
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL의 데이터 유형 및 스키마 최적화
MySQL의 데이터 유형 및 스키마 최적화

- coldplay.xixi앞으로
- 2020-10-26 17:58:092637검색
최근 MySQL 최적화에 대해 배우고 있습니다. Mysql Tutorial 칼럼에서는 데이터 유형과 스키마의 최적화를 소개합니다.
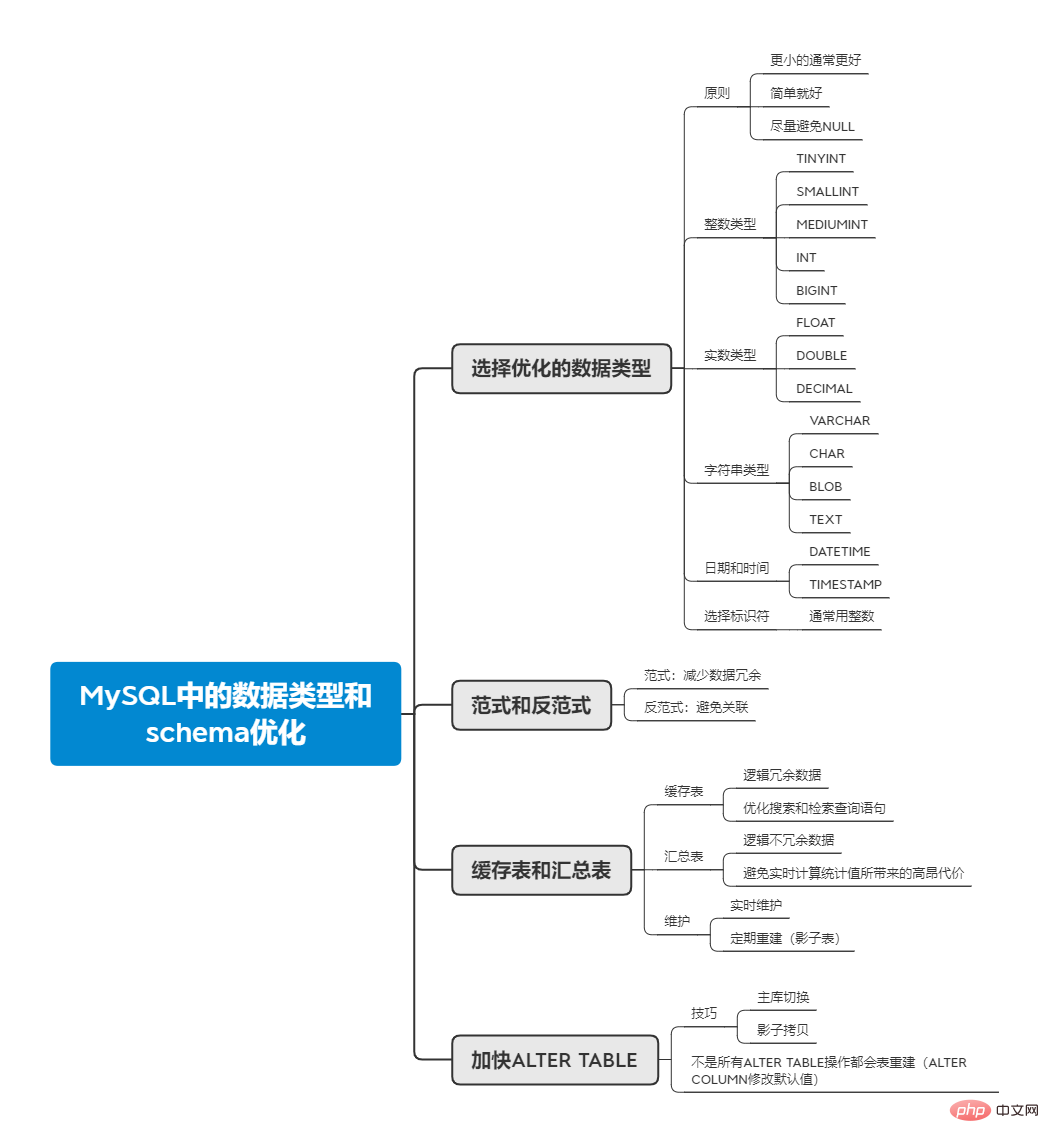
1. 최적화된 데이터 유형 선택
MySQL은 다양한 데이터 유형을 지원하며 올바른 데이터 유형을 선택하는 방법은 성능에 매우 중요합니다. 다음 원칙 은 데이터 유형을 결정하는 데 도움이 될 수 있습니다.
-
일반적으로 작을수록 좋습니다.
데이터를 올바르게 저장할 수 있는 가장 작은 데이터 유형은 충분하다면 최대한 많이 사용해야 합니다. 이렇게 하면 디스크, 메모리, 캐시를 덜 차지하며 처리 시간도 단축됩니다.
-
단순함이 더 좋습니다
두 가지 데이터 유형으로 필드를 저장할 수 있는 경우 더 간단한 것을 선택하는 것이 최선의 선택인 경우가 많습니다. 예를 들어 정수와 문자열의 경우 정수의 연산 비용이 문자의 연산 비용보다 적기 때문에 둘 중 하나를 선택할 때 일반적으로 정수를 선택하는 것이 성능이 더 좋습니다.
-
NULL을 피하세요
열이 NULL이 될 수 있는 경우 MySQL의 경우 인덱싱 및 값 비교 측면에서 더 많은 작업이 필요하지만 성능에 미치는 영향은 크지 않지만 다음과 같이 시도해야 합니다. 가능한 한 NULL이 되도록 설계하지 마십시오.
위 원칙 외에도 데이터 유형을 선택할 때 다음 단계를 따라야 합니다. 먼저 데이터, 문자열, 시간 등과 같은 적절한 대형 유형을 결정한 다음 특정 유형을 선택합니다. 큰 유형의 일부 특정 유형은 아래에서 설명됩니다. 첫 번째는 정수와 실수의 두 가지 유형이 있는 숫자입니다.
1.1 정수형
정수형과 차지하는 공간은 다음과 같습니다.
| 정수형 | 공간 크기(비트) |
|---|---|
| TINYINT | 8 |
| SMALLINT | 16 |
| MEDIUMINT | 24 |
| INT | 32 |
| BIGINT | 64 |
정수형이 저장할 수 있는 범위는 공간 크기와 관련이 있습니다: -2^(N-1) ~ 2^(N-1)-1, 여기서 N은 공간 크기의 자릿수입니다.
정수형에는 UNSIGNED라는 선택적 속성이 있습니다. 선언하면 음수가 허용되지 않으며 저장 범위가 0에서 2^(N)-1이 되어 두 배가 됩니다.
MySQL에서는 INT(1)과 같은 정수 유형의 너비를 지정할 수도 있지만 이는 그다지 중요하지 않으며 유효한 값 범위를 제한하지 않습니다. 여전히 -2^31에서 2^31까지 저장할 수 있습니다. -1 이 값은 MySQL의 대화형 도구에서 표시되는 문자 수에 영향을 줍니다.
1.2 실수형
실수형의 비교는 다음과 같습니다.
| 실수형 | 공간 크기(바이트) | 값 범위 | 계산 정확도 |
|---|---|---|---|
| FLOAT | 4 | 음수: -3.4E+38~-1.17E-38; 음수가 아닌 숫자: 0, 1.17E-38~3.4E+38 | 대략적인 계산 |
| DOUBLE | 8 | 음수 : -1.79E+308~-2.22 E-308; 음수가 아닌 숫자: 0, 2.22E-308~1.79E+308 | 대략적인 계산 |
| DECIMAL | 정확도 관련 | DOUBLE과 동일 | 정확한 계산 |
위에서 볼 수 있듯이 FLOAT와 DOUBLE은 모두 공간 크기가 고정되어 있지만 동시에 표준 부동 소수점 연산을 사용하기 때문에 대략적인 계산만 가능합니다. DECIMAL은 정확한 계산을 수행할 수 있지만 동시에 더 많은 공간을 차지하고 더 많은 계산 오버헤드를 소비합니다.
DECIMAL이 차지하는 공간은 지정된 정밀도와 관련됩니다. 예를 들어 DECIMAL(M,D):
- M은 전체 숫자의 최대 길이이고 값 범위는 [1, 65]이며 기본값은 value는 10입니다.
- D 소수점 이하의 길이이며, 값 범위는 [0, 30]이며, D
MySQL은 저장할 때 DECIMAL 유형을 이진 문자열로 저장합니다. 4바이트마다 9자리 숫자를 저장합니다. 9자리 미만인 경우 숫자가 차지하는 공간은 다음과 같습니다.
| 숫자 개수 | 점유 공간(바이트) |
|---|---|
| 1, 2 | 1 |
| 3, 4 | 2 |
| 5, 6 | 3 |
| 7, 8 | 4 |
소수점 앞과 뒤의 문자가 별도로 저장되며, 소수점도 1바이트를 차지합니다. 다음은 두 가지 계산 예입니다.
- DECIMAL(18, 9): 정수 부분의 길이가 9이고 4바이트를 차지합니다. 소수 부분의 길이는 9이고 4바이트를 차지한다. 동시에 소수점 1바이트를 더해 총 9바이트를 차지하게 된다.
- DECIMAL(20, 9): 정수 부분의 길이는 14로, 7(4+3)바이트를 차지합니다. 소수 부분의 길이는 9이고 4바이트를 차지한다. 동시에 소수점 1바이트를 더해 총 12바이트를 차지하게 된다.
DECIMAL은 여전히 많은 공간을 차지하므로 DECIMAL은 소수의 정확한 계산이 필요할 때만 필요하다는 것을 알 수 있습니다. 또한 DECIMAL 대신 BIGINT를 사용할 수도 있습니다. 예를 들어 소수점 이하 5자리의 계산을 보장해야 하는 경우 해당 값에 10의 5승을 곱하여 BIGINT로 저장할 수 있습니다. 부정확한 부동 소수점 저장 계산과 동시에 DECIMAL 계산 비용이 많이 드는 문제입니다.
1.3 문자열 유형
가장 일반적으로 사용되는 문자열 유형은 VARCHAR 및 CHAR입니다. VARCHAR가변 길이 문자열으로, 문자열의 길이를 기록하는 데 1~2바이트가 추가로 사용됩니다. 최대 길이가 255를 초과하지 않는 경우 255를 초과하는 경우 1바이트만 기록하면 됩니다. , 2바이트. VARCHAR의 적용 가능한 시나리오:
- 최대 길이는 평균 길이보다 훨씬 큽니다.
- 열은 조각화를 방지하기 위해 덜 업데이트됩니다.
- UTF-8과 같은 복잡한 문자 집합을 사용하고 각 문자는 서로 다른 문자를 사용할 수 있습니다. 바이트 저장.
CHAR은 정의된 문자열 길이에 따라 충분한 공간을 할당하는 고정 길이 문자열입니다.
짧은 길이,- 자주 업데이트됩니다. .
- VARCHAR 및 CHAR 외에도 BLOB 및 TEXT 유형을 사용하여 큰 문자열을 저장할 수 있습니다. BLOB와 TEXT의 차이점은
- BLOB 은
에 저장되고 TEXT는 characters에 저장된다는 것입니다. 이로 인해 BLOB 유형의 데이터는 문자 집합의 개념이 없어 문자별로 정렬할 수 없는 반면, TEXT 유형의 데이터는 문자 집합의 개념을 갖고 문자별로 정렬할 수 있다는 사실도 알 수 있습니다. 두 가지의 사용 시나리오도 저장 형식에 따라 결정됩니다. 그림과 같은 바이너리 데이터를 저장할 때는 BLOB를 사용해야 하고, 기사와 같은 텍스트를 저장할 때는 TEXT 유형을 사용해야 합니다. 1.4 날짜 및 시간 유형MySQL에 저장할 수 있는 최소 시간 단위는 초입니다. 일반적으로 사용되는 날짜 유형에는 DATETIME 및 TIMESTAMP가 있습니다.
Type| 공간 크기(바이트) | 시간대 개념 | ||
|---|---|---|---|
| 8 | 형식의 정수없음 | TIMESTAMP | |
| 4 | has |
TIMESTAMP에 표시되는 값은 시간대에 따라 달라집니다. 즉, 시간대별로 쿼리되는 값이 다릅니다. 위에 나열된 차이점 외에도 TIMESTAMP에는 삽입 및 업데이트 중에 첫 번째 TIMESTAMP 열의 값이 지정되지 않으면 이 열의 값이 현재 시간으로 설정됩니다. 개발 과정에서 TIMESTAMP를 사용하도록 노력해야 합니다. 주로 공간 크기가 DATETIME의 절반에 불과하고 공간 효율성이 높기 때문입니다. 날짜와 시간을 초 단위까지 정확하게 저장하고 싶다면 어떻게 해야 할까요? MySQL은 이를 제공하지 않기 때문에 BIGINT를 사용하여 마이크로 수준의 타임스탬프를 저장하거나 DOUBLE을 사용하여 초 후 소수 부분을 저장할 수 있습니다. 1.5 식별자 선택일반적으로 정수는 식별자로 가장 적합합니다. 그 이유는 정수가 간단하고 계산이 빠르며 AUTO_INCREMENT를 사용할 수 있기 때문입니다. 2. 패러다임과 안티 패러다임간단히 말하면, 패러다임은 데이터 테이블의 테이블 구조가 준수하는 특정 디자인 표준의 수준입니다. 첫 번째 정규형에서는 속성이 분리되지 않습니다. 현재 RDBMS 시스템에서 구축된 테이블은 모두 첫 번째 정규형과 일치합니다. 두 번째 정규형은 코드(기본 키로 이해될 수 있음)에 대한 기본이 아닌 속성의 부분적 종속성을 제거합니다. 세 번째 정규형은 코드에 대한 기본이 아닌 속성의 전이적 종속성을 제거합니다. 구체적인 소개는 Zhihu(https://www.zhihu.com/question/24696366/answer/29189700)에서 이 답변을 읽을 수 있습니다. Strictnormalized데이터베이스에서 각 사실 데이터는 한 번만 나타납니다. , 데이터 중복이 없으며 이로 인해 얻을 수 있는 이점은 다음과 같습니다.
의 장점은 연관할 필요가 없으며 데이터가 중복 저장된다는 것입니다. 실제 응용 프로그램에서는 완전한 정규화 또는 완전한 비정규화가 발생하지 않습니다. 정규화와 비정규화를 혼합해야 하는 경우가 종종 있습니다. 데이터베이스 설계에 관해서는 인터넷에서 이 문단을 보고 느낀 바가 있습니다. 데이터베이스 디자인은 세 가지 영역으로 나누어야 합니다.
위에서 언급한 안티 패러다임과 테이블에 중복 데이터를 저장하는 것 외에도 검색 요구 사항을 충족하기 위해 완전히 독립적인 요약 테이블 또는 캐시 테이블을 만들 수도 있습니다.캐시 테이블은 스키마 내의 다른 테이블에서 얻을 수 있는 데이터, 즉 논리적으로 중복되는 데이터를 저장하는 테이블을 말합니다. summary table은 GROUP BY와 같은 문을 사용하여 데이터를 집계하여 계산된 중복되지 않는 데이터를 저장하는 것을 의미합니다. 캐시 테이블을 사용하여 검색 및 검색 쿼리 문을 최적화할 수 있습니다. 여기에 사용할 수 있는 기술에는 캐시 테이블에 대해 다른 스토리지 엔진을 사용하는 것이 포함되며, 캐시 테이블은 MyISAM을 사용하여 가져올 수 있습니다. 더 작은 인덱스를 차지합니다. Lucene과 같은 전문 검색 시스템에 캐시 테이블을 넣을 수도 있습니다. 요약표는 실시간 통계값 계산으로 인한 높은 비용을 피하기 위한 것입니다. 비용은 두 가지 측면에서 발생합니다. 하나는 테이블에 있는 대부분의 데이터를 스캔해야 한다는 점과 다른 하나입니다. UPDATE 작업에 영향을 미치는 특정 인덱스가 설정됩니다. 예를 들어 지난 24시간 동안의 WeChat 모멘트 수를 쿼리하려면 매시간 전체 테이블을 스캔하고 통계 후 요약 테이블에 레코드를 쓰면 쿼리할 때 요약에서 최신 24개 레코드만 쿼리하면 됩니다. 각 쿼리 중에 전체 테이블에서 통계를 검색합니다. 캐시 테이블과 요약 테이블을 사용할 때 필요에 따라 실시간 데이터 유지 또는 주기적인 재구축 여부를 결정해야 합니다. 실시간 유지 관리에 비해 정기적인 재구성은 더 많은 리소스를 절약하고 테이블 조각화를 줄일 수 있습니다. 재구성하는 동안에도 작업 중에 데이터를 사용할 수 있는지 확인해야 하며 이는 "섀도 테이블"을 통해 달성되어야 합니다. 실제 테이블 뒤에 섀도우 테이블을 생성합니다. 데이터를 채운 후 원자성 이름 바꾸기 작업을 통해 섀도우 테이블과 원본 테이블을 전환합니다. MySQL은 ALTER TABLE 작업을 수행할 때 새 테이블을 생성한 다음 이전 테이블의 데이터를 확인하여 새 테이블에 삽입한 다음 이전 테이블을 삭제하는 경우가 많습니다. 테이블이 매우 크면 시간이 오래 걸리고 MySQL 서비스가 중단될 수 있습니다. 서비스 중단을 피하기 위해 일반적으로 두 가지 기술을 사용할 수 있습니다. 그러나 모든 ALTER TABLE 작업이 테이블 재구성을 유발하는 것은 아닙니다. 예를 들어 필드의 기본값을 수정할 때 MODIFY COLUMN을 사용하면 테이블이 재구성되지만 ALTER COLUMN을 사용하면 테이블 재구성이 발생하지 않습니다. 빠른. . ALTER COLUMN이 기본값을 수정하면 테이블을 다시 작성하지 않고 기존 테이블(필드의 기본값이 저장됨)의 .frm 파일을 직접 수정하기 때문입니다. 더 많은 관련 무료 학습 권장사항: mysql 튜토리얼(동영상) |
위 내용은 MySQL의 데이터 유형 및 스키마 최적화의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!