
YOLOv10이 왔습니다! 진정한 실시간 엔드투엔드 표적 탐지

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2024-06-09 17:29:311177검색
지난 몇 년 동안 YOLO는 계산 비용과 감지 성능 간의 효과적인 균형으로 인해 실시간 객체 감지 분야의 주류 패러다임이 되었습니다. 연구자들은 YOLO의 구조 설계, 최적화 목표, 데이터 개선 전략 등에 대해 심층적인 탐구를 수행하여 상당한 진전을 이루었습니다. 그러나 NMS(Non-Maximum Suppression)에 대한 사후 처리 의존도는 YOLO의 엔드투엔드 배포를 방해하고 추론 대기 시간에 부정적인 영향을 미칩니다. 더욱이 YOLO의 다양한 구성 요소 설계에는 포괄적이고 철저한 검토가 부족하여 상당한 계산 중복이 발생하고 모델 성능이 제한됩니다. 이로 인해 효율성이 최적화되지 않고 성능이 향상될 가능성이 커집니다. 이 작업에서 우리는 후처리와 모델 아키텍처 모두에서 YOLO의 성능 효율성 경계를 더욱 발전시키는 것을 목표로 합니다. 이를 위해 우리는 먼저 경쟁력 있는 성능과 낮은 추론 지연 시간을 동시에 제공하는 NMS 없는 YOLO 교육을 위한 지속적인 이중 할당을 제안합니다. 또한 YOLO를 위한 포괄적인 효율성-정확성 중심 모델 설계 전략을 소개합니다. 효율성과 정확성의 관점에서 YOLO의 각 구성 요소를 포괄적으로 최적화하여 계산 오버헤드를 크게 줄이고 모델 기능을 향상시켰습니다. 우리 노력의 결과로 YOLOv10이라는 실시간 엔드투엔드 객체 감지를 위해 설계된 차세대 YOLO 시리즈가 탄생했습니다. 광범위한 실험에 따르면 YOLOv10은 다양한 모델 규모에서 최첨단 성능과 효율성을 달성합니다. 예를 들어 COCO 데이터세트에서 YOLOv10-S는 유사한 AP의 RT-DETR-R18보다 1.8배 빠르며 매개변수 및 부동 소수점 연산(FLOP)을 2.8배 줄였습니다. YOLOv9-C와 비교하여 YOLOv10-B는 동일한 성능에서 대기 시간을 46% 줄이고 매개 변수를 25% 줄입니다. 코드 링크: https://github.com/THU-MIG/yolov10.
YOLOv10에는 어떤 개선 사항이 있나요?
먼저 NMS가 없는 YOLO에 대한 지속적인 이중 할당 전략을 제안하여 후처리의 중복 예측 문제를 해결합니다. 이 전략에는 이중 레이블 할당 및 일관된 일치 측정항목이 포함됩니다. 이를 통해 모델은 훈련 중에 풍부하고 조화로운 감독을 얻는 동시에 추론 중에 NMS의 필요성을 제거하고 높은 효율성을 유지하면서 경쟁력 있는 성능을 달성할 수 있습니다.
이번에는 모델 아키텍처에 대한 포괄적인 효율성-정확도 기반 모델 설계 전략을 제안하고 YOLO의 각 구성 요소를 종합적으로 검토합니다. 효율성 측면에서 명백한 계산 중복을 줄이고 보다 효율적인 아키텍처를 달성하기 위해 경량 분류 헤드, 공간 채널 분리 다운샘플링 및 순위 안내 블록 설계가 제안됩니다.
정확도 측면에서 대규모 커널 컨볼루션을 탐색하고 효과적인 부분 self-attention 모듈을 제안하여 모델 기능을 향상하고 저렴한 비용으로 성능 개선 잠재력을 활용합니다.
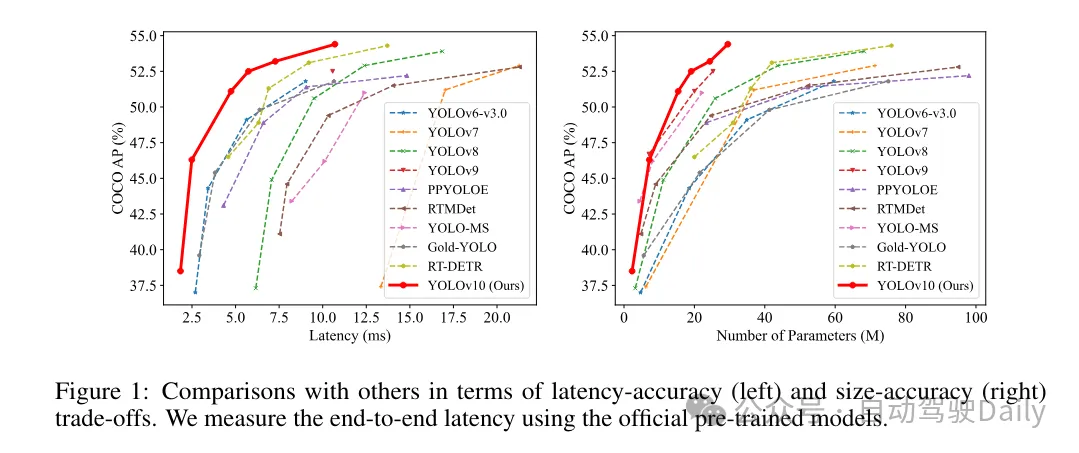
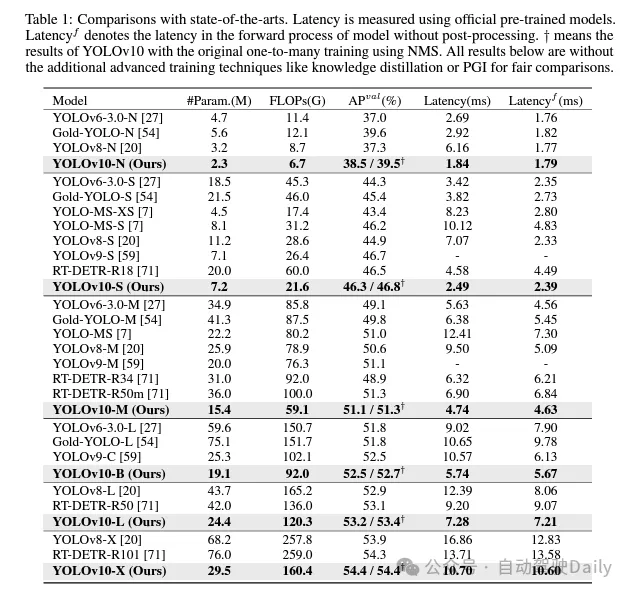
이러한 방법을 기반으로 저자는 다양한 모델 크기, 즉 YOLOv10-N/S/M/B/L/X를 사용하여 일련의 실시간 엔드투엔드 감지기를 성공적으로 구현했습니다. 표준 개체 감지 벤치마크에 대한 광범위한 실험에서 YOLOv10은 다양한 모델 크기의 계산 정확도 절충 측면에서 이전 최첨단 모델을 능가하는 능력을 보여줍니다. 그림 1에 표시된 것처럼 유사한 성능에서 YOLOv10-S/X는 RT-DETR R18/R101보다 각각 1.8배/1.3배 빠릅니다. YOLOv9-C와 비교하여 YOLOv10-B는 동일한 성능에서 46%의 대기 시간 감소를 달성합니다. 또한 YOLOv10은 매우 높은 매개변수 활용 효율성을 보여줍니다. YOLOv10-L/X는 YOLOv8-L/X보다 0.3AP와 0.5AP 높으며 매개변수 수가 각각 1.8배, 2.3배 감소했습니다. YOLOv10-M은 YOLOv9-M/YOLO-MS와 유사한 AP를 달성하면서 매개변수 수를 각각 23% 및 31% 줄였습니다.
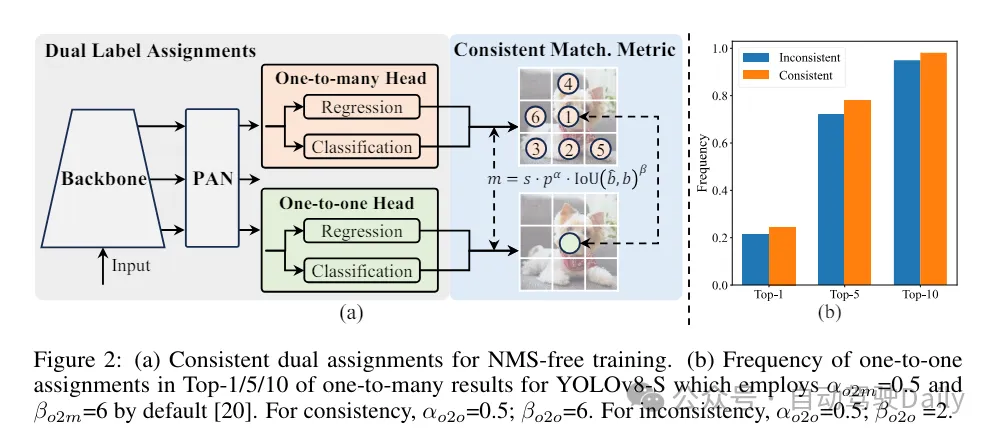
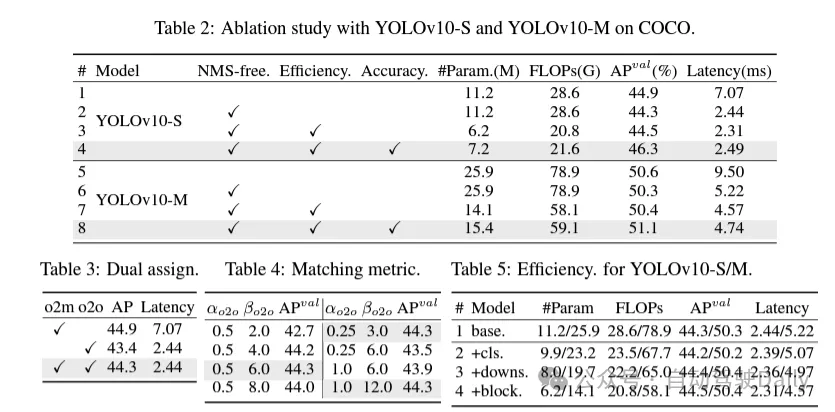
교육 과정에서 YOLO는 일반적으로 TAL(Task Assignment Learning)을 활용하여 각 인스턴스에 여러 샘플을 할당합니다. 일대다 할당 방법을 채택하면 풍부한 감독 신호가 생성되어 더 강력한 성능을 최적화하고 달성하는 데 도움이 됩니다. 그러나 이로 인해 YOLO는 NMS(비최대 억제) 사후 처리에 의존해야 하므로 배포 시 추론 효율성이 최적이 아닙니다. 이전 연구에서는 중복 예측을 억제하기 위해 일대일 매칭 접근 방식을 탐색했지만, 추론 오버헤드를 추가하거나 최적이 아닌 성능을 초래하는 경우가 많습니다. 본 연구에서는 이중 라벨 할당과 일관된 매칭 측정항목을 채택하여 높은 효율성과 경쟁력 있는 성능을 달성하는 NMS 없는 교육 전략을 제안합니다. 이 전략을 통해 YOLO는 더 이상 교육에 NMS가 필요하지 않으며 높은 효율성과 경쟁력 있는 성과를 달성합니다.
효율성 중심 모델 디자인. YOLO의 구성 요소에는 스템, 다운샘플링 레이어, 기본 빌딩 블록이 포함된 스테이지 및 헤드가 포함됩니다. 백본 부분의 계산 비용이 매우 낮기 때문에 나머지 세 부분에 대해서는 효율성 중심의 모델 설계를 수행합니다.
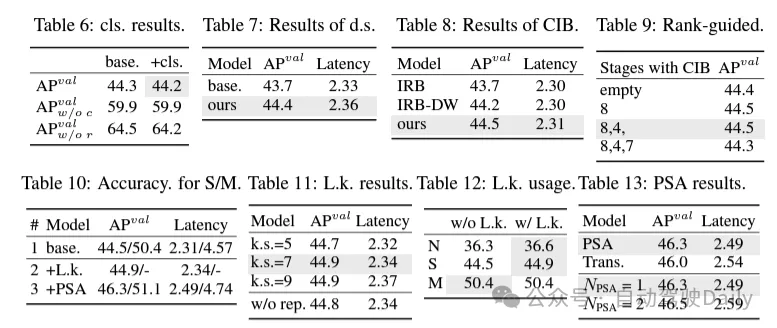
(1) 경량 분류 헤더. YOLO에서는 분류 헤드와 회귀 헤드가 일반적으로 동일한 아키텍처를 갖습니다. 그러나 계산 오버헤드에는 상당한 차이가 있습니다. 예를 들어 YOLOv8-S에서는 분류 헤드(FLOP 및 매개변수의 5.95G/1.51M)와 회귀 헤드(2.34G/0.64M)의 FLOP 개수와 매개변수가 회귀의 2.5배와 2.4배입니다. 각각 머리. 그러나 분류 오류와 회귀 오류(표 6 참조)의 영향을 분석함으로써 YOLO 성능에 회귀 헤드가 더 중요하다는 사실을 발견했습니다. 따라서 성능 저하에 대한 걱정 없이 분류 헤더의 오버헤드를 줄일 수 있습니다. 따라서 우리는 커널 크기가 3×3인 두 개의 깊이 분리 가능한 컨볼루션과 1×1 커널로 구성된 경량 분류 헤드 아키텍처를 간단히 채택했습니다. 위의 개선을 통해 우리는 컨볼루션 커널 크기가 3×3인 두 개의 깊이 분리 가능한 컨볼루션과 1×1 컨볼루션 커널로 구성된 경량 분류 헤드의 아키텍처를 단순화할 수 있습니다. 이 단순화된 아키텍처는 더 적은 계산 오버헤드와 매개변수 수로 분류 기능을 달성할 수 있습니다.
(2) 공간 채널 분리 다운샘플링. YOLO는 일반적으로 스트라이드가 2인 일반 3×3 표준 컨볼루션을 사용하는 동시에 공간 다운샘플링(H × W에서 H/2 × W/2로)과 채널 변환(C에서 2C로)을 구현합니다. 이로 인해 무시할 수 없는 계산 비용과 매개변수 수가 발생합니다. 대신, 보다 효율적인 다운샘플링을 달성하기 위해 공간 감소와 채널 증가 작업을 분리할 것을 제안합니다. 구체적으로, 포인트별 컨볼루션은 먼저 채널 크기를 변조하는 데 활용되고, 그런 다음 깊이별 컨볼루션이 공간 다운샘플링에 활용됩니다. 이렇게 하면 계산 비용이 로 줄어들고 매개변수 수가 로 줄어듭니다. 동시에 다운샘플링 중에 정보 보존을 극대화하여 경쟁력 있는 성능을 유지하면서 대기 시간을 줄입니다.
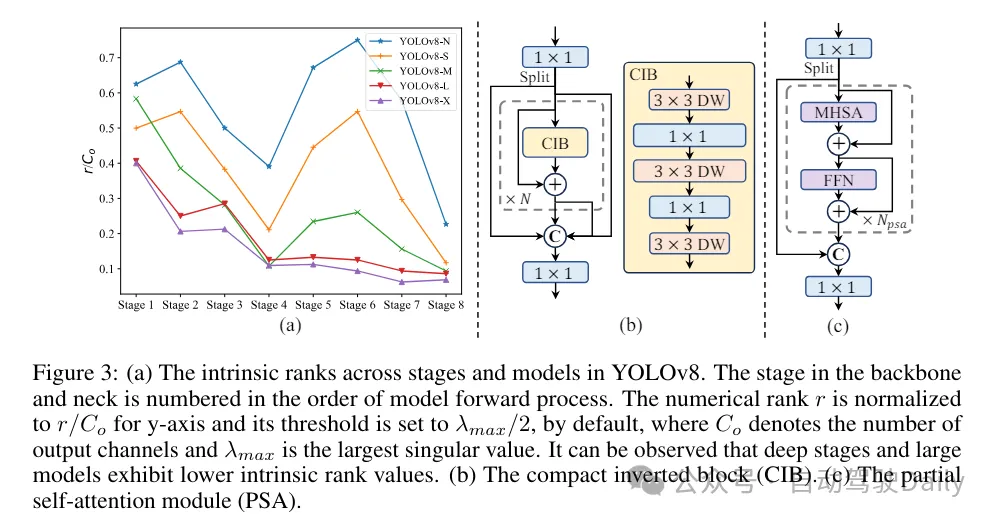
(3) 순위 안내에 따른 모듈 설계. YOLO는 일반적으로 YOLOv8의 병목 현상 블록과 같이 모든 단계에 대해 동일한 기본 빌딩 블록을 사용합니다. 이러한 YOLO의 동형 설계를 철저히 조사하기 위해 고유 순위를 활용하여 각 단계의 중복성을 분석합니다. 구체적으로 각 단계의 마지막 기본블록에 있는 마지막 콘볼루션의 수치순위를 계산하는데, 이는 임계값보다 큰 특이값의 개수를 센다. 그림 3(a)는 YOLOv8의 결과를 보여주며, 딥 스테이지와 대규모 모델이 더 많은 중복성을 나타낼 가능성이 더 높다는 것을 보여줍니다. 이 관찰은 단순히 동일한 블록 설계를 모든 단계에 적용하는 것이 최고의 용량 효율성 균형을 달성하는 데 차선책임을 시사합니다. 이 문제를 해결하기 위해 컴팩트한 아키텍처 설계를 통해 중복되는 것으로 판명된 단계의 복잡성을 줄이는 것을 목표로 하는 순위 기반 모듈 설계 방식이 제안되었습니다.
그림 3(b)와 같이 먼저 공간 믹싱을 위해 저렴한 깊이별 컨볼루션을 채택하고 채널 믹싱을 위해 비용 효율적인 포인트별 컨볼루션을 채택한 컴팩트한 역 블록(CIB) 구조를 소개합니다. 예를 들어 ELAN 구조에 내장된 효과적인 기본 빌딩 블록 역할을 할 수 있습니다(그림 3(b)). 그런 다음 경쟁력을 유지하면서 최적의 효율성을 달성하기 위해 순위 기반 모듈 할당 전략이 옹호됩니다. 구체적으로, 모델이 주어지면 모든 단계를 고유 순위의 오름차순에 따라 정렬합니다. 선행단의 기본 블록을 CIB로 교체한 후의 성능 변화를 추가로 검토합니다. 해당 모델에 비해 성능 저하가 없으면 계속해서 다음 단계를 교체하고, 그렇지 않으면 프로세스를 중단합니다. 결과적으로 우리는 다양한 단계와 모델 크기에서 적응형 컴팩트 블록 설계를 구현하여 성능 저하 없이 더 큰 효율성을 달성할 수 있습니다.
정밀도 중심의 모델 디자인을 기반으로 합니다. 이 백서는 최소 비용으로 성능을 향상시키는 것을 목표로 정밀 기반 설계를 달성하기 위해 대형 커널 컨볼루션 및 self-attention 메커니즘을 추가로 탐구합니다.
(1) 대규모 커널 컨볼루션. 대형 커널 딥 컨볼루션을 채택하는 것은 수용 필드를 확장하고 모델의 기능을 향상시키는 효과적인 방법입니다. 그러나 단순히 모든 단계에서 이를 활용하면 작은 물체를 감지하는 데 사용되는 얕은 기능에 오염이 발생할 수 있으며 고해상도 단계에서 상당한 I/O 오버헤드와 대기 시간이 발생할 수도 있습니다. 따라서 저자들은 딥 스테이지의 CIB(Inter-Stage Information Block)에서 대규모 커널 딥 콘볼루션을 활용할 것을 제안합니다. 여기서 CIB의 두 번째 3×3 깊이 컨볼루션의 커널 크기는 7×7로 증가됩니다. 또한 추론 오버헤드를 증가시키지 않고 최적화 문제를 완화하기 위해 또 다른 3×3 깊이 컨볼루션 분기를 도입하기 위해 구조적 재매개변수화 기술이 채택되었습니다. 또한 모델 크기가 증가함에 따라 수용 필드가 자연스럽게 확장되고 큰 커널 컨볼루션을 사용하는 이점이 점차 감소합니다. 따라서 큰 커널 컨볼루션은 작은 모델 규모에서만 사용됩니다.
(2) 부분적 자기 주의(PSA). Self-Attention 메커니즘은 뛰어난 전역 모델링 기능으로 인해 다양한 시각적 작업에 널리 사용됩니다. 그러나 계산 복잡도와 메모리 사용량이 높습니다. 이 문제를 해결하기 위해 유비쿼터스 주의 헤드 중복성을 고려하여 저자는 그림 3.(c)와 같이 효율적인 부분 자기 주의(PSA) 모듈 설계를 제안합니다. 구체적으로, 특징은 1×1 컨볼루션 이후 채널별로 두 부분으로 균등하게 나뉩니다. MHSA(Multi-Head Self-Attention Module)와 FFN(Feed-Forward Network)으로 구성된 NPSA 블록에는 기능 중 일부만 입력됩니다. 그런 다음 특징의 두 부분을 1×1 컨볼루션을 통해 접합하고 융합합니다. 또한 MHSA의 쿼리 및 키 크기를 값의 절반으로 설정하고 빠른 추론을 위해 LayerNorm을 BatchNorm으로 바꿉니다. PSA는 self-attention의 2차 계산 복잡성으로 인해 발생하는 과도한 오버헤드를 피하기 위해 가장 낮은 해상도로 4단계 이후에만 배치됩니다. 이러한 방식으로 전역 표현 학습 기능을 낮은 계산 비용으로 YOLO에 통합할 수 있으므로 모델의 기능이 향상되고 성능이 향상됩니다.
실험적 비교
여기서는 너무 많은 소개는 하지 않고 결과만 말씀드리겠습니다! ! ! 지연 시간은 줄어들고 성능은 계속해서 향상됩니다.
위 내용은 YOLOv10이 왔습니다! 진정한 실시간 엔드투엔드 표적 탐지의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!