
비디오 모델에 빠르고 느린 눈을 추가하면 훈련이 필요 없는 Apple의 새로운 방법이 모든 SOTA를 몇 초 만에 능가합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2024-08-11 16:02:31573검색
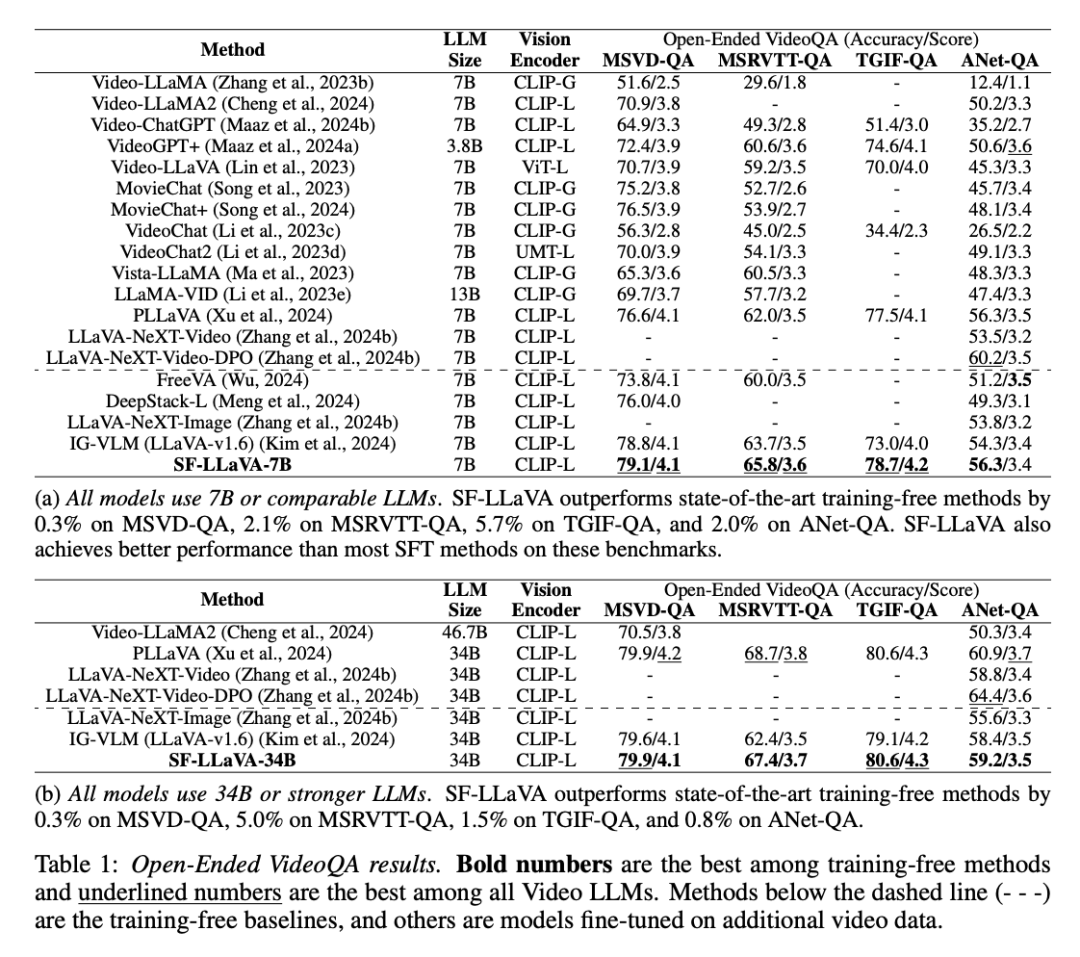
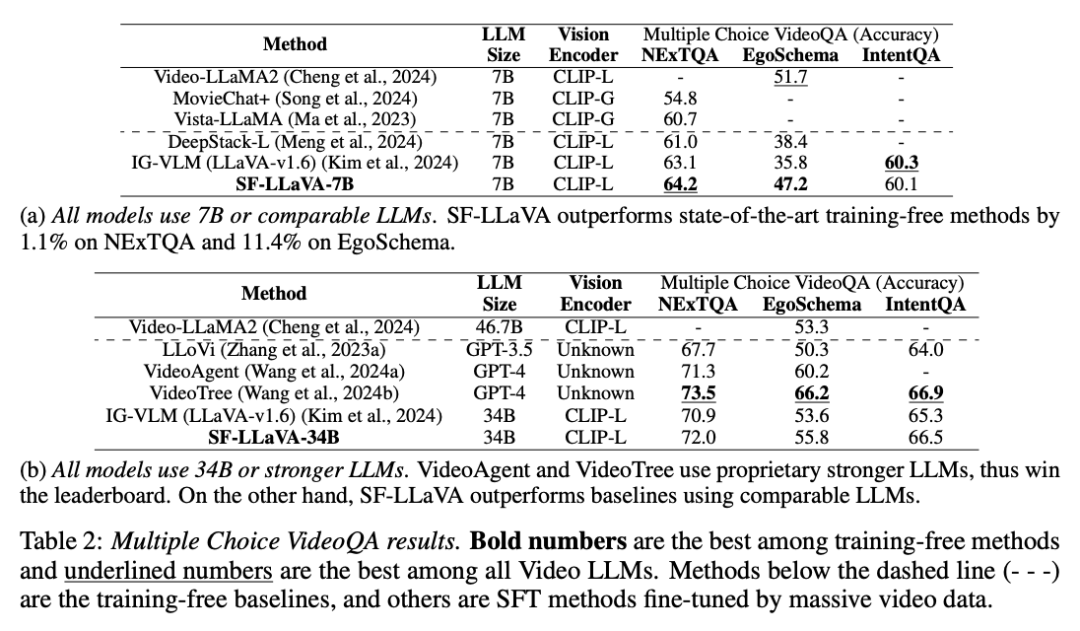
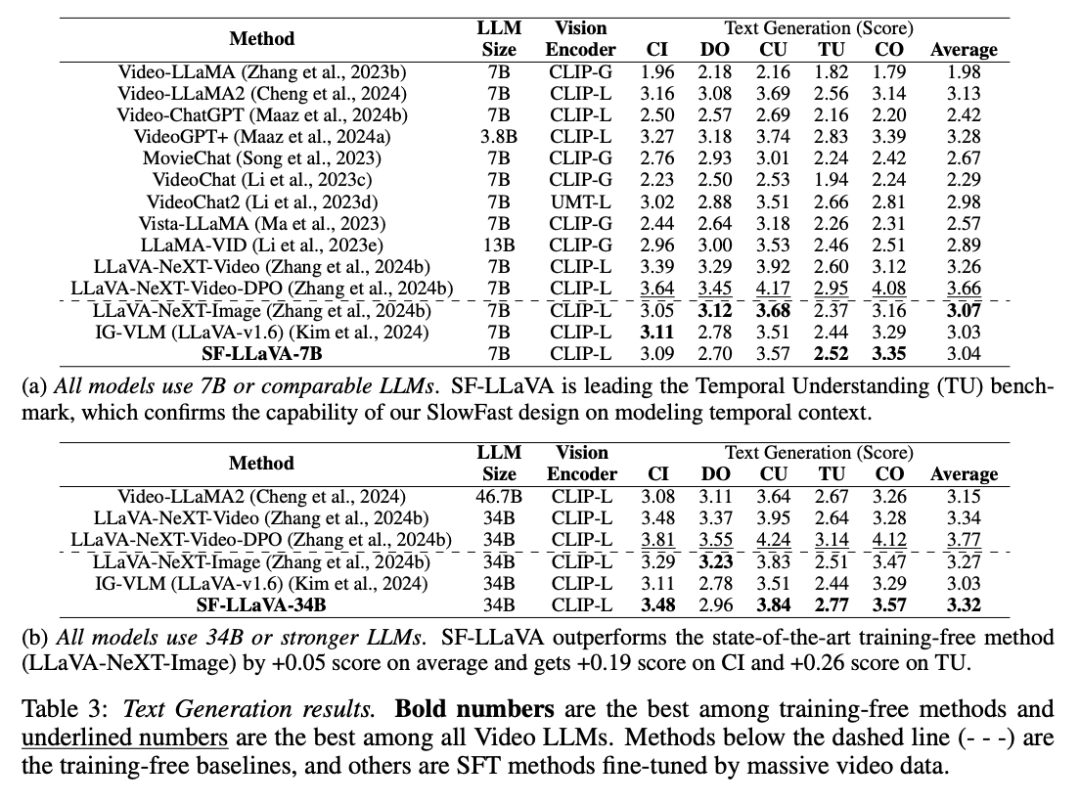
느린 경로: 가능한 한 많은 공간 세부 정보를 유지하면서 낮은 프레임 속도에서 특징을 추출합니다(예: 8프레임마다 24×24 토큰 유지) 빠른 경로: 높은 프레임 속도로 실행하지만 사용 더 큰 시간적 맥락을 시뮬레이션하고 행동의 일관성을 이해하는 데 더 집중하기 위해 비디오의 해상도를 줄이기 위한 더 큰 공간 풀링 단계 크기



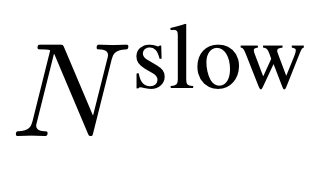 à partir de F_v, où
à partir de F_v, où 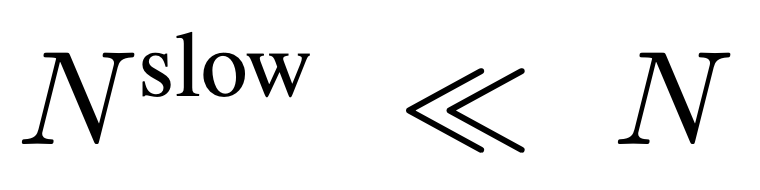 .
. 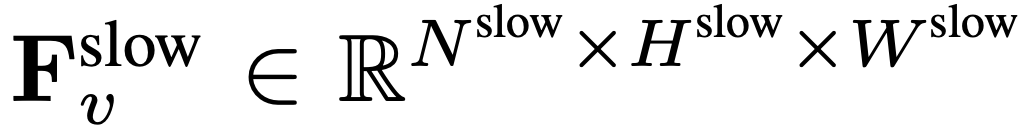 , où
, où 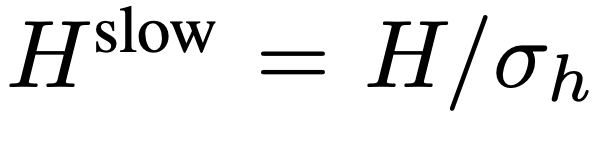 ,
, 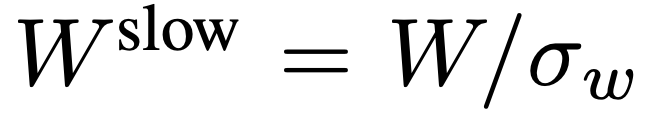 . L’ensemble du processus du chemin lent est illustré dans l’équation 2.
. L’ensemble du processus du chemin lent est illustré dans l’équation 2. 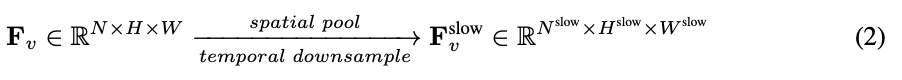
 pour sous-échantillonner de manière agressive F_v afin d’obtenir la caractéristique finale
pour sous-échantillonner de manière agressive F_v afin d’obtenir la caractéristique finale 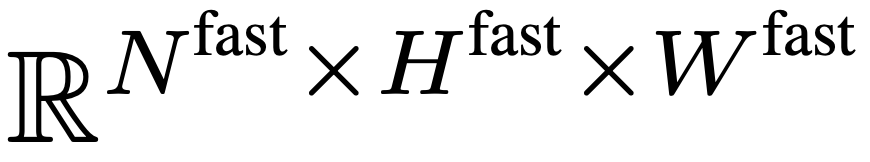 . L'équipe de recherche a mis en place
. L'équipe de recherche a mis en place  ,
, 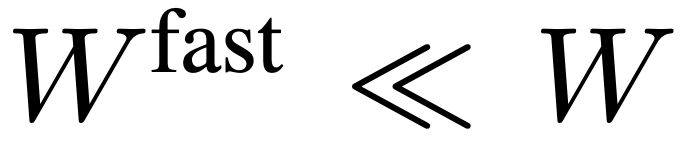 afin que la voie rapide puisse se concentrer sur la simulation du contexte temporel et des signaux de mouvement. L’ensemble du processus du chemin lent est illustré dans l’équation 3.
afin que la voie rapide puisse se concentrer sur la simulation du contexte temporel et des signaux de mouvement. L’ensemble du processus du chemin lent est illustré dans l’équation 3. 
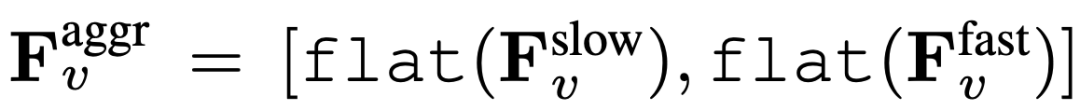 , où flat et [, ] représentent respectivement les opérations d'aplatissement et de concaténation. Comme le montre l'expression,
, où flat et [, ] représentent respectivement les opérations d'aplatissement et de concaténation. Comme le montre l'expression, 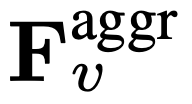 ne nécessite aucun jeton spécial pour séparer les chemins lents et rapides. SF-LLaVA utilise un total de
ne nécessite aucun jeton spécial pour séparer les chemins lents et rapides. SF-LLaVA utilise un total de 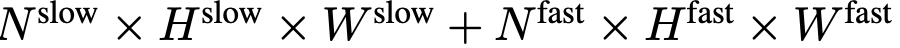 jetons vidéo. Les caractéristiques visuelles de la vidéo
jetons vidéo. Les caractéristiques visuelles de la vidéo 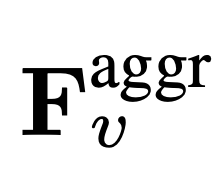 seront combinées avec des informations textuelles (telles que les questions posées par les utilisateurs) et envoyées comme données d'entrée à un grand modèle de langage (LLM) pour traitement.
seront combinées avec des informations textuelles (telles que les questions posées par les utilisateurs) et envoyées comme données d'entrée à un grand modèle de langage (LLM) pour traitement. 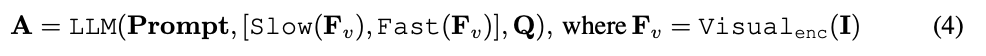
위 내용은 비디오 모델에 빠르고 느린 눈을 추가하면 훈련이 필요 없는 Apple의 새로운 방법이 모든 SOTA를 몇 초 만에 능가합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.