
ホームページ >テクノロジー周辺機器 >AI >Yuanxiang の最初の MoE 大型モデルはオープンソースです: 42 億の活性化パラメーター、効果は 13 億のモデルに匹敵します
Yuanxiang の最初の MoE 大型モデルはオープンソースです: 42 億の活性化パラメーター、効果は 13 億のモデルに匹敵します

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-02 13:25:081309ブラウズ
Yuanxiang は、業界最先端の混合エキスパート モデル アーキテクチャ (Mixture of Experts) を採用し、パラメーター 4.2B を有効にする XVERSE-MoE-A4.2B 大型モデルをリリースしました。その効果は 13B モデルに匹敵します。このモデルは完全にオープンソースであり、商用利用は無条件に無料です。これにより、多数の中小企業、研究者、開発者が Yuanxiang の高性能「ファミリー バケット」でオンデマンドで使用できるようになり、低コストの導入。

GPT3、Llama、XVERSE などの主流の大規模モデルの開発は、スケーリング則に従います。モデルのトレーニングと推論のプロセスでは、単一の順方向計算と逆方向計算が行われます。すべてのパラメータがアクティブ化されます。これは、Dense アクティブ化 (高密度にアクティブ化) と呼ばれます。モデルの規模が大きくなると、計算能力のコストが急激に増加します。
まばらに活性化された MoE モデルは、モデルのサイズを大きくしてもトレーニングと推論の計算コストを大幅に増加させることなく、より効果的であると考える研究者がますます増えています。このテクノロジーは比較的新しいため、中国ではほとんどのオープンソース モデルや学術研究はまだ普及していません。
同じコーパスを使用して 2.7 京個のトークンをトレーニングした要素の自己調査では、XVERSE-MoE-A4.2B は実際に 4.2B のパラメーターをアクティブにし、パフォーマンスが XVERSE-13B-2 を「飛躍」させました。計算量が削減され、トレーニング時間が 50% 削減されます。複数のオープンソース ベンチマーク Llama と比較すると、このモデルは Llama2-13B を大幅に上回り、Llama1-65B に近づいています (下の図)。
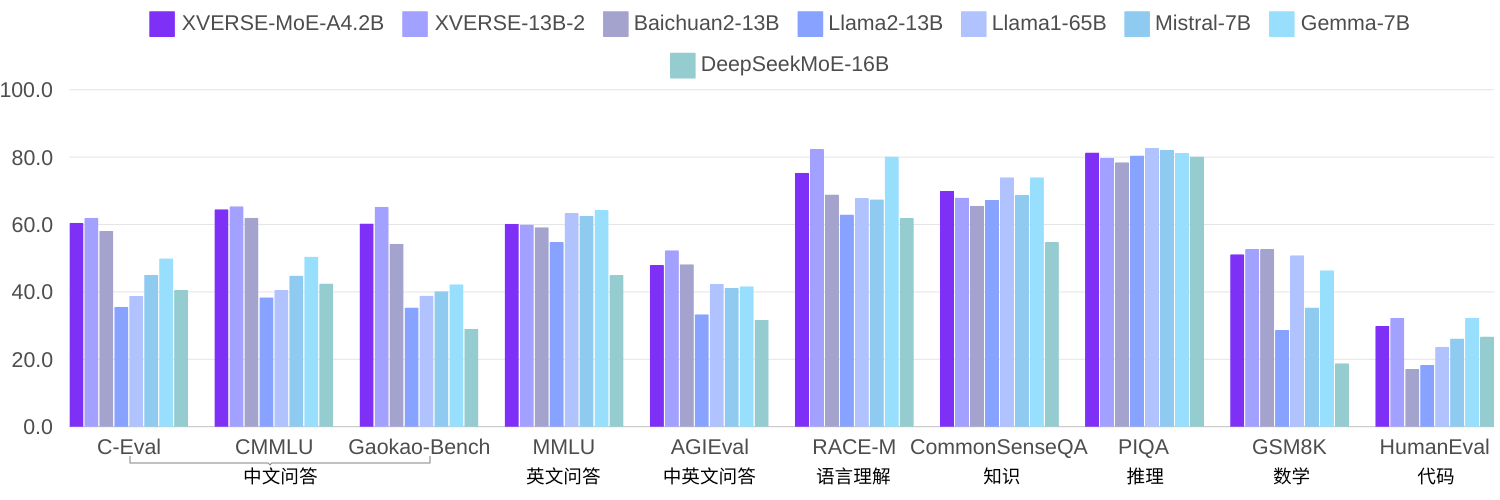
複数の信頼できるレビューを見る
オープンソースに関しては、要素大モデル「ファミリーバケット」が反復を続け、国内オープンソースを世界にリード一級レベル。アプリケーションの面では、Element は AI 3D テクノロジーの独自の利点を活用し、大型モデル 3D 空間や AIGC ツールなどのワンストップ ソリューションを立ち上げ、エンターテインメント、観光、金融などのさまざまな業界を強化し、インテリジェントな顧客サービス、クリエイティブな体験を提供します。 、効率改善ツールなど。複数のシナリオで優れたユーザー エクスペリエンスを作成します。
MoE技術の自己研究とイノベーション
教育省 (MoE) は、業界で最も最先端のモデル フレームワークです。比較的新しいテクノロジーのため、国内のオープンソース モデルや学術研究はまだ普及していません。 MetaObject は MoE の効率的なトレーニングと推論フレームワークを独自に開発し、次の 3 つの方向で革新しました。
パフォーマンスの面では、MoE アーキテクチャの独自のエキスパート ルーティングと重み計算ロジックに基づいて効率的な融合オペレーターのセットが開発されました。これにより、コンピューティング効率が大幅に向上します。MoE モデルにおける高いメモリ使用量と大量の通信量という課題を考慮して、コンピューティング、通信、メモリ オフロードの重複操作が全体の処理スループットを効果的に向上させるように設計されています。
アーキテクチャの面では、各エキスパートのサイズを標準の FFN と同等にする従来の MoE (Mixtral 8x7B など) とは異なり、Yuanxiang はよりきめ細かいエキスパート設計を採用しており、各エキスパートのサイズは標準の FFN のわずか 4 分の 1 です。まず、モデルの柔軟性とパフォーマンスが向上します。また、エキスパートが 2 つのカテゴリ (共有エキスパートと非共有エキスパート) に分類されます。共有エキスパートは計算中にアクティブなままですが、非共有エキスパートは必要に応じて選択的にアクティブになります。この設計は、一般知識を共有エキスパート パラメータに圧縮し、非共有エキスパート パラメータ間の知識の冗長性を軽減するのに役立ちます。
スイッチトランス、ST-MoE、DeepSeekMoE からインスピレーションを得たトレーニングに関して、Yuanxiang は、専門家間の負荷のバランスを良くするためにロード バランシング損失項を導入しました。ルータの Z-loss 項は、効率的で安定した動作を保証するために使用されます。トレーニング。
アーキテクチャの選択は、一連の比較実験を通じて得られました (下の図)。実験 3 と実験 2 では、パラメーターの総量と活性化パラメーターの量は同じでしたが、前者はより高いパフォーマンスをもたらしました パフォーマンスこれに基づいて、実験 4 ではさらに専門家を共有型と非共有型の 2 つのタイプに分類することで、効果が大幅に向上しました。実験 5 では、エキスパートのサイズが標準の FFN と等しい場合に共有エキスパートを導入する方法を検討しますが、その効果は理想的ではありません。
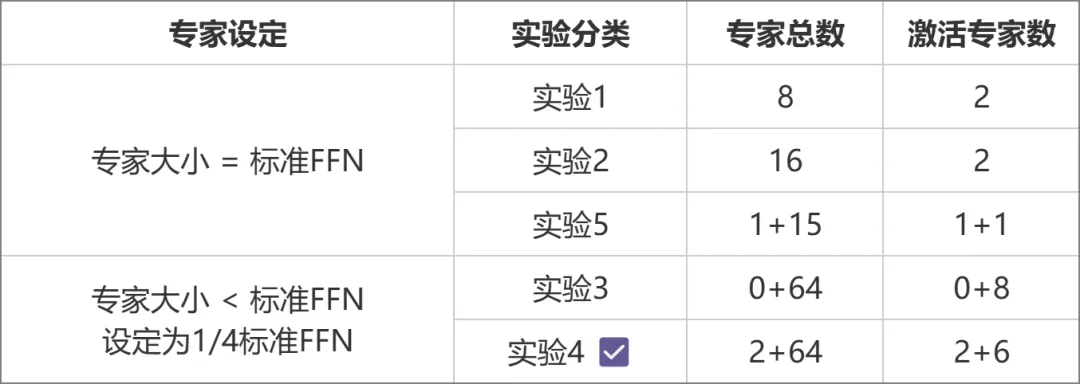
実験設計計画の比較
包括的なテスト結果 (下の図) では、最終的に Yuanxiang は実験 4 に対応するアーキテクチャ設定を採用しました。将来に目を向けると、Google Gemma や
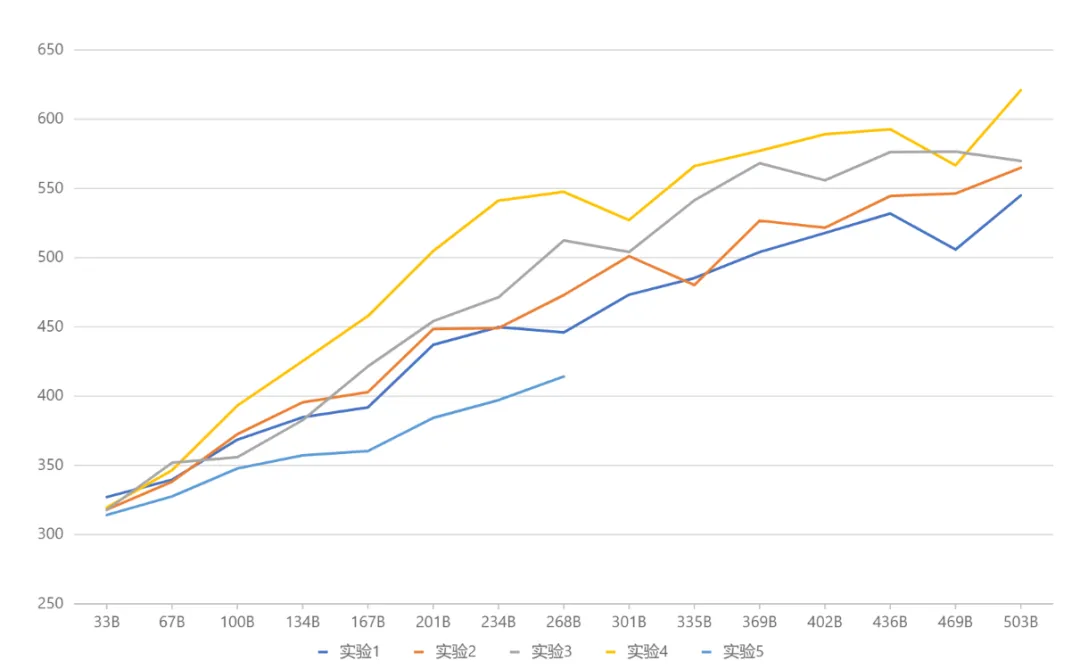
実験結果の比較
大きなモデルの無料ダウンロード
- ハグフェイス: https://huggingface.co/xverse / XVERSE-MoE-A4.2B
- ModelScope:https://modelscope.cn/models/xverse/XVERSE-MoE-A4.2B
- Github:https://github.com /xverse-ai/XVERSE-MoE-A4.2B
- お問い合わせは、opensource@xverse.cn
以上がYuanxiang の最初の MoE 大型モデルはオープンソースです: 42 億の活性化パラメーター、効果は 13 億のモデルに匹敵しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。