
Redis 데이터 구조 지식을 그림과 텍스트로 자세히 설명

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-04-01 13:31:132945검색
이 글은 Redis에 대한 관련 지식을 제공합니다. 주로 문자열, 목록, 해시, 순서 집합 등을 포함한 데이터 구조와 관련된 문제를 소개합니다. 모든 사람에게 도움이 되기를 바랍니다.

추천 학습: Redis 학습 튜토리얼
redis 데이터 구조: String(문자열), List(목록), hash(해시), Set(세트), Shorted Set(순서 있는 세트)
기본 데이터 구조 : 단순 동적 문자열, 이중 연결 목록, 압축 목록, 해시 테이블, 점프 목록, 정수 배열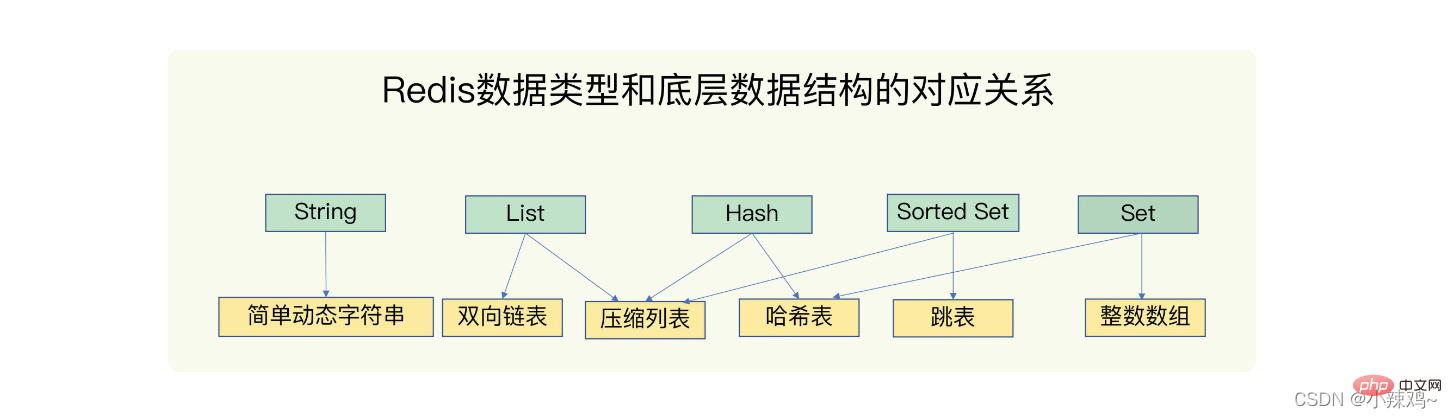
1. 해시 테이블: 해시 테이블은 실제로 배열이며, 배열의 각 요소를 해시 버킷이라고 합니다. 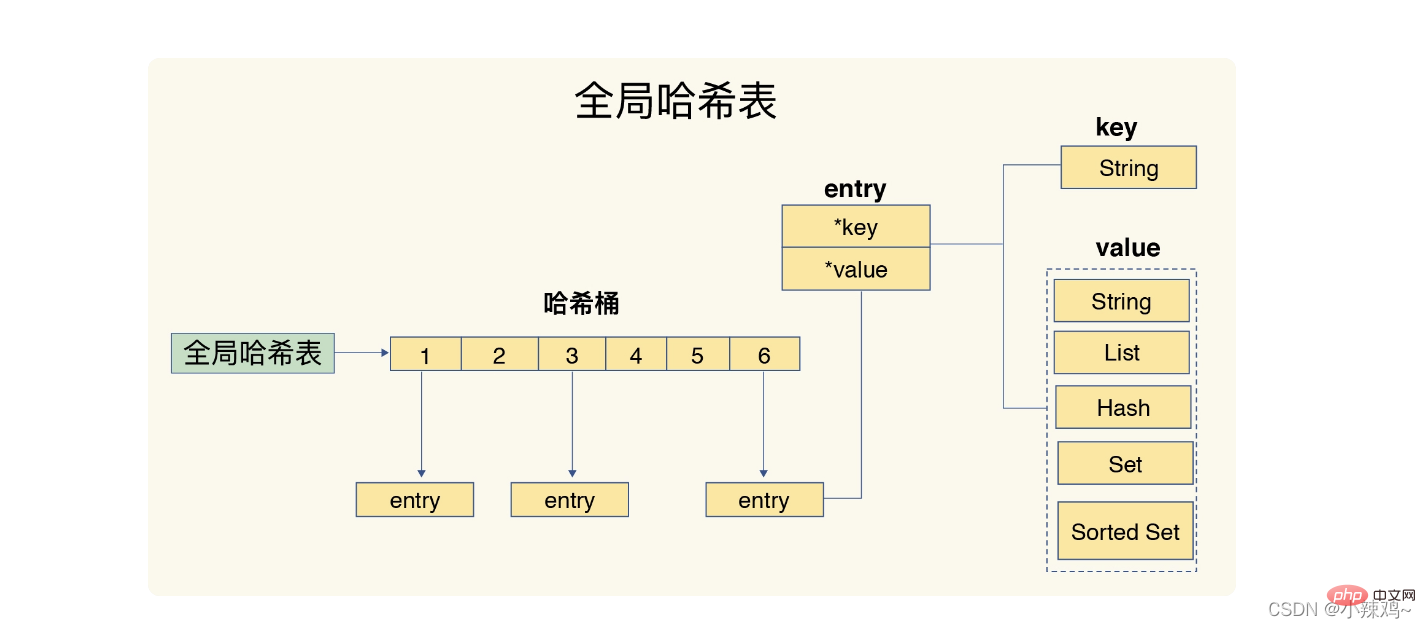
해시 충돌 및 재해시로 인해 작업이 차단될 수 있습니다.
Redis의 해시 충돌 해결 방법은 체인 해싱이고, 재해시는 기존 해시 버킷 수를 늘리는 것입니다. 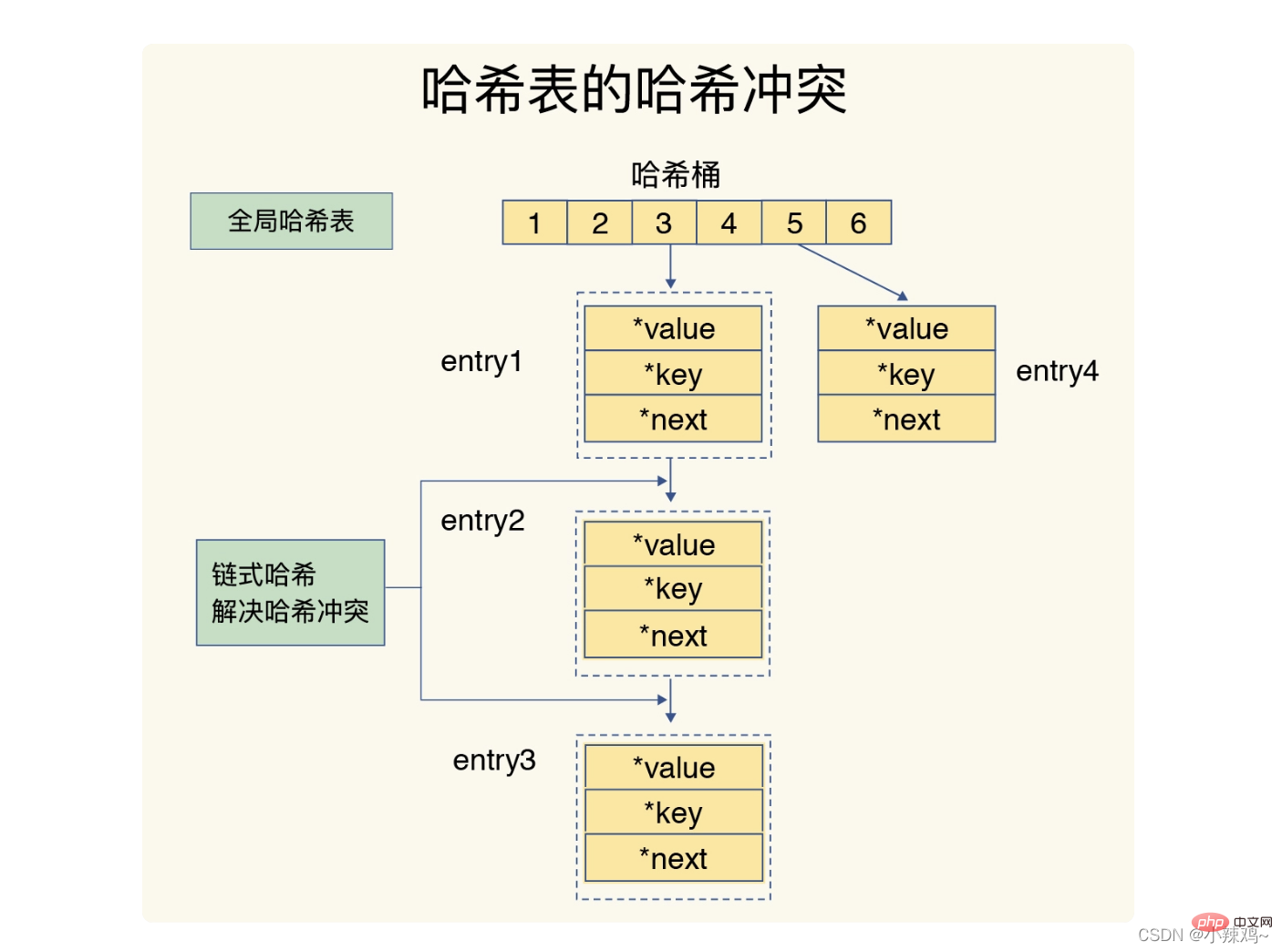
재해시 작업 단계: 1. 해시 테이블에 더 큰 공간을 할당합니다(예: 현재 해시 테이블 크기의 두 배)
2. 해시 테이블 1의 데이터를 해시 테이블 2에 다시 매핑하고 복사합니다
3. 공간을 해제합니다. of hash table 1
두 번째 단계에는 많은 수의 데이터 복사 작업이 포함됩니다. 해시 테이블 1의 모든 데이터가 한 번에 마이그레이션되면 스레드가 차단되고 다른 요청이 처리되지 않습니다. 이 문제를 피하기 위해 redis는 점진적인 rehash를 사용합니다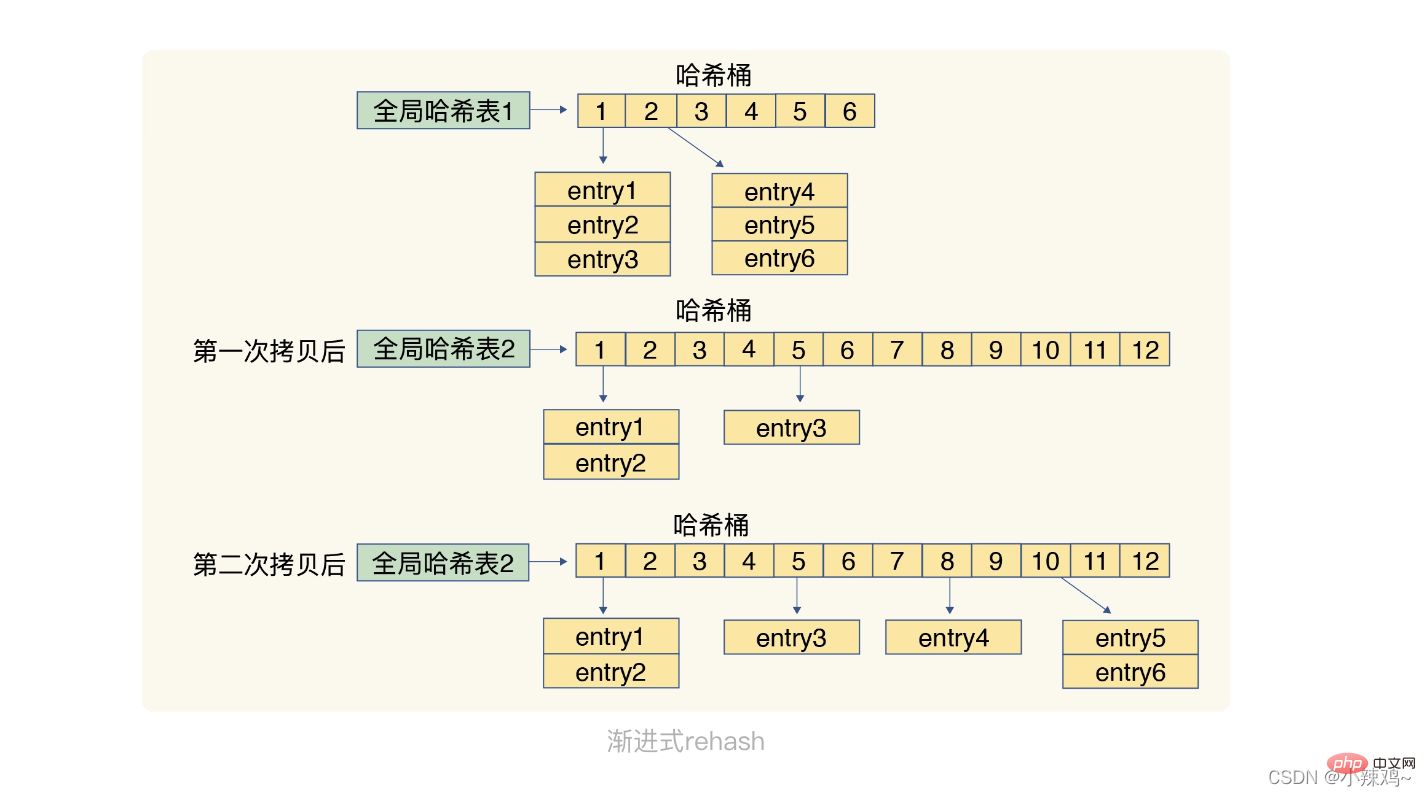
정수 배열과 이중 연결 목록의 복잡성은 O(N)입니다.
압축된 목록의 헤더에는 목록 길이, 꼬리 오프셋의 세 가지 데이터가 있습니다. 목록과 목록 중간에 있는 항목 수
압축된 목록에는 목록의 끝을 나타내기 위해 테이블 끝에 zlend 요소도 있습니다. 
목록 건너뛰기: 순서가 지정된 연결 목록은 요소를 하나씩만 찾을 수 있습니다. 하나, 스킵 리스트는 연결된 리스트를 기반으로 다중 레벨 인덱스를 추가합니다. 인덱스 위치를 통해 여러 점프를 통해 데이터의 빠른 위치 지정을 달성합니다. 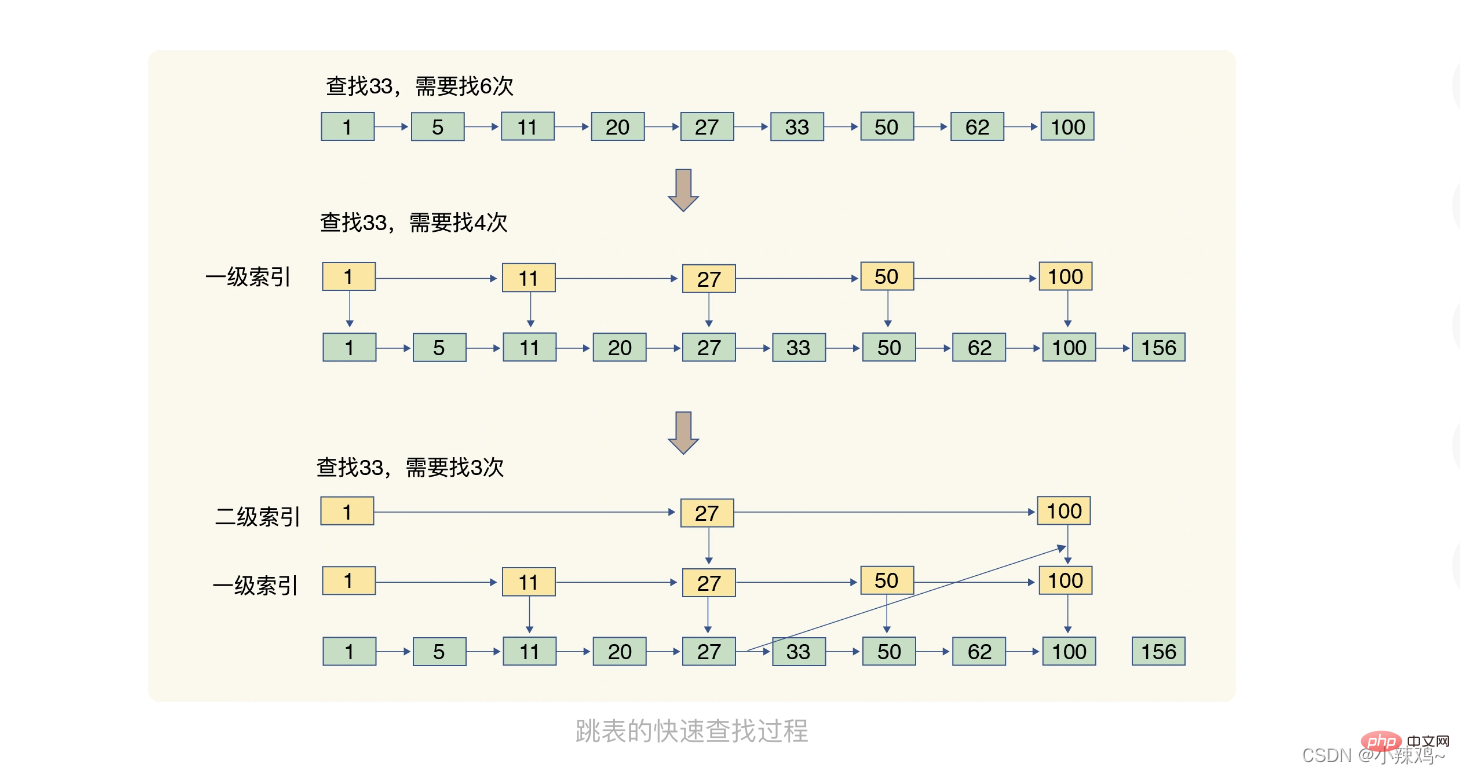
다음 다섯 가지 구조의 시간 복잡도 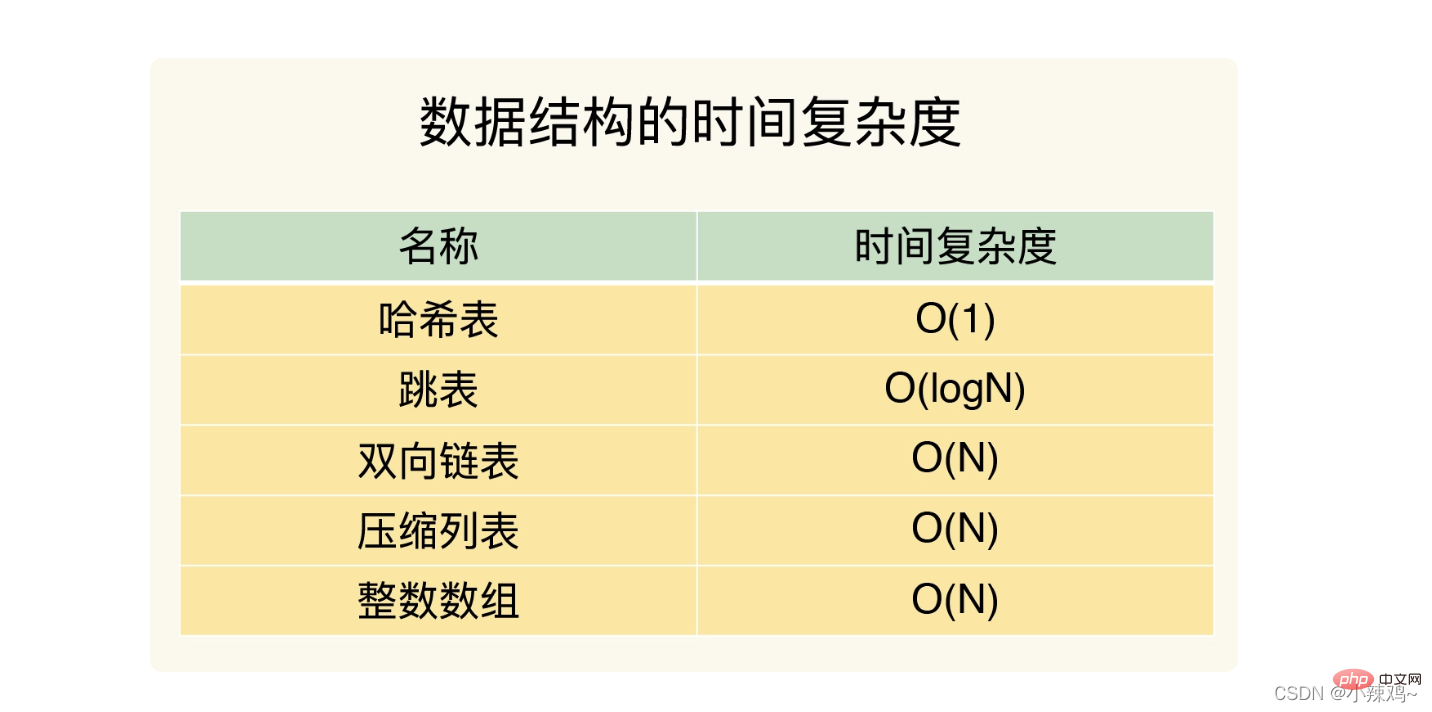
문자열 유형
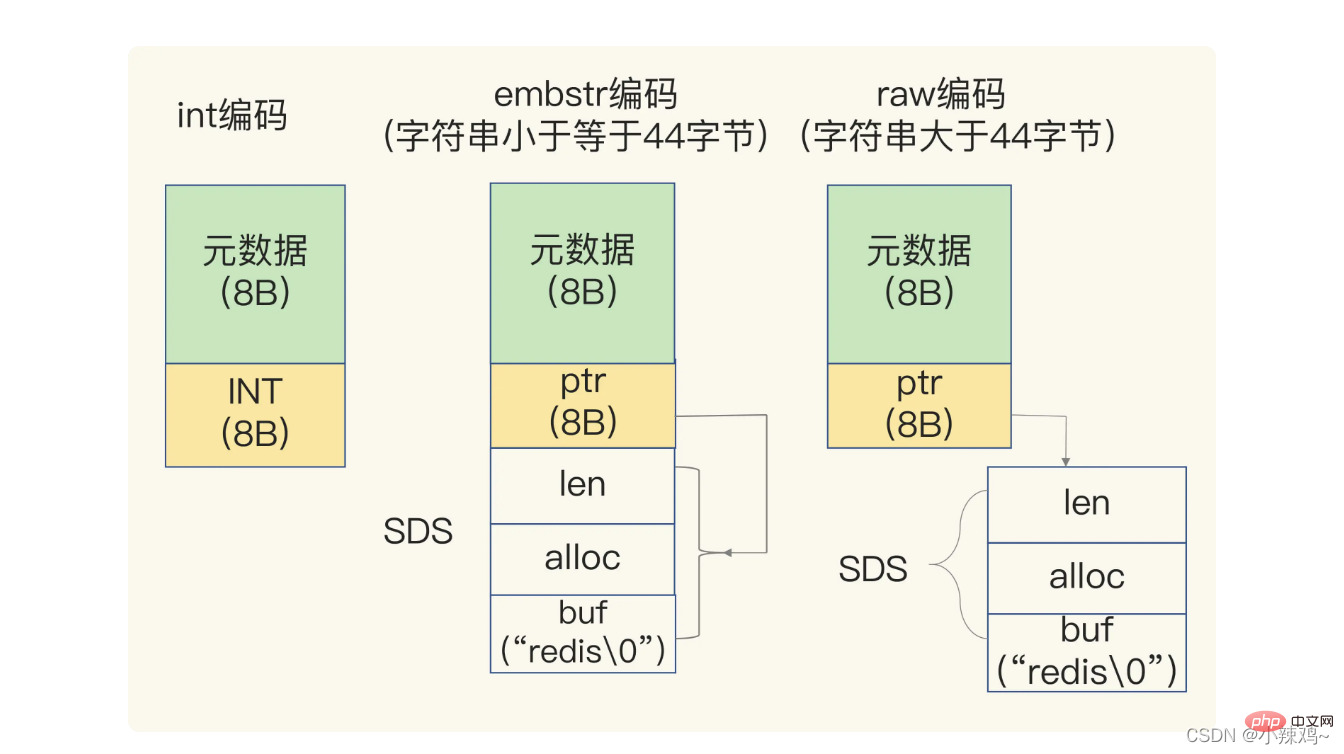
문자열 유형은 모든 시나리오에 적합하지 않습니다. 데이터를 저장할 때 더 많은 메모리 공간을 소비한다는 명백한 단점이 있습니다. String 유형은 데이터 길이, 공간 사용량 및 기타 정보를 기록하기 위해 추가 메모리 공간이 필요하므로 이 정보를 메타데이터라고도 합니다.
저장된 데이터에 문자가 포함된 경우 간단한 동적 문자열 SDS 구조를 사용하여 문자열이 저장됩니다. 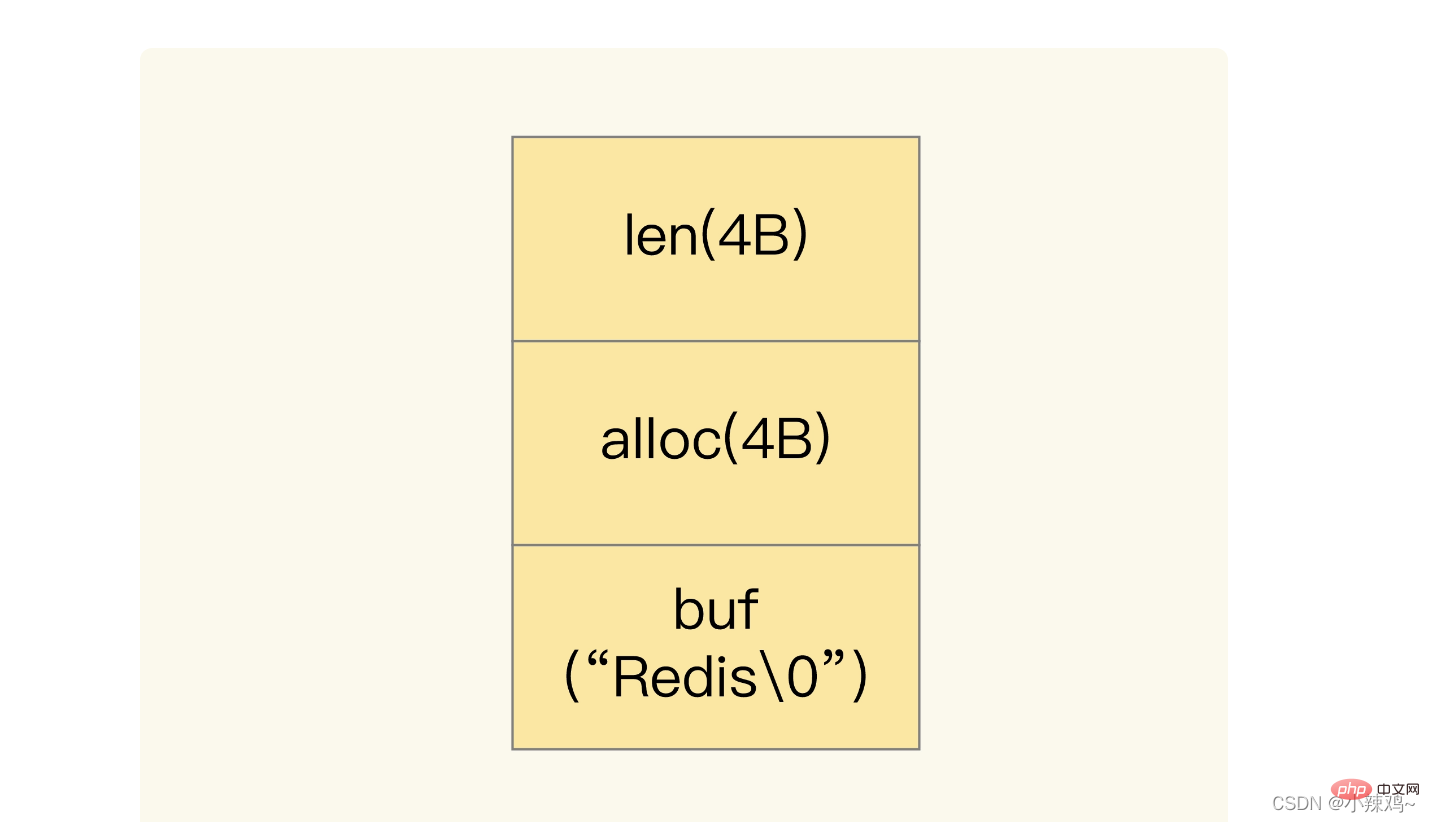
len은 buf에 사용된 길이이고 alloc은 buf에 실제로 할당된 길이입니다.
Redis 데이터 유형이 많기 때문에 데이터가 다릅니다. 동일한 메타데이터를 기록해야 하므로 redis는 RedisObject 구조를 사용하여 이러한 메타데이터를 균일하게 기록합니다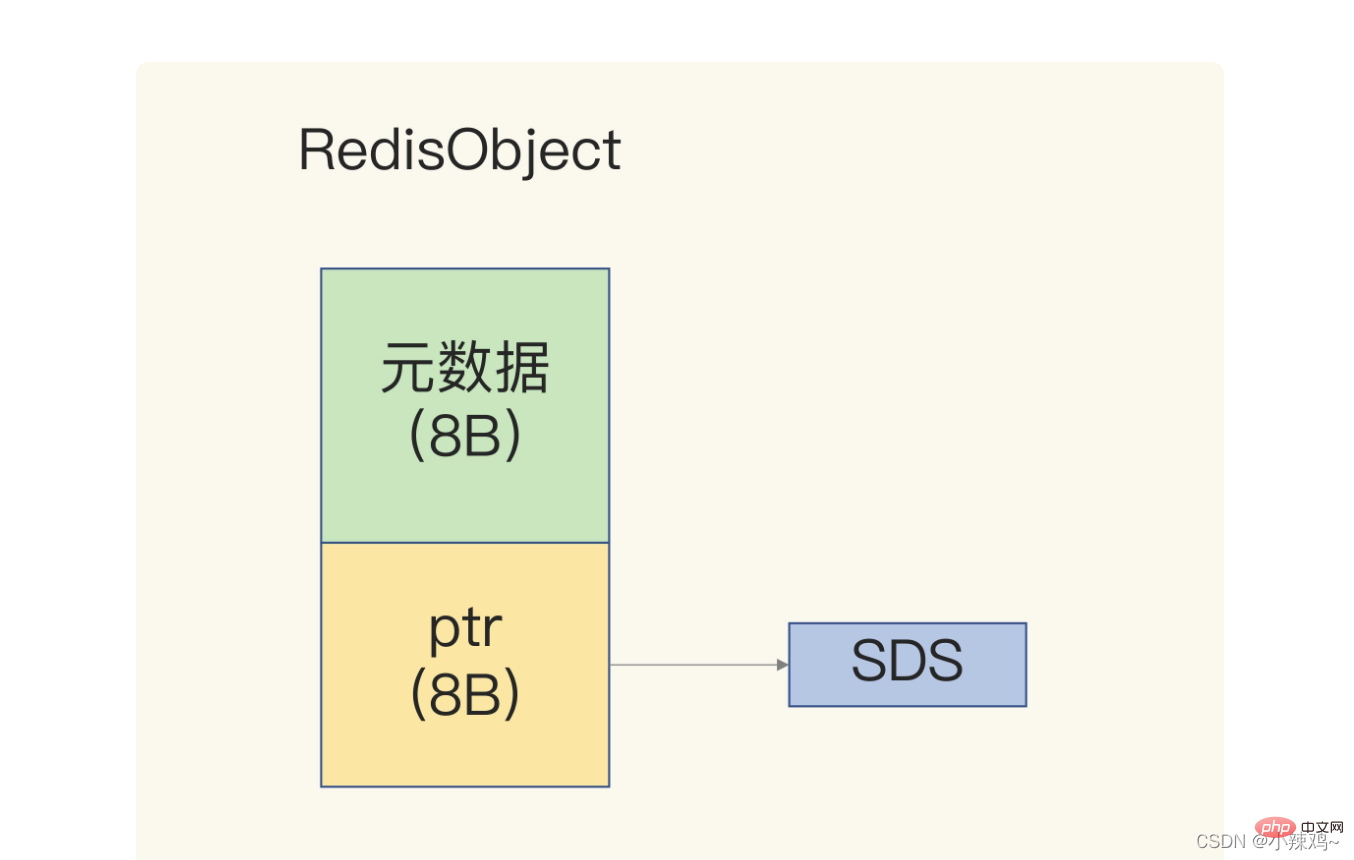
Long 유형을 저장할 때 RedisObject 포인터는 정수 데이터에 직접 할당되므로 추가 포인터가 가리킬 필요가 없습니다. 정수로 포인터의 공간 오버헤드를 절약합니다.
저장된 문자열이 44바이트 미만인 경우 SDS와 메타데이터는 embstr 인코딩이라는 연속 메모리 영역에 할당됩니다.
저장된 문자열이 44바이트보다 큰 경우 SDS와 메타데이터는 별도로 저장되며 원시 인코딩이라고 합니다
또한 Redis는 전역 해시 테이블을 사용하여 모든 키-값 쌍을 저장합니다. 해시 테이블의 각 항목은 키-값 쌍을 가리키는 데 사용되는 dictEntry 구조입니다. value+next는 24바이트를 사용하지만 실제로는 32바이트를 차지합니다. 이는 jemalloc이 메모리를 할당할 때 우리가 적용한 바이트 수에 따라 N보다 크지만 N에 가장 가까운 2의 거듭제곱을 할당 공간으로 찾기 때문입니다. N의 경우 빈번한 할당 횟수를 줄일 수 있습니다. 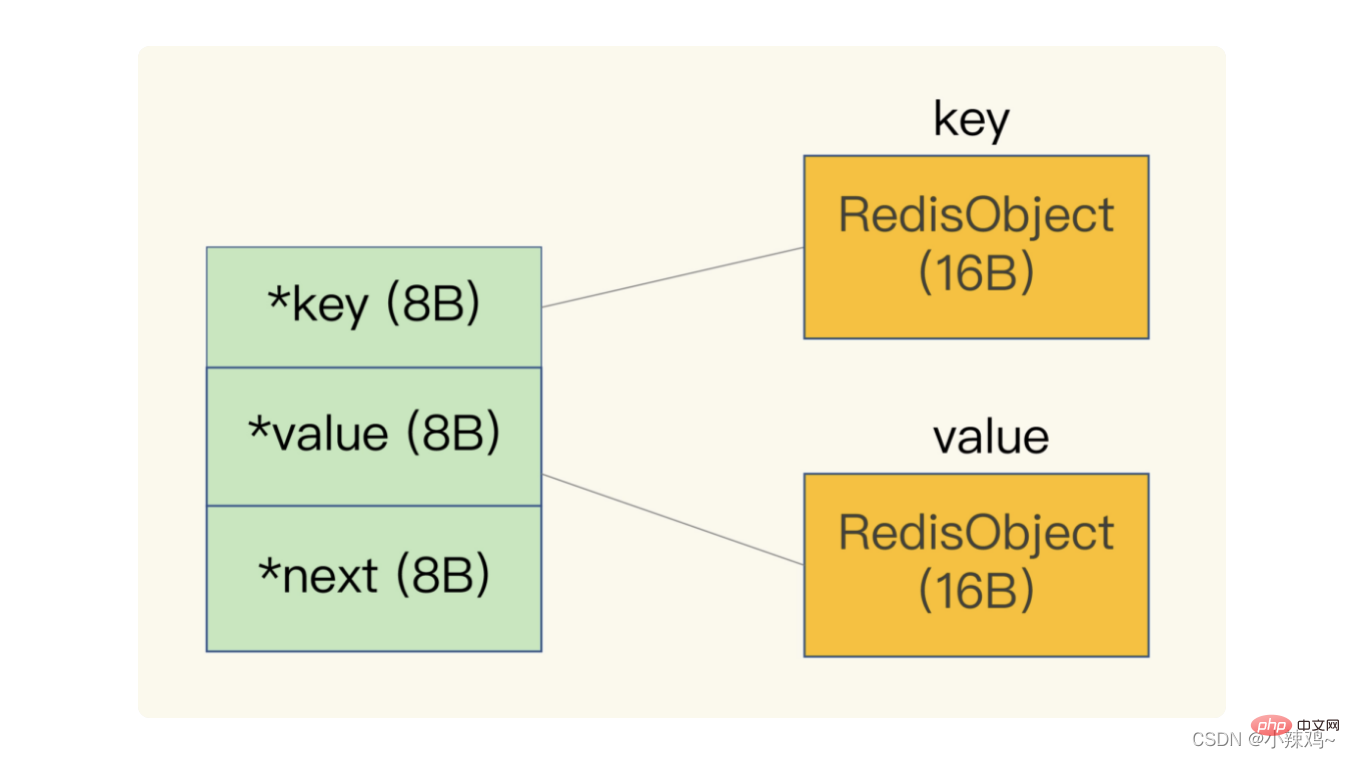
메모리를 절약하기 위해 어떤 데이터 구조를 사용할 수 있나요?
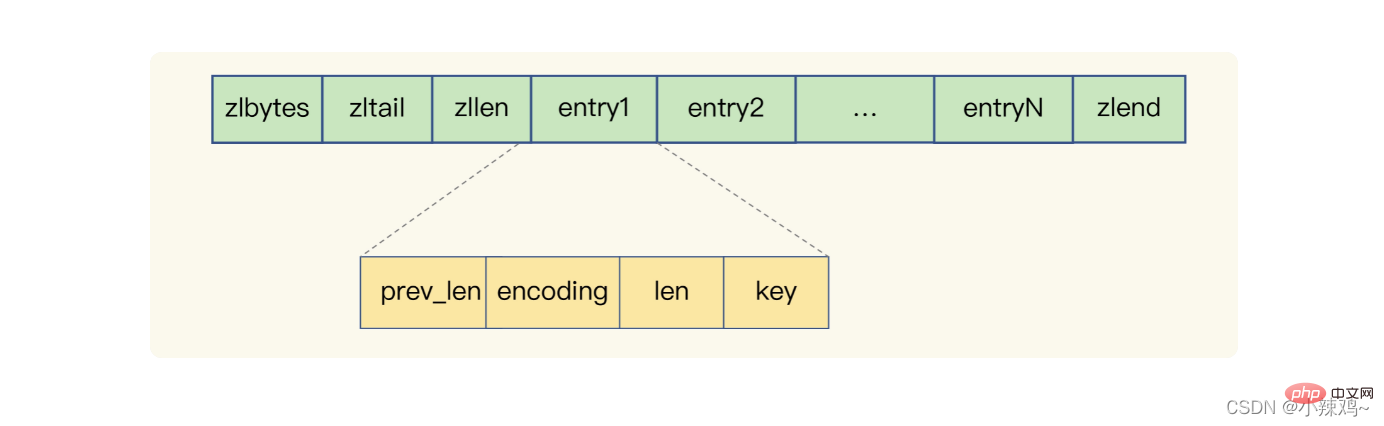
압축된 목록: zlbytes는 목록의 길이를 나타내고, zltail은 목록의 꼬리 오프셋을 나타내고, zllen은 목록의 항목 수를 나타내고, zlend는 목록의 끝을 나타내고, perv_len은 이전 항목의 길이를 나타냅니다. len은 인코딩 방법을 나타내고, len은 자체 길이를 나타내며, key는 실제 저장된 데이터입니다. Redis는 압축된 목록을 기반으로 목록, 해시 및 정렬 집합을 구현합니다.
집합 유형을 사용하여 단일 값 키-값 쌍을 저장하는 방법은 무엇입니까?
단일 값 키-값 쌍을 저장할 때 단일 값 값을 두 부분으로 분할하는 해시의 보조 인코딩을 사용할 수 있습니다. 첫 번째 부분은 해시의 키로 사용되고 후자는 사용됩니다. Hash
以图片 ID 1101000060 和图片存储对象 ID 3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。127.0.0.1:6379> info memory# Memoryused_memory:1039120127.0.0.1:6379> hset 1101000 060 3302000080(integer) 1127.0.0.1:6379> info memory# Memoryused_memory:1039136
Hash 값으로 이 유형에는 두 가지 기본 구현 구조가 있습니다. 1. 압축된 목록 2. 해시 테이블
해시 목록에는 두 개의 임계값이 초과되면 압축된 목록에서 변환됩니다. 목록을 해시 테이블로
hash-max-ziplist-entries로 표시 압축된 목록으로 저장할 때 설정된 해시 목록의 최대 요소 수
hash-max-ziplist-value는 해시의 단일 요소의 최대 길이를 나타냅니다. 압축된 목록으로 저장할 때 설정
통계 모드 설정
1. 집계 통계
2 . 통계 정렬
3. 이진 상태 통계
4. 카디널리티 통계
redis의 세 가지 확장 데이터 유형
1.Bitmap:
2.HyperLogLog
3.GEO:
LBS 애플리케이션용 GEO 데이터 유형
GEO의 기본 구조는 Sorted Set을 기반으로 구현되며 요소의 가중치에 따라 정렬될 수 있으며 범위 쿼리를 지원합니다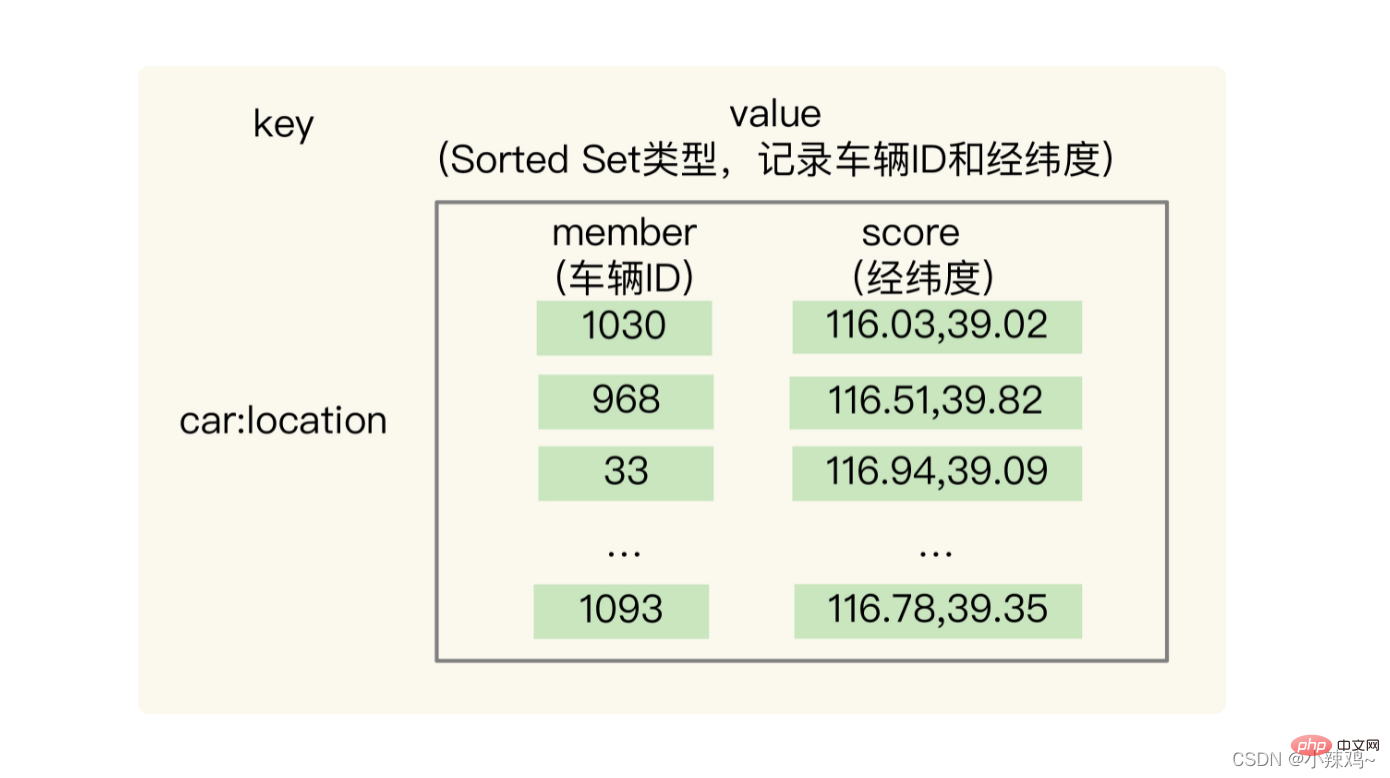
가중치 점수 sorted Set은 부동소수점 숫자(float type)이고, 경도와 위도가 2개의 숫자이므로 GeoHash 인코딩이 필요합니다.
GeoHash 인코딩은 "바이너리 간격, 간격 인코딩"을 통해 수행됩니다.
먼저 경도와 위도를 코드화된 형식으로 변환한 다음 크로스오버를 수행합니다. 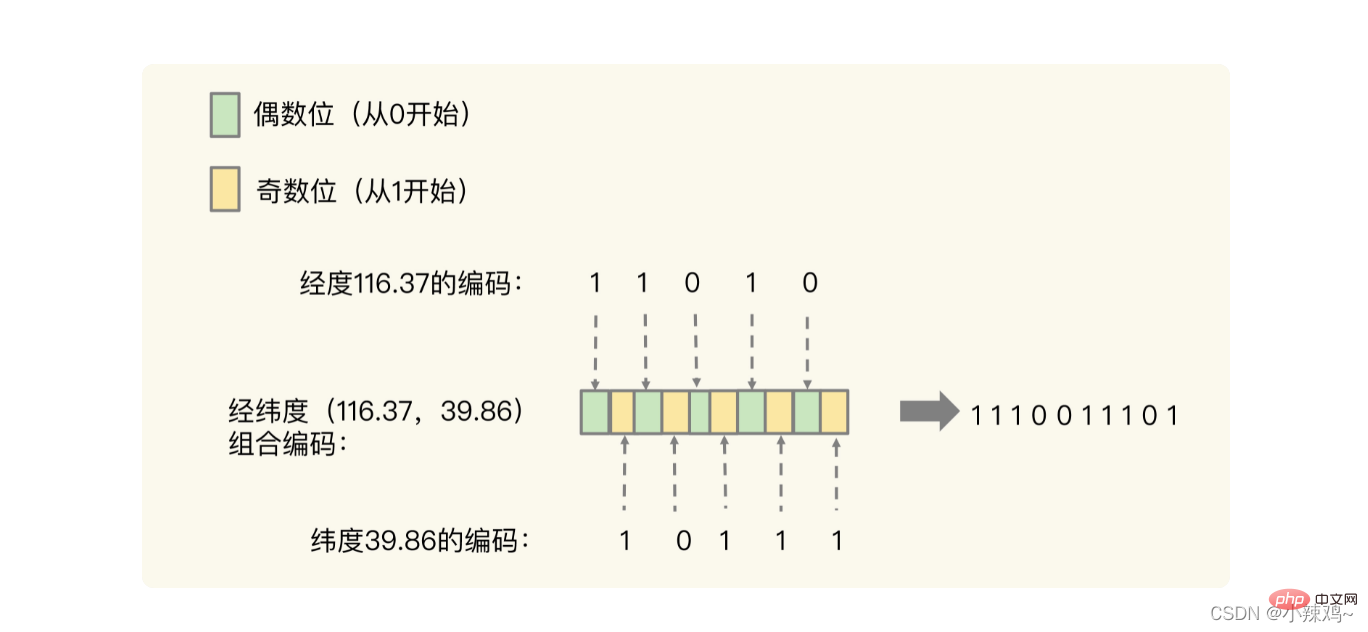
사실 크로스오버의 목적은 아래 그림과 같은 개념입니다. 크로스오버 후에는 실제로 사각형을 둘 사이에 위치시킬 수 있습니다. - 차원 공간. 유사한 코딩 값을 얻기 위해 Sorted Set 범위 쿼리를 사용합니다. 예를 들어 1110011101과 1111011101은 공간 위치에서 인접하지만 실제 사각형은 인접하지 않은 상황입니다. 따라서 이러한 상황이 발생하지 않도록 하려면 특정 경도와 위도 주변의 4~8개의 사각형을 동시에 쿼리할 수 있습니다.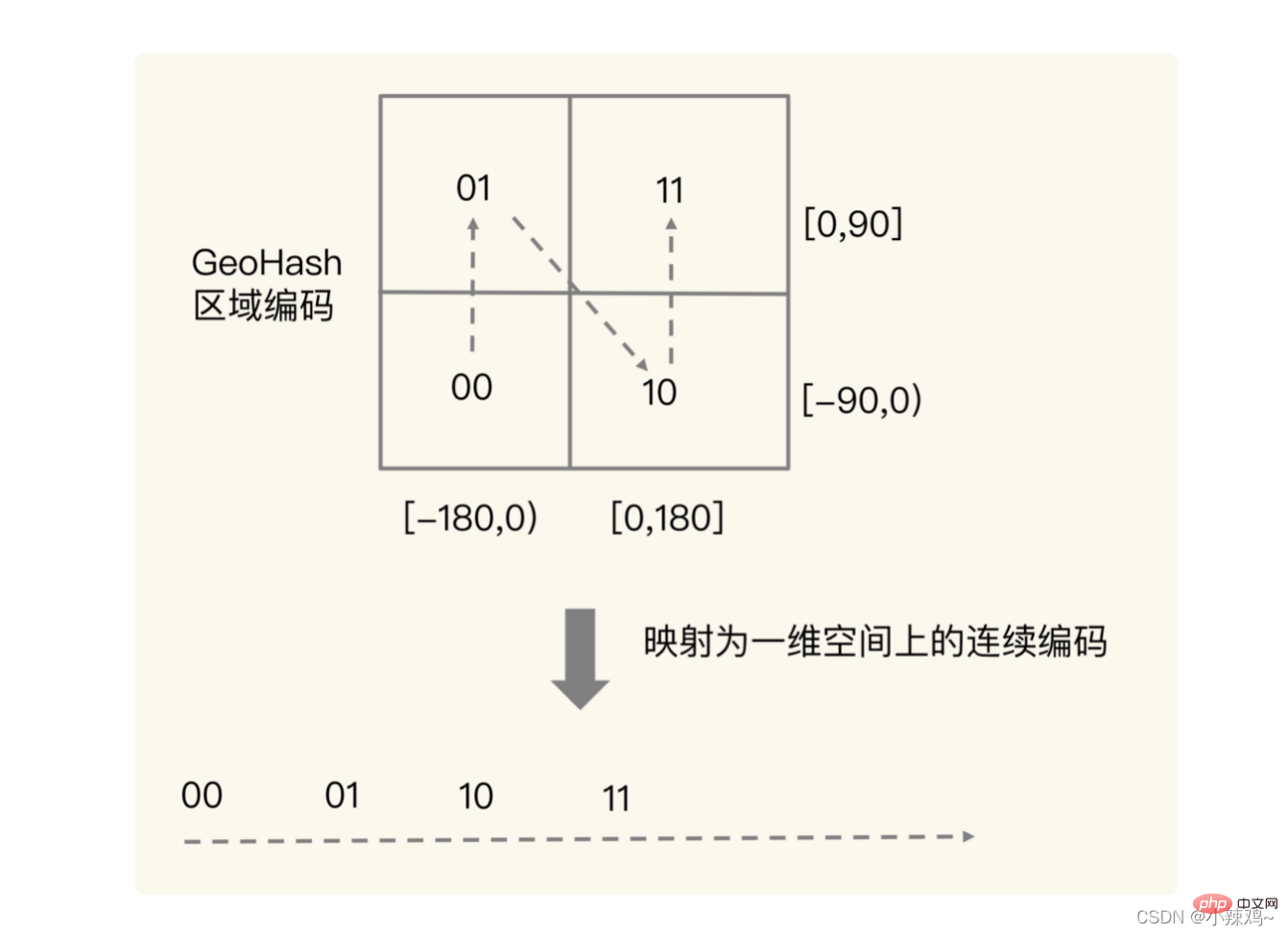
GEO 유형을 어떻게 작동하나요? 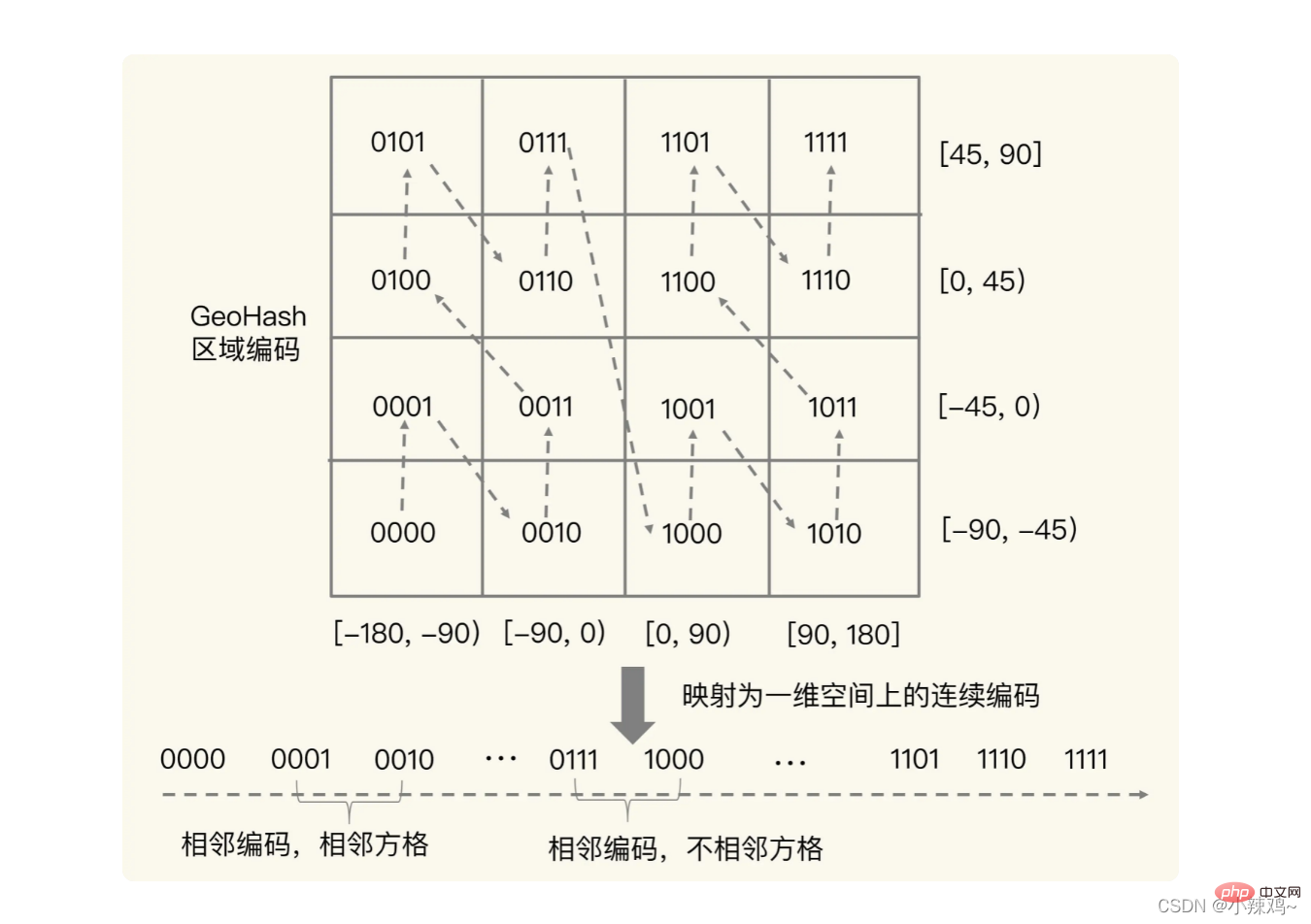 GEO 유형을 사용할 때 우리가 자주 사용하는 두 가지 명령은 GEOADD와 GEORADIUS입니다.
GEO 유형을 사용할 때 우리가 자주 사용하는 두 가지 명령은 GEOADD와 GEORADIUS입니다.
사용 방법: 차량 ID가 33이고 위도 및 경도 위치가 (116.034579, 39.030452)라고 가정하면 GEO 컬렉션을 사용하여 모든 차량의 위도 및 경도를 저장할 수 있습니다. ID 번호 33인 차량의 현재 경도 및 위도 위치를 GEO에 저장하려면 다음 명령만 실행하면 됩니다.
GEOADD cars:locations 116.034579 39.030452 33
GEORADIUS: 입력된 경도와 위도의 위치를 기준으로 이 경도와 위도를 중심으로 특정 범위 내의 다른 요소를 쿼리합니다.
데이터 유형을 사용자 정의하는 방법은 무엇입니까? redis의 기본 객체 구조에는 유형, 인코딩, lru 및 refcount, *ptr
이 포함됩니다. NewTypeObject라는 데이터 구조를 개발합니다. 특히 다음 네 단계가 있습니다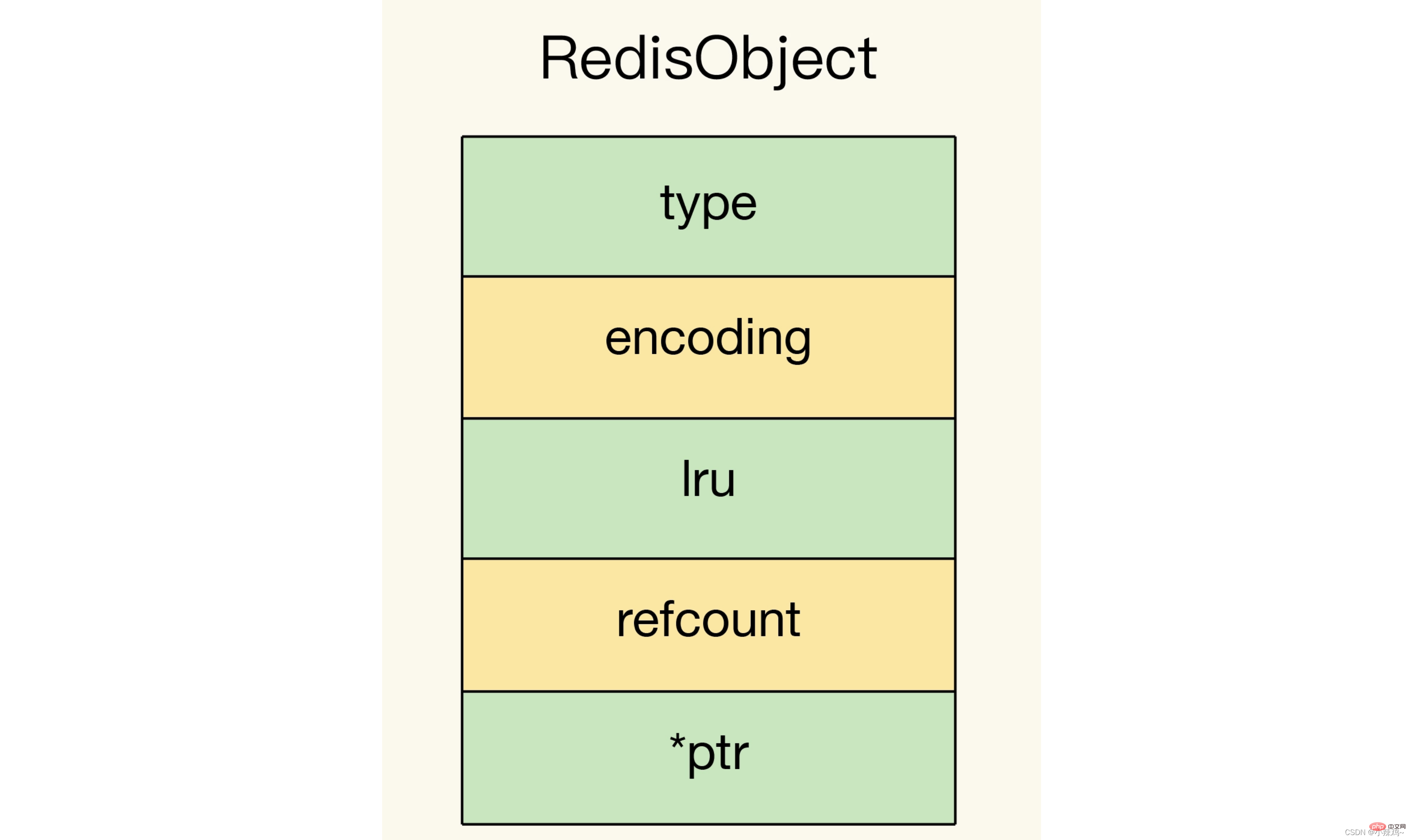
Redis에 시계열 데이터를 저장하는 방법은 무엇입니까?
1. 해시 및 정렬된 집합을 기반으로 저장: 왜 두 가지 데이터 구조를 기반으로 쿼리해야 합니까?
해시 유형은 시계열 단일 키 쿼리의 요구 사항을 충족하는 빠른 단일 키 쿼리를 구현할 수 있습니다. 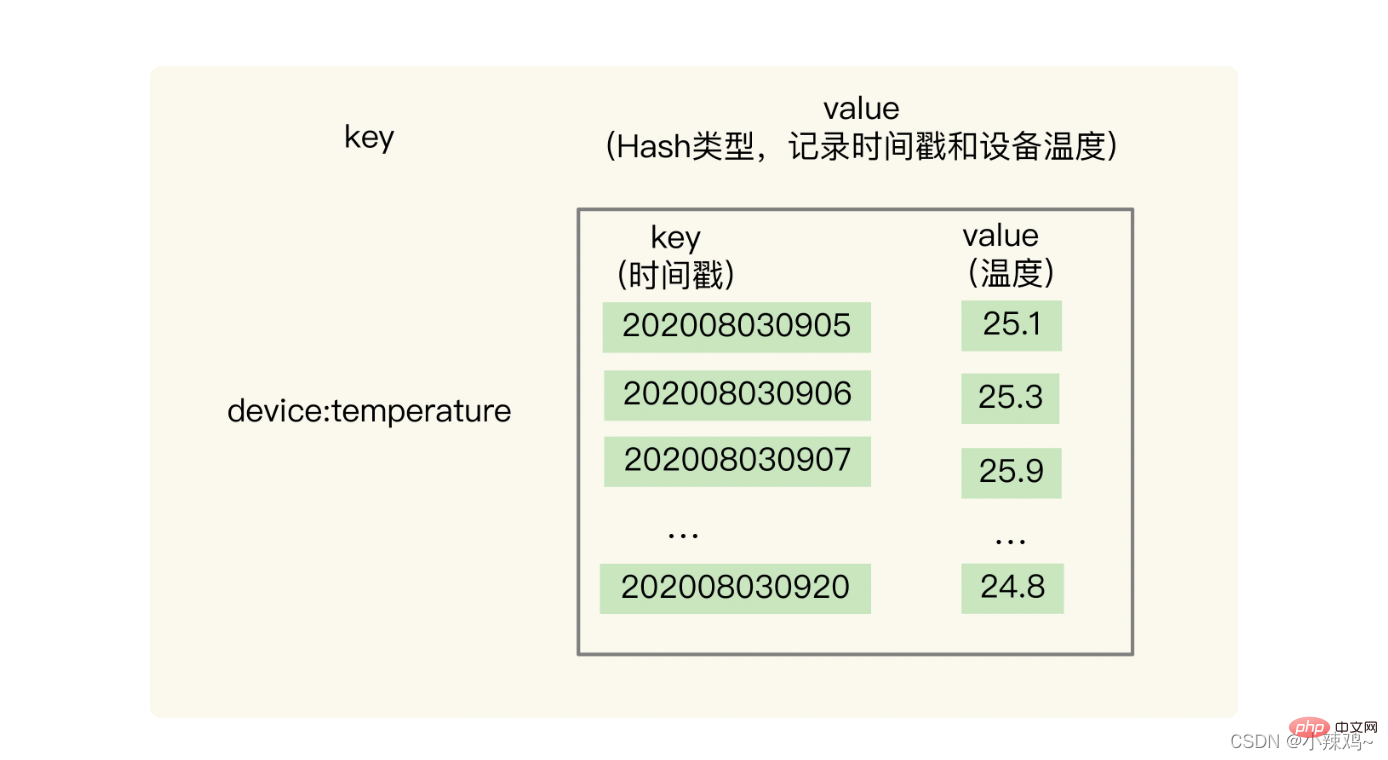
그러나 해시 유형은 타임스탬프 범위 쿼리를 지원하지 않는다는 단점이 있습니다. 요소의 가중치 점수에 따라 정렬되기 때문에 Sorted Set을 사용해야 합니다. 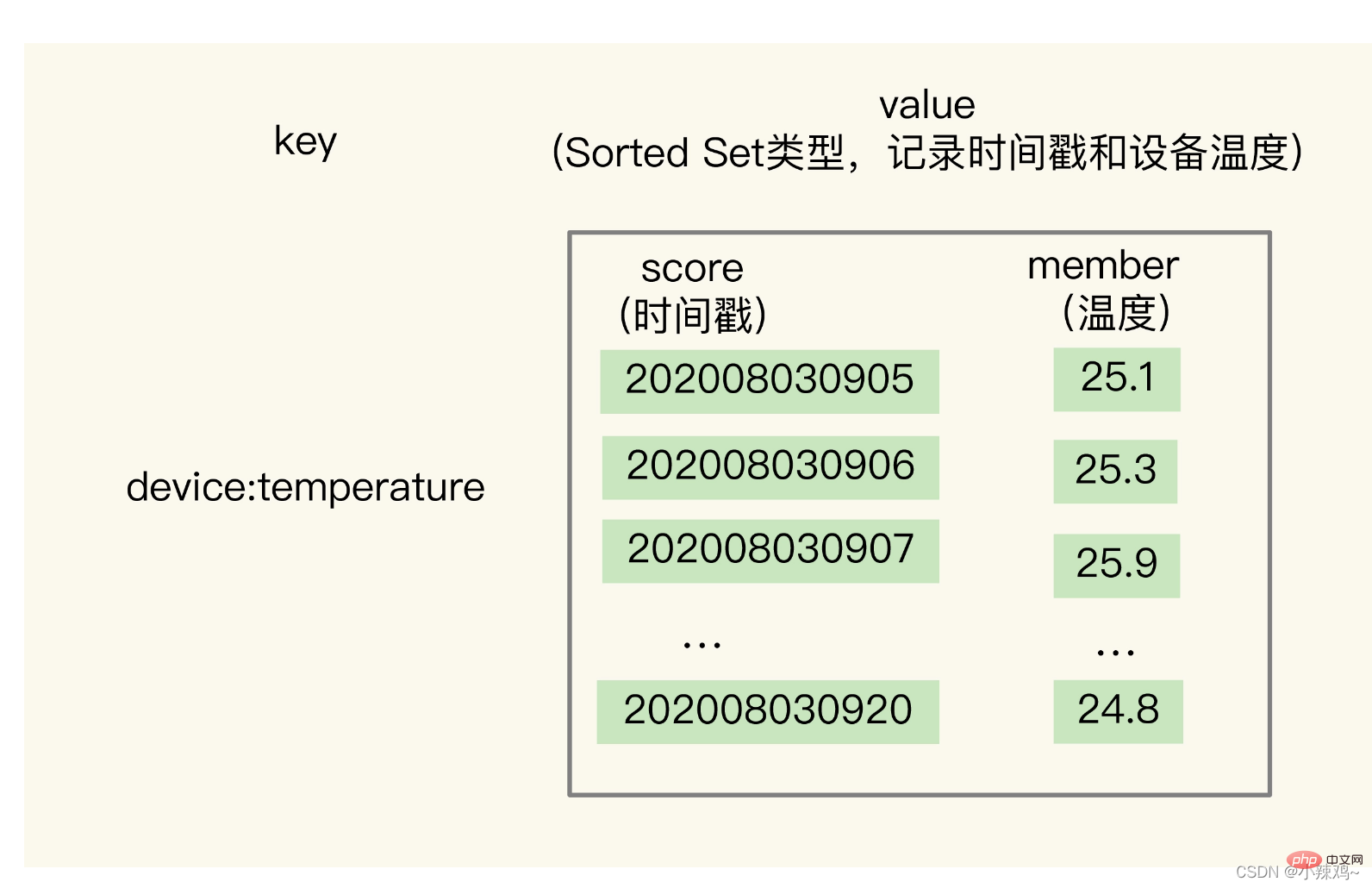
그렇다면 이 두 작업의 원자성을 어떻게 보장할 수 있을까요?
MULTI 및 EXEC라는 두 가지 명령을 전달해야 합니다.
MULTI는 이 명령을 받은 후 명령을 대기열에 넣습니다.
EXEC는 이 명령을 받은 후 대기열에 있는 명령 실행을 시작합니다. 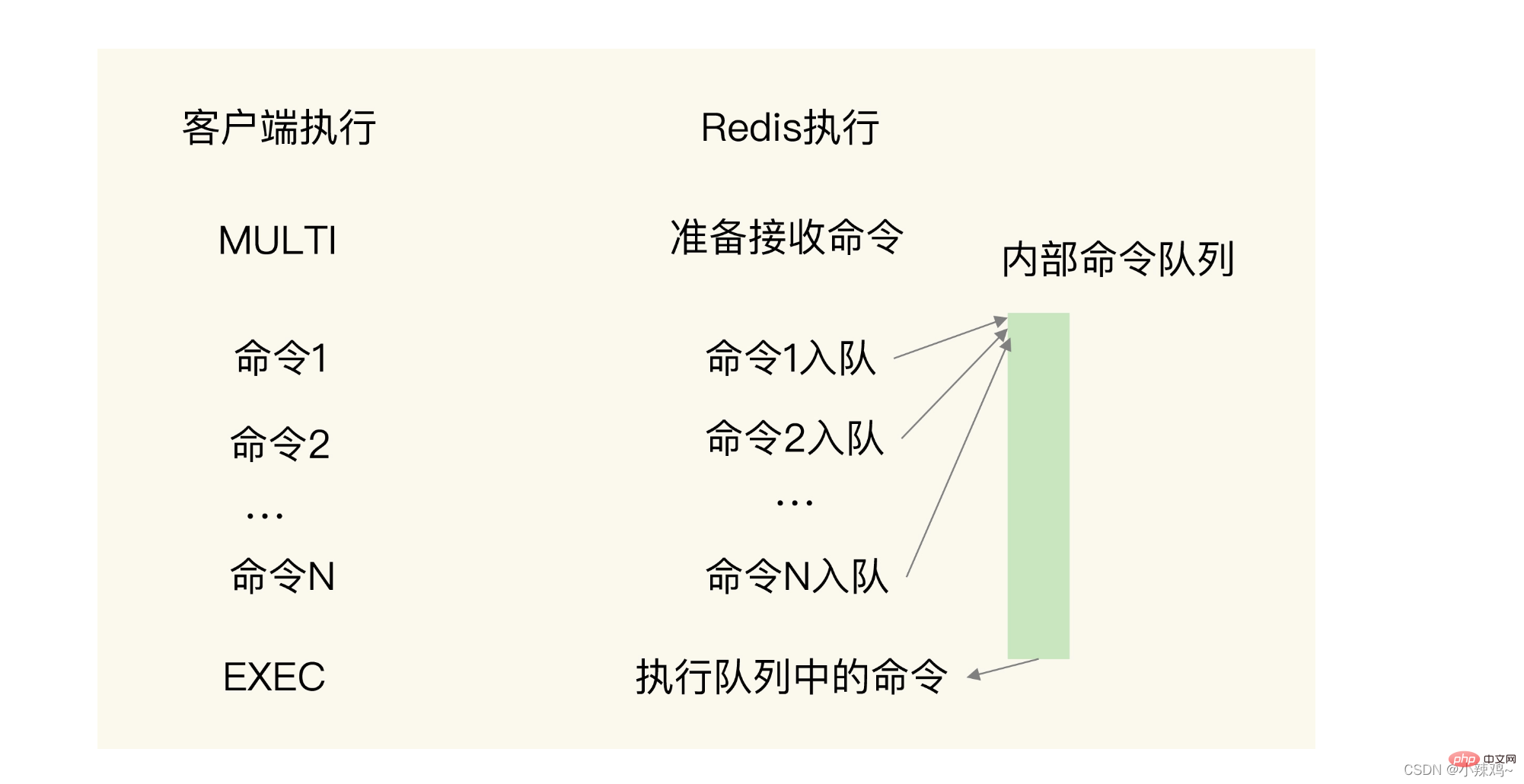 그러나 해시 및 정렬 세트 사용은 범위 쿼리만 지원하고 집계 계산은 지원하지 않는 경우. 클라이언트에서 집계 계산을 수행하면 많은 양의 네트워크 전송이 발생합니다. 따라서 RedisTimeSeries를 통해 Redis에서 집계 계산을 수행할 수 있습니다.
그러나 해시 및 정렬 세트 사용은 범위 쿼리만 지원하고 집계 계산은 지원하지 않는 경우. 클라이언트에서 집계 계산을 수행하면 많은 양의 네트워크 전송이 발생합니다. 따라서 RedisTimeSeries를 통해 Redis에서 집계 계산을 수행할 수 있습니다.
위 내용은 Redis 데이터 구조 지식을 그림과 텍스트로 자세히 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!