
최적화 팁! ! 프런트엔드 초보자가 인터페이스 속도를 60% 향상

- coldplay.xixi앞으로
- 2020-11-11 17:28:012267검색
javascript 칼럼에서는 프런트엔드 초보자가 인터페이스 속도를 60% 향상하기 위해 사용하는 기술을 소개합니다.

Background
오랫동안 글을 쓰지 않고 반년 넘게 침묵을 지켰습니다
계속되는 불쾌감, 간헐적인 간질 발작
매일 삼촌을 방문하고, 매일 시간을 보냅니다. 혼란스럽고 불안한 하루
인정해야겠습니다 사실 저는 아깝습니다
로우레벨 프론트엔드 엔지니어로서
최근에 10년 넘게 전해 내려오는 고대 인터페이스를 다루었습니다 년
최고의 복잡도 논리를 모두 물려받았습니다
한 번의 호출로 CPU 부하가 90% 치솟을 수 있다고 합니다
다양한 불만과 알츠하이머병 치료에 특화
이 인터페이스가 얼마나 시간이 많이 걸리는지 감상해 봅시다 이다
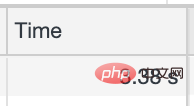
평균 통화 시간이 3초 이상
심각한 페이지 리디렉션을 초래함
다양한 끝에 이런 심층적인 분석과 전문가와의 Q&A
최종 결론은: 진료 포기
루 Xun은 "광인의 일기"에서 다음과 같이 말했습니다. "나를 이길 수 있는 유일한 것은 벌레가 아니라 여자와 술입니다”能打败我的,只有女人和酒精,而不是bug”
每当身处黑暗之时
这句话总能让我看到光
所以这次要硬起来
我决定做一个node代理层
用下面三个方法进行优化:
按需加载 -> graphQL数据缓存 -> redis轮询更新 -> schedule
代码地址:github
按需加载 -> graphQL
天秀老接口存在一个问题,我们每次请求1000条数据,返回的数组中,每一条数据都有上百个字段,其实我们前端只用到其中的10个字段而已。
如何从一百多个字段中,抽取任意n个字段,这就用到graphQL。
graphQL按需加载数据只需要三步:
- 定义数据池 root
- 描述数据池中数据结构 schema
- 自定义查询数据 query
定义数据池
我们针对屌丝追求女神的场景,定义一个数据池,如下:
// 数据池var root = { girls: [{ id: 1, name: '女神一', iphone: 12345678910, weixin: 'xixixixi', height: 175, school: '剑桥大学', wheel: [{ name: '备胎1号', money: '24万元' }, { name: '备胎2号', money: '26万元' }]
},
{ id: 2, name: '女神二', iphone: 12345678910, weixin: 'hahahahah', height: 168, school: '哈佛大学', wheel: [{ name: '备胎3号', money: '80万元' }, { name: '备胎4号', money: '200万元' }]
}]
}复制代码
里面有两个女神的所有信息,包括女神的名字、手机、微信、身高、学校、备胎集合等信息。
接下来我们就要对这些数据结构进行描述。
描述数据池中数据结构
const { buildSchema } = require('graphql');// 描述数据结构 schemavar schema = buildSchema(`
type Wheel {
name: String,
money: String
}
type Info {
id: Int
name: String
iphone: Int
weixin: String
height: Int
school: String
wheel: [Wheel]
}
type Query {
girls: [Info]
}
`);复制代码
上面这段代码就是女神信息的schema。
首先我们用type Query定义了一个对女神信息的查询,里面包含了很多女孩girls的信息Info,这些信息是一堆数组,所以是[Info]
我们在type Info
-

온디맨드 로딩 -> graphQL 데이터 캐싱-> redis

폴링 업데이트-> code>
코드 주소: github
요청 시 로드-> graphQL
Tianxiu의 이전 인터페이스에 문제가 있습니다. 1000개의 데이터를 요청하면 반환된 배열의 각 데이터에는 수백 개의 필드가 있습니다. 실제로 프런트 엔드에서는 그 중 10개만 사용합니다.
100개가 넘는 필드에서 n개의 필드를 추출하는 방법은 graphQL을 사용합니다.
GraphQL에서는 요청 시 데이터를 로드하는 데 세 단계만 필요합니다.
- 데이터 풀 루트 정의
- 데이터 풀의 데이터 구조 스키마 설명
- 쿼리 사용자 정의 데이터 쿼리
데이터 풀 정의
디아오시가 여신을 쫓는 장면에 대한 데이터 풀을 다음과 같이 정의합니다.const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
weixin
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码
It 여신의 이름, 휴대폰, 위챗, 키, 학교, 스페어 타이어 수집 및 기타 정보를 포함하여 두 여신의 모든 정보가 포함되어 있습니다. 다음으로 이러한 데이터 구조에 대해 설명하겠습니다.
데이터 풀의 데이터 구조를 설명하세요const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
wheel {
money
}
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码
위 코드는 여신 정보의 스키마입니다.
먼저 type Query를 사용하여 소녀에 대한 많은 정보가 포함된 여신 정보에 대한 쿼리를 정의합니다. Info 이 정보는 배열이므로 다음과 같습니다. [Info]
type Info에는 이름, 휴대폰(iphone), WeChat(weixin), 키, 학교 등 소녀에 대한 모든 정보의 차원을 설명합니다. , 스페어 타이어 세트(휠)
쿼리 규칙 정의
여신의 정보 설명(스키마)을 얻은 후, 여신이 얻은 다양한 정보의 조합을 맞춤 설정할 수 있습니다.
예를 들어 여신을 알고 싶다면 이름과 웨이신만 알면 됩니다. 쿼리 규칙 코드는 다음과 같습니다.
const redis = require("redis");const { promisify } = require("util");// 链接redis服务const client = redis.createClient(6379, '127.0.0.1');// promise化redis方法,以便用async/awaitconst getAsync = promisify(client.get).bind(client);const setAsync = promisify(client.set).bind(client);async function list() { // 先获取缓存中数据,没有缓存就去拉取天秀接口
let result = await getAsync("缓存"); if (!result) { // 拉接口
const data = await 天秀接口();
result = data; // 设置缓存数据
await setAsync("缓存", data)
} return result;
}
list();
复制代码
필터링 결과는 다음과 같습니다.
🎜🎜또 다른 예를 들어, 여신과 더욱 발전하려면 여신의 스페어 휠 정보를 가져와 부를 쿼리해야 합니다( 돈)의 예비바퀴(바퀴)가 얼마인지, 짝을 선택할 수 있는 첫 번째 권리를 얻을 수 있는지 분석해 보세요. 쿼리 규칙 코드는 다음과 같습니다. 🎜const schedule = require('node-schedule');// 每个小时更新一次缓存schedule.scheduleJob('* * 0 * * *', async () => { const data = await 天秀接口(); // 设置redis缓存数据
await setAsync("缓存", data)
});复制代码🎜필터 결과는 다음과 같습니다. 🎜🎜🎜🎜🎜 여신의 예를 사용하여 graphQL을 통해 요청 시 데이터를 로드하는 방법을 보여줍니다. 🎜🎜비즈니스의 특정 시나리오에 매핑되어 Tianxiu 인터페이스에서 반환된 각 데이터에는 100개의 필드가 포함되어 있으며 나머지 90개의 불필요한 필드가 전송되지 않도록 스키마를 구성합니다. 🎜🎜graphQL의 또 다른 이점은 유연하게 구성할 수 있다는 것입니다. 이 인터페이스에는 10개의 필드가 필요하고, 다른 인터페이스에는 5개의 필드가 필요하며, n번째 인터페이스에는 또 다른 x 필드가 필요합니다.🎜🎜기존 접근 방식에 따르면 n개의 인터페이스만 만들어야 합니다. 모든 상황을 충족하려면 인터페이스를 다른 스키마로 구성해야 합니다. 🎜🎜영감🎜🎜살면서 개를 핥는 우리는 필요에 따라 graphQL을 로드한다는 아이디어가 정말 부족합니다🎜🎜나쁜 남자와 나쁜 여자, 각자 필요한 것을 얻습니다🎜🎜연예인 앞에서 당신의 진심은 말할 가치도 없습니다🎜🎜 좋아하면 배워야지🎜🎜오면 차키 보여주고, 차가 없으면 재능 뽐내라🎜🎜오늘밤은 꼭 나누고 싶은 조상염색체가 있다🎜🎜만약 그렇다면 작동하면 그냥 변경하고, 그렇지 않으면 다음 항목으로 변경하세요🎜🎜간단하고 조잡한 주제로 바로 이동하세요 🎜🎜Cache-> redis🎜🎜두 번째 최적화 방법은 Redis 캐시를 사용하는 것입니다🎜天秀老接口内部调用了另外三个老接口,而且是串行调用,极其耗时耗资源,秀到你头皮发麻
我们用redis来缓存天秀接口的聚合数据,下次再调用天秀接口,直接从缓存中获取数据即可,避免高耗时的复杂调用,简化后代码如下:
const redis = require("redis");const { promisify } = require("util");// 链接redis服务const client = redis.createClient(6379, '127.0.0.1');// promise化redis方法,以便用async/awaitconst getAsync = promisify(client.get).bind(client);const setAsync = promisify(client.set).bind(client);async function list() { // 先获取缓存中数据,没有缓存就去拉取天秀接口
let result = await getAsync("缓存"); if (!result) { // 拉接口
const data = await 天秀接口();
result = data; // 设置缓存数据
await setAsync("缓存", data)
} return result;
}
list();
复制代码
先通过getAsync来读取redis缓存中的数据,如果有数据,直接返回,绕过接口调用,如果没有数据,就会调用天秀接口,然后setAsync更新到缓存中,以便下次调用。因为redis存储的是字符串,所以在设置缓存的时候,需要加上JSON.stringify(data),为了便于大家理解,我就不加了,会把具体细节代码放在github中。
将数据放在redis缓存里有几个好处
可以实现多接口复用、多机共享缓存
这就是传说中的云备胎
追求一个女神的成功率是1%
同时追求100个女神,那你获取到一个女神的概率就是100%
鲁迅《狂人日记》里曾说过:“舔一个是舔狗,舔一百个你就是战狼”
你是想当舔狗还是当战狼?
来吧,缓存用起来,redis用起来
轮询更新 -> schedule
最后一个优化手段:轮询更新 -> schedule
女神的备胎用久了,会定时换一批备胎,让新鲜血液进来,发现新的快乐
缓存也一样,需要定时更新,保持与数据源的一致性,代码如下:
const schedule = require('node-schedule');// 每个小时更新一次缓存schedule.scheduleJob('* * 0 * * *', async () => { const data = await 天秀接口(); // 设置redis缓存数据
await setAsync("缓存", data)
});复制代码
天秀接口不是一个强实时性接口,数据源一周可能才会变一次
所以我们根据实际情况用轮询来设置更新缓存频率
我们用node-schedule这个库来轮询更新缓存,* * 0 * * *这个的意思就是设置每个小时的第0分钟就开始执行缓存更新逻辑,将获取到的数据更新到缓存中,这样其他接口和机器在调用缓存的时候,就能获取到最新数据,这就是共享缓存和轮询更新的好处。
早年我在当舔狗的时候,就将轮询机制发挥到淋漓尽致
每天向白名单里的女神,定时轮询发消息
无限循环云跪舔三件套:
- “啊宝贝,最近有没有想我”
- “啊宝贝早安安”
- “宝贝晚安,么么哒”
虽然女神依然看不上我
但仍然时刻准备着为女神服务
结尾
经过以上三个方法优化后
接口请求耗时从3s降到了860ms
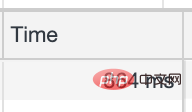
这些代码都是从业务中简化后的逻辑
真实的业务场景远比这要复杂:分段式数据存储、主从同步 读写分离、高并发同步策略等等
每一个模块都晦涩难懂
就好像每一个女神都高不可攀
屌丝战胜了所有bug,唯独战胜不了她的心
受伤了只能在深夜里独自买醉
但每当梦到女神打开我做的页面
被极致流畅的体验惊艳到
在精神高潮中享受灵魂升华
那一刻
我觉得我又行了
(完)
相关免费学习推荐:JavaScript(视频)
위 내용은 최적화 팁! ! 프런트엔드 초보자가 인터페이스 속도를 60% 향상의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!