
ホームページ >テクノロジー周辺機器 >AI >オブジェクトの 3D 表現と生成モデルを透視: NUS チームが X 線を提案
オブジェクトの 3D 表現と生成モデルを透視: NUS チームが X 線を提案

- 王林転載
- 2024-05-06 18:30:131239ブラウズ

- プロジェクトのホームページ: https://tau-yihouxiang.github.io/projects/X-Ray/X-Ray.html
- ペーパーアドレス: https://arxiv.org/abs/2404.14329
- コードアドレス: https://github.com/tau-yihouxiang/ X 線
- データセット: https://huggingface.co/datasets/yihouxiang/X-Ray

##現在、人工知能は人間の知能の分野で急速に発展しています。コンピューター ビジョンでは、画像とビデオの生成テクノロジがますます成熟しており、Midjourney や Stable Video Diffusion などのモデルが広く使用されています。しかし、3D ビジョン分野の生成モデルは依然として課題に直面しています。
現在の 3D モデル生成テクノロジは、通常、マルチアングル ビデオの生成と神経放射場 (NeRF) または3D ガウス スムーズ モデル (3D ガウス スプラッティング テクノロジー) により、3D オブジェクトを段階的に構築します。この方法は主に単純な非セルフオクルージョンの 3 次元オブジェクトの生成に限定されており、オブジェクトの内部構造を表現できないため、生成プロセス全体が複雑かつ不完全になり、この技術の複雑さと限界が示されています。
その理由は、現在、柔軟で効率的かつ簡単に一般化できる 3D 表現 (3D 表現) が不足しているためです。

シンガポール国立大学 (NUS) Huラン博士は研究チームを率いて、カメラの視点から見た物体の表面形状と質感を逐次表現し、ビデオ生成機能を駆使してモデルを生成できる新しい 3D 表現 - X 線をリリースしました。これらの利点を利用して 3D オブジェクトを生成し、オブジェクトの内部および外部の 3D 構造を同時に生成できます。
この記事では、X 線テクノロジーの原理、利点、幅広い応用の可能性について詳しく説明します。
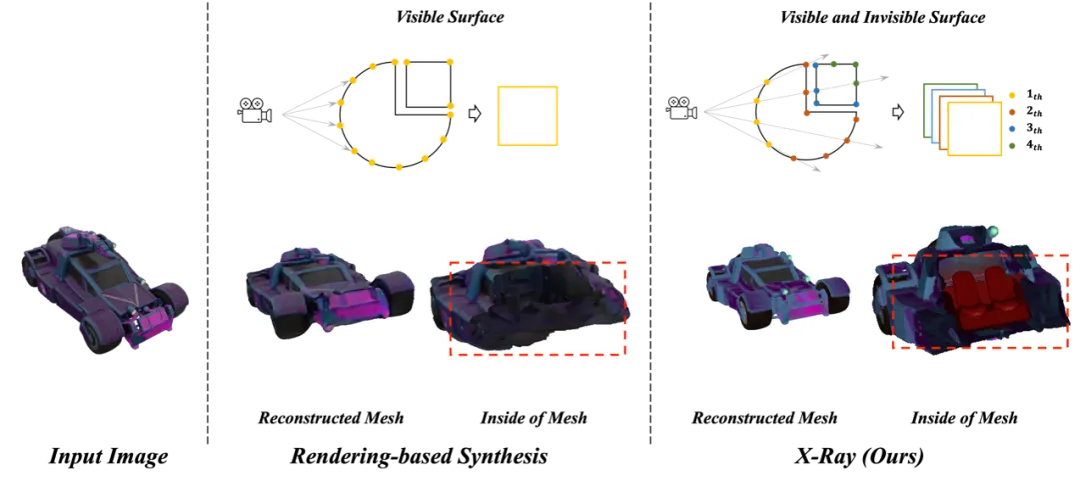
技術革新:物体の内外面の3次元表現法
X線表現:物体を起点とするH×Wカメラの中心をオブジェクトの方向に向けてマトリックス ポイントが光線を放射します。各光線方向において、物体表面との交点に奥行き、法線ベクトル、色などのL個の三次元属性データを1つずつ記録し、L×H×Wの形式に整理します。あらゆる 3D モデルの作成を実現するために、これがチームによって提案された X 線表現方法です。
表現がビデオ形式と同じであるため、ビデオ生成モデルを 3D 生成モデルの作成に使用できることは注目に値します。具体的なプロセスは以下の通りです。

1. エンコード プロセス: 3D モデルから X 線への変換
与えられた 3D モデル (通常は 3 次元)グリッドでは、まずモデルを観察するためにカメラを設定し、次にレイ キャスティング アルゴリズムを使用して、各カメラの光線がオブジェクトと交差するすべてのサーフェスのプロパティを記録します。#、法線ベクトル 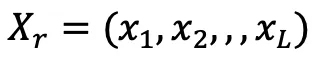 #、色
#、色 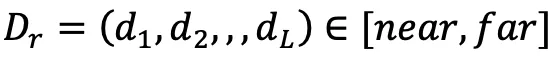 など、説明の便宜上、
など、説明の便宜上、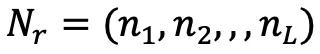 ## を使用します。 # その位置にサーフェスが存在するかどうかを表します。
## を使用します。 # その位置にサーフェスが存在するかどうかを表します。 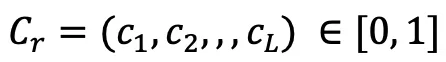 次に、カメラ光線などのすべての交差する表面点を取得することで、次の式と図 3 に示すように、完全な X 線 3D 表現を取得できます。
次に、カメラ光線などのすべての交差する表面点を取得することで、次の式と図 3 に示すように、完全な X 線 3D 表現を取得できます。 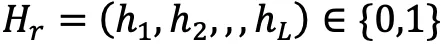
エンコード プロセスを通じて、任意の 3D モデルは、ビデオ形式と同じでフレーム数が異なる X-Ray に変換されます。通常、フレーム数 L=8 で十分です。 3Dオブジェクトを表現します。
2. デコード プロセス: X 線から 3D モデルへの変換
X 線があれば、次のこともできます。デコード処理を経て 3D モデルに戻されるため、X-Ray を生成するだけで 3D モデルを生成できます。具体的な処理には、点群生成処理と点群表面再構成処理の2つの処理が含まれる。
- X 線から点群へ: 3D 点の位置座標に加えて、各点には色もありますそして法線ベクトル情報。
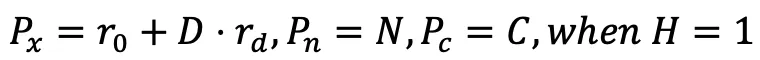
ここで、r_0 と r_d はそれぞれカメラ レイの開始点と正規化された方向です。各カメラ レイを処理することで、A が得られます。完全な点群を取得できます。
- 点群から 3 次元メッシュへ: 次のステップは、点群を 3 次元メッシュに変換することです。これは長年研究されてきた技術で、これらの点群は法線ベクトルを持っているため、スクリーンド ポアソン アルゴリズムを使用して点群を最終的な 3D モデルである 3 次元メッシュ モデルに直接変換します。
X 線表現に基づく 3D モデル生成
高解像度で多様な 3D X 線モデルを生成するには、チームは、ビデオ形式と同様のビデオ拡散モデル アーキテクチャを使用しました。このアーキテクチャは、連続 3D 情報を処理し、アップサンプリング モジュールを通じて X 線の品質を向上させ、高精度の 3D 出力を生成します。拡散モデルはノイズの多いデータから詳細な 3D 画像を段階的に生成する役割を果たし、アップサンプリング モジュールは画像の解像度と詳細を強化して高品質基準を満たすようにします。具体的な構造を図4に示します。
X 線拡散生成モデル
拡散モデルは X 線生成で潜在空間を使用し、通常はベクトル量子化 - 変分法のカスタム開発が必要です。オートエンコーダ (VQ-VAE) [3] はデータ圧縮を実行しますが、このプロセスには既製のモデルがなく、トレーニングの負担が増大します。
高解像度ジェネレーターを効果的にトレーニングするために、チームはカスケード合成戦略を採用し、限られた環境に適応するために Imagen や Stable Cascaded などのテクノロジーを通じて低解像度から高解像度まで段階的にトレーニングしました。コンピューティング リソースを活用し、X 線画像の品質を向上させます。
具体的には、Stable Video Diffusion の 3D U-Net アーキテクチャが、低解像度の X 線を生成する拡散モデルとして使用され、時空間的注意を通じて 2D フレームと 1D 時間から生成されます。メカニズム シーケンスから特徴を抽出して、高品質の結果に不可欠な X 線の処理と解釈を強化します。
X 線アップサンプリング モデル
前段階の拡散モデルでは、低解像度の放射線画像しか生成できません。その後の段階では、これらの低解像度の X 線をより高い解像度にアップグレードすることに重点が置かれます。
チームは、点群アップサンプリングとビデオ アップサンプリングという 2 つの主要なアプローチを検討しました。
形状と外観の大まかな表現が得られたため、このデータを色と法線を使用して点群にエンコードするのは簡単なプロセスです。
ただし、点群表現の構造は緩すぎるため、密な予測には適していません。従来の点群アップサンプリング手法は通常、単にポイントの数を増やすだけであり、次のような点を改善するのに役立ちます。テクスチャとカラーが十分に有効ではない可能性があります。プロセスを簡素化し、パイプライン全体の一貫性を確保するために、ビデオ アップサンプリング モデルが選択されました。
このモデルは、Stable Video Diffusion (SVD) の時空間 VAE デコーダから適応されており、合成 X 線フレームのオリジナルを維持しながら 4 倍にアップサンプリングするために最初から特別にトレーニングされています。層。デコーダは、フレーム レベルと階層レベルで独立してアテンション操作を実行できます。この二重層のアテンション メカニズムにより、解像度が向上するだけでなく、画像全体の品質も大幅に向上します。これらの機能により、ビデオ アップサンプリング モデルは、高解像度 X 線生成において、より調整された効率的なソリューションになります。
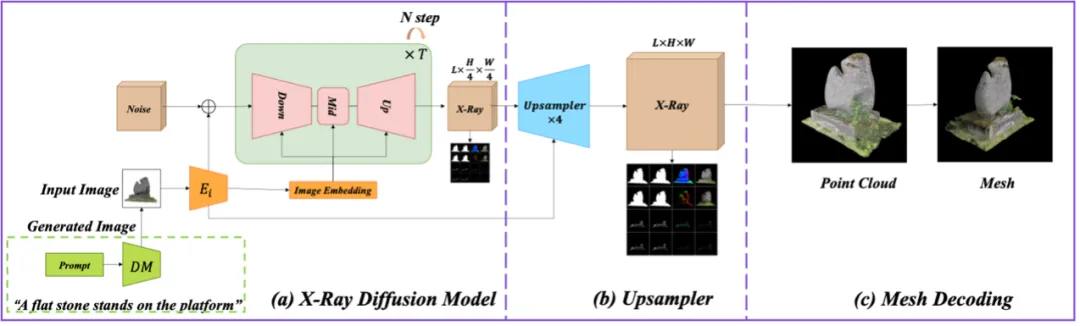
図 4: X 線拡散モデルと X 線アップサンプリング モデルを含む、X 線表現に基づく 3D モデル生成フレームワーク。
実験
1. データセット:
実験的使用Objaverse データセットのフィルタリングされたサブセットが作成され、そこからテクスチャの不足やヒントが不十分なエントリが削除されました。
このサブセットには 60,000 を超える 3D オブジェクトが含まれています。オブジェクトごとに、方位角 -180 ~ 180 度、仰角 -45 ~ 45 度をカバーする 4 つのカメラ ビューがランダムに選択され、カメラからオブジェクトの中心までの距離は 1.5 に固定されます。
次に、Blender ソフトウェアを使用してレンダリングし、trimesh ライブラリによって提供されるレイ キャスティング アルゴリズムを通じて対応する X 線を生成します。これらのプロセスを通じて、生成モデルをトレーニングするために 240,000 を超える画像と X 線データセットのペアを作成できます。
2. 実装の詳細:
X 線拡散モデルは、Stable Video Diffusion (SVD) で使用される時空間 UNet アーキテクチャに基づいており、若干の調整が加えられています。モデルは、8 つのチャネル (ヒット チャネル 1 つ、深度チャネル 1 つ、および 6 つのチャネル) を合成するように構成されています。元のネットワークの 4 チャネルと比較して、通常のチャネル。
X 線画像と従来のビデオの間には大きな違いがあるため、モデルは X 線とビデオのフィールド間の大きなギャップを埋めるためにゼロからトレーニングされました。トレーニングは 8 台の NVIDIA A100 GPU サーバーで 1 週間にわたって実施されました。この期間中、AdamW オプティマイザーを使用して学習率は 0.0001 に維持されました。
X 線ごとにレイヤー数が異なるため、バッチ処理とトレーニングを向上させるために同じ 8 レイヤーにパッドまたはクロップします。各レイヤーのフレーム サイズは 64×64 です。アップサンプリング モデルの場合、L 層の出力は依然として 8 ですが、各フレームの解像度は 256 × 256 に増加し、拡大された X 線の詳細と明瞭さが向上します。結果を図 5 と 6 に示します。 。
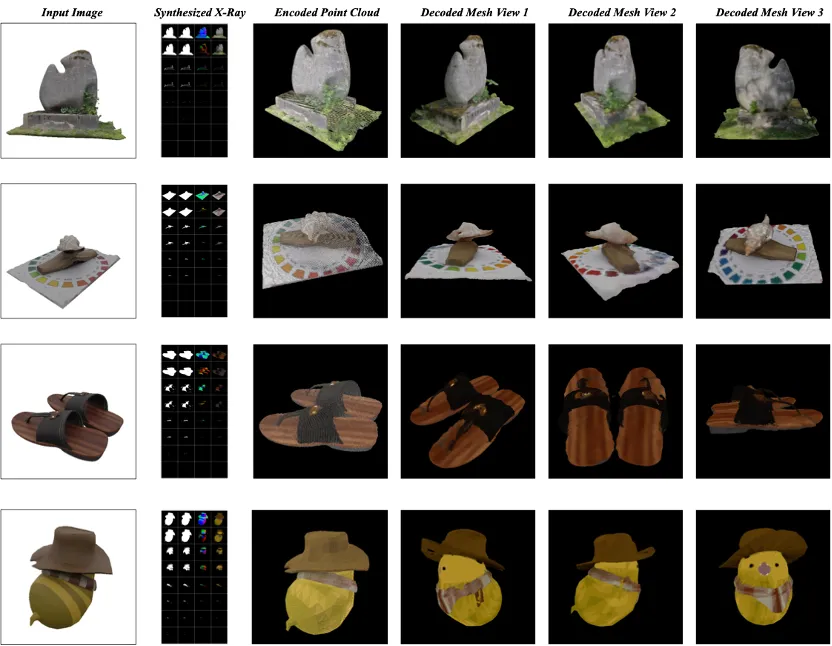
#図 5: 画像から X 線への変換および 3D モデルの生成

図 6: X 線へのテキストと 3D モデルの生成##将来の見通し: 新しい表現が無限の可能性をもたらします
#機械学習と画像処理技術の継続的な進歩により、X 線の応用の可能性は無限に広がります。
将来的には、このテクノロジーを拡張現実 (AR) および仮想現実 (VR) テクノロジーと組み合わせて、ユーザーに完全に没入型の 3D エクスペリエンスを作成する可能性があります。教育・研修分野においても、より直観的な学習教材や3D再構築によるシミュレーション実験の提供など、メリットが得られます。
さらに、医療画像およびバイオテクノロジーの分野における X 線技術の応用は、複雑な生物学的構造に対する人々の理解と研究方法を変える可能性があります。三次元世界との関わり方がどのように変化するのか、楽しみにしていてください。 ##################################
以上がオブジェクトの 3D 表現と生成モデルを透視: NUS チームが X 線を提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。