
하이브리드 전문가는 더욱 적극적이며 다양한 양상을 인식하고 상황에 따라 행동할 수 있습니다. Meta는 양상 인식 전문가 하이브리드를 제안합니다.

- 王林원래의
- 2024-08-11 13:02:22429검색
하이브리드 전문가들도 수술 분야에 전문성을 갖고 있습니다.


논문 제목: MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts 논문 주소: https://arxiv.org/pdf/2407.21770

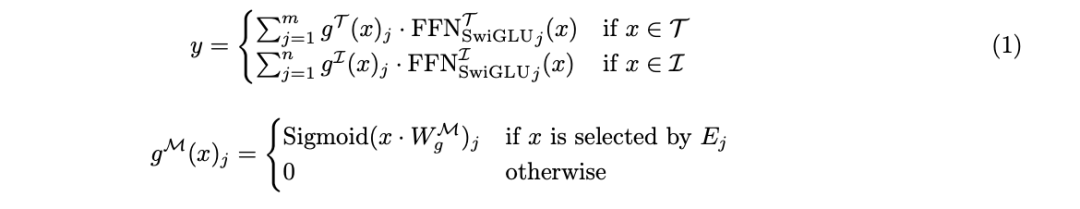


각 양식의 전문가를 동질적인 전문가로 제한하고 금지합니다. 텍스트 토큰을 이미지 전문가에게 전달하거나 그 반대로 라우팅합니다. 블록 희소성을 사용하여 실행 효율성을 높입니다. 양식 수가 제한되면 시퀀스 전문가에서 다양한 양식을 실행하세요.






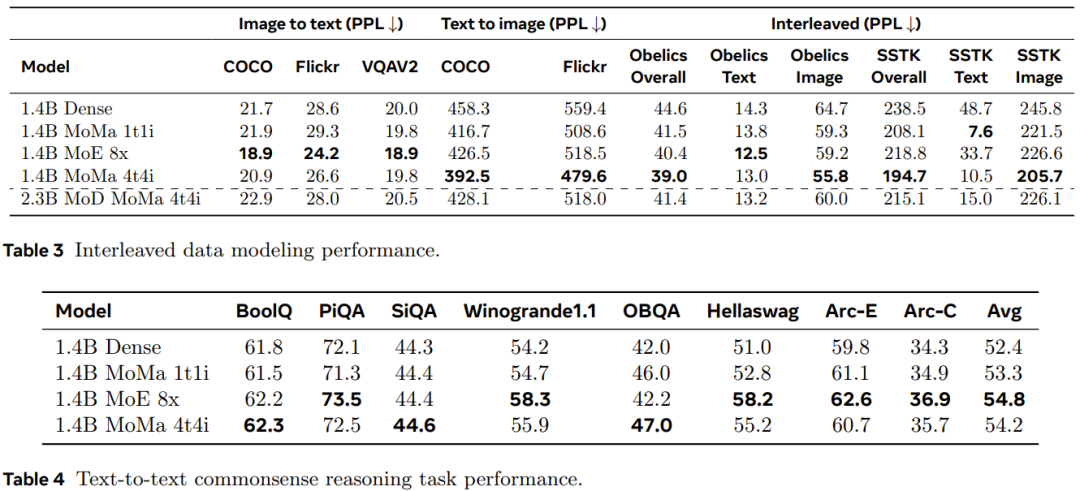
위 내용은 하이브리드 전문가는 더욱 적극적이며 다양한 양상을 인식하고 상황에 따라 행동할 수 있습니다. Meta는 양상 인식 전문가 하이브리드를 제안합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.