
Redis 마스터-슬레이브 복제 원칙 및 일반적인 문제

- 咔咔원래의
- 2020-08-28 17:20:512033검색
❝많은 친구들이 이미 마스터-슬레이브 복제를 구성했지만 Redis 마스터-슬레이브 복제의 워크플로와 일반적인 문제에 대한 심층적인 이해가 없다고 생각합니다. Kaka는 이번에 컴파일하는 데 이틀을 보냈습니다. 당신을 위한 사본 Redis 마스터-슬레이브 복제에 대한 모든 지식 포인트
❝
Kaka는 이 로드맵에 따라 작성을 준비하면서 로드맵을 편집하고 인터뷰 가이드를 만들었습니다. 기사에 포함되지 않은 지식 포인트도 나중에 댓글로 추가하겠습니다. 1. Redis 마스터-슬레이브 복제란 무엇인가요? 마스터-슬레이브 복제는 이제 두 개의 Redis 서버가 있고 한 Redis의 데이터가 다른 Redis 데이터베이스와 동기화된다는 의미입니다. 전자를 마스터 노드, 후자를 슬레이브 노드라고 합니다. 데이터는 마스터에서 슬레이브로 한 방향으로만 동기화될 수 있습니다.
그러나 실제 과정에서는 마스터-슬레이브 복제를 위해 두 개의 Redis 서버만 보유하는 것은 불가능합니다. 이는 각 Redis 서버를 마스터 노드(마스터)라고 부를 수 있음을 의미합니다.
아래의 경우, 우리의 슬레이브3는 둘 다입니다 마스터의 슬레이브 노드와 슬레이브의 마스터 노드.
먼저 이 개념을 이해하고, 더 자세한 설명을 보려면 아래를 계속 읽어보세요. 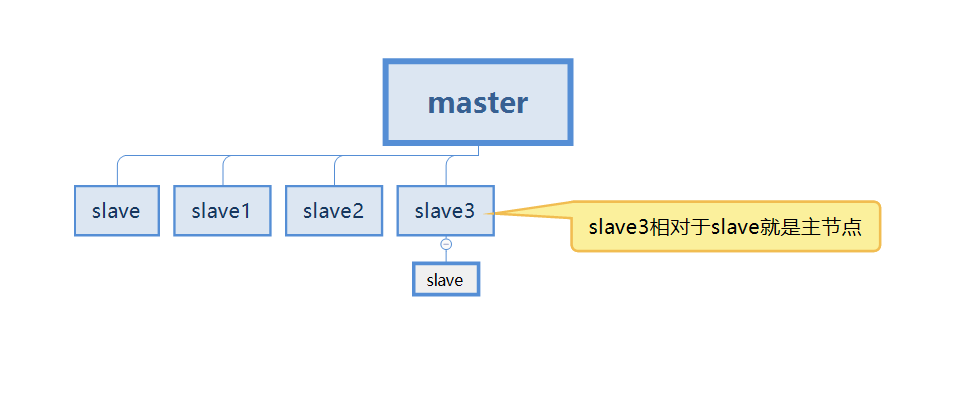
2. Redis 마스터-슬레이브 복제가 필요한 이유는 무엇입니까?
현재 독립형 상태인 Redis 서버가 있다고 가정해 보겠습니다.
이 경우 발생하는 첫 번째 문제는 서버 다운타임으로, 이는 데이터 손실로 직결됩니다. 프로젝트가 RMB와 관련이 있다면 그 결과는 상상할 수 있습니다.
두 번째 상황은 메모리 문제입니다. 서버가 하나만 있으면 메모리는 확실히 정점에 도달합니다.  그래서 위의 두 가지 문제에 대응하여 몇 대의 서버를 더 준비하고 마스터-슬레이브 복제를 구성하도록 하겠습니다. 여러 서버에 데이터를 저장합니다. 그리고 각 서버의 데이터가 동기화되었는지 확인하세요. 서버가 다운되더라도 사용자의 이용에는 영향을 미치지 않습니다. Redis는 계속해서 고가용성과 데이터 중복 백업을 달성할 수 있습니다.
그래서 위의 두 가지 문제에 대응하여 몇 대의 서버를 더 준비하고 마스터-슬레이브 복제를 구성하도록 하겠습니다. 여러 서버에 데이터를 저장합니다. 그리고 각 서버의 데이터가 동기화되었는지 확인하세요. 서버가 다운되더라도 사용자의 이용에는 영향을 미치지 않습니다. Redis는 계속해서 고가용성과 데이터 중복 백업을 달성할 수 있습니다.
이때 마스터와 슬레이브를 어떻게 연결하는지 궁금하신 점이 많을 텐데요. 데이터를 동기화하는 방법은 무엇입니까? 마스터 서버가 다운되면 어떻게 되나요? 걱정하지 말고 문제를 조금씩 해결해 보세요. 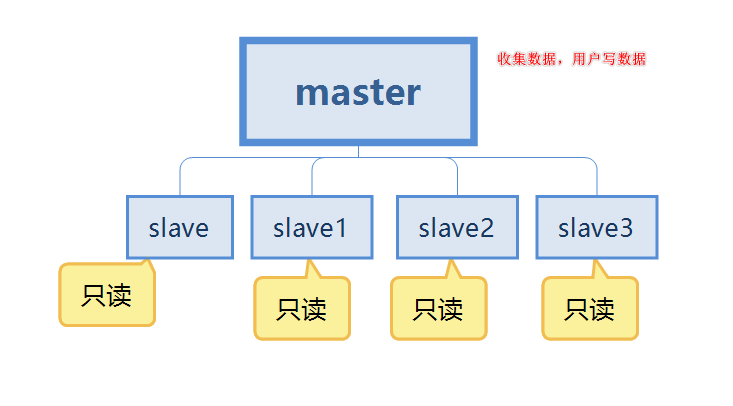
3. Redis 마스터-슬레이브 복제의 역할
위에서 Redis의 마스터-슬레이브 복제를 사용하는 이유에 대해 이야기했는데, 마스터-슬레이브 복제의 역할은 왜 사용되는지 설명하는 것입니다. .
이 다이어그램을 계속 사용하여 에 대해 이야기해 보겠습니다. 첫 번째 요점은 데이터의 핫 백업을 구현하는 데이터 중복성입니다. 이는 지속성 이외의 또 다른 방법입니다. 두 번째 요점은 단일 기계 고장에 관한 것입니다. 마스터 노드에 문제가 발생한 경우, 슬레이브인 슬레이브 노드에서 서비스를 제공할 수 있어 신속한 장애 복구가 가능한 서비스 이중화를 이룬다. 세 번째 포인트는 읽기와 쓰기의 분리입니다. 마스터 서버는 주로 쓰기에 사용되고, 슬레이브는 주로 데이터 읽기에 사용되므로 서버의 로드 용량을 향상시킬 수 있습니다. 동시에 수요 변화에 따라 슬레이브 노드 수를 추가할 수 있습니다. 네 번째 포인트는 로드 밸런싱입니다. 읽기와 쓰기의 분리와 함께 마스터 노드는 쓰기 서비스를 제공하고 슬레이브 노드는 읽기 서비스를 제공하여 서버 부하를 공유합니다. 특히 쓰기가 적고 읽기가 많은 경우에 그렇습니다. , 읽기는 여러 슬레이브 노드를 통해 공유되므로 Redis 서버의 동시성과 로드가 크게 증가할 수 있습니다. 다섯 번째 요점은 고가용성의 초석입니다. 마스터-슬레이브 복제는 Sentinel 및 클러스터 구현의 기초이므로 마스터-슬레이브 복제는 고가용성의 초석이라고 할 수 있습니다.
4. Redis 마스터-슬레이브 복제 구성
말이 많았으니 먼저 마스터-슬레이브 복제 사례를 먼저 구성한 다음 이야기해 보겠습니다. 그것에 대해 구현 원칙.
redis 저장 경로는 usr/local/redis
로그 및 구성 파일이 저장되는 위치: usr/local/redis/data
먼저 redis6379.conf 및 redis6380.conf라는 두 가지 구성 파일을 구성합니다.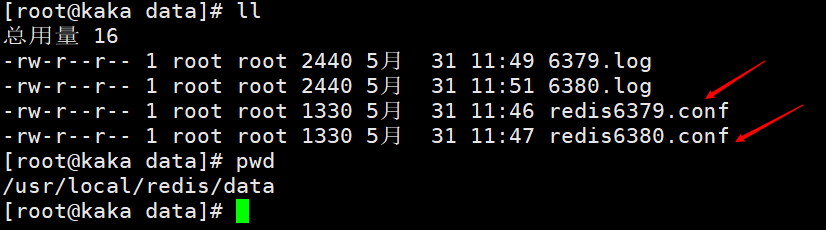 주로 포트를 수정하기 위해 구성 파일을 수정합니다. 보기의 편의를 위해 로그 파일과 영구 파일의 이름은 해당 포트로 식별됩니다.
주로 포트를 수정하기 위해 구성 파일을 수정합니다. 보기의 편의를 위해 로그 파일과 영구 파일의 이름은 해당 포트로 식별됩니다. 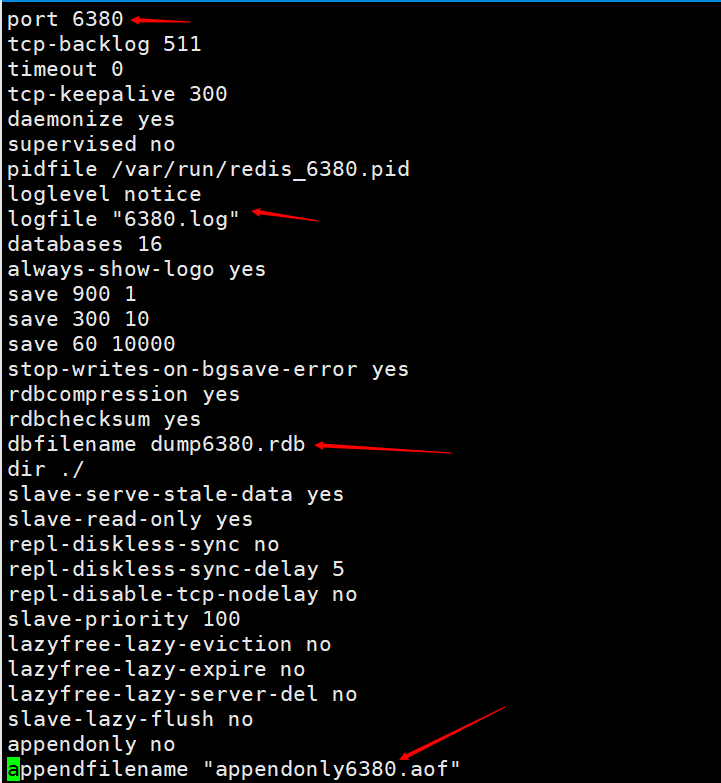 그런 다음 각각 포트 6379와 포트 6380을 사용하여 두 개의 Redis 서비스를 엽니다.
그런 다음 각각 포트 6379와 포트 6380을 사용하여 두 개의 Redis 서비스를 엽니다. redis-server redis6380.conf,然后使用redis-cli -p 6380连接,因为redis的默认端口就是6379所以我们启动另外一台redis服务器直接使用redis-server redis6379.conf 然后直接使用redis-cli 명령을 실행하고 직접 연결하세요.  현재 우리는 두 개의 Redis 서비스를 성공적으로 구성했습니다. 하나는 6380이고 다른 하나는 6379입니다. 이는 단지 데모용입니다. 실제 작업에서는 두 개의 서로 다른 서버에 구성해야 합니다.
현재 우리는 두 개의 Redis 서비스를 성공적으로 구성했습니다. 하나는 6380이고 다른 하나는 6379입니다. 이는 단지 데모용입니다. 실제 작업에서는 두 개의 서로 다른 서버에 구성해야 합니다.
1 클라이언트 명령줄을 사용하여
먼저 개념이 있어야 합니다. 즉, 마스터-슬레이브 복제를 구성할 때 모든 작업은 슬레이브 노드, 즉 슬레이브에서 동작합니다.
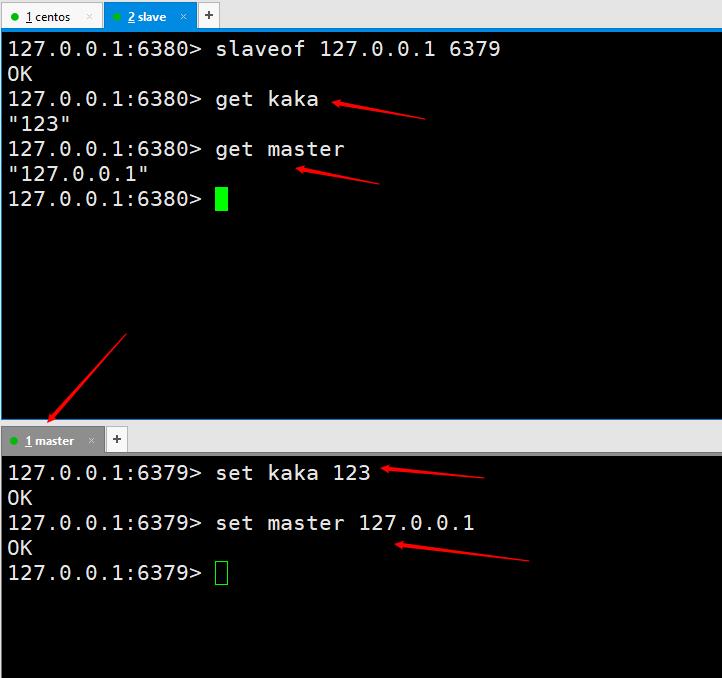
그런 다음 를 실행하면 연결되었다는 의미입니다. <img src="/static/imghwm/default1.png" data-src="https://img-blog.csdnimg.cn/20200531161251477.png" class="lazy" alt="여기에 이미지 설명 삽입" style="max-width:90%">마스터-슬레이브 복제가 달성되었는지 먼저 테스트해 보겠습니다. 두 개의 <code style="overflow-wrap: break-word; margin: 0px 2px;font-family: " operator mono consolas monaco menlo monospace word-break: break- all color : rgb rgba>을 설정하면 Slave6380 포트를 성공적으로 얻을 수 있습니다. 이는 마스터-슬레이브 복제가 구성되었음을 의미합니다. 그러나 프로덕션 환경의 구현이 세상의 종말은 아닙니다. 나중에 고가용성이 달성될 때까지 마스터-슬레이브 복제가 더욱 최적화될 것입니다. <code style="overflow-wrap: break-word; margin: 0px 2px; font-family: " operator mono consolas monaco menlo monospace word-break: break-all color: rgb background: rgba padding: border-radius: height: line-height:>slaveof 127.0.0.1 6379,执行完就代表我们连接上了。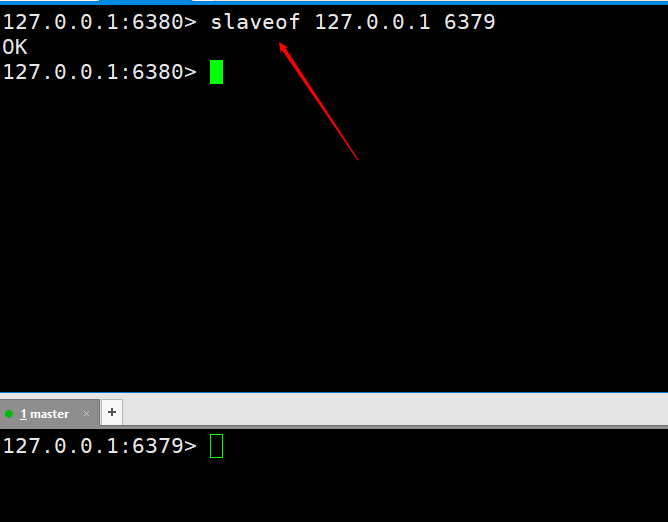 我们先测试一下看是否实现主从复制。在master这台服务器上执行俩个
我们先测试一下看是否实现主从复制。在master这台服务器上执行俩个set kaka 123 和 set master 127.0.0.1,然后在slave6380端口是可以成功获取到的,也就说明我们的主从复制就已经配置完成了。但是在实现生产环境可不是就这样完事了,后边会在进一步对主从复制进行优化,直到实现高可用。
2. 使用配置文件启用
在使用配置文件启动主从复制之前呢!先需要把之前使用客户端命令行连接的断开,在从主机执行slaveof no one即可断开主从复制。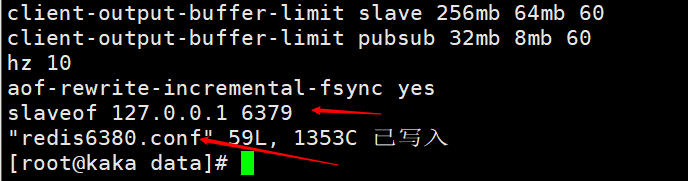 在哪可以查看从节点已经断开了主节点呢!在主节点的客户端输入命令行
在哪可以查看从节点已经断开了主节点呢!在主节点的客户端输入命令行info
누구의 슬레이브도 마스터-슬레이브 복제를 끊을 수 없습니다. 슬레이브 노드가 마스터 노드에서 연결 해제되었는지 어디서 확인할 수 있나요? 마스터 노드의 클라이언트에 명령줄을 입력합니다정보 보기 🎜이 사진은 클라이언트 명령줄을 사용하여 슬레이브 노드를 사용하여 마스터 노드에 연결한 후 클라이언트에서 info 출력된 정보를 보면 Slave0에 대한 정보가 있는 것을 볼 수 있습니다. 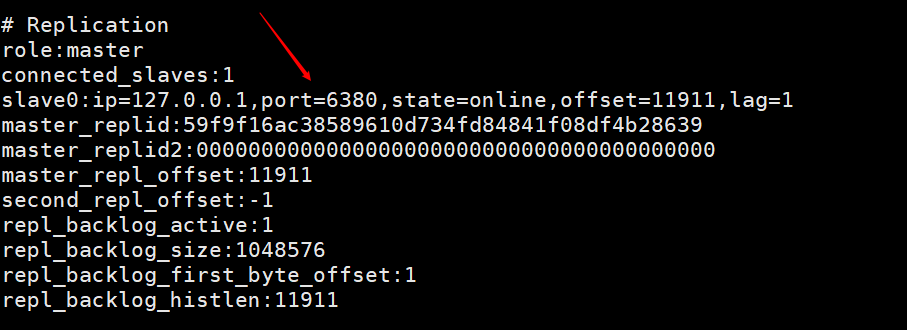 이 이미지는 슬레이브 노드에서 실행됩니다
이 이미지는 슬레이브 노드에서 실행됩니다slaveof no one 이후에는 info, 이는 슬레이브 노드가 마스터 노드에서 연결이 끊어졌음을 나타냅니다. 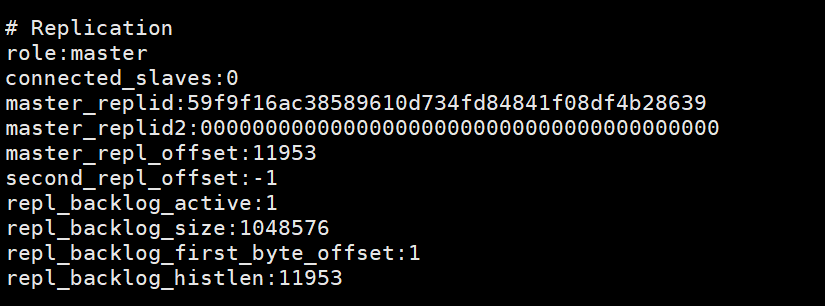 구성 파일에 따라 Redis 서비스를 시작할 때
구성 파일에 따라 Redis 서비스를 시작할 때 redis-server redis6380.confinfo打印的信息,可以看到有一个slave0的一个信息。这个图是在从节点执行完slaveof no one 后,在主节点打印的info,说明从节点已经跟主节点断开连接了。在根据配置文件启动redis服务,redis-server redis6380.conf
当在从节点重新启动后就可以在主节点直接查看到从节点的连接信息。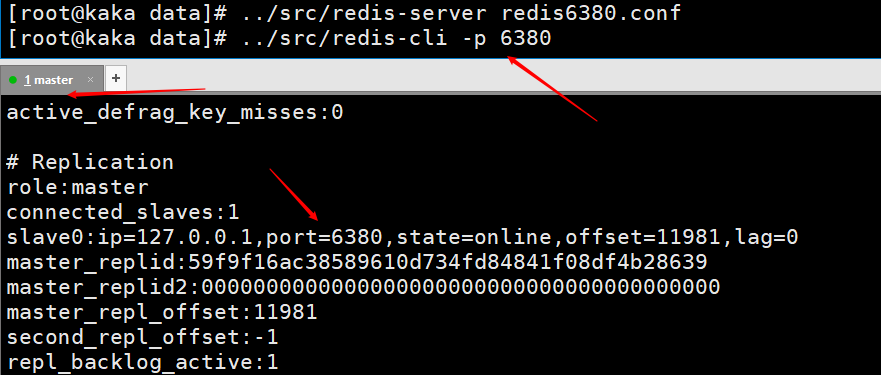 测试数据,主节点写的东西,从节点还是会自动同步的。
测试数据,主节点写的东西,从节点还是会自动同步的。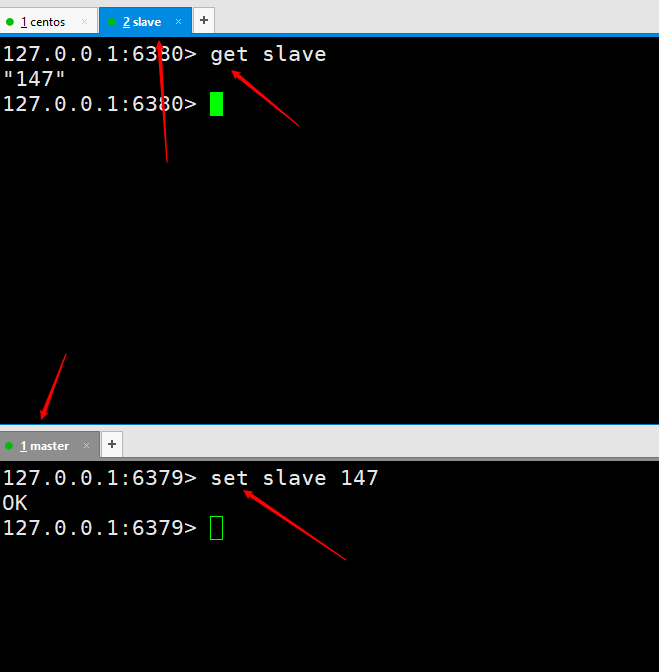
3. 启动redis服务器时启动
这种方式配置也是很简单,在启动redis服务器时直接就启动主从复制,执行命令:redis-server --slaveof host port
테스트 데이터, 마스터 노드가 작성한 내용은 여전히 슬레이브 노드에 의해 자동으로 동기화됩니다. 🎜3. Redis 서버 시작 시 시작
🎜이 구성도 매우 간단합니다. Redis 서버를 시작하면 마스터-슬레이브 복제가 직접 시작됩니다. 명령을 실행하십시오:redis-server --slaveof 호스트 포트 🎜4. 마스터-슬레이브 복제 시작 후 로그 정보를 확인하세요
마스터 노드의 로그 정보입니다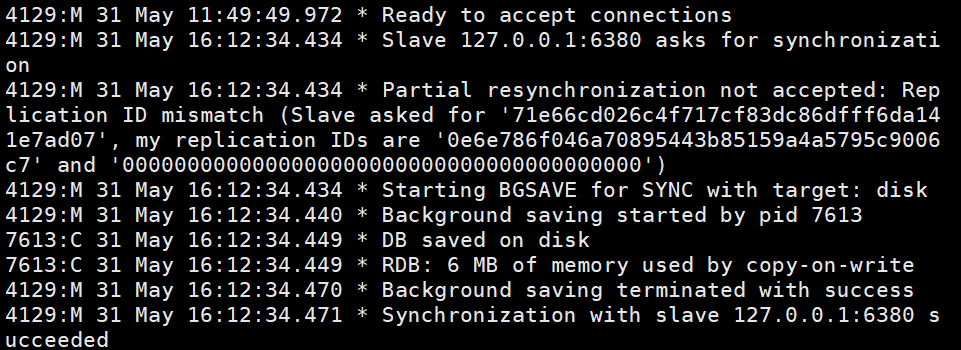 마스터의 연결 정보가 포함된 슬레이브 노드의 정보입니다. 노드 및 RDB 스냅샷 저장.
마스터의 연결 정보가 포함된 슬레이브 노드의 정보입니다. 노드 및 RDB 스냅샷 저장. 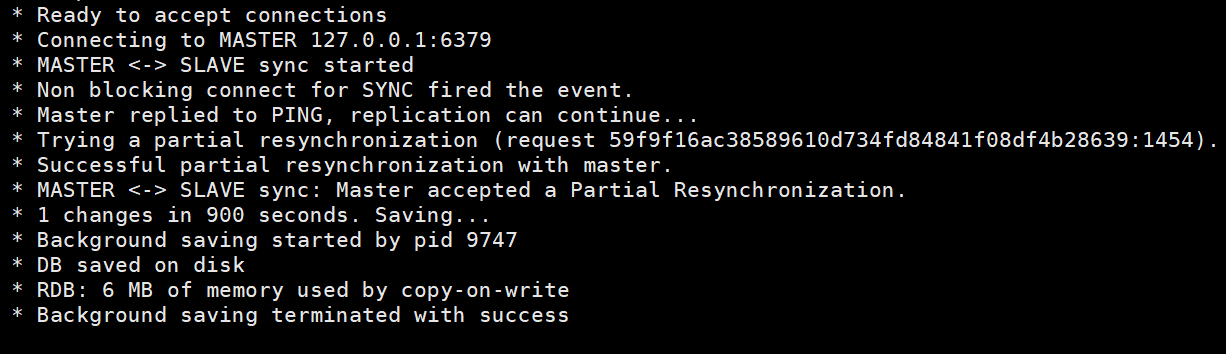
5. 마스터-슬레이브 복제의 작동 원리
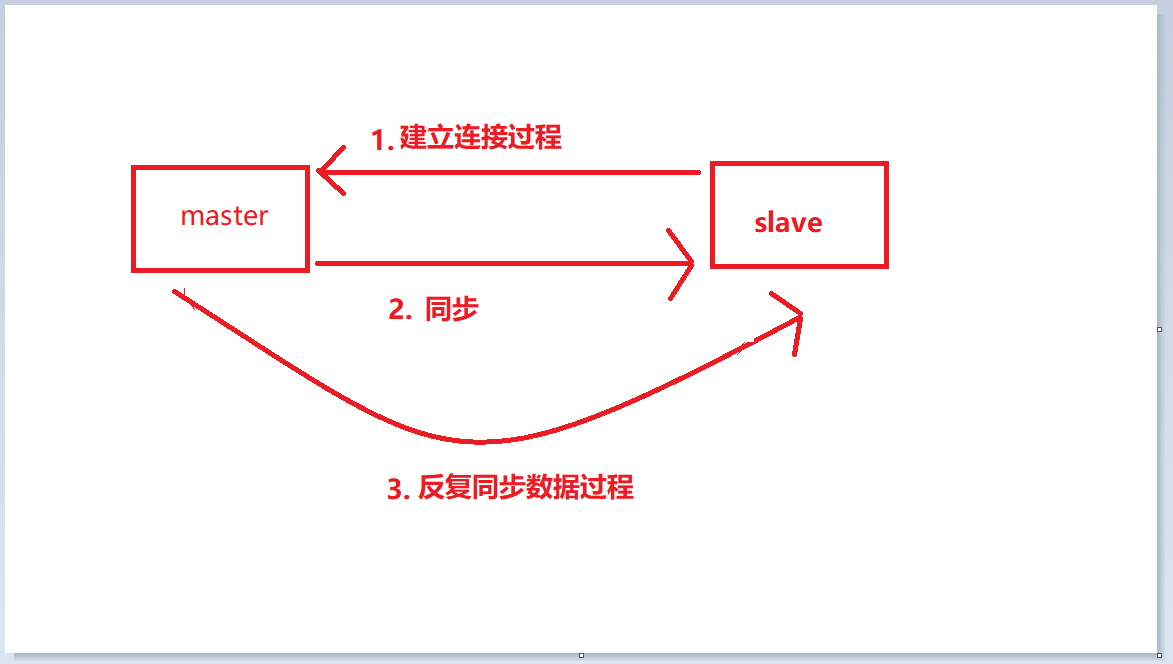
1. 마스터-슬레이브 복제의 3단계
마스터-슬레이브 복제의 전체 작업 흐름은 다음과 같이 나뉩니다. 세 단계. 각 세그먼트에는 고유한 내부 워크플로우가 있으므로 이 세 가지 프로세스에 대해 설명하겠습니다.
연결 설정 프로세스: 슬레이브를 마스터로 연결하는 프로세스 데이터 동기화 프로세스: 마스터가 슬레이브에 데이터를 동기화하는 프로세스 명령 전파 프로세스: 동기화를 반복하는 프로세스 data 
2. 첫 번째 단계: 연결 설정 프로세스
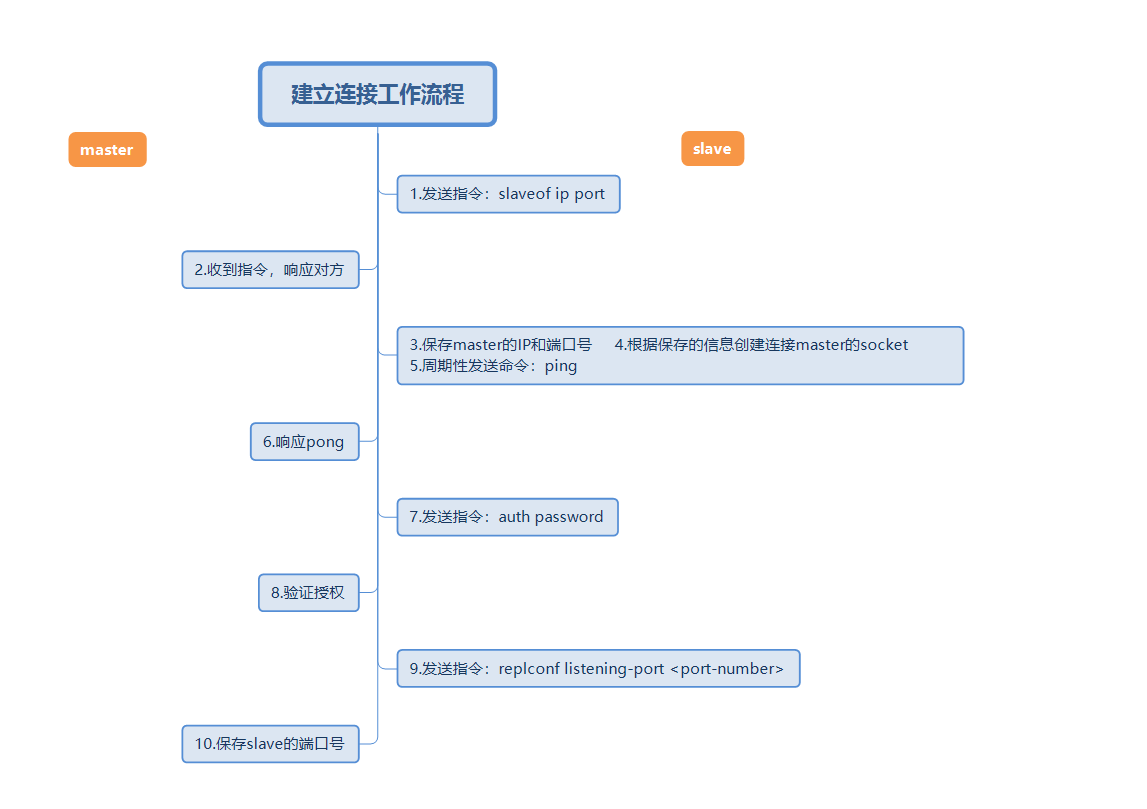 위 그림은 전체 마스터-슬레이브 복제 연결 설정 워크플로입니다. 그런 다음 짧은 단어를 사용하여 위의 작업 흐름을 설명합니다.
위 그림은 전체 마스터-슬레이브 복제 연결 설정 워크플로입니다. 그런 다음 짧은 단어를 사용하여 위의 작업 흐름을 설명합니다.
마스터 주소와 포트 설정, 마스터 정보 저장 소켓 연결 설정(이 연결이 수행하는 작업은 아래 설명됨) 지속적으로 핑 명령 보내기 인증 슬레이브 포트 정보 보내기
연결을 설정하는 과정에서 슬레이브 노드는 마스터의 주소와 포트를 저장하고, 마스터 노드 마스터는 슬레이브 노드의 포트를 저장합니다.
3. 두 번째 단계: 데이터 동기화 단계 프로세스
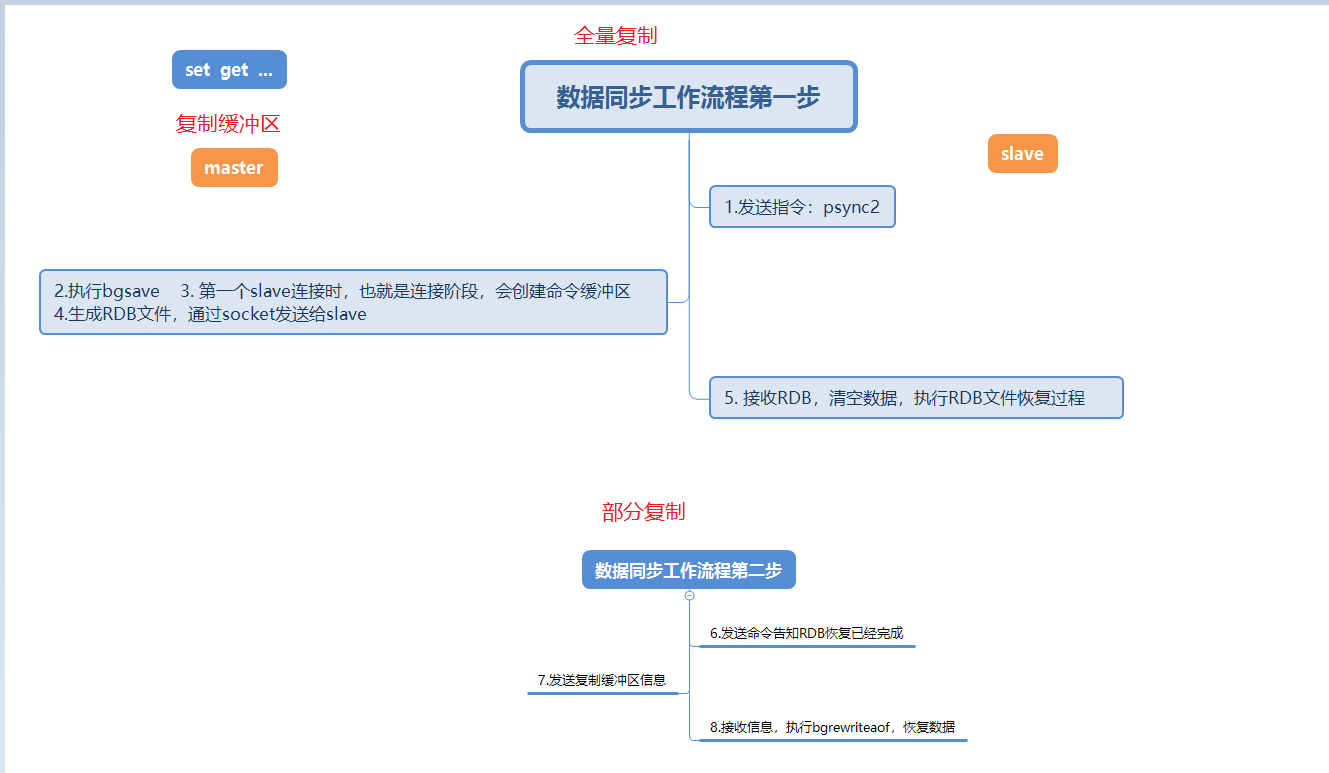 이 그림은 슬레이브 노드가 마스터 노드에 처음 연결될 때 데이터 동기화 프로세스를 자세히 설명합니다.
이 그림은 슬레이브 노드가 마스터 노드에 처음 연결될 때 데이터 동기화 프로세스를 자세히 설명합니다.
슬레이브 노드가 마스터 노드에 처음 연결되면 먼저 전체 복사를 수행합니다. 이 전체 복사는 불가피합니다.
전체 복제가 완료된 후 마스터 노드는 복제 백로그 버퍼에 데이터를 보내고, 슬레이브 노드는 bgrewriteaof를 실행하여 데이터를 복원하는데, 이 역시 부분 복제입니다.
이 단계에서는 전체 복사, 부분 복사, 복사 버퍼 백로그 세 가지 새로운 사항이 언급됩니다. 이러한 사항은 아래 FAQ에서 자세히 설명하겠습니다.
4. 세 번째 단계: 명령 전파 단계
마스터 데이터베이스가 수정되어 마스터와 슬레이브 서버의 데이터가 일치하지 않으면 마스터와 슬레이브 데이터가 일치하도록 동기화됩니다. 프로세스는 명령에 대해 전파(Propagate)라고 합니다.
마스터는 수신한 데이터 변경 명령을 슬레이브에 보내고, 슬레이브는 명령을 받은 후 명령을 실행하여 마스터-슬레이브 데이터를 일치시킵니다.
「명령 전파 단계에서 부분 복제」
명령 전파 단계에서 네트워크 연결이 끊어지거나 네트워크 지터로 인해 연결이 끊어집니다(연결 끊김)
이때 마스터 노드는 계속해서 replbackbuffer(복제 버퍼 백로그 영역)에 데이터를 쓰게 됩니다
슬레이브 노드는 계속해서 마스터에 연결(마스터에 연결)을 시도합니다
슬레이브 노드가 자신의 runid와 복제 오프셋을 넣을 때 마스터 노드로 보내고, pysnc 명령을 실행하여 동기화합니다. 마스터는 오프셋이 복사 버퍼 범위 내에 있다고 판단하면 계속 명령을 반환합니다. 그리고 복사 버퍼의 데이터를 슬레이브 노드로 보냅니다.
슬레이브 노드로부터 데이터를 수신하고 bgrewriteaof를 실행하여 데이터를 복원합니다.
6. 마스터-슬레이브 복제 원리(전체 복제 + 부분 복제)에 대한 자세한 소개
 이 프로세스는 가장 완벽한 마스터-슬레이브 복제 전체 프로세스 설명입니다. 그럼 각 과정을 간략히 소개하겠습니다
이 프로세스는 가장 완벽한 마스터-슬레이브 복제 전체 프로세스 설명입니다. 그럼 각 과정을 간략히 소개하겠습니다
노드에서 명령 보내기 해당 <code style="overflow-wrap: break-word; margin: 0px 2px;font-family: " operator mono consolas monaco menlo monospace word-break: break rgb rgba runid>데이터를 요청합니다. 하지만 여기서는 슬레이브 노드가 처음 연결될 때 마스터 노드의 <code style="overflow-wrap: break-word; margin: 0px 2px; Font-family: " operator mono consolas monaco menlo monospace rgb>runid 및 오프셋. 따라서 전송된 첫 번째 명령은은 마스터 노드의 모든 데이터를 원한다는 의미입니다. <code style="overflow-wrap: break-word; margin: 0px 2px; font-family: " operator mono consolas monaco menlo monospace word-break: break-all color: rgb background: rgba padding: border-radius: height: line-height:>psync ? 1 psync runid offset找对应的runid索取数据。但是这里可以考虑一下,当从节点第一次连接的时候根本就不知道主节点的runid 和 offset。所以第一次发送的指令是psync ? 1意思就是主节点的数据我全要。主节点开始执行bgsave生成RDB文件,记录当前的复制偏移量offset 主节点这个时候会把自己的runid 和 offset 通过 +FULLRESYNC runid offset 指令 通过socket发送RDB文件给从节点。 从节点接收到+FULLRESYNC 保存主节点的runid和offset 然后清空当前所有数据,通过socket接收RDB文件,开始恢复RDB数据。 在全量复制后,从节点已经获取到了主节点的runid和offset,开始发送指令 psync runid offset主节点接收指令,判断runid是否匹配,判断offset是否在复制缓冲区中。 主节点判断runid和offset有一个不满足,就会在返回到步骤 2- 마스터 노드는 bgsave를 실행하여 RDB 파일을 생성하고 현재 복제 오프셋 오프셋을 기록하기 시작합니다.
슬레이브 노드에서 +FULLRESYNC를 수신하고, 마스터 노드의 runid와 오프셋을 저장한 후, 현재 데이터를 모두 지우고, 소켓을 통해 RDB 파일을 수신하고, RDB 데이터 복원을 시작합니다. 🎜🎜🎜🎜전체 복사 후 슬레이브 노드는 마스터 노드의 runid와 오프셋을 획득하고 지침 전송을 시작했습니다
psync runid offset🎜🎜🎜🎜 마스터 노드는 명령을 수신하고 runid가 일치하는지 확인하고 오프셋이 복사 버퍼에 있는지 확인합니다. 🎜🎜🎜🎜마스터 노드가 runid와 offset 중 하나가 만족되지 않는다고 판단하면 2 계속해서 전체 복사를 수행합니다. 여기서 runid 불일치는 슬레이브 노드를 다시 시작해야만 발생할 수 있습니다. 이 문제는 복제 백로그 버퍼 오버플로로 인해 해결될 예정입니다. runid나 offset 검사를 통과한 경우, 슬레이브 노드의 오프셋이 마스터 노드의 오프셋과 같으면 무시됩니다. runid 또는 오프셋 검사를 통과하고 슬레이브 노드의 오프셋이 오프셋과 다른 경우 +CONTINUE 오프셋(이 오프셋은 마스터 노드에 속함)이 전송되고, 슬레이브 노드 오프셋에서 마스터 노드 오프셋으로의 데이터가 전송됩니다. 복제 버퍼는 소켓을 통해 전송됩니다. 🎜🎜🎜🎜노드로부터 +CONTINUE를 받아 마스터의 오프셋을 저장한 후, 소켓을 통해 정보를 받은 후 bgrewriteaof를 실행하여 데이터를 복원합니다. 🎜🎜🎜🎜🎜 "1~4개는 전체 사본, 5~8개는 부분 사본"🎜🎜마스터 노드 3단계에서 마스터-슬레이브 복제 기간 동안 마스터 노드가 클라이언트 데이터를 수신하면서 마스터 노드의 오프셋이 변경되었습니다. 변경 사항만 각 슬레이브에 전송됩니다. 이 전송 프로세스를 하트비트 메커니즘이라고 합니다.
7. 하트비트 메커니즘
명령 전파 단계에서는 항상 마스터 노드와 슬레이브 노드 사이에 통신이 있습니다. 마스터 노드와 슬레이브 노드 간의 연결을 온라인 상태로 유지하려면 정보 교환과 유지 관리를 위한 하트비트 메커니즘을 사용해야 합니다.
master heartbeat
명령: ping 기본값은 10초에 한 번이며 repl-ping-slave-기간 매개변수에 의해 결정됩니다 가장 중요한 것은 슬레이브 노드가 온라인 상태입니다. 슬레이브 노드에서 임대한 후 정보 복제를 사용하여 연결 시간 간격을 확인할 수 있습니다. 지연이 0 또는 1이면 정상입니다. ㅋㅋㅋ 마스터 노드로부터 최신 데이터 변경 명령을 받으면, 또 하나는 마스터 노드가 온라인 상태인지 확인하는 것입니다.
-
"하트비트 단계 중 주의 사항"
데이터 안정성을 보장하기 위해 슬레이브 노드 수가 중단되거나 지연 시간이 너무 높을 때 마스터 노드가 데이터를 보호합니다. 모든 정보 동기화가 거부됩니다.- 구성 조정에는 두 가지 매개변수가 있습니다: min-slaves-to-write 2
- min-slaves-max-lag 8이 두 매개변수는 슬레이브 노드가 2개만 남았음을 나타냅니다. 지연 시간이 8초를 초과하면 마스터 노드는 마스터 기능을 강제로 끄고 데이터 동기화를 중지합니다.
그렇다면 마스터 노드는 장애가 발생한 슬레이브 노드의 수와 지연 시간을 어떻게 알 수 있을까요? 하트비트 메커니즘에서 슬레이브는 매초 perlconf ack 명령을 보냅니다. 이 명령은 오프셋, 슬레이브 노드의 지연 시간 및 슬레이브 노드 수를 전달할 수 있습니다.
8. 부분 복제의 세 가지 핵심 요소
1. 서버의 실행 ID(run id)
먼저 이 실행 ID가 무엇인지 살펴보고 info를 실행해 보겠습니다. 명령을 볼 수 있습니다. 위의 시작 로그 정보를 보면 이를 확인할 수도 있습니다.
Redis는 시작될 때 자동으로 임의 ID를 생성합니다(ID는 시작될 때마다 다르다는 점에 유의해야 합니다). 이는 40개의 임의의 16진수 문자열로 구성되며 Redis 노드를 고유하게 식별하는 데 사용됩니다. . 마스터-슬레이브 복제가 처음 시작되면 마스터는 슬레이브에 runid를 보내고 슬레이브는 마스터의 ID를 저장합니다. info 명령을 사용하여 이를 볼 수 있습니다.
여기에 그림 설명을 삽입하세요. 연결이 끊어졌을 때 슬레이브는 이 ID를 마스터로 보냅니다. 슬레이브가 저장한 runid가 마스터의 현재 runid와 동일하면 마스터는 부분 복제를 시도합니다(또 다른 요소). 이 블록을 성공적으로 복사할 수 있는지 여부는 오프셋입니다. 슬레이브가 저장한 runid가 마스터의 현재 runid와 다를 경우 바로 전체 복사가 수행됩니다.
2. 복사 백로그 버퍼
복사 버퍼 백로그는 사용자가 마스터의 명령 레코드를 저장하여 데이터를 수집하는 선입선출 큐입니다. 복사 버퍼의 기본 저장 공간은 1M입니다.
구성 파일에서 수정 가능
버퍼 크기를 제어합니다. 이 비율은 Kaka가 약 30%를 예약한 서버 메모리에 따라 수정될 수 있습니다. <code style="overflow-wrap: break-word; margin: 0px 2px; font-family: " operator mono consolas monaco menlo monospace word-break: break-all color: rgb background: rgba padding: border-radius: height: line-height:>repl-backlog-size 1mb来控制缓冲区大小,这个比例可以根据自己的服务器内存来修改,咔咔这边是预留出了30%左右。「复制缓冲区到底存储的是什么?」
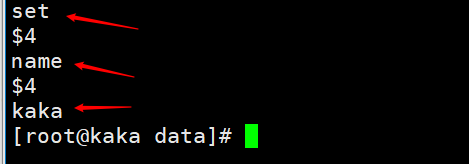
当执行一个命令为
set name kaka「복사 버퍼에 정확히 무엇이 저장되어 있나요?」이름 설정, 영구 파일 보기를 볼 수 있습니다그러면 복사 백로그 버퍼는 영구 데이터로 저장되며 바이트로 구분됩니다. 자체 오프셋. 이 오프셋도 복제 오프셋(offset)입니다
🎜"그럼 왜 복제 버퍼 백로그가 전체 복제를 일으킬 수 있다고 하는 걸까요?"🎜🎜🎜명령 전파 단계에서 마스터 노드는 수집된 데이터를 복제 버퍼에 저장하게 됩니다. 그런 다음 슬레이브 노드로 전송됩니다. 여기서 문제가 발생하는데, 마스터 노드에 있는 데이터의 양이 순간적으로 너무 많아 복제 버퍼의 메모리를 초과하게 되면 일부 데이터가 압착되어 마스터 노드와 슬레이브 노드 사이의 데이터 불일치가 발생하게 됩니다. . 전체 사본을 만들려면 버퍼 크기를 무리하게 설정하면 무한 루프가 발생할 수 있습니다. 슬레이브 노드는 항상 전체를 복사하고 데이터를 지우고 전체를 복사합니다. 🎜3. 복제 오프셋(offset)
마스터 노드 복제 오프셋은 슬레이브 노드에 레코드를 한 번 보내고, 슬레이브 노드가 레코드를 한 번 받는 것입니다. 정보 동기화, 마스터 노드와 슬레이브 노드의 차이 비교, 슬레이브 연결 끊김 시 데이터 사용량 복원 등에 사용됩니다.
이 값은 복사 버퍼 백로그 영역의 오프셋입니다.
9. 마스터-슬레이브 복제 관련 일반적인 문제
1. 마스터 노드 재시작 문제(내부 최적화)
마스터 노드가 재시작되면 runid 값이 변경됩니다. 이로 인해 모든 슬레이브 노드가 완전히 복제됩니다.
이 문제에 대해 생각할 필요는 없습니다. 시스템이 어떻게 최적화되어 있는지 알면 됩니다.
마스터-슬레이브 복제가 설정된 후 마스터 노드는 생성된 전략은 runid와 동일하며 길이는 41비트, runid 길이는 40비트입니다. 슬레이브 노드.
마스터 노드에서 shutdown save 명령이 실행되면 RDB 지속성이 수행되고 runid와 오프셋이 RDB 파일에 저장됩니다. redis-check-rdb 명령을 사용하여 이 정보를 볼 수 있습니다.
마스터 노드가 재시작된 후 RDB 파일을 로드하고, 파일에 있는 repl-id와 repl-offset을 메모리에 로드합니다. 모든 슬레이브 노드가 이전 마스터 노드로 간주되는 경우에도 마찬가지입니다. 2. 슬레이브 노드 네트워크가 중단되고 오프셋이 경계를 넘어 전체 복제가 발생합니다.
네트워크 환경이 좋지 않아 슬레이브 노드 네트워크가 중단됩니다. 복제 백로그 버퍼 메모리가 너무 작아서 데이터 오버플로가 발생하고 슬레이브 노드 오프셋이 경계를 넘으면서 전체 복제가 발생합니다. 이로 인해 전체 복사가 반복될 수 있습니다.
해결책: 복제 백로그 버퍼 크기 수정: repl-backlog-size
설정 제안: 마스터 노드가 슬레이브 노드에 연결하는 데 걸리는 시간을 테스트하고 마스터 노드에서 생성된 평균 총 명령 수를 얻습니다. per second write_size_per_second
복제 버퍼 공간 설정 = 2 * 마스터-슬레이브 연결 시간 * 초당 마스터 노드에서 생성되는 총 데이터 양
3. 높은 CPU로 인한 빈번한 네트워크 중단
마스터 노드를 사용하거나 슬레이브 노드에서 자주 연결하는 경우. 이러한 상황의 결과로 버퍼, 대역폭, 연결 등을 포함하되 이에 국한되지 않는 마스터 노드의 다양한 리소스가 심각하게 점유됩니다.
마스터 노드 자원이 심각하게 점유되는 이유는 무엇인가요?
하트비트 메커니즘에서 슬레이브 노드는 매초 마스터 노드에 replconf ack 명령을 보냅니다. 슬레이브 노드에서 느린 쿼리가 실행되어 CPU를 많이 차지했습니다. 마스터 노드는 1초마다 복제 타이밍 함수인 ReplicationCron을 호출하고, 이후 슬레이브 노드는 오랫동안 응답하지 않습니다.
해결책:
슬레이브 노드 시간 초과 해제 설정
매개변수 설정: repl-timeout
이 매개변수의 기본값은 60초입니다. 60초 후에 슬레이브를 해제합니다.
4. 데이터 불일치 문제
네트워크 요인으로 인해 여러 슬레이브 노드의 데이터가 일치하지 않습니다. 이 요인을 피할 수 있는 방법은 없습니다.
이 문제에 대한 해결책은 두 가지가 있습니다.
첫 번째 데이터는 일관성이 뛰어나고 Redis 서버를 구성해야 하며, 읽기와 쓰기 모두에 하나의 서버를 사용해야 합니다. 이 방법은 소량의 데이터로 제한되며, 일관성이 높아야 합니다.
두 번째는 마스터-슬레이브 노드의 오프셋을 모니터링하는 것입니다. 슬레이브 노드의 지연이 너무 크면 슬레이브 노드에 대한 클라이언트의 액세스가 일시적으로 차단됩니다. 매개변수를slave-serve-stale-data yes|no로 설정합니다. 이 매개변수가 설정되면 info Slaveof와 같은 몇 가지 명령에만 응답할 수 있습니다.
5. 슬레이브 노드 실패
이 문제는 클라이언트에서 사용 가능한 노드 목록을 직접 유지 관리하며, 슬레이브 노드가 실패하면 다른 노드로 전환하여 작업합니다. .
10. 요약
이 문서에서는 주로 마스터-슬레이브 복제가 무엇인지, 마스터-슬레이브 복제 작업의 세 가지 주요 단계, 워크플로 및 부분 복제의 세 가지 핵심에 대해 설명합니다. 명령 전파 단계 중 하트비트 메커니즘. 마지막으로 마스터-슬레이브 복제의 일반적인 문제에 대해 설명합니다.
이 기사는 작성하는 데 이틀이 걸렸습니다. 이것은 Kaka가 최근 작성한 기사 중 가장 긴 기사입니다. 앞으로 Kaka가 게시하는 기사는 단일 문제를 설명하기 위해 여러 기사를 게재하지 않을 것입니다. 한 글로 모두 마치겠습니다. 카카의 지식 포인트가 증가함에 따라 불완전한 지식 포인트나 잘못된 지식 포인트도 개선됩니다. 이 글은 주로 카카 리뷰의 편의를 위한 것입니다. 질문이 있으시면 댓글 섹션을 참조하세요.
Kaka는 모두가 함께 소통하고 배울 수 있기를 바랍니다. 잘못된 점이 있으면 지적해도 됩니다.
❝
배움에 대한 끈기, 블로그에 대한 끈기, 공유에 대한 끈기는 카카가 경력 이후부터 늘 지켜온 신념입니다. 거대한 인터넷에 올라온 카카의 글이 조금이나마 도움이 되기를 바랍니다.
❞추천: "redis 튜토리얼"
 Redis는 시작될 때 자동으로 임의 ID를 생성합니다(ID는 시작될 때마다 다르다는 점에 유의해야 합니다). 이는 40개의 임의의 16진수 문자열로 구성되며 Redis 노드를 고유하게 식별하는 데 사용됩니다. .
Redis는 시작될 때 자동으로 임의 ID를 생성합니다(ID는 시작될 때마다 다르다는 점에 유의해야 합니다). 이는 40개의 임의의 16진수 문자열로 구성되며 Redis 노드를 고유하게 식별하는 데 사용됩니다. . 
 「복사 버퍼에 정확히 무엇이 저장되어 있나요?」
「복사 버퍼에 정확히 무엇이 저장되어 있나요?」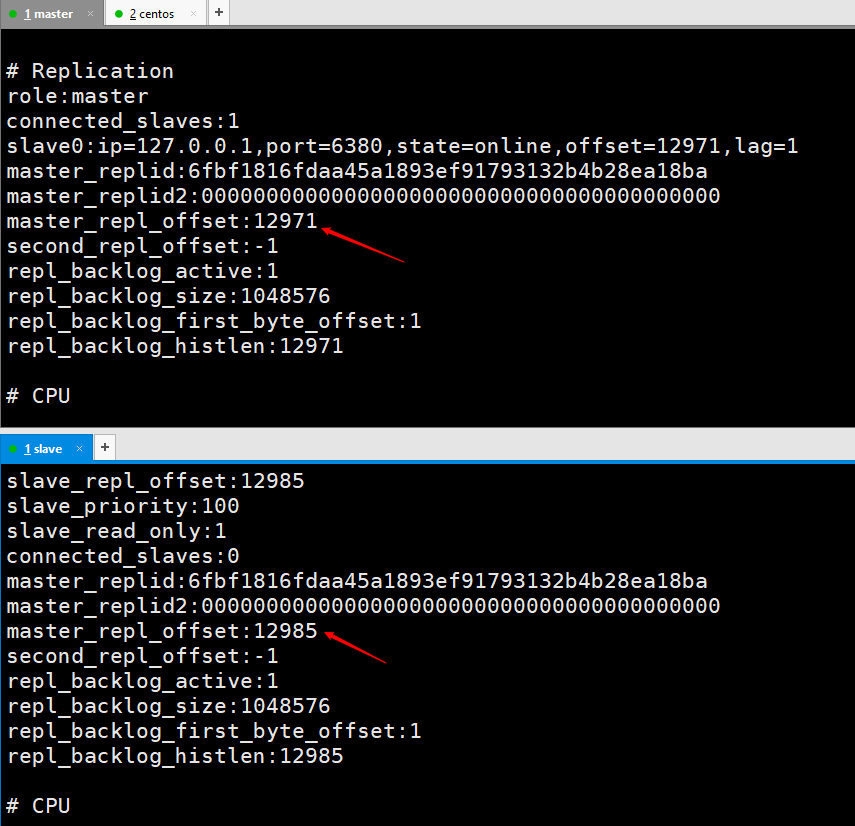 마스터 노드 복제 오프셋은 슬레이브 노드에 레코드를 한 번 보내고, 슬레이브 노드가 레코드를 한 번 받는 것입니다.
마스터 노드 복제 오프셋은 슬레이브 노드에 레코드를 한 번 보내고, 슬레이브 노드가 레코드를 한 번 받는 것입니다. 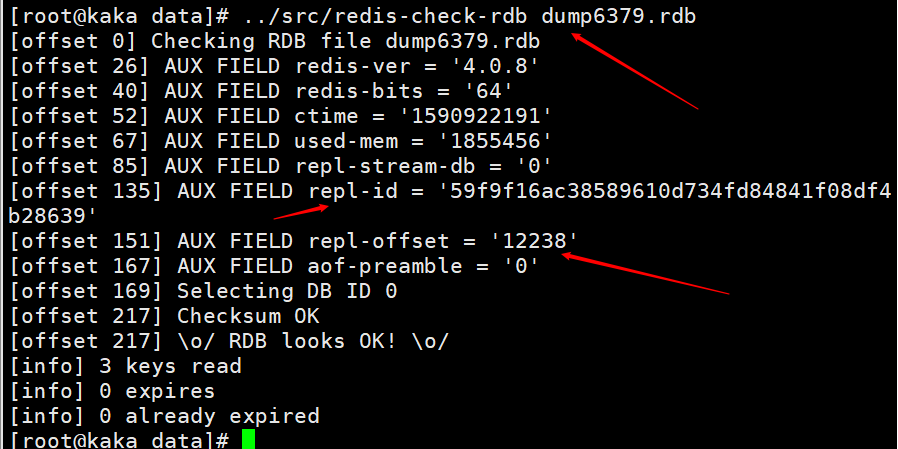 마스터 노드가 재시작된 후 RDB 파일을 로드하고, 파일에 있는 repl-id와 repl-offset을 메모리에 로드합니다. 모든 슬레이브 노드가 이전 마스터 노드로 간주되는 경우에도 마찬가지입니다.
마스터 노드가 재시작된 후 RDB 파일을 로드하고, 파일에 있는 repl-id와 repl-offset을 메모리에 로드합니다. 모든 슬레이브 노드가 이전 마스터 노드로 간주되는 경우에도 마찬가지입니다. 위 내용은 Redis 마스터-슬레이브 복제 원칙 및 일반적인 문제의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!