
파이썬 예제 상세한 xpath 분석

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-03-31 12:18:452932검색
이 기사는 xpath와 관련된 문제를 주로 소개하는 python에 대한 관련 지식을 제공합니다. XML 경로 언어의 전체 이름인 XPath는 XML 문서에서 정보를 찾는 언어입니다. 모든 사람.

추천 학습: python tutorial
XPath는 XML 경로 언어의 전체 이름입니다. 원래는 XML 문서에서 정보를 검색하는 데 사용되는 언어입니다. 또한 HTML 문서 검색에도 적합합니다. XPath의 선택 기능은 매우 간결하며, 문자열, 값 및 시간에 대한 100개 이상의 내장 기능도 제공합니다. 노드 및 시퀀스 처리 등, 우리가 찾으려는 거의 모든 노드를 사용하여 선택할 수 있습니다. 구문 분석된 페이지 소스 데이터가 이 개체에 로드됩니다.
etree 개체에서 xpath 메서드를 호출하고 이를 xpath 표현식과 결합하여 레이블 위치 지정 및 콘텐츠 캡처를 달성합니다.
-
환경 설치
pip install lxml
lxml은 Python의 구문 분석 라이브러리로, HTML 및 XML 구문 분석을 지원하고, XPath 구문 분석 방법을 지원하며 구문 분석 효율성이 매우 높습니다. etree 개체를 인스턴스화하는 방법
1. html 문서의 소스 코드 데이터는 etree 객체:
etree. parse(filePath)#你的文件路径
2에 로드됩니다. 인터넷에서 얻은 소스 코드 데이터는 object
etree.HtML('page_ text')#page_ text互联网中响应的数据
xpath 표현식
ExpressionDescription에 로드될 수 있습니다.| nodename | 이 노드의 모든 하위 노드 선택 |
|---|---|
| 은 루트 노드에서 시작한다는 의미입니다. 수준을 나타냅니다. | |
| 은 여러 레벨을 나타냅니다. 이는 위치 지정이 모든 위치에서 시작됨을 의미할 수 있습니다. | |
| @* | |
| [@attrib] | |
| [@attrib='value' ] | |
| [태그] | |
| [tag='text'] | |
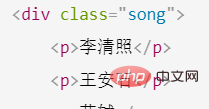
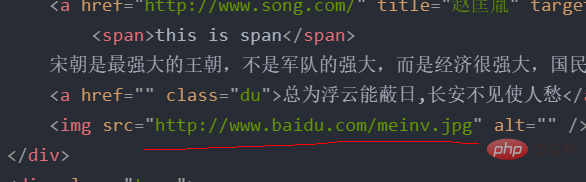
对上面表达式的实例详解这是一个HTML的文档 <meta> <title>测试bs4</title> <p> </p><p>百里守约</p> <p> </p><p>李清照</p> <p>王安石</p> <p>苏轼</p> <p>柳宗元</p> <a> <span>this is span</span> 宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a> <a>总为浮云能蔽日,长安不见使人愁</a> <img src="/static/imghwm/default1.png" data-src="http://www.baidu.com/meinv.jpg" class="lazy" alt="파이썬 예제 상세한 xpath 분석" > <p> </p>
从浏览器中打开是这样的 子节点和子孙节点的定位 / 和 //先来看子节点和子孙节点,我们从上往下找p这个节点,可以看到p的父节点是body,body父节点是html import requestsfrom lxml import etree
tree = etree.parse('test.html')r1=tree.xpath('/html/body/p') #直接从上往下挨着找节点r2=tree.xpath('/html//p')#跳跃了一个节点来找到这个p节点的对象r3=tree.xpath('//p')##跳跃上面所有节点来寻找p节点的对象r1,r2,r3>>([<element>,
<element>,
<element>],
[<element>,
<element>,
<element>],
[<element>,
<element>,
<element>])</element></element></element></element></element></element></element></element></element>
属性定位如果我只想要p里面song这一个标签,就可以对其属性定位 r4=tree.xpath('//p[@class="song"]')r4>>>[<element>]</element>
索引定位如果我只想获得song里面的苏轼的这个标签 tree.xpath('//p[@class="song"]/p')>>[<element>,
<element>,
<element>,
<element>]</element></element></element></element>
这个单独返回的苏轼的p标签,要注意的是这里的索引不是从0开始的,而是1 tree.xpath('//p[@class="song"]/p[3]')[<element>]</element>
取文本比如我想取杜牧这个文本内容 tree.xpath('//p[@class="tang"]//li[5]/a/text()')>>['杜牧']
可以看到这个返回的是一个列表,如果我们想取里面的字符串,可以这样 tree.xpath('//p[@class="tang"]//li[5]/a/text()')[0]杜牧
看一个更直接的,//li 直接定位到 li这个标签,//text()直接将这个标签下的文本提取出来。但要注意,这样会把所有的li标签下面的文本提取出来,有时候你并不想要的文本也会提取出来,所以最好还是写详细一点,如具体到哪个p里的li。 tree.xpath('//li//text()')['清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村',
'秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山',
'岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君',
'杜甫',
'杜牧',
'杜小月',
'度蜜月',
'凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘']
取属性比如我想取下面这个属性 tree.xpath('//p[@class="song"]/img/@src')['http://www.baidu.com/meinv.jpg']
或者如果我想取所有的href这个属性,可以看到tang和song的所有href属性 tree.xpath('//@href')['http://www.song.com/',
'',
'http://www.baidu.com',
'http://www.163.com',
'http://www.126.com',
'http://www.sina.com',
'http://www.dudu.com',
'http://www.haha.com']
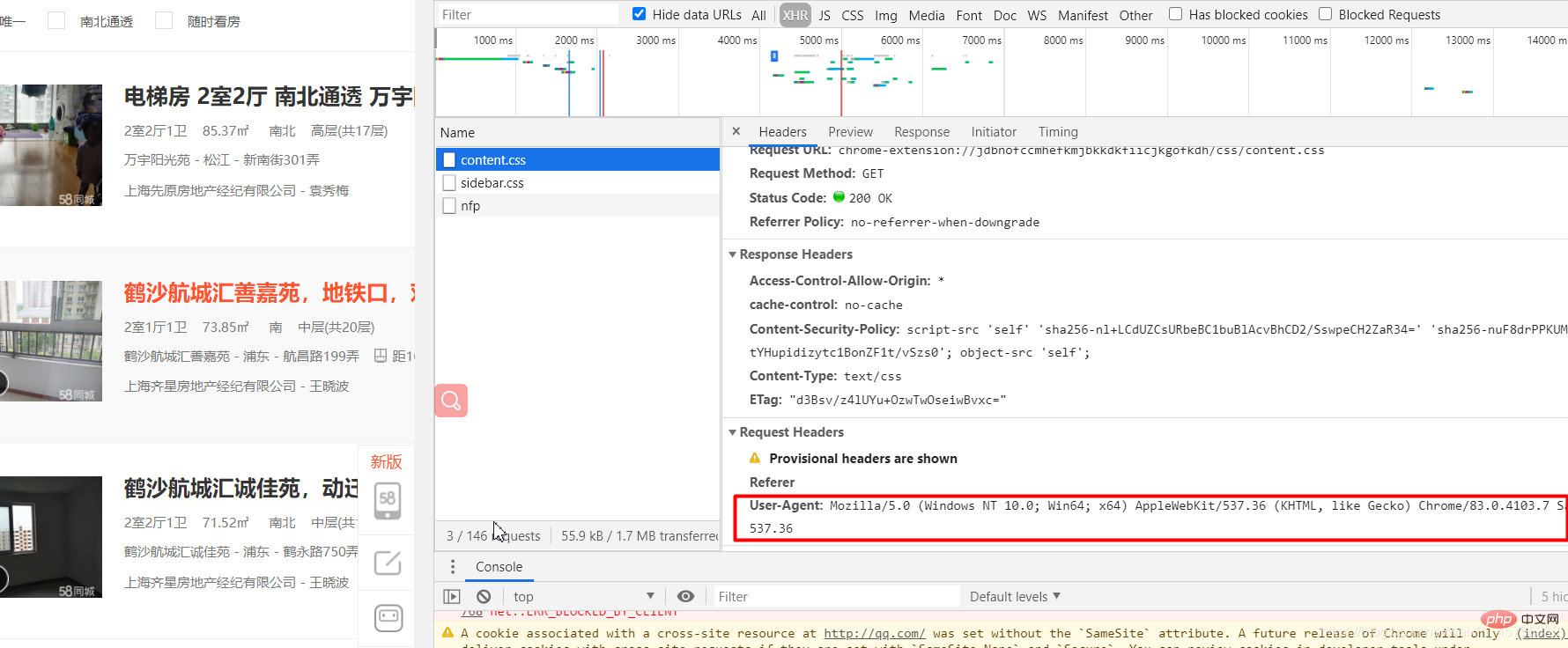
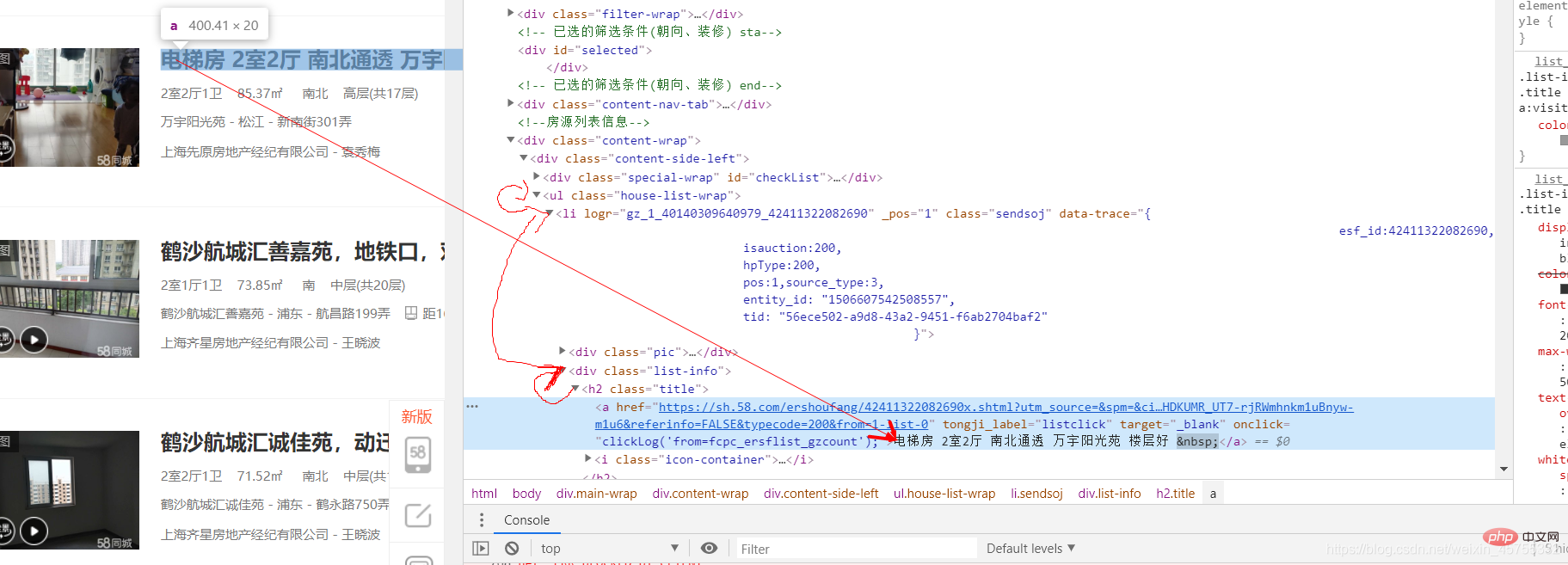
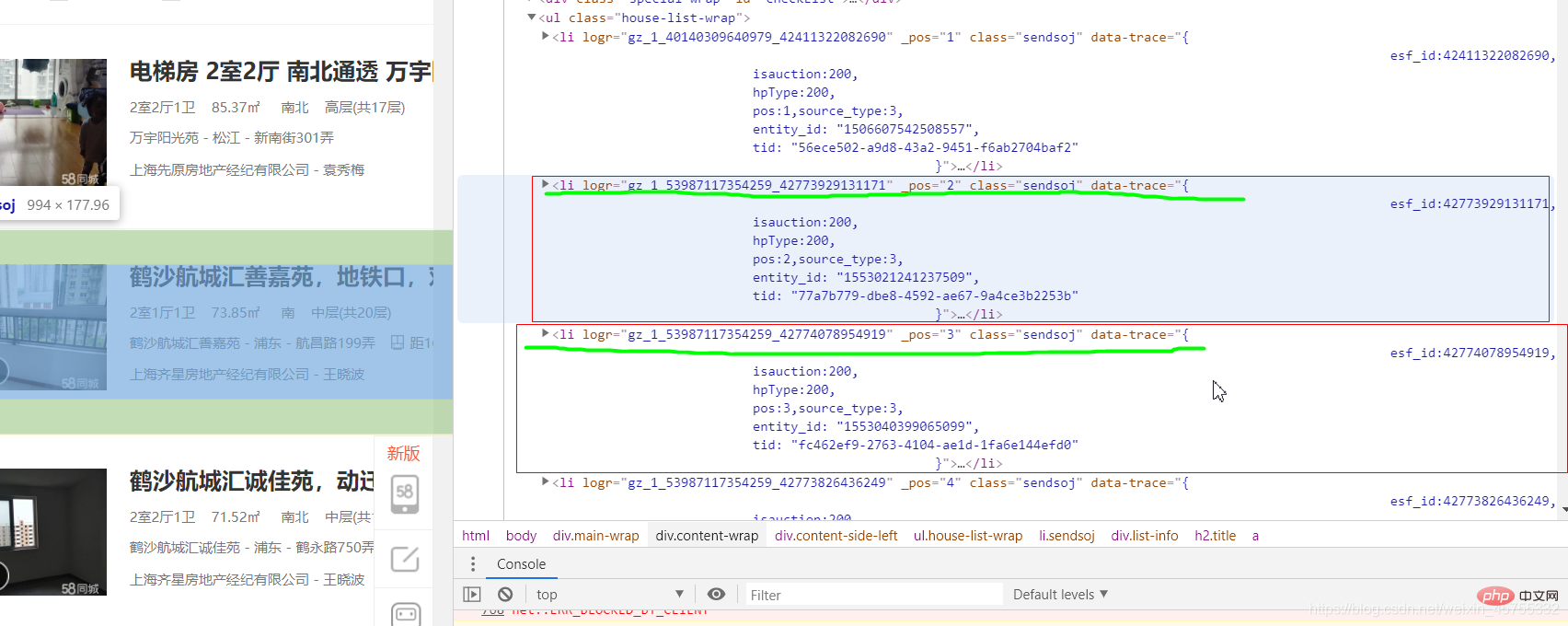
爬虫实战之58同城房源信息#导入必要的库import requestsfrom lxml import etree#URL就是网址,headers看图一url='https://sh.58.com/ershoufang/'headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.7 Safari/537.36'}#对网站发起请求page_test=requests.get(url=url,headers=headers).text# 这里是将从互联网上获取的源码数据加载到该对象中tree=etree.HTML(page_test)#先看图二的解释,这里li有多个,所里返回的li_list是一个列表li_list=tree.xpath('//ul[@class="house-list-wrap"]/li')#这里我们打开一个58.txt文件来保存我们的信息fp=open('58.txt','w',encoding='utf-8')#li遍历li_listfor li in li_list:
#这里 ./是对前面li的继承,相当于li/p...
title=li.xpath('./p[2]/h2/a/text()')[0]
print(title+'\n')
#把文件写入文件
fp.write(title+'\n')fp.close()
图一:
推荐学习:python教程 |






위 내용은 파이썬 예제 상세한 xpath 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!