


効率16倍アップ! VRSO: 純粋に視覚的な静的オブジェクトの 3D アノテーションにより、データの閉ループが開かれます。

アノテーションの悲しみ
信号機、誘導標識、トラフィック コーンなどの静的物体検出 (SOD) のほとんどのアルゴリズムはデータ駆動型のディープ ニューラル ネットワークであり、大量のトレーニングデータ。現在の実践では、ロングテールのケースを修正するために、LiDAR でスキャンした点群データ上の多数のトレーニング サンプルに手動でアノテーションを付けることが一般的に行われています。

手動のアノテーションでは、実際のシーンの変動性と複雑性を捉えるのが難しく、オクルージョン、さまざまな照明条件、さまざまな視野角を考慮できないことがよくあります (図 1 の黄色の矢印)。 。 プロセス全体には長いリンクがあり、非常に時間がかかり、エラーが発生しやすく、コストがかかります (図 2)。 したがって、現在企業は、特に純粋なビジョンに基づいた自動ラベル付けソリューションを探しています。結局のところ、すべての車に LiDAR が搭載されているわけではありません。

VRSO は、静的オブジェクト アノテーション用のビジョンベースのアノテーション システムです。主に SFM、2D オブジェクト検出、インスタンス セグメンテーションの結果からの情報を使用します。全体的な効果:
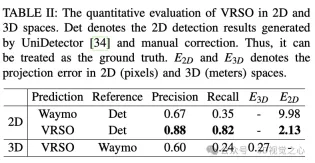
- アノテーションの平均投影誤差はわずか 2.6 ピクセルで、Waymo アノテーション (10.6 ピクセル) の約 4 分の 1 です。
- 手動アノテーションと比較して、速度は約 16 倍向上します
静的オブジェクトの場合、VRSO は、インスタンスのセグメンテーションとキーポイントの輪郭抽出を通じて、さまざまな視野角からの静的オブジェクトの統合と重複除去という課題、およびオクルージョンの問題による不十分な観察の困難を解決します。により、ラベルの精度が向上します。 図 1 より、Waymo Open データセットの手動アノテーション結果と比較して、VRSO はより高い堅牢性と幾何学的精度を示しています。
(皆さんもこれを見たことがあるでしょう。親指を上にスライドさせて一番上のカードをクリックして私をフォローしてみてはいかがでしょうか。 操作全体にかかる時間は 1.328 秒だけです。将来役立つ情報をすべてお届けします。うまくいったらどうなるか~)
状況を打破する方法
VRSO システムは主に 2 つの部分に分かれています。 シーン再構成 および 静的オブジェクトには のマークが付けられます。
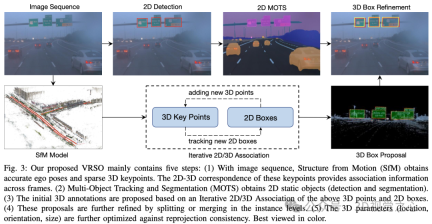
#再構築部分は焦点ではなく、SFM アルゴリズムに基づいて画像の姿勢とまばらな 3D キー ポイントを復元します。
静的オブジェクト アノテーション アルゴリズムと疑似コードの組み合わせの一般的なプロセスは次のとおりです (以下で段階的に詳しく説明します):
- 既製の 2D オブジェクト検出およびセグメンテーション アルゴリズムを使用する候補を生成します
- SFM モデルの 3D-2D キーポイント対応を使用して、フレーム全体の 2D インスタンスを追跡します
- 再投影の一貫性を導入して、静的オブジェクトの 3D 注釈パラメータを最適化します

1. 関連付けの追跡
- #ステップ 1: 3D 境界ボックス内のキー ポイントに基づいて 3D ポイントを抽出します。 SFMモデル。
- ステップ 2: 2D-3D マッチング関係に基づいて、2D マップ上の各 3D 点の座標を計算します。
- ステップ 3: 2D マップ座標とインスタンス セグメンテーション コーナー ポイントに基づいて、現在の 2D マップ上の 3D ポイントの対応するインスタンスを決定します。
- ステップ 4: 各 2D 画像の 2D 観察と 3D 境界ボックスの間の対応を決定します。
2.プロポーザルの生成
ビデオ クリップ全体の静的オブジェクトの 3D フレーム パラメーター (位置、方向、サイズ) を初期化します。 SFM の各キー ポイントには、正確な 3D 位置と対応する 2D 画像があります。 2D インスタンスごとに、2D インスタンス マスク内の特徴点が抽出されます。次に、対応する 3D キーポイントのセットを 3D 境界ボックスの候補として考慮できます。
道路標識は空間内の方向をもつ長方形として表され、移動 (,,)、方向 (θ)、サイズ (幅と高さ) を含む 6 つの自由度があります。その奥行きを考慮すると、信号機には 7 つの自由度があります。トラフィック コーンは信号機と同様に表されます。
3.提案の洗練
- ステップ 1: 2D インスタンスのセグメンテーションから各静的オブジェクトの輪郭を抽出します。
- ステップ 2: 輪郭の輪郭に最小指向性バウンディング ボックス (OBB) を適合させます。
- ステップ 3: 最小境界ボックスの頂点を抽出します。
- ステップ 4: 頂点と中心点に基づいて方向を計算し、頂点の順序を決定します。
- ステップ 5: 2D 検出とインスタンスのセグメンテーションの結果に基づいて、セグメンテーションとマージのプロセスが実行されます。
- ステップ 6: オクルージョンを含む観察を検出して拒否します。 2D インスタンス セグメンテーション マスクから頂点を抽出するには、各標識の 4 つの角がすべて表示されている必要があります。オクルージョンがある場合、軸に合わせたバウンディング ボックス (AABB) がインスタンス セグメンテーションから抽出され、AABB と 2D 検出ボックスの面積比が計算されます。オクルージョンがない場合、これら 2 つの面積計算方法は近いはずです。
4. 三角形分割
三角形分割を通じて 3D 条件下で静的オブジェクトの初期頂点値を取得します。
シーン再構築中に SFM とインスタンス セグメンテーションによって取得された 3D バウンディング ボックス内のキーポイントの数をチェックすることにより、キーポイントの数がしきい値を超えるインスタンスのみが、安定した有効な観測であると見なされます。これらのインスタンスでは、対応する 2D 境界ボックスが有効な観測値とみなされます。複数の画像の 2D 観察を通じて、2D バウンディング ボックスの頂点が三角形分割され、バウンディング ボックスの座標が取得されます。
マスク上の「左下、左上、右上、右上、および右下」の頂点を区別しない円形標識の場合、これらの円形標識を識別する必要があります。 2D 検出結果は円形オブジェクトの観察として使用され、2D インスタンス セグメンテーション マスクは輪郭抽出に使用されます。中心点と半径は、最小二乗フィッティング アルゴリズムを通じて計算されます。円形標識のパラメータには、中心点 (,,)、方向 (θ)、半径 () が含まれます。
5.tracking洗練
SFMに基づいて特徴点マッチングを追跡します。 3D バウンディング ボックスの頂点と 2D バウンディング ボックスの投影 IoU のユークリッド距離に基づいて、これらの分離されたインスタンスをマージするかどうかを決定します。マージが完了すると、インスタンス内の 3D 特徴点をクラスタリングして、より多くの 2D 特徴点を関連付けることができます。 2D 特徴点を追加できなくなるまで、反復的な 2D-3D 関連付けが実行されます。
6. 最終的なパラメータの最適化
長方形の記号を例に挙げると、最適化できるパラメータには位置 (,,) と方向 (θ) が含まれます。 ) とサイズ (,)、合計 6 つの自由度。主な手順は次のとおりです。
- 6 つの自由度を 4 つの 3D 点に変換し、回転行列を計算します。
- 変換された 4 つの 3D 点を 2D 画像に投影します。
- 投影結果とインスタンス セグメンテーションによって得られたコーナー ポイント結果との間の残差を計算します。
- Huber を使用して境界ボックス パラメーターを最適化および更新する
ラベリング効果



要約すると、
VRSO フレームワークは、静的オブジェクトの高精度で一貫した 3D アノテーションを実現し、検出、セグメンテーション、およびSFM アルゴリズムは、インテリジェント運転アノテーションにおける手動介入を排除し、LiDAR ベースの手動アノテーションと同等の結果を提供します。定性的および定量的評価は、広く認知されている Waymo Open Dataset を使用して実施されました。手動によるアノテーションと比較して、最高の一貫性と精度を維持しながら、速度は約 16 倍向上しました。以上が効率16倍アップ! VRSO: 純粋に視覚的な静的オブジェクトの 3D アノテーションにより、データの閉ループが開かれます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM
革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM食品の準備を強化するAI まだ初期の使用中ですが、AIシステムは食品の準備にますます使用されています。 AI駆動型のロボットは、ハンバーガーの製造、SAの組み立てなど、食品の準備タスクを自動化するためにキッチンで使用されています
 Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM
Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM導入 Python関数における変数の名前空間、スコープ、および動作を理解することは、効率的に記述し、ランタイムエラーや例外を回避するために重要です。この記事では、さまざまなASPを掘り下げます
 ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM
MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM製品のケイデンスを継続して、今月MediaTekは、新しいKompanio UltraやDimenity 9400を含む一連の発表を行いました。これらの製品は、スマートフォン用のチップを含むMediaTekのビジネスのより伝統的な部分を埋めます
 今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM
今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM#1 GoogleはAgent2Agentを起動しました 物語:月曜日の朝です。 AI駆動のリクルーターとして、あなたはより賢く、難しくありません。携帯電話の会社のダッシュボードにログインします。それはあなたに3つの重要な役割が調達され、吟味され、予定されていることを伝えます
 生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM
生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM私はあなたがそうであるに違いないと思います。 私たちは皆、精神障害がさまざまな心理学の用語を混ぜ合わせ、しばしば理解できないか完全に無意味であることが多い、さまざまなおしゃべりで構成されていることを知っているようです。 FOを吐き出すために必要なことはすべてです
 プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM
プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM今週公開された新しい研究によると、2022年に製造されたプラスチックの9.5%のみがリサイクル材料から作られていました。一方、プラスチックは埋め立て地や生態系に積み上げられ続けています。 しかし、助けが近づいています。エンジンのチーム
 AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM
AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM主要なエンタープライズ分析プラットフォームAlteryxのCEOであるAndy Macmillanとの私の最近の会話は、AI革命におけるこの重要でありながら過小評価されている役割を強調しました。 MacMillanが説明するように、生のビジネスデータとAI-Ready情報のギャップ


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

SublimeText3 中国語版
中国語版、とても使いやすい

