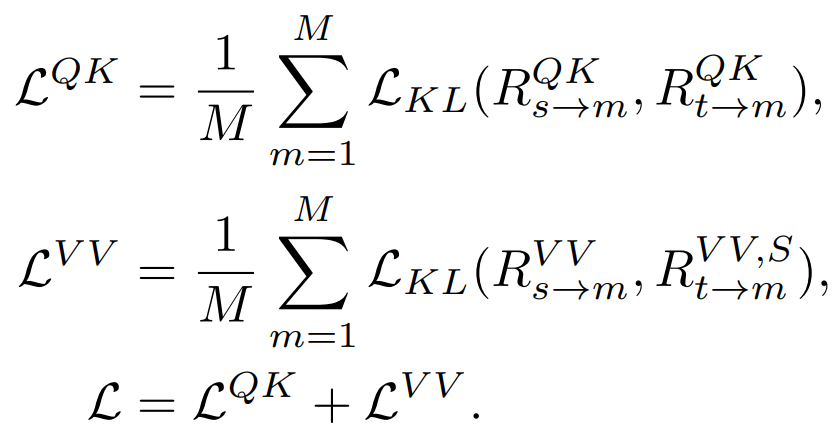마스크 모델링(MIM, MAE)은 매우 효과적인 자기 지도 훈련 방법임이 입증되었습니다. 그러나 그림 1에 표시된 것처럼 MIM은 더 큰 모델에서 상대적으로 더 잘 작동합니다. 모델이 매우 작은 경우(예: ViT-T 5M 매개변수, 이러한 모델은 실제 세계에서 매우 중요함) MIM은 모델의 효과를 어느 정도 감소시킬 수도 있습니다. 예를 들어, ImageNet에서 MAE로 훈련한 ViT-L의 분류 효과는 일반 감독으로 훈련한 모델보다 3.3% 더 높지만, ImageNet에서 MAE로 훈련한 ViT-T의 분류 효과는 0.6% 더 낮습니다. 일반적인 감독으로 훈련된 모델입니다. 이 연구에서 우리는 증류 방법을 사용하여 구조를 변경하지 않고 다른 귀납적 편향을 도입하기 위해 구조를 수정하지 않으면서 대형 모델에서 ViT로 지식을 전달하는 TinyMIM을 제안했습니다. 
- 문서 주소: https://arxiv.org/pdf/2301.01296.pdf
- 코드 주소: https://github.com/OliverRensu /TinyMIM
증류 목적, 데이터 강화, 정규화, 보조 손실 함수 등이 증류에 미치는 영향을 체계적으로 연구했습니다. ImageNet-1K만 훈련 데이터로 엄격하게 사용하고(ImageNet-1K 훈련만 사용하는 Teacher 모델 포함) ViT-B를 모델로 사용하는 경우 현재 우리 방법이 최고의 성능을 달성합니다. 그림에 표시된 대로: 우리의 방법(TinyMIM)을 마스크 재구성 기반 방법 MAE 및 처음부터 훈련된 지도 학습 방법 DeiT와 비교합니다. MAE는 모델이 상대적으로 클 때 성능이 크게 향상되지만, 모델이 상대적으로 작을 때는 개선이 제한되고 모델의 최종 효과에 해를 끼칠 수도 있습니다. 우리의 방법인 TinyMIM은 다양한 모델 크기에서 상당한 개선을 달성했습니다. 우리의 기여는 다음과 같습니다:
1. 증류 대상: 1) 클래스 토큰이나 기능 맵만 증류하는 것보다 토큰 간의 관계를 증류하는 것이 더 효과적입니다. 층을 증류 대상으로 삼습니다.
2. 데이터 향상 및 모델 정규화(데이터 및 네트워크 정규화): 1) 마스크된 이미지를 사용하면 효과가 더 나쁩니다. 2) 학생 모델에는 약간의 드롭 경로가 필요하지만 교사 모델에는 그렇지 않습니다. 3. 보조 손실: MIM은 보조 손실 기능으로는 의미가 없습니다. 4. 매크로 증류 전략: 직렬 증류(ViT-B -> ViT-S -> ViT-T)가 가장 효과적인 것으로 나타났습니다.
증류골, 입력이미지, 증류골 모듈을 체계적으로 조사했습니다.
당 i=L인 경우 Transformer 출력층의 특성을 의미합니다. i b. Attention(Attention) 기능 및 FFN(Feed-Forward Layer) 레이어 기능
Transformer 각 블록에는 Attention 레이어와 FFN 레이어가 있으며 증류됩니다. 다른 레이어는 다른 효과를 갖습니다.
주의 레이어에는 Q, K, V 기능이 있으며 이러한 기능은 주의 메커니즘을 계산하는 데 사용됩니다. 이러한 특성을 직접 증류합니다.
Q, K, V는 어텐션 맵을 계산하는 데 사용되며 이러한 특징 간의 관계도 지식의 대상으로 사용할 수 있습니다. 증류. 전통지식 증류는 완성된 이미지를 직접 입력하는 것입니다. 우리의 방법은 증류 마스크 모델링 모델을 탐색하는 것이므로 마스크된 이미지가 지식 증류의 입력으로 적합한지 여부도 탐색합니다. 가장 간단한 방법은 DeiT와 같은 MAE 사전 훈련된 모델의 클래스 토큰을 직접 증류하는 것입니다:
여기서 는 학생 모델의 클래스 토큰을 나타내고, 는 교사 모델의 클래스 토큰을 나타냅니다. 2) 특징 증류: 비교를 위해 특징 증류 [1]을 직접 참조합니다
3) 관계 증류: 우리는 또한 이 글의 기본 증류 전략
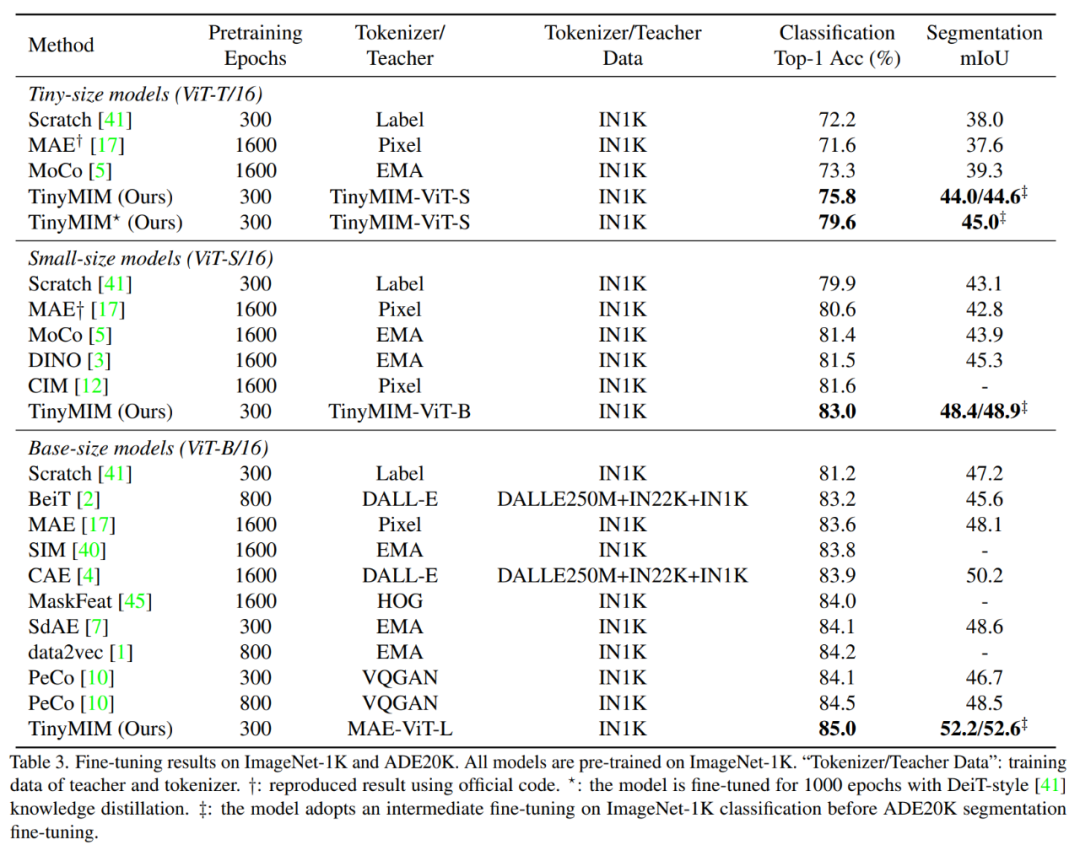
저희 방법은 ImageNet에서 사전 학습되었습니다. 1K이며 교사 모델도 ImageNet-1K에서 사전 훈련되었습니다. 그런 다음 다운스트림 작업(분류, 의미론적 분할)에 대해 사전 훈련된 모델을 미세 조정했습니다. 모델 성능은 그림과 같습니다:
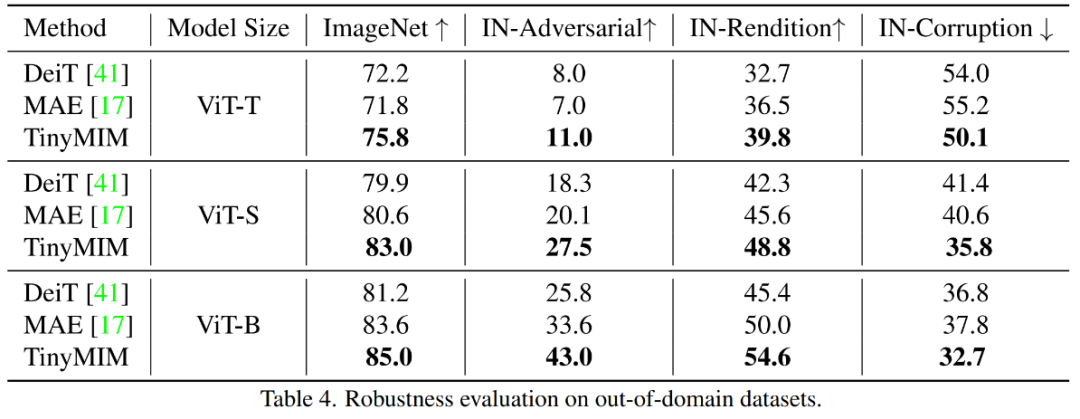
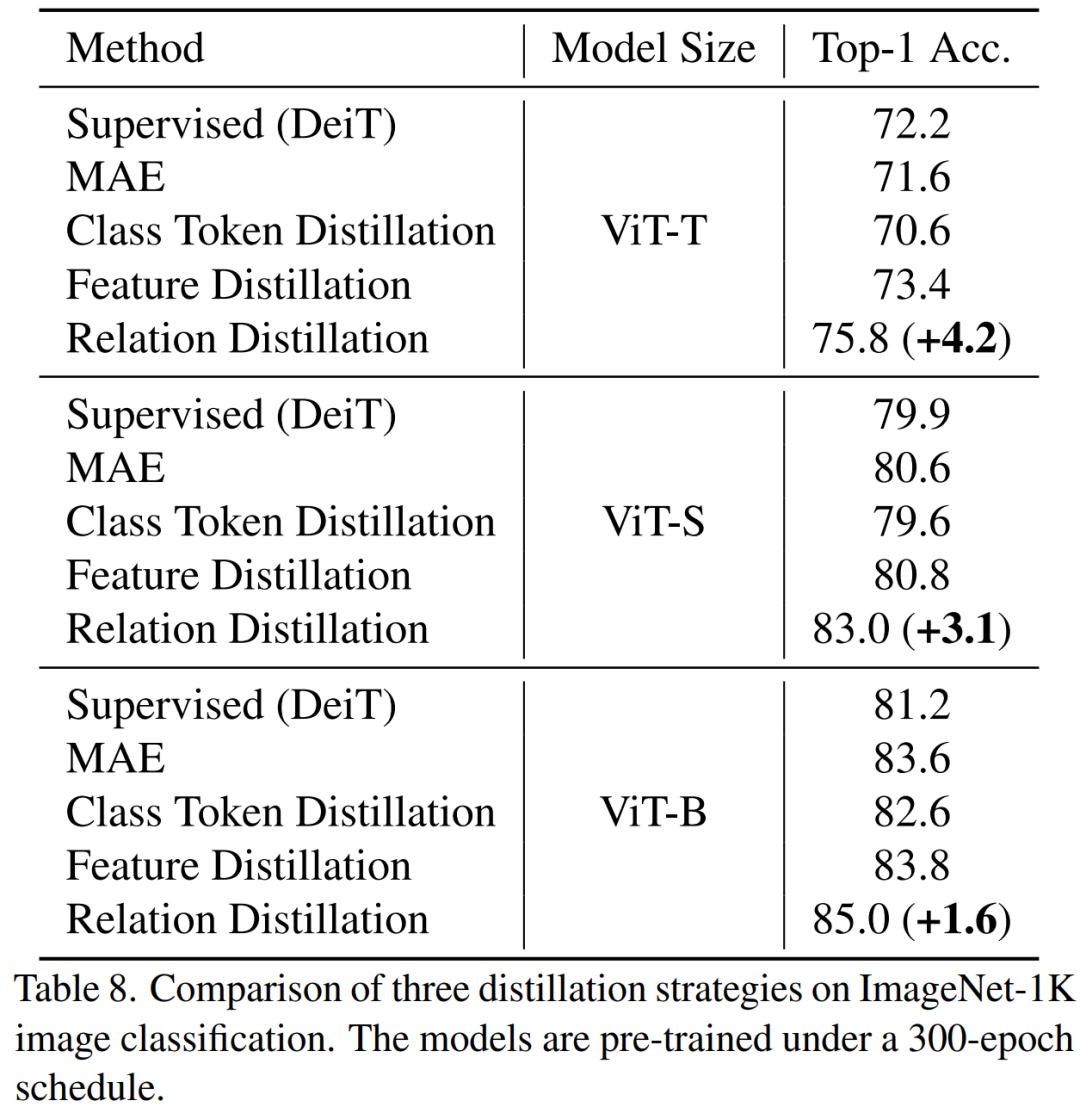
저희 방법은 특히 소형 모델의 경우 이전 MAE 기반 방법보다 훨씬 뛰어난 성능을 발휘합니다. 특히, 초소형 모델 ViT-T의 경우, 우리의 방법은 MAE 기준 모델에 비해 4.2 향상된 75.8%의 분류 정확도를 달성했습니다. 소형 모델 ViT-S의 경우 이전 최상의 방법에 비해 1.4 향상된 83.0%의 분류 정확도를 달성했습니다. 기본 크기 모델의 경우, 우리의 방법은 각각 CAE 4.1 및 2.0에서 MAE 기준 모델과 이전 최고 모델보다 성능이 뛰어납니다. 동시에 그림에 표시된 대로 모델의 견고성도 테스트했습니다.
TinyMIM-B와 ImageNet의 MAE-B 비교 -A 및 ImageNet- R은 각각 +6.4 및 +4.6 향상되었습니다.
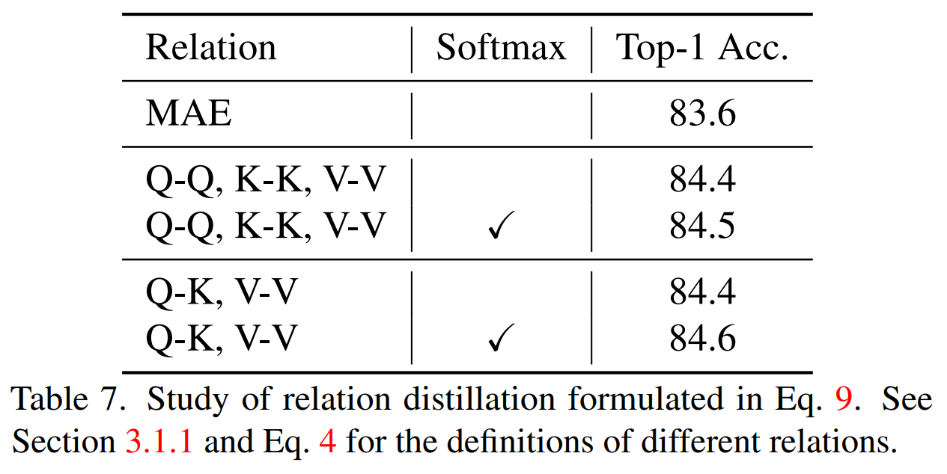
동시 QK, V V 관계를 추출하고 관계를 계산할 때 Softmax를 구현합니다. 결과.
TinyMIM 이 관계 증류 방법은 MAE 기준 모델, 클래스 토큰 증류 및 기능 맵 증류보다 더 나은 성능을 달성합니다. 효과는 모든 크기의 모델에서 동일합니다.
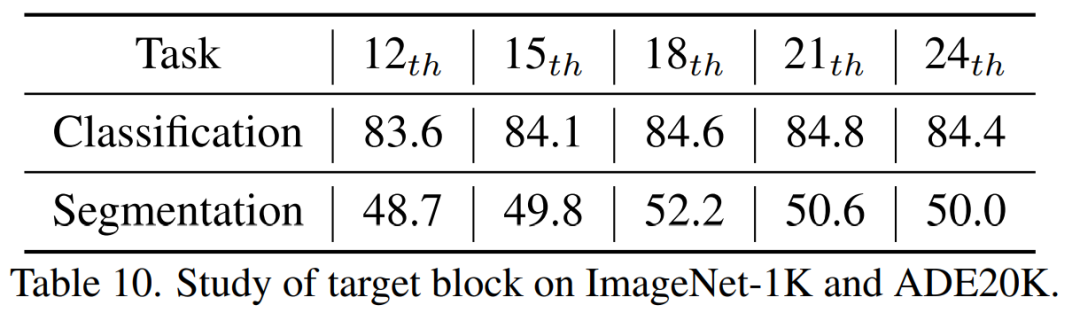
우리는 18번째 증류층이 최고의 결과를 얻는다는 것을 발견했습니다. 본 논문에서는 소규모 모델이 MIM(Mask Reconstruction Modeling) 사전 훈련의 이점을 성공적으로 누릴 수 있는 최초의 모델인 TinyMIM을 제안했습니다. 작업으로 마스크 재구성을 채택하는 대신 지식 증류 방식으로 대형 모델의 관계를 시뮬레이션하기 위해 소형 모델을 학습하여 소형 모델을 사전 학습합니다. TinyMIM의 성공은 증류 목표, 증류 입력 및 중간 레이어를 포함하여 TinyMIM 사전 훈련에 영향을 미칠 수 있는 다양한 요소에 대한 포괄적인 연구에 기인합니다. 광범위한 실험을 통해 관계 증류가 특성 증류, 클래스 라벨 증류 등에 비해 우수하다는 결론을 내렸습니다. 단순성과 강력한 성능을 통해 우리의 방법이 향후 연구를 위한 견고한 기반을 제공할 수 있기를 바랍니다. [1] Wei, Y., Hu, H., Xie, Z., Zhang, Z., Cao, Y., Bao, J., ... & Guo, B.(2022) . arXiv 사전 인쇄 arXiv:2205.14141.를 통한 미세 조정에서 대조 학습 경쟁은 마스크 이미지입니다.위 내용은 Microsoft Research Asia, TinyMIM 출시: 지식 증류를 통해 소규모 ViT의 성능 향상의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



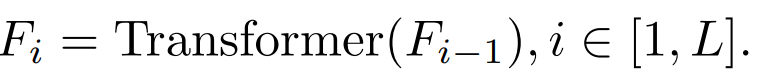
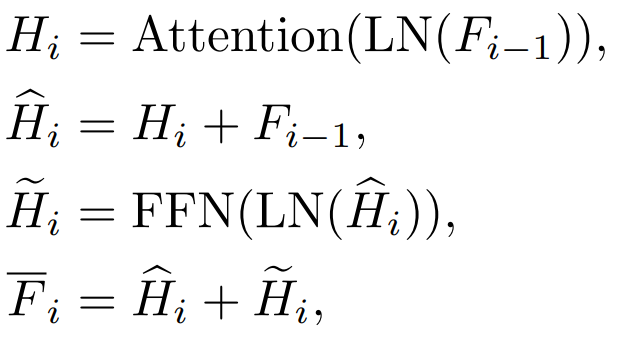
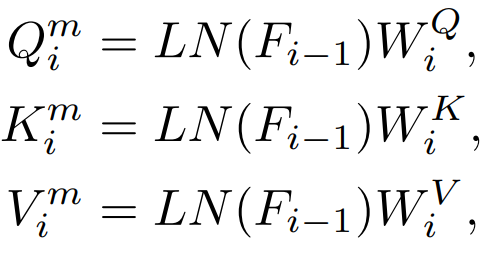

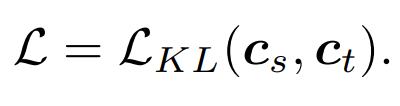
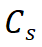 는 학생 모델의 클래스 토큰을 나타내고,
는 학생 모델의 클래스 토큰을 나타내고, 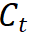 는 교사 모델의 클래스 토큰을 나타냅니다.
는 교사 모델의 클래스 토큰을 나타냅니다.