
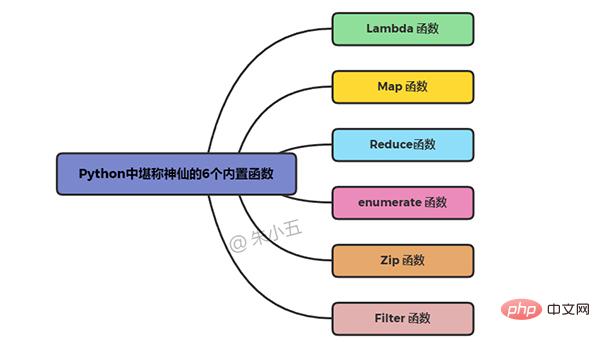
Python에 내장된 6가지 마법 같은 함수

- 王林앞으로
- 2023-04-13 08:04:051980검색

인생은 짧습니다. 초보자도 Python을 배웁니다!
저는 초보입니다. 오늘은 6가지 마법 내장 기능을 한번에 공유해보겠습니다. 많은 컴퓨터 서적에서는 일반적으로 고차 함수로 소개되기도 합니다. 그리고 일상 업무에서 코드를 더 빠르고 이해하기 쉽게 만들기 위해 종종 이를 사용합니다.
Lambda 함수
Lambda 함수는 익명 함수, 즉 이름이 없는 함수를 만드는 데 사용됩니다. 이는 단지 표현식일 뿐이며 함수 본문은 def보다 훨씬 간단합니다. 익명 함수는 단일 작업을 수행하고 한 줄에 작성할 수 있는 함수를 만들어야 할 때 사용됩니다.
lambda [arg1 [,arg2,.....argn]]:expression
람다의 본문은 코드 블록이 아니라 표현식입니다. 제한된 논리만 람다 식으로 캡슐화할 수 있습니다. 예를 들면 다음과 같습니다.
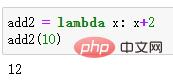
lambda x: x+2
def에 의해 정의된 함수를 언제든지 호출하려면 해당 함수 개체에 람다 함수를 할당할 수 있습니다.
add2 = lambda x: x+2 add2(10)
출력 결과:
Lambda 함수를 사용하면 코드가 훨씬 단순화될 수 있습니다.
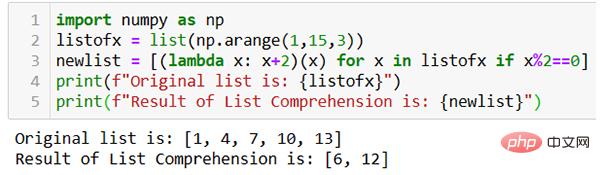
위 그림과 같이 람다 함수를 사용하여 한 줄의 코드로 결과 목록 newlist가 생성됩니다.
Map 함수
map() 함수는 입력 목록의 모든 요소에 함수를 매핑합니다.
map(function,iterable)
예를 들어, 먼저 대문자 입력 단어를 반환하는 함수를 만든 다음 이 함수를 목록 색상의 모든 요소에 적용합니다.
def makeupper(word): return word.upper() colors=['red','yellow','green','black'] colors_uppercase=list(map(makeupper,colors)) colors_uppercase
출력 결과:

또한 익명 함수 람다를 사용하여 지도 함수와 협력할 수 있어 더욱 간소화될 수 있습니다.
colors=['red','yellow','green','black'] colors_uppercase=list(map(lambda x: x.upper(),colors)) colors_uppercase
Map 함수를 사용하지 않으면 for 루프를 사용해야 합니다.
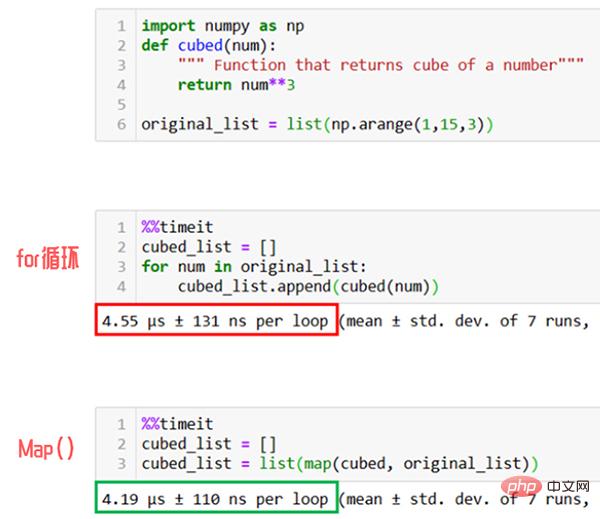
위 그림과 같이 실제 사용 시 Map 함수는 요소를 순차적으로 나열하는 for 루프 방식보다 1.5배 더 빠릅니다.
Reduce 함수
Reduce()는 목록에서 일부 계산을 수행하고 결과를 반환해야 할 때 매우 유용한 함수입니다. 예를 들어, 정수 목록의 모든 요소의 곱을 계산해야 하는 경우 감소 함수를 사용할 수 있습니다. [1]
함수와 가장 큰 차이점은 Reduce()의 매핑 함수(함수)는 두 개의 매개변수를 받는 반면, map은 하나의 매개변수를 받는다는 것입니다.
reduce(function, iterable[, initializer])
다음으로, 예제를 사용하여 Reduce()의 코드 실행 프로세스를 보여줍니다.
from functools import reduce def add(x, y) : # 两数相加 return x + y numbers = [1,2,3,4,5] sum1 = reduce(add, numbers) # 计算列表和
결과 sum1 = 15가 얻어지며, 코드 실행 과정은 아래 애니메이션과 같습니다.
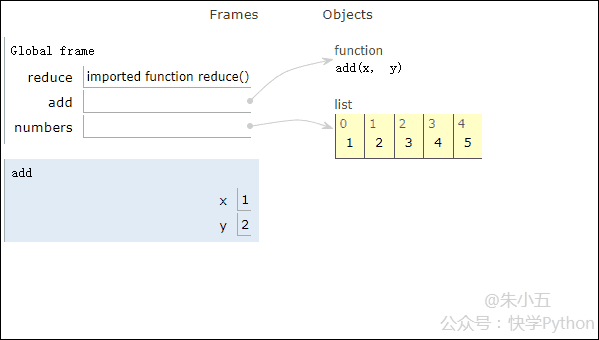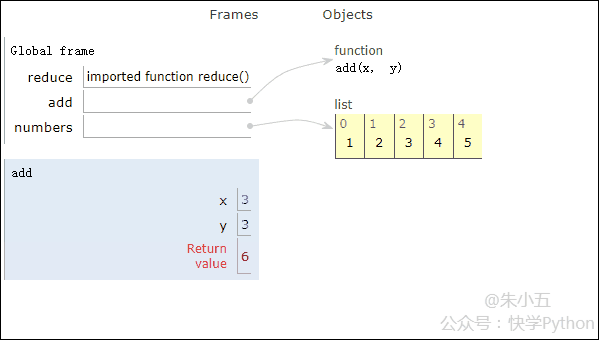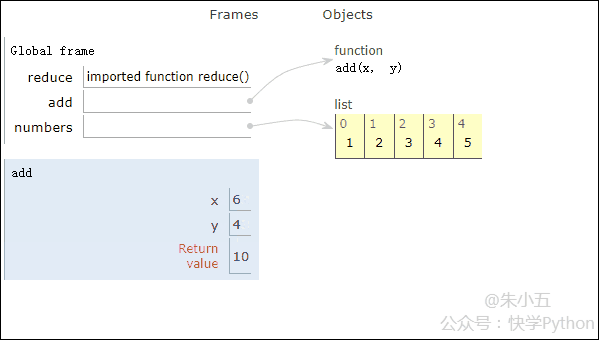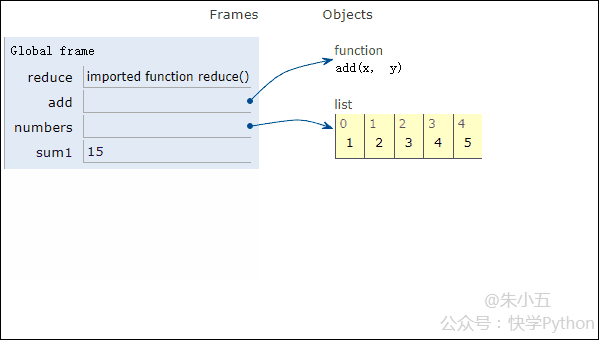
▲코드 실행 과정 애니메이션
위 그림과 결합하면, Reduce는 리스트 [1,2,3,4,5]에 추가 함수 add()를 적용하고 매핑하는 것을 볼 수 있습니다. 함수 수신 두 개의 매개변수를 사용하여 Reduce()는 목록의 다음 요소로 결과를 계속해서 누적합니다.
또한 익명 함수 람다를 사용하여 축소 함수와 협력할 수 있어 더욱 간소화될 수 있습니다.
from functools import reduce numbers = [1,2,3,4,5] sum2 = reduce(lambda x, y: x+y, numbers)
출력 sum2= 15가 얻어지며 이는 이전 결과와 일치합니다.
참고: Python3 이후로 Reduce()는 functools 모듈로 이동되었습니다. 탐색 가능한 데이터 객체(예: 목록, 튜플 또는 문자열)는 일반적으로 다음에서 사용되는 데이터 및 데이터 첨자를 동시에 나열하는 인덱스 시퀀스로 결합됩니다. for 루프. 구문은 다음과 같습니다:
enumerate(iterable, start=0)
두 개의 매개변수 중 하나는 시퀀스, 반복자 또는 반복을 지원하는 기타 객체입니다. 다른 하나는 기본적으로 0부터 시작하는 첨자의 시작 위치입니다. 카운터 시작 번호.
colors = ['red', 'yellow', 'green', 'black'] result = enumerate(colors)
색상을 저장하는 색상 목록이 있는 경우 이를 실행한 후 열거 객체를 얻습니다. for 루프에서 직접 사용하거나 목록으로 변환할 수 있습니다.
for count, element in result:
print(f"迭代编号:{count},对应元素:{element}")
Zip 函数
zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表[3]。
我们还是用两个列表作为例子演示:
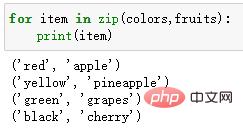
colors = ['red', 'yellow', 'green', 'black'] fruits = ['apple', 'pineapple', 'grapes', 'cherry'] for item in zip(colors,fruits): print(item)
输出结果:
当我们使用zip()函数时,如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
prices =[100,50,120] for item in zip(colors,fruits,prices): print(item)

Filter 函数
filter()函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表,其语法如下所示[4]。
filter(function, iterable)
比如举个例子,我们可以先创建一个函数来检查单词是否为大写,然后使用filter()函数过滤出列表中的所有奇数:
def is_odd(n): return n % 2 == 1 old_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] new_list = filter(is_odd, old_list) print(newlist)
输出结果:

今天分享的这6个内置函数,在使用 Python 进行数据分析或者其他复杂的自动化任务时非常方便。
위 내용은 Python에 내장된 6가지 마법 같은 함수의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!