
Python 데이터 처리 및 시각화에 대한 심층적인 이해

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-03-21 17:43:432617검색
이 글은 NumPy의 사전 사용, Matplotlib 패키지 사용, 데이터 통계의 시각적 표시 등 데이터 처리 및 시각화와 관련된 문제를 주로 소개하는 python에 대한 관련 지식을 제공합니다. 모두에게 도움이 되기를 바랍니다.

추천 학습: python tutorial
1. NumPy의 초기 사용
Table은 데이터의 일반적인 표현이지만 기계가 이해할 수 없는, 즉 인식할 수 없는 데이터이므로 조정이 필요합니다. 테이블의 형태.
일반적으로 사용되는 기계 학습 표현은 데이터 매트릭스입니다. 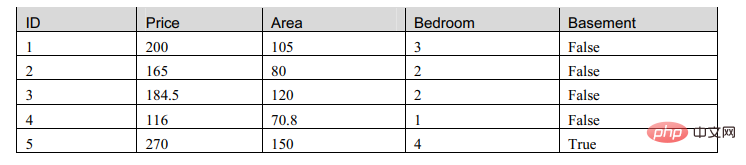
이 표를 살펴본 결과 행렬에 두 가지 유형의 속성이 있음을 발견했습니다. 하나는 숫자 유형이고 다른 하나는 부울 유형입니다. 이제 이 테이블을 설명하는 모델을 구축하겠습니다.
# 数据的矩阵化import numpy as np data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False], [4,116,70.8,1,False],[5,270,150,4,True]])row = 0for line in data: row += 1print( row )print(data.size)print(data)
여기서 코드의 첫 번째 줄은 NumPy를 도입하고 이름을 np로 바꾸는 것을 의미합니다. 두 번째 줄에서는 NumPy의 mat() 메서드를 사용하여 데이터 행렬을 만들고, row는 행 수를 계산하기 위해 도입된 변수입니다.
여기서의 크기는 5*5의 테이블을 의미합니다. 데이터를 직접 인쇄하여 볼 수 있습니다. 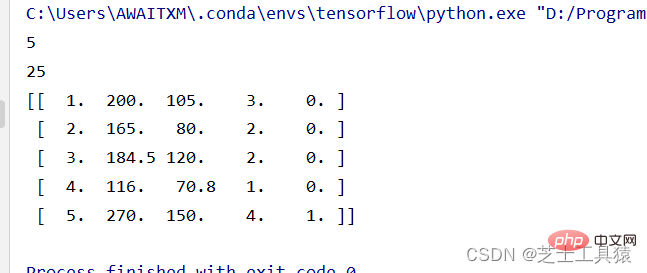
2. Matplotlib 패키지 사용 - 그래픽 데이터 처리
두 번째 열은 다음과 같습니다. 주택 가격의 차이를 직관적으로 확인하기가 쉽지 않기 때문에(숫자만 있기 때문에) 그려보시길 바랍니다(수치적 차이와 이상치를 연구하는 방법은 데이터의 분포를 그리는 것입니다):
import numpy as npimport scipy.stats as statsimport pylab data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False], [4,116,70.8,1,False],[5,270,150,4,True]])coll = []for row in data: coll.append(row[0,1])stats.probplot(coll,plot=pylab)pylab.show()
이 코드의 결과는 다음과 같은 그림을 생성하는 것입니다.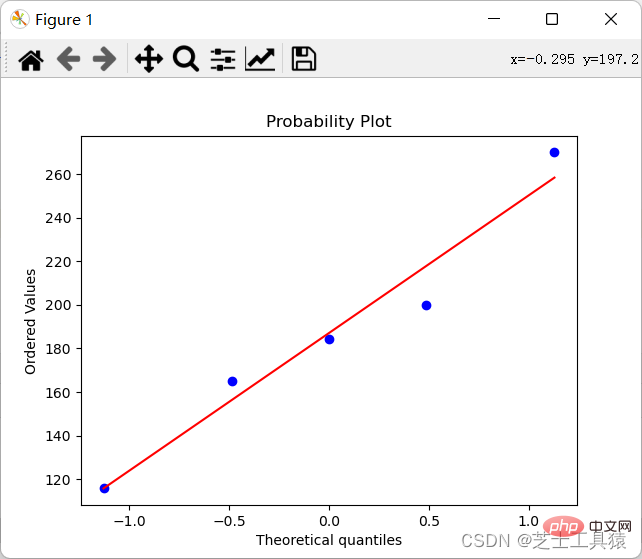
차이를 명확하게 볼 수 있습니다.
좌표 차트의 요구 사항은 다양한 행과 열을 통해 데이터의 특정 값을 표시하는 것입니다.
물론 좌표 다이어그램을 표시할 수도 있습니다. 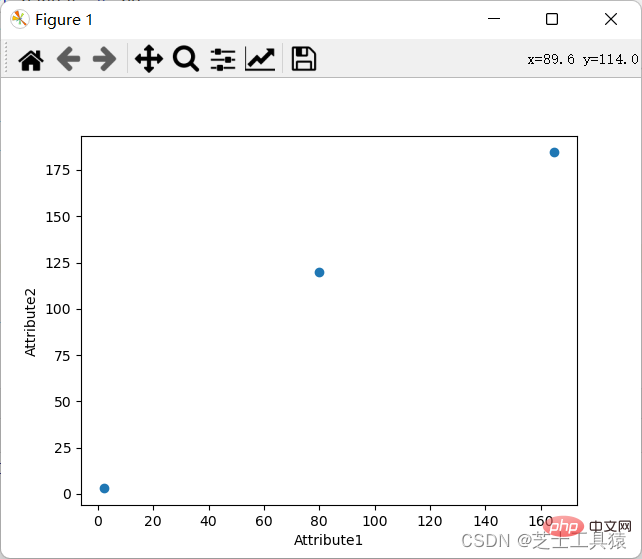
3. 딥러닝 이론적 방법 – 유사성 계산(생략 가능)
유사성 계산에는 여러 가지 방법이 있습니다. 가장 일반적으로 사용되는 두 가지 방법을 선택합니다. 즉 유클리드 측지 유사성 및 코사인 유사성 계산입니다.
1. 유클리드 거리를 기반으로 한 유사성 계산
유클리드 거리는 3차원 공간에서 두 점 사이의 실제 거리를 나타내는 데 사용됩니다. 실제로 우리는 모두 공식을 알고 있지만 이름은 거의 들어보지 못합니다. 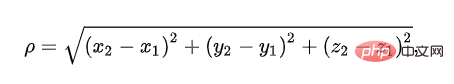
그런 다음 실제 적용을 살펴보겠습니다.
이 표는 사용자 3명의 항목 평점입니다. 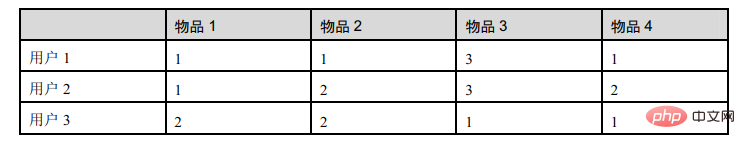
d12는 사용자 1과 사용자 사이의 유사성을 나타냅니다. user 2 정도이면 다음과 같습니다: 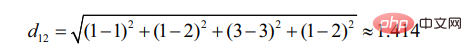
마찬가지로 d13: 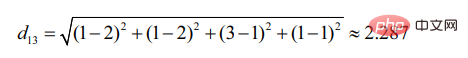
사용자 2가 사용자 1과 더 유사하다는 것을 알 수 있습니다(거리가 작을수록 유사성은 더 커집니다).
2. 코사인 각도에 따른 유사성 계산
코사인 각도 계산의 시작점은 끼인 각도의 차이입니다. 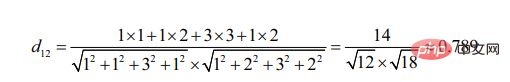
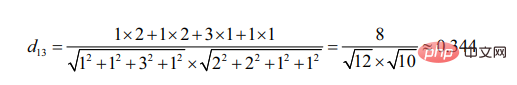
사용자 3과 비교할 때 사용자 2는 사용자 1과 더 유사하다는 것을 알 수 있습니다. (두 대상이 유사할수록 선분이 이루는 각도가 작아집니다.)
4. 시각적 표시 데이터 통계 (예: 보저우시 강수량 기준)
데이터 사분위수
사분위수는 통계에서 일종의 분위수입니다. 즉, 데이터를 작은 것부터 큰 것까지 배열한 다음 4개의 동일한 부분으로 나눕니다. 세 부분으로 나누어 포인트 위치의 데이터는 사분위수입니다.
제1사분위수(Q1), 하위사분위수라고도 함;
제2사분위수(Q1), 중앙값이라고도 함
제3사분위수, 하위사분위수라고도 함;
3사분위수와 1사분위수 사이의 간격을 IQR(사분위간 간격)이라고도 합니다.
若n为项数,则:
Q1的位置 = (n+1)*0.25
Q2的位置 = (n+1)*0.50
Q3的位置 = (n+1)*0.75
四分位示例:
关于这个rain.csv,有需要的可以私我要文件,我使用的是亳州市2010-2019年的月份降水情况。
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()print(summary)array = dataFile.iloc[:,:].values
boxplot(array)plot.xlabel("year")plot.ylabel("rain")show()
以下是plot运行结果: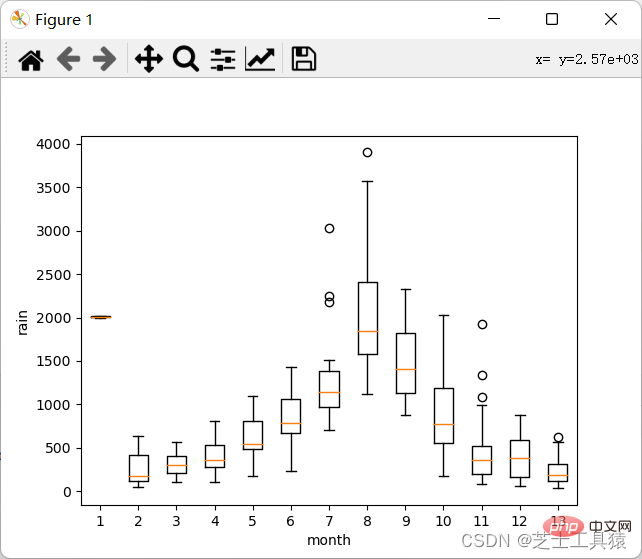
这个是pandas的运行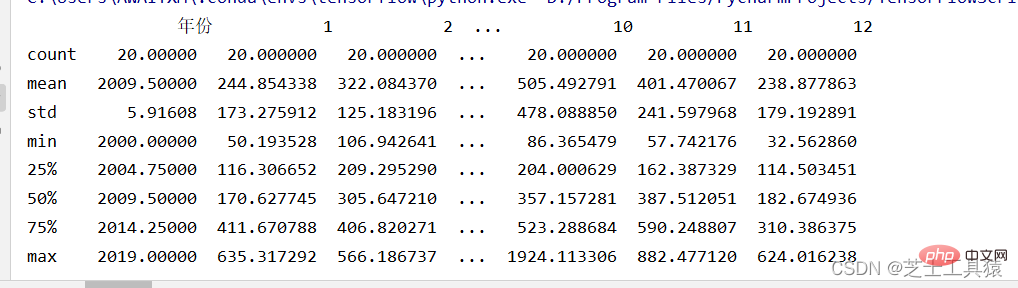
这里就可以很清晰的看出来数据的波动范围。
可以看出,不同月份的降水量有很大差距,8月最多,1-4月和10-12月最少。
那么每月的降水增减程度如何比较?
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()minRings = -1maxRings = 99nrows = 11for i in range(nrows):
dataRow = dataFile.iloc[i,1:13]
labelColor = ( (dataFile.iloc[i,12] - minRings ) / (maxRings - minRings) )
dataRow.plot(color = plot.cm.RdYlBu(labelColor),alpha = 0.5)plot.xlabel("Attribute")plot.ylabel(("Score"))show()
结果如图: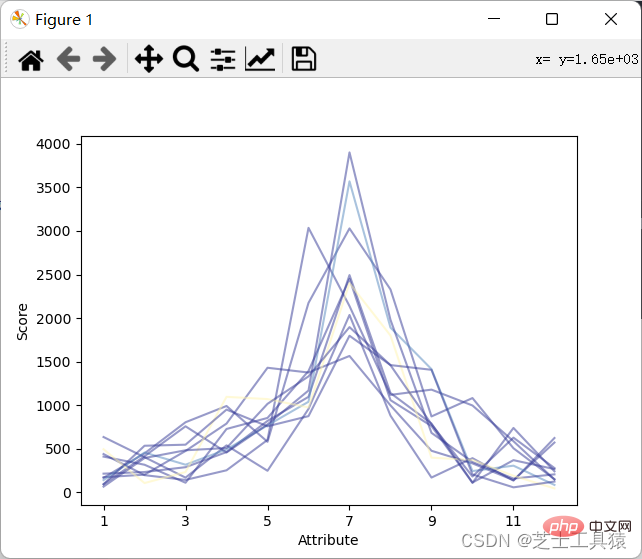
可以看出来降水月份并不规律的上涨或下跌。
那么每月降水是否相关?
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()corMat = pd.DataFrame(dataFile.iloc[1:20,1:20].corr())plot.pcolor(corMat)plot.show()
结果如图: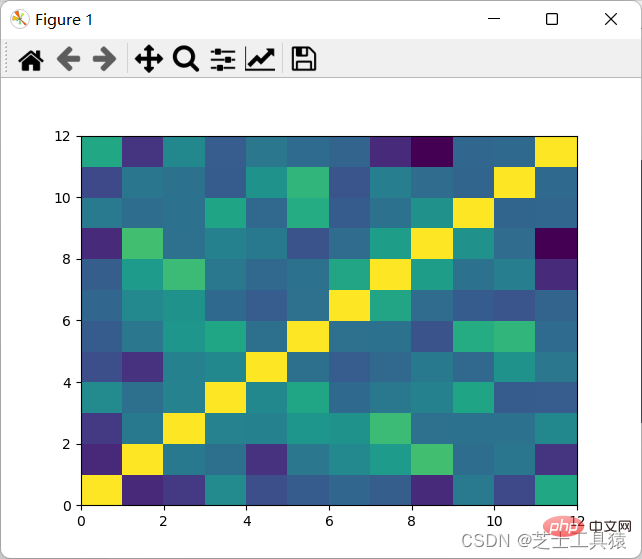
可以看出,颜色分布十分均匀,表示没有多大的相关性,因此可以认为每月的降水是独立行为。
今天就记录到这里了,我们下次再见!希望本文章对你也有所帮助。
推荐学习:python学习教程
위 내용은 Python 데이터 처리 및 시각화에 대한 심층적인 이해의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!