
Redis 핫 데이터 문제에 대한 솔루션을 함께 분석해 보겠습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-04-20 13:12:175269검색
이 기사는 Redis에 대한 관련 지식을 제공하며, Redis 핫키 큰 가치 솔루션과 관련된 문제를 주로 소개합니다. 모두에게 도움이 되기를 바랍니다.

추천 학습: Redis 비디오 튜토리얼
Redis 정보 핫 데이터 및 빅 키 빅 가치 질문은 높은 수준의 질문도 하기 쉬우므로 한 번에 끝내고 면접관이 말문이 막히게 하는 것이 좋습니다. 개인적으로 내 업무 경험에 따르면 핫스팟은 눈사태보다 직장에서 발생할 가능성이 더 높습니다. 그러나 대부분의 경우 핫스팟은 충분히 뜨겁지 않으며 사전에 경고하고 해결됩니다. 그러나 일단 이 문제는 제어할 수 없습니다. , 발생한 온라인 문제로 인해 귀하는 올해 실적의 최하위에 놓이게 될 것입니다. 알겠습니다. 헛소리는 그만하고 본론으로 들어가겠습니다.
일반적인 상황에서 Redis 클러스터의 데이터는 각 노드에 균등하게 분산되고 요청은 각 샤드에 균등하게 분산됩니다. 그러나 외부 크롤러, 공격, 핫 상품 등과 같은 일부 특수한 시나리오에서는 가장 일반적입니다. 연예인들이 웨이보에서 이혼을 발표하고, 사람들이 몰려들어 메시지를 남기는 바람에 웨이보의 댓글 기능이 이렇게 짧은 시간에 너무 많아 특정 키에 대한 방문 횟수가 너무 많아졌고, 동일한 데이터가 발생했습니다. 샤드에서 샤드의 높은 부하로 인해 병목 현상이 발생하여 눈사태와 같은 일련의 문제가 발생합니다.
1. 인터뷰어: 프로젝트에서 Redis 핫 데이터 문제를 겪은 적이 있나요? 일반적인 원인은 무엇입니까?
문제 분석: 지난번 그룹 인터뷰 알리 p7에서 빅 보스를 들었을 때 이 질문을 받았습니다. 난이도 지수는 별 다섯 개로 저 같은 초보자에게는 정말 플러스입니다.
답변: 핫 데이터 문제에 대해 말씀드릴 것이 있습니다. 저는 Redis를 처음 배울 때부터 이 문제를 알고 있었기 때문에 사용할 때 의도적으로 피하고 절대로 구멍을 뚫지 않을 것입니다. 핫스팟 데이터의 가장 큰 문제는 Redis 클러스터 로드 불균형(즉, 데이터 불균형)으로 인해 발생하는 장애입니다. 이러한 문제는 Redis 클러스터에 치명적입니다.
먼저 Reids 클러스터 로드 불균형 실패의 주요 원인에 대해 이야기해 보겠습니다.
- 액세스 볼륨이 높은 키, 즉, 과거 유지 관리 경험에 따르면 키로 액세스한 QPS가 1000을 초과하면 인기상품, 핫이슈 등 세심한 주의를 기울여야 합니다.
- 큰 가치 일부 키 액세스 QPS는 높지 않지만 큰 값으로 인해 네트워크 카드 로드가 크고 네트워크 카드 트래픽이 가득 차서 단일 시스템에서 기가비트/초 및 IO 오류가 발생할 수 있습니다.
- 핫스팟 키 + 빅밸류가 동시에 존재, 서버 킬러.
그러면 단축키 또는 큰 값으로 인해 어떤 오류가 발생합니까?
- 데이터 왜곡 문제: 큰 값은 클러스터의 여러 노드에서 데이터 분포가 고르지 않게 되어 많은 수의 데이터 왜곡 문제가 발생합니다. 매우 높은 읽기-쓰기 비율은 다음과 같습니다. 동일한 Redis 서버에서는 Redis의 로드가 심각하게 증가하고 충돌이 발생하기 쉽습니다.
- QPS 왜곡: 샤드 전반에 걸쳐 QPS가 고르지 않습니다.
- 값이 크면 Redis 서버 버퍼가 부족하여 가져오기 시간 초과가 발생합니다.
- 값이 너무 커서 컴퓨터실의 네트워크 카드 트래픽이 부족합니다.
- Redis 캐시 오류는 데이터베이스 계층 붕괴의 연쇄 반응으로 이어집니다.
2. 인터뷰어: 실제 프로젝트에서 핫 데이터 이슈를 어떻게 정확하게 찾아내나요?
답변: 이 문제에 대한 해결책은 비교적 광범위합니다. 다양한 비즈니스 시나리오에 따라 다릅니다. 예를 들어 회사에서 프로모션 활동을 조직하는 경우 프로모션에 참여하는 제품을 미리 계산하는 방법이 있어야 합니다. 이 시나리오에서는 추정 방법을 사용할 수 있습니다. 긴급 상황과 불확실성이 있는 경우 Redis는 핫스팟 데이터를 자체적으로 모니터링합니다. 요약하자면:
-
미리 알아두는 방법:
사업에 따라서는 인신통계나 시스템 통계가 판촉물, 핫토픽, 명절 토픽, 기념일 활동 등 핫데이터가 될 수도 있습니다. -
Redis 클라이언트 수집 방법:
호출자는 키 요청 수를 세어 계산하지만 키 수를 예측할 수 없으며 코드가 방해가 됩니다.public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) { //从参数中获取key String key = analysis(args); //计数 counterKey(key); //ignore } -
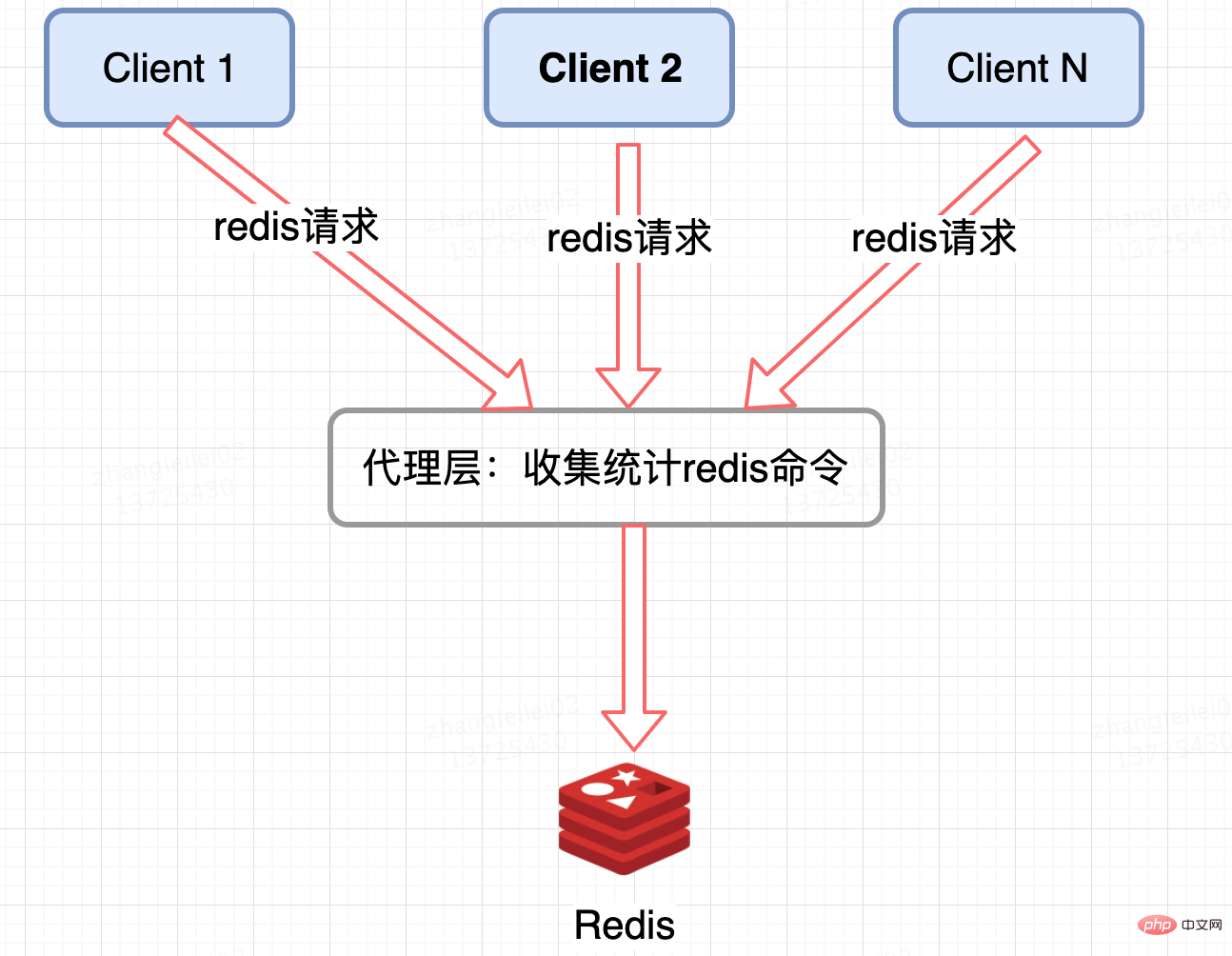
Redis 클러스터 프록시 계층 통계:
Twemproxy 및 codis와 같은 프록시 기반 Redis 분산 아키텍처는 통합된 입구를 가지며 프록시 계층에서 수집 및 보고될 수 있습니다. 그러나 모든 Redis 클러스터 아키텍처가 분명한 것은 아닙니다. 프록시가 있습니다.
-
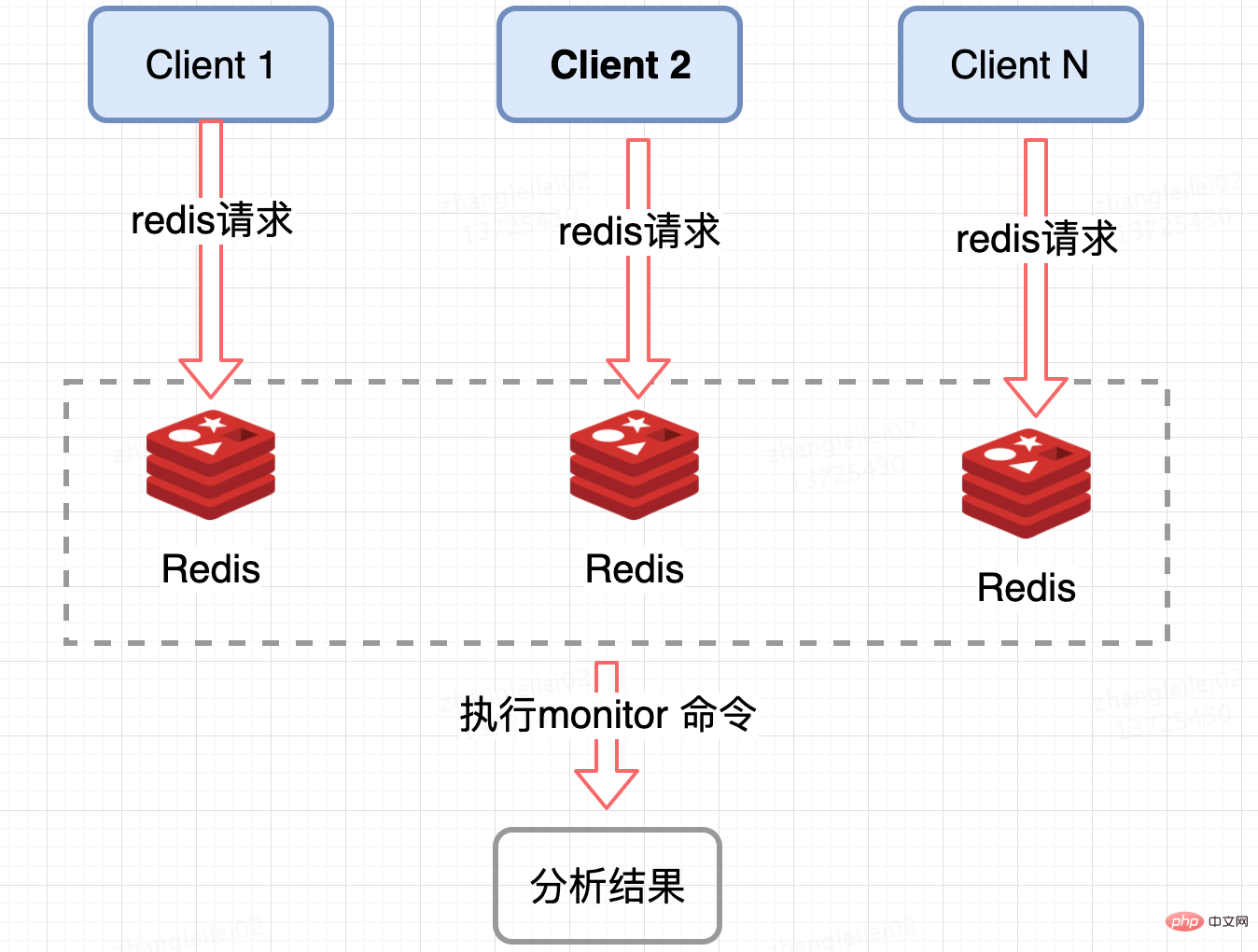
Redis 서버 컬렉션:
단일 Redis 샤드의 QPS를 모니터링하고, QPS가 어느 정도 기울어진 노드를 모니터링하여 핫스팟 키를 얻을 수 있는 Redis는 특정 Redis 노드를 계산할 수 있는 모니터 명령을 제공합니다. 모든 명령이 실행되고 핫스팟 키를 분석합니다. 높은 동시성 조건에서는 메모리 폭발 및 Redis 성능의 숨겨진 위험이 있으므로 이 방법은 단기간에만 사용할 수 있습니다. 하나의 Redis 노드의 핫스팟 키. 클러스터 요구 사항의 경우 요약 통계는 비즈니스 관점에서 좀 더 까다롭습니다.
위에서 언급한 4가지 방법은 모두 업계에서 흔히 사용하는 방법인데 Redis 소스코드를 공부하다 새로운 아이디어를 얻었습니다. 유형 5: Redis 소스 코드를 수정합니다.
-
Redis 소스 코드 수정: (소스 코드를 읽은 후 아이디어 생각하기)
Redis4.0이 LFU 기반 핫스팟 키 검색 메커니즘을 포함하여 많은 새로운 기능을 제공한다는 것을 알았습니다. 새로운 기능을 사용하면 이를 기반으로 핫스팟 키의 통계를 실현할 수 있습니다. 이것은 단지 내 개인적인 생각일 뿐입니다.
인터뷰어의 심리: 그 청년은 꽤 사려 깊고 마음이 넓으며, 심지어 소스 코드 수정에도 관심을 쏟습니다. 저는 그런 야망이 없습니다. 우리 팀에는 이런 사람이 필요해요.
(문제를 발견하고, 문제를 분석하고, 문제를 해결하고, 면접관의 질문을 기다리지 않고 핫 데이터 문제를 해결하는 방법을 직접 알려주십시오. 핵심 내용입니다.)
3. 핫 데이터 문제 해결 방법
답변: 핫 데이터 문제를 관리하는 방법과 관련하여 우리는 이 문제를 해결하기 위해 주로 두 가지 측면을 고려합니다. 첫 번째는 데이터 샤딩입니다. 두 번째는 마이그레이션 격리입니다.
요약 요약:
-
키 분할:
현재 키의 유형이 해시 유형과 같은 보조 데이터 구조인 경우. 해시 요소 수가 많은 경우 현재 해시를 분할하여 단축키를 여러 개의 새 키로 분할하고 다른 Redis 노드에 배포하여 부담을 줄일 수 있습니다. -
단축키 마이그레이션:
Redis 클러스터를 예로 들면, 핫스팟 키가 있는 슬롯을 별도로 새로운 Redis 노드로 마이그레이션할 수 있습니다. 이렇게 하면 이 핫스팟 키의 QPS가 매우 높더라도 전체의 다른 비즈니스에 영향을 주지 않습니다. 클러스터를 사용자 정의하고 개발할 수도 있습니다. 이 솔루션에는 더 많은 복사본이 필요합니다. 핫스팟 키 전류 제한: -
읽기 명령의 경우 핫스팟 키를 마이그레이션한 다음 슬레이브 노드를 추가하여 문제를 해결할 수 있습니다. 쓰기 명령의 경우 이 핫스팟 키를 별도로 대상으로 지정하여 전류를 제한할 수 있습니다.
로컬 캐시 늘리기: -
데이터 일관성이 그다지 높지 않은 기업의 경우 비즈니스 시스템의 로컬 캐시에 핫스팟 키를 캐시할 수 있습니다. 핫스팟 키는 비즈니스 측의 로컬 메모리에 있기 때문에 원격 IO가 필요하지 않습니다. 부르다. 그러나 데이터가 업데이트되면 비즈니스 데이터와 Redis 데이터 간에 불일치가 발생할 수 있습니다.
인터뷰어: 답변을 아주 잘 해주시고, 아주 종합적으로 생각해 주셨네요.
문제 분석:
핫키라는 큰 개념에 비해 Redis는 단일 스레드에서 실행되므로 작업 값이 크면 부정적인 영향을 미친다는 개념을 이해하는 것이 좋습니다. Redis는 Key-Value 구조의 데이터베이스이기 때문에 전체 Redis의 응답 시간에 영향을 미칩니다. 값이 크다는 것은 단일 값이 많은 양의 메모리를 차지한다는 것을 의미합니다. Redis 클러스터에 가장 직접적인 영향을 미치는 것은 데이터 왜곡입니다.
답변:(나를 괴롭히고 싶나요? 준비되어 있습니다.) 먼저 회사의 인프라가 제공하는 경험 가치에 따라 다음과 같이 나눌 수 있습니다.
참고 : (경험치는 표준이 아니며, 클러스터 운영 및 유지관리 담당자가 온라인 사례를 장기간 관찰하여 정리한 것임)- Big
- : 문자열 유형 값 > 10K, 세트 내 , list, hash, zset 및 기타 컬렉션 데이터 유형 요소 수 > 1000. 초대형:
- 문자열 유형 값 > 100K, set, list, hash, zset 및 기타 컬렉션 데이터 유형의 요소 수 > 10000. Redis는 단일 스레드로 실행되기 때문에 작업의 값이 매우 크면 전체 Redis의 응답 시간에 부정적인 영향을 미치므로 분할이 가능하다면 분할할 수 있습니다. 다음은 몇 가지 일반적인 분할 계획입니다.
- 一个较大的 key-value 拆分成几个 key-value ,将操作压力平摊到多个 redis 实例中,降低对单个 redis 的 IO 影响
- 将分拆后的几个 key-value 存储在一个 hash 中,每个 field 代表一个具体的属性,使用 hget,hmget 来获取部分的 value,使用 hset,hmset 来更新部分属性。
- hash、set、zset、list 中存储过多的元素
类似于场景一中的第一个做法,可以将这些元素分拆。
以 hash 为例,原先的正常存取流程是:
hget(hashKey, field); hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000,每次存取的时候,先在本地计算 field 的 hash 值,模除 10000,确定该 field 落在哪个 key 上,核心思想就是将 value 打散,每次只 get 你需要的。
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value); hget(newHashKey, field)
推荐学习:Redis学习教程
위 내용은 Redis 핫 데이터 문제에 대한 솔루션을 함께 분석해 보겠습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!