
ホームページ >テクノロジー周辺機器 >AI >58 行のコードは Llama 3 から 100 万コンテキストまで拡張可能、あらゆる微調整バージョンが適用可能
58 行のコードは Llama 3 から 100 万コンテキストまで拡張可能、あらゆる微調整バージョンが適用可能

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-05-06 18:10:081465ブラウズ
Llama 3、オープンソースの雄大な王様、オリジナルのコンテキストウィンドウは、実際には...8k しかありません。これには「本当に」という言葉を飲み込みました。おいしい」とまた口元に。。
現在、32k が開始点であり、100k が一般的ですが、これはオープンソース コミュニティへの貢献の余地を意図的に残しているのでしょうか?
オープンソース コミュニティは、この機会を決して逃すことはありません:
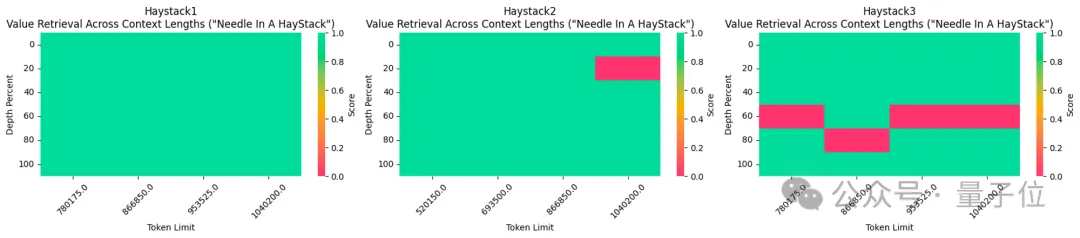
わずか 58 行のコードで、Llama 3 70b の微調整されたバージョンであれば、 1048k(100万)コンテキストは自動的に拡張されます。
ファイルはわずか 800mb です。
次に、Mergekit を使用して、同じアーキテクチャの他のモデルで実行したり、モデルに直接マージしたりできます。
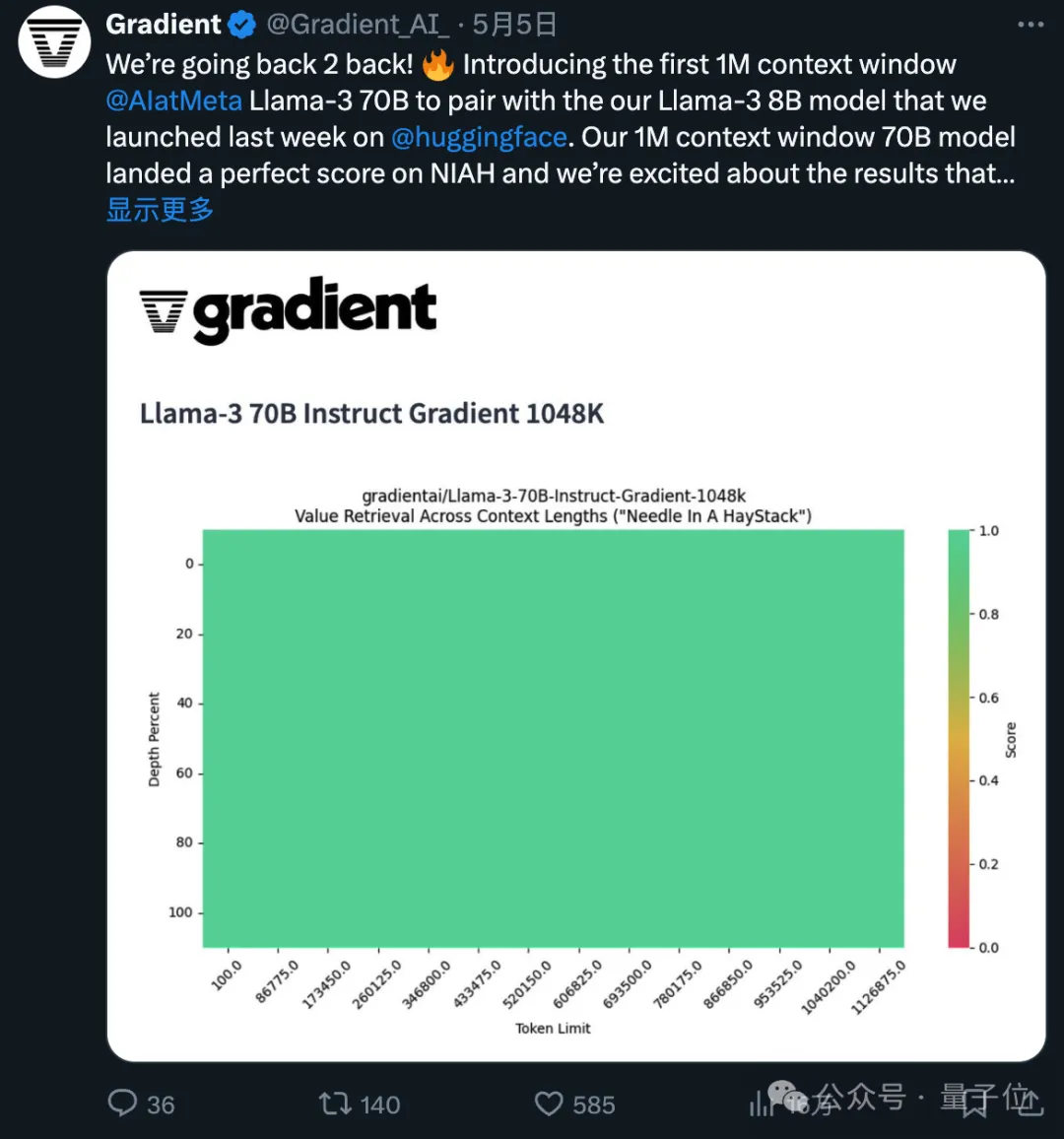
Gradient AI から来ています。 はエンタープライズ AI ソリューションのスタートアップです。

Eric Hartford によるもので、微調整されたモデルと元のバージョンの違いを比較します。 、パラメータはさまざまに抽出されます。
彼は最初に 524k コンテキスト バージョンを作成し、次に 1048k バージョンを更新しました。
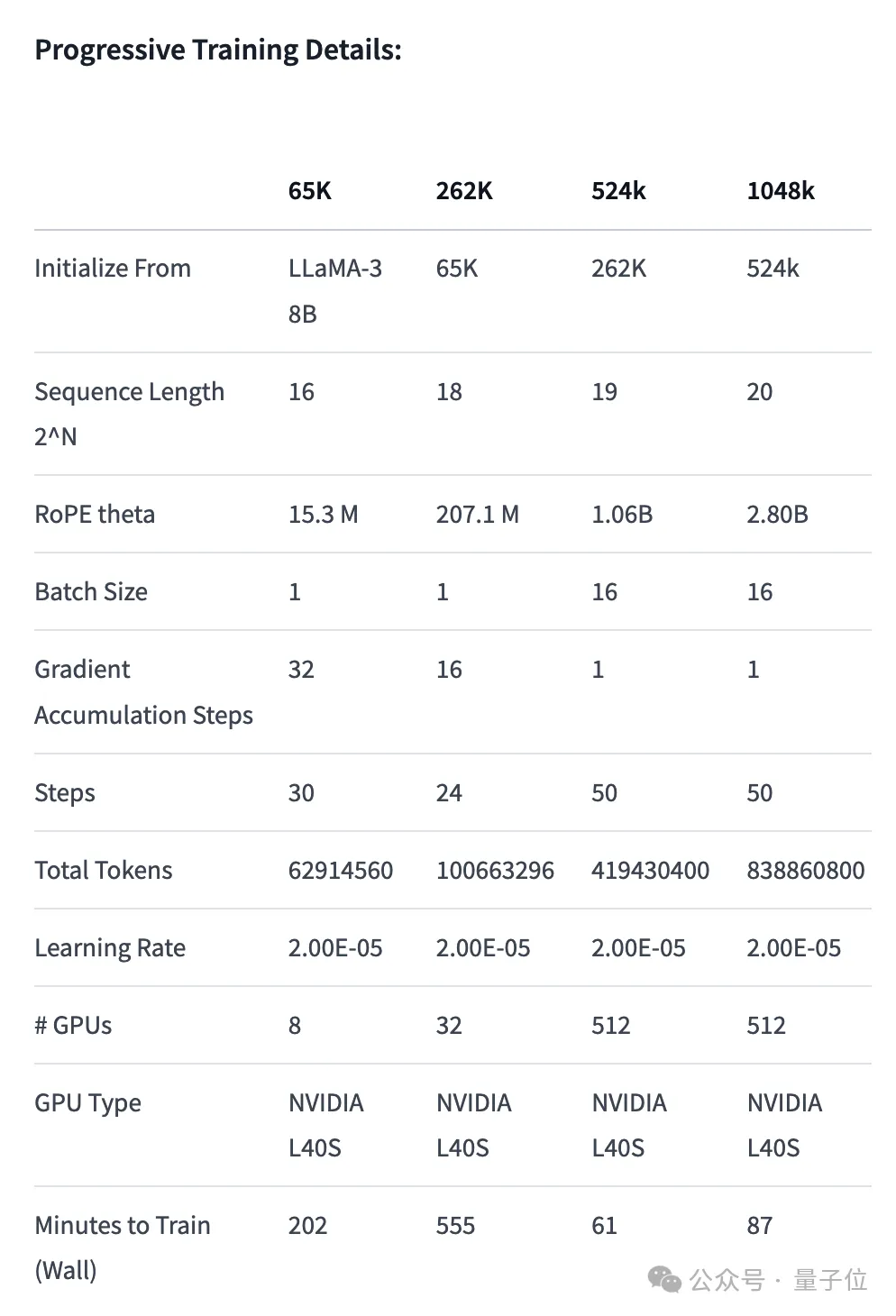
- 位置エンコーディングの調整: RoPE theta を NTK で初期化します。意識的な補間 最適なスケジューリング、長さを延長した後の高周波情報の損失を防ぐための最適化
- プログレッシブ トレーニング: カリフォルニア大学バークレー校によって提案Pieter Abbeel チーム Blockwise RingAttendance メソッドはモデルのコンテキスト長を拡張します

#524k バージョン LoRA: https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-524k-adapter
1048k バージョン LoRA: https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-1048k-adapter
# #マージコード:https://gist.github.com/ehartford/731e3f7079db234fa1b79a01e09859ac
以上が58 行のコードは Llama 3 から 100 万コンテキストまで拡張可能、あらゆる微調整バージョンが適用可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。