
매우 간단합니다! Python을 사용하여 이미지 및 PDF에서 워터마크 제거

- WBOY앞으로
- 2023-04-12 23:43:012409검색

온라인으로 다운로드한 일부 PDF 학습 자료에는 워터마크가 있어 읽기에 큰 영향을 미칩니다. 예를 들어, 아래 그림은 PDF 파일에서 잘라낸 것입니다. 오늘은 Python을 사용하여 이 문제를 해결하겠습니다.

모듈 설치
PIL: Python Imaging Library는 Python의 매우 강력한 이미지 처리 표준 라이브러리이지만 Python 2.7만 지원할 수 있기 때문에 일부 자원봉사자는 PIL 기반 Python 3을 지원하는 필로우를 만들고 추가했습니다. 몇 가지 새로운 기능.
pip install pillow
pymupdf는 Python을 사용하여 확장자가 *.pdf, .xps, .oxps, .epub, .cbz 또는 *.fb2인 파일에 액세스할 수 있습니다. 다중 페이지 TIFF 이미지를 포함하여 널리 사용되는 다양한 이미지 형식도 지원됩니다.
pip install PyMuPDF
필요한 모듈 가져오기
from PIL import Image from itertools import product import fitz import os
이미지의 RGB 가져오기
pdf 워터마크 제거의 원리는 이미지 워터마크 제거의 원리와 유사합니다. 편집기는 위 이미지의 워터마크 제거부터 시작합니다.
컴퓨터를 공부한 친구들은 모두 컴퓨터에서 RGB가 빨간색, 녹색, 파란색을 나타내고, (255, 0, 0)이 빨간색을, (0, 255, 0)이 녹색을, (0, 0, 255)가 파란색을 나타낸다는 것을 모두 알고 있습니다. , (255, 255, 255)는 흰색을 나타내고, (0, 0, 0)은 검정색을 나타냅니다. 워터마크 제거의 원리는 워터마크의 색상을 흰색(255, 255, 255)으로 변경하는 것입니다.
먼저 이미지의 너비와 높이를 구하고 itertools 모듈을 사용하여 너비와 높이의 데카르트 곱을 픽셀로 구합니다. 각 픽셀의 색상은 RGB의 처음 3비트와 알파 채널의 네 번째 비트로 구성됩니다. 알파 채널은 필요하지 않으며 RGB 데이터만 필요합니다.
def remove_img():
image_file = input("请输入图片地址:")
img = Image.open(image_file)
width, height = img.size
for pos in product(range(width), range(height)):
rgb = img.getpixel(pos)[:3]
print(rgb)
사진에서 워터마크 제거
WeChat 스크린샷을 사용하여 워터마크 픽셀의 RGB를 확인하세요.
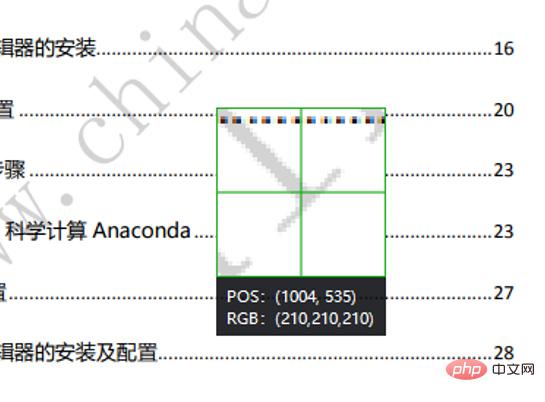
워터마크의 RGB가 (210, 210, 210)임을 알 수 있습니다. 여기서 RGB의 합이 620을 초과하면 워터마크 포인트로 판단됩니다. 흰색으로 교체했습니다. 마지막으로 사진을 저장합니다.
rgb = img.getpixel(pos)[:3]
if(sum(rgb) >= 620):
img.putpixel(pos, (255, 255, 255))
img.save('d:/qsy.png')
예시 결과:

PDF 워터마크 제거
PDF 워터마크 제거 원리는 이미지 워터마크 제거 원리와 거의 동일합니다. PyMuPDF로 PDF 파일을 열면 PDF의 각 페이지가 변환됩니다. 이미지 픽스맵, 픽스맵 자체 RGB가 있으므로 PDF 워터마크의 RGB를 (255, 255, 255)로 변경하고 마지막으로 이미지로 저장하면 됩니다.
def remove_pdf():
page_num = 0
pdf_file = input("请输入 pdf 地址:")
pdf = fitz.open(pdf_file);
for page in pdf:
pixmap = page.get_pixmap()
for pos in product(range(pixmap.width), range(pixmap.height)):
rgb = pixmap.pixel(pos[0], pos[1])
if(sum(rgb) >= 620):
pixmap.set_pixel(pos[0], pos[1], (255, 255, 255))
pixmap.pil_save(f"d:/pdf_images/{page_num}.png")
print(f"第{page_num}水印去除完成")
page_num = page_num + 1
예제 결과:
그림을 pdf로 변환
그림을 pdf로 변환합니다. 주의할 점은 숫자 파일 이름을 먼저 int 형식으로 변환한 다음 정렬해야 한다는 것입니다. PyMuPDF 모듈로 이미지를 연 후, ConvertToPDF() 함수를 사용하여 이미지를 단일 페이지 PDF로 변환합니다. 새 PDF 파일에 삽입하세요.
def pic2pdf():
pic_dir = input("请输入图片文件夹路径:")
pdf = fitz.open()
img_files = sorted(os.listdir(pic_dir),key=lambda x:int(str(x).split('.')[0]))
for img in img_files:
print(img)
imgdoc = fitz.open(pic_dir + '/' + img)
pdfbytes = imgdoc.convertToPDF()
imgpdf = fitz.open("pdf", pdfbytes)
pdf.insertPDF(imgpdf)
pdf.save("d:/demo.pdf")
pdf.close()
요약
PDF와 사진의 성가신 워터마크가 마침내 강력한 Python 앞에서 사라질 수 있습니다. 여러분, 충분히 배웠나요?
위 내용은 매우 간단합니다! Python을 사용하여 이미지 및 PDF에서 워터마크 제거의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!