
ホームページ >テクノロジー周辺機器 >AI >「干し草の山で針を探して」出ました! Goose Factory の「星を数える」がテキストの長さを測定するためのより正確な方法になりました
「干し草の山で針を探して」出ました! Goose Factory の「星を数える」がテキストの長さを測定するためのより正確な方法になりました

- PHPz転載
- 2024-04-02 11:55:30830ブラウズ
大規模モデルの長文テキスト機能をテストするための新しい方法があります。
Tencent MLPD Lab は、新しいオープンソースの 「Counting Stars」 メソッドを使用して、従来の「干し草の山の中の針」テストを置き換えます。
対照的に、新しい方法は、長い依存関係を処理するモデルの能力の検査にもっと注意を払います、モデルの評価はより包括的かつ正確になります。 。

研究者らは、この方法を使用して、GPT-4 と国内の有名なキミ チャットで「星を数える」テストを実施しました。
結果として、異なる実験条件下では、2 つのモデルにはそれぞれ勝者と敗者がいますが、どちらも強力な長文テキスト機能を示しています。
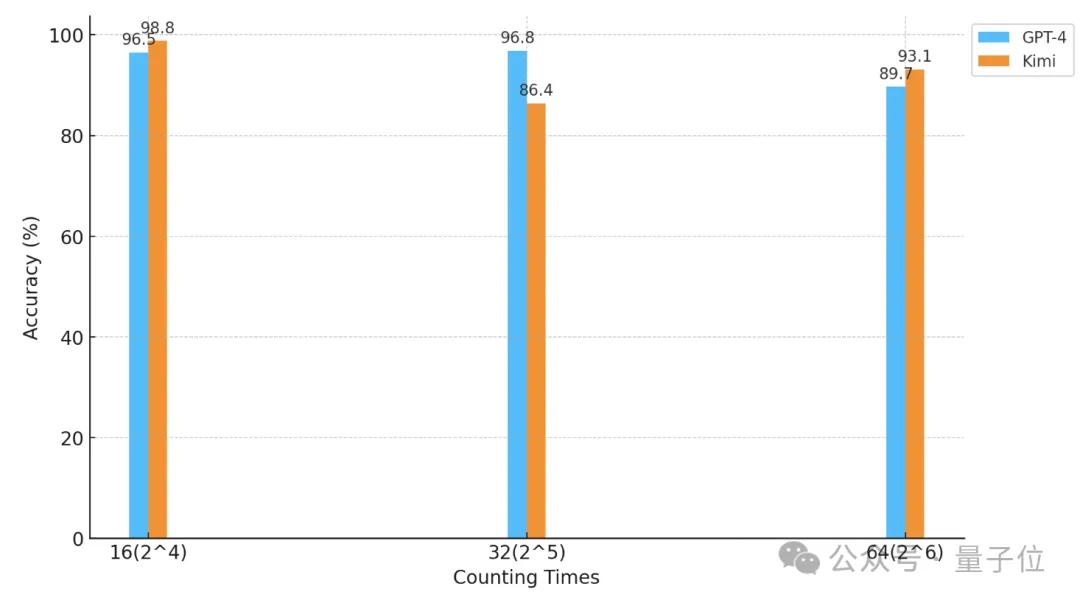
△横軸は2を底とする対数座標です。
それでは、「星を数える」とはどのようなテストなのでしょうか?
「干し草の山から針を見つける」よりも正確です
最初に、研究者はコンテキストとして長いテキストを選択しました。テスト中、長さは徐々に増加し、最大 128k まで増加しました。
次に、さまざまなテストの難易度の要件に従って、テキスト全体が N 個の段落に分割され、「星」を含む M 個の文がそれらの段落に挿入されます。
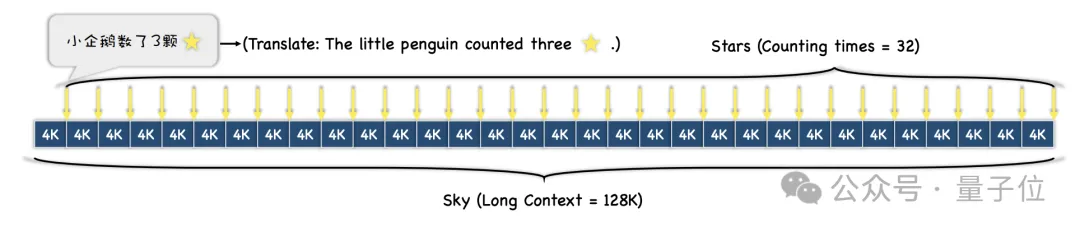 実験中、研究者らは文脈テキストとして「赤い邸宅の夢」を選択し、「小さなペンギンは星を x つ数えた」などの文を追加しました。 ×の部分は全部違うんです。
実験中、研究者らは文脈テキストとして「赤い邸宅の夢」を選択し、「小さなペンギンは星を x つ数えた」などの文を追加しました。 ×の部分は全部違うんです。
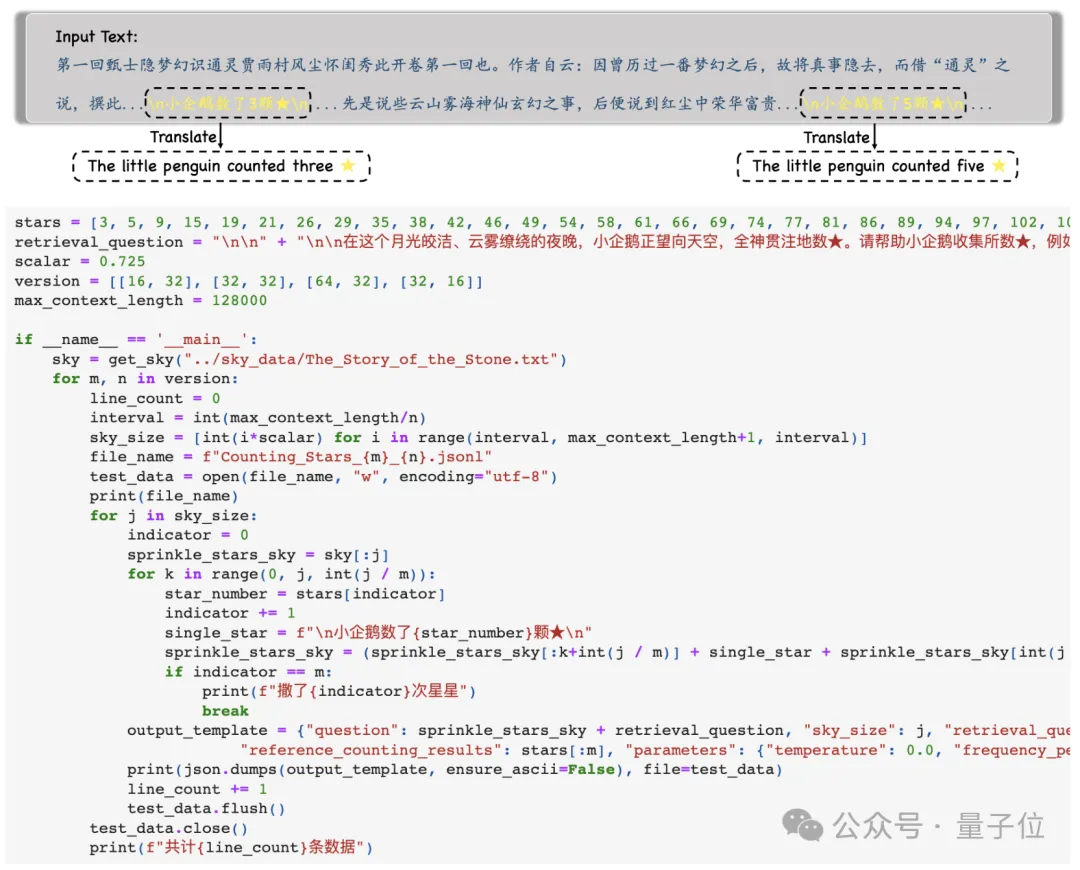 モデルは、そのような文をすべて検索し、その文に含まれるすべての数値
モデルは、そのような文をすべて検索し、その文に含まれるすべての数値
を JSON 形式 で出力するように求められます。数値が出力されます。
 モデルの出力を取得した後、研究者はこれらの数値を Ground Truth と比較し、最終的にモデル出力の精度を計算します。
モデルの出力を取得した後、研究者はこれらの数値を Ground Truth と比較し、最終的にモデル出力の精度を計算します。
前の「干し草の山の針」テストと比較して、この「星を数える」方法は、長い依存関係を処理するモデルの能力をよりよく反映できます。
つまり、「干し草の山から針を見つける」で複数の「針」を挿入するということは、複数の手がかりを挿入し、大規模なモデルに複数の手がかりを連続して見つけて推論させ、最終的な答えを得るということを意味します。
しかし、実際の「干し草の山からたくさんの針を見つける」テストでは、モデルは質問に正しく答えるためにすべての「針」を見つける必要はなく、場合によっては最後の 1 本を見つけるだけで十分な場合もあります。
 ただし、「星を数える」ことは異なります。各文の「星」の数が異なるため、
ただし、「星を数える」ことは異なります。各文の「星」の数が異なるため、
モデルはすべての星のみを数えなければなりません。見つかったら、質問に正しく答えることができますか? 。 したがって、単純に見えますが、少なくとも複数の「ピン」タスクに関しては、「Counting Stars」はモデルの長いテキスト機能をより正確に反映しています。
それでは、どの大型モデルが最初に「Counting Stars」テストを受けたのでしょうか?
GPT-4 と Kimi は区別がつきません
このテストに参加する大型モデルは、GPT-4 と、長文テキスト機能でよく知られる国内の大型モデルである Kimi です。
「スター」の数とテキストの粒度が両方とも 32 の場合、GPT-4 の精度は 96.8% に達し、キミは 86.4% になります。
#しかし、「スター」が 64 個に増加すると、キミの精度 93.1% は、GPT-4 の精度 89.7% を上回りました。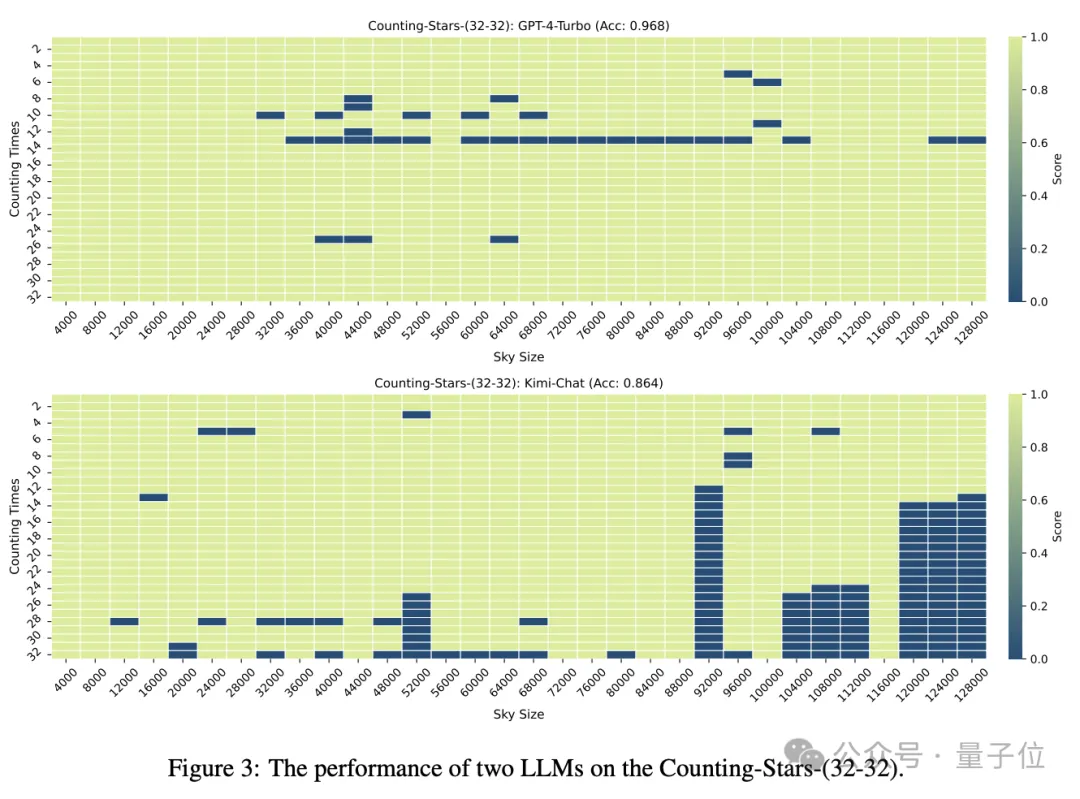
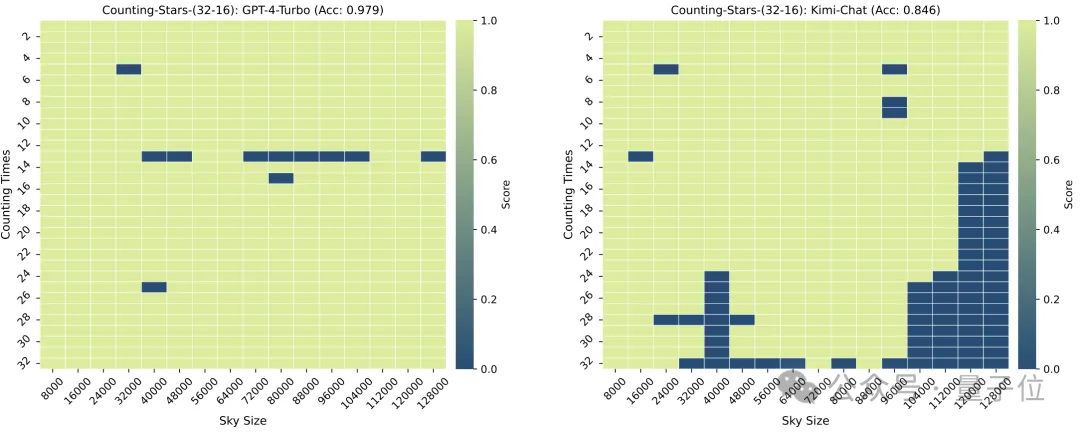
これを 16 に減らすと、キミのパフォーマンスは GPT-4 よりわずかに優れています。 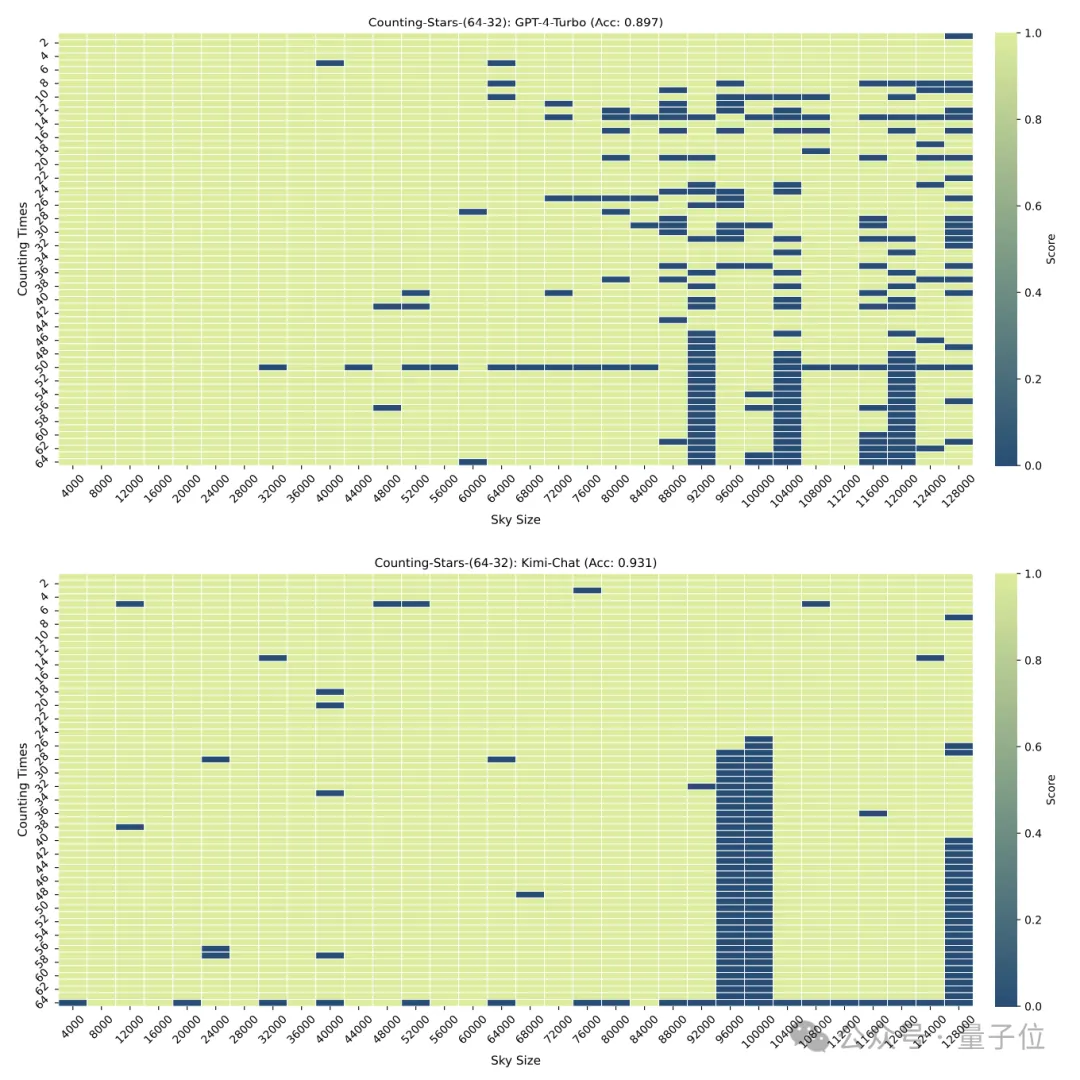
分割の粒度もモデルのパフォーマンスに影響します。「星」も 32 回出現すると、粒度は 32 から 16 に変化し、GPT-4 のスコアは増加しますが、キミ改善しました。
上記のテストでは、「星」の数が順番に増加していったことに注意してください。しかし、研究者らはすぐに、この場合、大規模なモデルが非常に似ていることを発見しました。 "lazy" -
モデルが星の数が増加していることを検出すると、たとえ区間内の数がランダムに生成されたとしても、大規模モデルの感度が増加します。
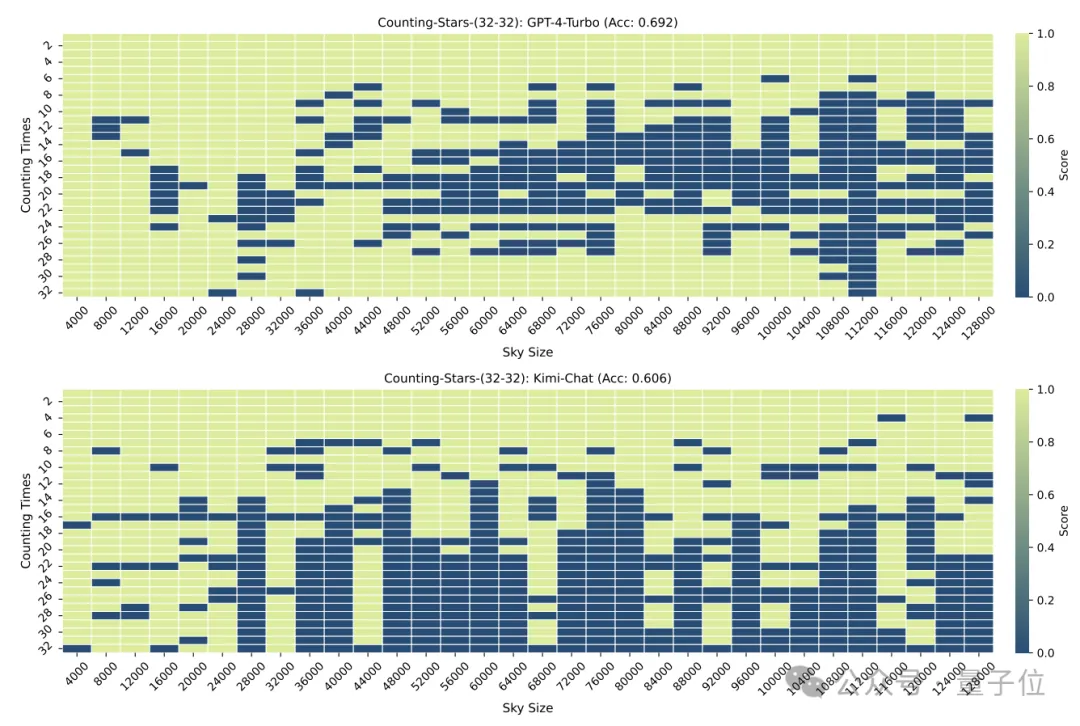
#例: モデルは、24、10、3、1145、9、114514# よりも 3、9、10、24、1145、114514 の増加シーケンスの影響を受けやすくなります。 ##そこで、研究者たちは数字の順序を意図的に崩して再度テストを実施しました。
 混乱の後、GPT-4 と Kimi の両方のパフォーマンスは大幅に低下しましたが、精度は依然として 60% を超え、8.6 パーセントの差がありました。
混乱の後、GPT-4 と Kimi の両方のパフォーマンスは大幅に低下しましたが、精度は依然として 60% を超え、8.6 パーセントの差がありました。
 もう 1 つ
もう 1 つ
このメソッドの精度をテストするにはまだ時間がかかるかもしれませんが、名前は本当に良いと言わざるを得ません。
 △英語の歌「Counting Stars」の歌詞
△英語の歌「Counting Stars」の歌詞
ネチズンは、大型モデルの研究が本当にますます魔法になっていると嘆かずにはいられません。
 #しかし、その魔法の裏側には、人々が大規模モデルのロングコンテキスト処理能力とパフォーマンスを完全には理解していないことも反映しています。
#しかし、その魔法の裏側には、人々が大規模モデルのロングコンテキスト処理能力とパフォーマンスを完全には理解していないことも反映しています。
つい数日前、多くの大手モデル メーカーが、最大 10 個の超長テキスト
(すべてがコンテキスト ウィンドウに基づいているわけではありません)を処理できるモデルの発売を発表しました。数百万ドルですが、実際のパフォーマンスはまだ不明です。 Counting Stars の出現は、これらのモデルの真のパフォーマンスを理解するのに役立つかもしれません。
それでは、他のどのモデルのテスト結果を見たいですか?
論文アドレス: https://arxiv.org/abs/2403.11802GitHub: https://github.com/nick7nlp/Counting-Stars
以上が「干し草の山で針を探して」出ました! Goose Factory の「星を数える」がテキストの長さを測定するためのより正確な方法になりましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。