
Redis의 LRU 알고리즘에 대한 자세한 설명

- 藏色散人앞으로
- 2020-08-27 13:33:394296검색
Redis Tutorial 칼럼에서는 Redis의 LRU 알고리즘에 대해 자세히 설명하겠습니다. 도움이 필요한 친구들에게 도움이 되길 바랍니다!

Redis의 LRU 알고리즘
LRU 알고리즘의 기본 아이디어는 컴퓨터 과학 어디에나 있으며 프로그램의 "지역성 원칙"과 매우 유사합니다. 프로덕션 환경에서는 Redis 메모리 사용량 경보가 발생하더라도 Redis의 캐시 사용량 전략을 이해하는 것이 여전히 유익합니다. 다음은 프로덕션 환경에서의 Redis 사용 전략입니다. 사용 가능한 최대 메모리는 4GB로 제한되며 allkeys-lru 삭제 전략이 채택됩니다. 소위 삭제 전략: Redis 사용량이 4GB와 같은 최대 메모리에 도달했을 때 이때 Redis에 새 키가 추가되면 Redis는 삭제할 키를 선택합니다. 그렇다면 삭제할 적절한 키를 선택하는 방법은 무엇입니까?
CONFIG GET maxmemory
- "maxmemory"
- "4294967296"
CONFIG GET maxmemory-policy
- "maxmemory-policy"
- "allkeys-lru"
공식 문서에서 Using Redis LRU 캐시 설명에는 allkeys-lru, 휘발성-lru 등과 같은 여러 가지 삭제 전략이 제공됩니다. 제 생각에는 무작위성, 최근 키에 액세스한 시간, 키 만료 시간(TTL)
의 세 가지 요소를 선택할 때 고려해야 합니다. 예: allkeys-lru, "count the Historical access times of all " 키, "가장 오래된" 키를 제거하세요. 참고: 여기에 따옴표를 추가했습니다. 실제로 Redis의 특정 구현에서는 모든 키의 최근 액세스 시간을 계산하는 데 비용이 많이 듭니다. 생각해 보세요, 어떻게 해야 할까요?
새 데이터를 추가할 공간을 확보하기 위해 최근에 사용하지 않은(LRU) 키를 먼저 제거하여 키를 제거합니다.
또 다른 예: allkeys-random, 키를 무작위로 선택하여 제거합니다. .
추가된 새 데이터를 위한 공간을 확보하기 위해 무작위로 키를 제거합니다.
또 다른 예: 휘발성-lru는 만료 명령을 사용하여 만료 시간이 설정된 키만 제거하고 LRU 알고리즘에 따라 제거합니다.
새 데이터를 추가할 공간을 확보하기 위해 가장 최근에 사용되지 않은(LRU) 키를 먼저 제거하되 만료 세트가 있는 키 중에서만 제거하여 키를 제거합니다.
또 다른 예: 휘발성- ttl, 만료 명령을 사용하여 만료 시간이 설정된 키만 제거합니다. 생존 시간이 더 짧은 키(TTL KEY가 작을수록)가 먼저 제거됩니다.
만료 세트를 사용하여 키를 제거하고, 추가된 새 데이터를 위한 공간을 확보하기 위해 먼저 TTL(수명)이 더 짧은 키를 제거해 보십시오.
휘발성 전략(제거 방법) 키는 다음과 같습니다. 만료 시간이 설정된 것. redisDb 구조에서는 만료 명령을 사용하여 만료 시간이 설정된 모든 키를 저장하기 위해 만료라는 사전(dict)이 정의되어 있습니다. 만료 사전의 키는 redis 데이터베이스 키 공간(redisServer--->redisDb)을 가리킵니다. --->redisObject), 만료 사전의 값은 이 키의 만료 시간(long 유형 정수)입니다. 추가 언급: redis 데이터베이스 키 공간은 redisDb 구조에 정의되고 해시 사전 유형에 정의된 "dict"라는 포인터를 의미하며, 이는 redis DB의 각 키 개체와 해당 값 개체를 저장하는 데 사용됩니다.
전략이 너무 많으니 어떤 전략을 사용해야 할까요? 여기에는 Redis의 Key 액세스 패턴(access-pattern)이 포함됩니다. 액세스 패턴은 코드의 비즈니스 로직과 관련이 있습니다. 예를 들어 특정 특성을 충족하는 키에는 액세스하는 경우가 많지만 다른 키에는 거의 사용되지 않습니다. 모든 키가 애플리케이션에서 액세스할 수 있는 기회가 동일하다면 해당 액세스 패턴은 균일한 분포를 따르며 대부분의 경우 액세스 패턴은
(power-law distribution)을 따릅니다. 주요 패턴 역시 시간이 지남에 따라 변경될 수 있으므로 다양한 상황을 catch(캡처) 위해 적절한 삭제 전략이 필요합니다. 전력 분배 측면에서 LRU는 좋은 전략입니다.
캐시는 미래를 예측할 수 없지만 다음과 같이 추론할 수 있습니다.다시 요청될 가능성이 있는 키는 최근에 자주 요청된 키입니다. 일반적으로 액세스 패턴은 갑자기 바뀌지 않으므로 이는 효과적인 전략입니다.
Redis에서 LRU 전략 구현
가장 직관적인 아이디어: LRU, 각 키의 가장 최근 액세스 시간을 기록합니다(예: unix 타임스탬프) . Unix 타임스탬프의 가장 작은 키는 최근에 사용되지 않은 키입니다. HashMap이 그것을 할 수 있는 것 같습니다. 예, 하지만 먼저 각 키와 해당 타임스탬프를 저장해야 합니다. 둘째, 최소값을 얻으려면 타임스탬프를 비교해야 합니다. 비용은 매우 높고 비현실적입니다.
두 번째 방법: 또 다른 관점에서 볼 때 특정 접속 시점(unix 타임스탬프)을 기록하지 않고 유휴 시간을 기록합니다. 유휴 시간이 작을수록 최근에 접속했다는 의미입니다.
LRU 알고리즘은 유휴 시간이 가장 긴 키를 의미하는 가장 최근에 사용된 키를 제거합니다.
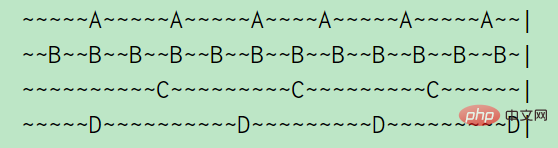
예를 들어 A, B, C, D 네 개의 키의 경우 A는 5초마다 액세스되고 B는 2초마다 액세스되고 C와 D는 10초마다 액세스됩니다. (물결표는 1초를 나타냄) 위 그림에서 알 수 있듯이 A의 유휴 시간은 2초, B의 유휴 시간은 1초, C의 유휴 시간은 5초, D가 방금 방문했으므로 유휴 시간은 0초입니다
여기서는 이중으로 사용하세요. 모든 키를 연결하려면 키를 연결 목록의 맨 위로 이동하세요. 키를 제거하려면 목록 끝에서 직접 제거하세요.
주어진 키에 마지막으로 액세스한 시간을 추적하기만 하면 되므로 구현하기가 간단합니다. 때로는 이것이 필요하지도 않습니다. 제거하려는 모든 객체를 연결 목록에 연결했을 수도 있습니다. .
하지만 Redis에서는 LinkedList가 너무 많은 공간을 차지하는 느낌이 듭니다. Redis는 문자열, 연결 목록, 사전과 같은 데이터 구조를 기반으로 KV 데이터베이스를 직접 구현하지 않고 이러한 데이터 구조를 기반으로 객체 시스템 Redis 객체를 생성합니다. 24비트 부호 없는 유형 필드는 명령 프로그램에서 객체에 마지막으로 액세스한 시간을 저장하기 위해 redisObject 구조에 정의되어 있습니다.
Redis 객체 구조를 약간 수정하여 24비트 공간을 만들 수 있었습니다. 연결된 목록의 개체를 연결할 공간이 없었습니다(뚱뚱한 포인터!)
결국 완전히 정확한 LRU 알고리즘은 필요하지 않습니다. 최근에 액세스한 키가 제거되더라도 영향은 크지 않습니다.
이 메타데이터를 가져오기 위해 다른 데이터 구조를 추가하는 것은 옵션이 아니었습니다. 그러나 LRU 자체가 우리가 달성하려는 것에 대한 근사치이므로 LRU 자체를 근사화하는 것은 어떻습니까?
원래 Redis는 다음과 같이 구현되었습니다:
Random 3개의 키를 선택하고 유휴 시간이 가장 긴 키를 제거합니다. 나중에 3은 구성 가능한 매개변수로 변경되었으며 기본값은 N=5였습니다. maxmemory-samples 5
키를 제거해야 할 경우 무작위로 3개의 키를 선택하고 유휴 시간이 가장 긴 키를 제거하세요
그렇게 간단합니다 , 믿을 수 없을 정도로 간단하고 매우 효과적입니다. 하지만 여전히 단점이 있습니다: 무작위로 선택될 때마다 역사 정보가 사용되지 않습니다. 각 라운드에서 키를 제거(제거)할 때 N에서 키를 무작위로 선택하고 다음 라운드에서 유휴 시간이 가장 큰 키를 제거하고 N에서 키를 무작위로 선택합니다. 과거: In에 대해 생각해 보셨나요? 지난 라운드에서 Key를 제거하는 과정을 통해 실제로 N Key의 유휴 시간을 알고 있었는데, 이전 라운드에서 배운 정보 중 일부를 다음 라운드에서 Key를 제거할 때 잘 활용할 수 있을까요?
그러나 이 알고리즘의 실행을 전반적으로 생각하면 우리가 어떻게 많은 흥미로운 데이터를 폐기하고 있는지 알 수 있습니다. 어쩌면 N 키를 샘플링할 때 좋은 후보를 많이 만나게 되지만 그런 다음에는 그냥 제거합니다. 최선을 다하고 다음 사이클을 처음부터 다시 시작하세요.
처음부터 시작하는 것은 정말 어리석은 일입니다. 그래서 Redis는 또 다른 개선을 이루었습니다: 버퍼 풀링(풀링) 사용
각 라운드에서 키가 제거될 때 유휴 시간이 풀에 있는 키의 유휴 시간보다 길면 이러한 N 키의 유휴 시간이 얻어집니다. 크기가 크면 수영장에 추가하세요. 이런 방식으로 매번 제거되는 키는 무작위로 선택된 N 키 중 가장 클 뿐만 아니라 풀에서 유휴 시간도 가장 길며, 풀에 있는 키는 여러 차례의 비교를 통해 선별되었으며 유휴 상태입니다. 시간 무작위로 획득한 키의 유휴 시간보다 시간이 더 클 가능성이 높습니다. 이는 다음과 같이 이해될 수 있습니다. 풀에 있는 키는 "과거 경험 정보"를 유지합니다.
기본적으로 N 키 샘플링이 수행될 때 더 큰 키 풀(기본적으로 16개 키)을 채우는 데 사용되었습니다. 이 풀에는 유휴 시간별로 정렬된 키가 있으므로 새 키는 키가 있을 때만 풀에 들어갑니다. 풀에 하나의 키보다 긴 유휴 시간이 있거나 풀에 빈 공간이 있을 때.
"풀"을 사용하면 전역 정렬 문제가 로컬 비교 문제로 변환됩니다. (정렬은 본질적으로 비교이지만, 囧). 유휴 시간이 가장 큰 키를 알기 위해서는 정확한 LRU가 전역 키의 유휴 시간을 정렬한 다음 유휴 시간이 가장 큰 키를 찾아야 합니다. 그러나 대략적인 아이디어를 채택할 수 있습니다. 즉, 전역 키를 나타내는 여러 키를 무작위로 샘플링하고, 샘플링을 통해 얻은 키를 풀에 넣고, 각 샘플링 후에 풀을 업데이트하여 풀에 있는 키가 무작위로 선택된 키 중 유휴 시간이 가장 긴 키가 항상 저장됩니다. 퇴거 키가 필요한 경우 유휴 시간이 가장 긴 키를 풀에서 직접 꺼내어 퇴거시킵니다. 이 아이디어는 배울 가치가 있습니다.
이제 LRU 기반 제거 전략 분석이 완료되었습니다. Redis에는 LFU(액세스 빈도)를 기반으로 한 제거 전략도 있는데 이에 대해서는 나중에 설명하겠습니다.
JAVA의 LRU 구현
JDK의 LinkedHashMap은 다음 구성 방법을 사용하여 LRU 알고리즘을 구현합니다. accessOrder는 "가장 최근에 사용된" 측정값을 나타냅니다. 예를 들어, accessOrder=true는 java.util.LinkedHashMap#get 요소를 실행할 때 이 요소가 최근에 액세스되었음을 의미합니다.
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
다시 작성: java.util.LinkedHashMap#removeEldestEntry 메소드.
새 매핑이 지도에 추가될 때 오래된 매핑을 자동으로 제거하는 정책을 적용하기 위해 {@link #removeEldestEntry(Map.Entry)} 메서드를 재정의할 수 있습니다.
스레드 안전성을 보장하려면 컬렉션을 사용하세요. syncedMap LinkedHashMap 객체 래핑:
이 구현은 동기화되지 않습니다. 여러 스레드가 연결된 해시 맵에 동시에 액세스하고 스레드 중 적어도 하나가 맵을 구조적으로 수정하는 경우 이는 일반적으로 동기화를 통해 수행되어야 합니다.
구현은 다음과 같습니다: (org.elasticsearch.transport.TransportService)
final Map<Long, TimeoutInfoHolder> timeoutInfoHandlers =
Collections.synchronizedMap(new LinkedHashMap<Long, TimeoutInfoHolder>(100, .75F, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > 100;
}
});
용량이 100을 초과하면 LRU 정책 실행을 시작합니다. 즉, 최근에 사용되지 않은 TimeoutInfoHolder 객체를 제거합니다.
참조 링크:
- Redis LRU 알고리즘 개선에 대한 무작위 참고 사항
- Redis를 LRU 캐시로 사용
마지막으로 이 기사와 관련 없는 내용에 대해 이야기해 보겠습니다. 데이터 처리에 대한 몇 가지 생각:
5G는 가능합니다. 다양한 종류의 노드가 네트워크에 연결되면 대량의 데이터가 생성됩니다. 이 데이터를 어떻게 효율적으로 처리하고 데이터 뒤에 숨겨진 패턴(머신 러닝, 딥 러닝)을 마이닝하는지는 매우 흥미로운 일입니다. 인간 행동의 객관적인 반영. 예를 들어 WeChat Sports의 걸음 수 계산 기능을 사용하면 다음과 같은 정보를 확인할 수 있습니다. 안녕하세요, 내 활동 수준이 매일 약 10,000걸음인 것으로 나타났습니다. 한걸음 더 나아가, 미래에는 다양한 산업용 장비와 가전제품이 다양한 데이터를 생성할 것이며, 이러한 데이터는 소셜 비즈니스 활동과 인간 활동의 구체화가 될 것입니다. 이 데이터를 합리적으로 활용하는 방법은 무엇입니까? 기존 스토리지 시스템이 이 데이터의 스토리지를 지원할 수 있습니까? 데이터에 숨겨진 가치를 분석할 수 있는 효율적인 컴퓨팅 시스템(스파크 또는 텐서플로우...)이 있습니까? 또한, 이러한 데이터를 기반으로 훈련된 알고리즘 모델은 적용 후 편향을 가져올까요? 데이터 오용은 없나요? 온라인으로 물건을 구매할 때 알고리즘이 물건을 추천합니다. Moments를 탐색할 때 타겟 광고가 게재됩니다. 모델은 또한 뉴스를 읽을 때 빌려야 할 금액과 빌려주고 싶은 금액을 평가합니다. 그리고 엔터테인먼트 가십. 당신이 매일 보고 접촉하는 많은 것들은 이러한 "데이터 시스템"에 의해 내려진 결정들입니다. 정말 공정합니까? 현실에서는 실수를 했을 때 선생님, 친구, 가족들이 피드백과 수정을 해주고 바꾸면 처음부터 다시 시작하면 됩니다. 하지만 이러한 데이터 시스템에서는 어떻습니까? 오류 수정을 위한 피드백 메커니즘이 있습니까? 사람들이 점점 더 깊이 가라앉도록 자극할 것인가? 당신이 올바르고 신용이 좋다 하더라도 알고리즘 모델에는 여전히 확률 편향이 있을 수 있습니다. 이것이 인간의 "공정한 경쟁" 기회에 영향을 미칠까요? 이는 데이터 개발자가 생각해 볼 만한 질문입니다.
원문: https://www.cnblogs.com/hapjin/p/10933405.html
위 내용은 Redis의 LRU 알고리즘에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!