
집 >데이터 베이스 >MySQL 튜토리얼 >[MySQL 데이터베이스] 4장 해석: 스키마 및 데이터 유형 최적화(1부)
[MySQL 데이터베이스] 4장 해석: 스키마 및 데이터 유형 최적화(1부)
- php是最好的语言원래의
- 2018-08-07 13:53:421823검색
서문:
고성능의 초석: 우수한 논리적, 물리적 설계, 시스템에서 실행되는 쿼리문을 기반으로 한 스키마 설계
이번 장에서는 MySQL 데이터베이스 설계에 중점을 두고 mysql 데이터베이스를 소개합니다. 디자인 및 기타 관계형 데이터베이스 관리 시스템의 차이점
스키마: [출처]
스키마는 데이터베이스 개체의 모음입니다. 이 컬렉션에는 테이블, 뷰, 저장 프로시저, 인덱스 등과 같은 다양한 개체가 포함되어 있습니다. 서로 다른 컬렉션을 구별하려면 서로 다른 컬렉션에 서로 다른 이름을 지정해야 합니다. 기본적으로 한 사용자의 스키마 이름은 사용자 이름과 동일하며 해당 사용자의 기본 스키마로 사용됩니다. 따라서 스키마 컬렉션은 사용자 이름처럼 보입니다. 데이터베이스를 창고로 생각하면 창고에는 많은 방(스키마)이 있고, 하나의 스키마는 방을 나타내고, 테이블은 각 방의 라커로 볼 수 있으며, 사용자는 각 스키마의 소유자이며, 거기에 각 룸의 권한은 데이터베이스에 매핑된 각 사용자가 각 스키마(룸)의 키를 가지고 있음을 의미합니다. SQL Server와 Oracle mysql의 차이점4.1 최적화된 데이터 유형 선택
원칙:
1,
더 작은 패스가 더 좋습니다, 데이터를 올바르게 저장할 수 있는 가장 작은 데이터 유형을 사용하십시오(디스크 메모리를 덜 차지합니다. CPU 캐시에 필요) 처리를 위한 CPU 주기가 적음: 빠름), 데이터를 처리할 수 있음 2. 단순한 것이 좋다: 단순형(CPU 주기가 적음), MySQL 내장형 저장 시간, 정수 사용 유형은 IP를 저장하고 정수 유형은 문자보다 저렴합니다(문자 세트 및 대조 정렬 규칙은 문자를 더 복잡하게 만듭니다)
3. null을 피하십시오: null이 아닌 것을 지정하는 것이 가장 좋습니다 *) Null 열은 더 많은 저장 공간을 차지합니다. mysql에서의 처리
*) Null은 인덱싱, 인덱스 통계 및 값 비교를 더 복잡하게 만듭니다. Null 허용 열이 인덱싱되면 각 인덱스 레코드에 추가 바이트가 필요합니다.
예외: InnoDB는 별도의 비트를 사용합니다. Null을 저장하므로 스파스에 대한 공간 효율성이 좋습니다. 데이터(많은 값이 null임), MyISAM에는 적합하지 않음
4.1.1 정수형 [참조]
integer 정수
tinyint (8비트 저장 공간) smallint(16 ) Mediumint(24) int (32) bigint(64)
1. 저장되는 값의 범위:
, N은 저장공간의 자릿수 2. unsigned: 선택사항, 음수는 허용되지 않음, 양수는 가능 한도는 두 배입니다:tinyint unsigned 0~255,tinyint-128~1273. 부호가 있든 없든 동일한 저장 공간을 사용하면 동일한 성능을 얻을 수 있습니다.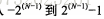 INT(11)와 같은 정수의 너비를 지정할 수 있습니다. 대부분의 응용 프로그램은 의미가 없으며 대화형 도구에서 표시되는 문자 수만 지정합니다. int (1) 및 int (20)은 동일합니다.
INT(11)와 같은 정수의 너비를 지정할 수 있습니다. 대부분의 응용 프로그램은 의미가 없으며 대화형 도구에서 표시되는 문자 수만 지정합니다. int (1) 및 int (20)은 동일합니다.
float 및 double을 사용하면 mysql은 내부 부동 소수점 계산 유형으로 duble을 사용합니다.
decimal: 정확한 소수를 저장하며 mysql 서버 자체에서 이를 구현합니다. 십진수(18,9) 18비트, 소수점 9자리, 9바이트(첫 번째 4 및 마지막) 4점 1)
금융 데이터 등 소수점에 대한 정확한 계산(추가 공간 및 계산 오버헤드)을 수행할 때만 사용하도록 하세요.
데이터 양이 많은 경우 대신 bigint를 사용하여 변환하는 것을 고려하세요. 소수로 저장해야 하는 화폐 단위. 해당 배수를 곱한 자릿수
부동 소수점:
권장 사항: 유형과 무기한 정밀도(mysql)만 지정하세요. MySQL은 자동으로 비표준입니다. 저장할 때 유형을 선택하거나 값을 반올림하세요
동일한 범위에 값을 저장합니다. 소수점 이하의 공간이 있는 경우 float4 바이트는 double8 바이트를 저장합니다(정밀도 범위가 더 높음)
4.1.3 문자열 유형
varchar 및 char:
전제: innodb 및 myisam 엔진, 가장 중요한 문자열 유형
디스크 저장: 저장 엔진의 저장 방법은 메모리 및 디스크의 저장 방법과 달라야 하므로 mysql 서버는 엔진의 값을 엔진의 값으로 변환해야 합니다. format
varchar:1. 변수 문자열을 저장하고 비율이 고정됩니다. 공간을 절약하지만(필요한 공간만 사용) 테이블에서 row_format=fixed를 사용하면 행이 고정된 길이로 저장됩니다
2 1/2 추가 바이트는 문자열 길이를 기록하는 데 사용됩니다. 1) 열 최대 길이
3. 저장 공간을 절약하고 성능에 도움이 되지만, 업데이트 중에 행이 원본보다 길어져 추가 작업이 필요할 수 있습니다.
적절한 상황:1) 문자열 열의 최대 길이는 평균 길이보다 훨씬 큽니다. 2) 열의 업데이트 수가 적습니다(조각화에 대한 걱정 없음). 3) UTF-8 문자열을 사용하며 각 문자는 서로 다른 수를 사용하여 저장됩니다. 바이트
문자:1. 길이를 고정하고, 길이에 따라 공백을 할당하고, 길이가 충분하지 않으면 공백을 모두 삭제하고, 공백을 채우는 것이 더 효율적입니다. 2. 저장공간 측면에서 char(1)은 Y N만 저장하는데 사용됩니다. 값은 1바이트, varchar2바이트이고, 레코드 길이가 있습니다 적합한 상황: 1) 매우 짧은 문자열 저장에 적합 2) 또는 모든 값이 동일한 길이에 가까움 3) 자주 변경되는 데이터, 조각화하기 쉽지 않음 공백에 해당, 저장: #🎜 🎜#문자 유형이 저장되면 후행 공백이 삭제됩니다. 데이터가 저장되는 방식은 메모리 엔진에만 달려 있습니다. 고정 길이 라인 지원(최대 길이는 공간 할당) , 바이트코드 , 길지 않음, 이전에는tinyint와 동의어, 새로운 기능 비트(1) 단일 비트 필드, 비트(2) 2비트, 최대 길이 64비트 동작 요인 스토리지 엔진 MyISAM은 모든 BIT 열을 압축하고 저장합니다(17개의 개별 비트 열에는 17비트의 저장 공간만 필요하며 myisam3 바이트도 괜찮습니다). 다른 엔진인 Memory 및 innoDB는 각 비트 열을 저장하기에 충분한 가장 작은 정수 유형을 사용합니다. MySQL은 비트를 문자열 유형으로 처리하고 비트(1) 값을 검색하며 결과는 이진수 0/1을 포함하는 문자열입니다. 시나리오 검색에서는 문자열을 숫자로 변환합니다. 대부분의 애플리케이션에서는 사용하지 않는 것이 가장 좋습니다. 하나의 요소 또는 여러 요소의 조합을 사용할 수 있습니다. 여러 요소를 가져올 때는 쉼표로 구분하세요. SET 타입의 값은 최대 64개 요소의 조합만 가능하며, 멤버에 따라 저장 방법도 다릅니다: [참고, enum과 동일] 4.1.5 비트
bit: mysql5.0
![[MySQL 데이터베이스] 4장 해석: 스키마 및 데이터 유형 최적화(1부)](https://img.php.cn//upload/image/636/907/440/1533621119495187.png "1533621119495187.png")
1~8成员的集合,占1个字节。
9~16成员的集合,占2个字节。
17~24成员的集合,占3个字节。
25~32成员的集合,占4个字节。
33~64成员的集合,占8个字节。
패킹된 비트(저장 공간의 효율적인 사용)로 내부적으로 표시되며 mysql에는 쿼리에 사용하기 편리한 find_in_set 및 필드 함수가 있습니다. 단점: 열 정의 변경 비용 높음, 테이블 변경이 필요하며 집합을 통해 인덱스 검색을 수행할 수 없음
정수 열에 대한 비트별 연산: 집합 대신: 정수를 사용하여 일련의 비트를 묶음: 8비트를 Tinyint로 묶을 수 있고, 비트별 연산을 사용하려면 비트에 대한 이름 상수를 정의하여 이 작업을 단순화하지만 이 쿼리 문은 작성하기 어렵고 이해하기 어렵습니다. : 자동 증가 열 [출처] 1) 값을 수동으로 삽입할 필요가 없습니다. 시스템은 기본 시퀀스 값을 제공합니다. 2) 기본 키와 일치할 필요는 없습니다. 3) 고유 키여야 합니다. 4) 테이블은 최대 1개입니다. 5) 유형은 숫자만 가능합니다. 5) auto_increment_increment=3으로 설정하여 전달할 수 있습니다. ;ID 열 유형을 선택할 때
저장 유형과 mysql이 계산을 수행하는 방법을 고려하세요. 결정한 후에는 모든 관련 테이블에서 동일한 유형을 사용해야 하며 유형이 정확하게 일치해야 합니다.팁:
1. 일반적으로 정수가 가장 좋습니다. 빠르며 auto_increment를 사용할 수 있습니다2. 열거형 및 세트 유형, 고정된 정보 저장3. 문자열: 회피, 숫자보다 느린 공간 소비, myisam 테이블 특히 주의하세요(기본 문자열 압축, 느린 쿼리)
1) 새로운 완전히 "임의의" 문자열 MD5/SHA1/UUID 함수에 의해 생성된 값은 넓은 공간에 임의로 분산되어 삽입 및 일부 선택 변경이 발생합니다. 느림:삽입 값은 인덱스의 다른 위치에 무작위로 기록됩니다
, 삽입이 느려집니다(페이지 분할 디스크가 클러스터형 인덱스 조각에 무작위로 액세스함). 선택이 느려지고논리적으로 인접한 행이 디스크와 메모리의 다른 위치에 분산됩니다.
임의 값으로 인해 모든 유형의 쿼리에 대해 캐시가 덜 효과적입니다. 명령문(액세스 지역성 원칙을 무효화
무효화)클러스터형 인덱스 , 실제 저장된 순차 구조 및 데이터 저장의 물리적 구조 일관되게 말하면 물리적 시퀀스 구조는 하나만 있으며 하나만 있을 수 있습니다. 테이블당 하나의 클러스터형 인덱스. 일반적으로 기본 키를 설정하면 시스템이 기본적으로 클러스터형 인덱스를 추가합니다. [출처] 비클러스터링 인덱스 논리적 순서의 논리적 순서는 반드시 연결될 필요는 없으며 이는 데이터의 저장 물리적 구조와 관련이 없습니다. 테이블에 해당하는 비클러스터 인덱스가 많을 수 있으며 필수 비클러스터형 열이 설정될 수 있습니다. index;
2) uuid를 저장하거나 - 기호를 제거하거나 unhex를 사용하여 uuid 값을 16바이트 숫자로 변환하고 검색할 때 16진수 형식으로 형식을 지정합니다. UUID에서 생성된 값은 암호화 해시 함수(sha1)에서 생성된 값과 다릅니다. 특징: uuid는 고르지 않게 분포되어 있으며 특정 순서를 갖는 것이 좋습니다. 자동 생성된 스키마에 주의하세요.
심각한 성능 문제, 매우 큰 varchar, 다양한 유형의 관련 열 orm은 모든 유형의 백엔드 데이터 저장소에 모든 유형의 데이터를 저장하며 더 나은 유형의 저장소를 사용하도록 설계되지 않았습니다. 때로는 각 객체의 각 속성에 대해 별도의 행을 사용하고 타임스탬프를 사용하도록 설정됩니다. 기반 버전 제어. 단일 속성의 여러 버전이 발생함 관련 기사: 4.1.7 특수 유형 데이터: 비어 있음
위 내용은 [MySQL 데이터베이스] 4장 해석: 스키마 및 데이터 유형 최적화(1부)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!