
ホームページ >テクノロジー周辺機器 >AI >OccFusion: Occ 用のシンプルで効果的なマルチセンサー フュージョン フレームワーク (パフォーマンス SOTA)
OccFusion: Occ 用のシンプルで効果的なマルチセンサー フュージョン フレームワーク (パフォーマンス SOTA)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-03-08 11:50:03863ブラウズ
自動運転では 3D シーンを包括的に理解することが重要であり、最近の 3D セマンティック占有予測モデルは、さまざまな形状やカテゴリを持つ現実世界のオブジェクトを記述するという課題にうまく対処しています。ただし、既存の 3D 占有予測方法はパノラマ カメラ画像に大きく依存しているため、照明や気象条件の変化の影響を受けやすくなっています。 LIDAR やサラウンドビュー レーダーなどの追加センサーの機能を統合することで、当社のフレームワークは占有予測の精度と堅牢性を向上させ、nuScenes ベンチマークで最高のパフォーマンスを実現します。さらに、困難な夜間や雨のシーンを含む nuScene データセットに関する広範な実験により、さまざまなセンシング範囲にわたるセンサー フュージョン戦略の優れたパフォーマンスが確認されました。
論文リンク: https://arxiv.org/pdf/2403.01644.pdf
論文名: OccFusion: 3D 占有予測のための簡単で効果的なマルチセンサー フュージョン フレームワーク
この論文の主な貢献は次のように要約されます:
- カメラ、ライダー、レーダー情報を統合して 3D セマンティック占有予測タスクを実行するマルチセンサー フュージョン フレームワークが提案されています。
- 3D セマンティック占有予測タスクでは、マルチセンサー フュージョンの利点を実証するために、私たちの方法が他の最先端 (SOTA) アルゴリズムと比較されます。
- 夜間や雨などの厳しい照明条件や気象条件下で、さまざまなセンサーの組み合わせによって達成されるパフォーマンスの向上を評価するために、徹底したアブレーション研究が実施されました。
- さまざまなセンサーの組み合わせと困難なシナリオを考慮して、3D セマンティック占有予測タスクにおけるフレームワークのパフォーマンスに対する知覚距離要因の影響を分析するための包括的な調査が実施されました。
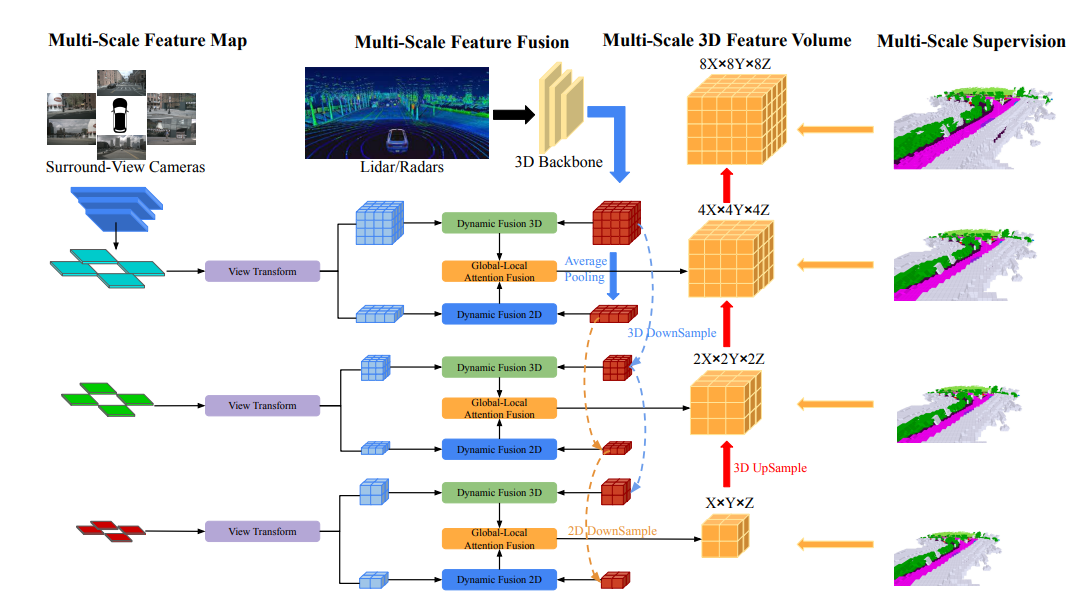
ネットワーク構造の概要
OccFusion の全体的なアーキテクチャは次のとおりです。まず、サラウンド ビュー画像が 2D バックボーンに入力され、マルチスケールの特徴が抽出されます。続いて、各スケールでビュー変換が実行され、各レベルでのグローバル BEV 特徴とローカル 3D 特徴ボリュームが取得されます。 LIDAR とサラウンド レーダーによって生成された 3D 点群も 3D バックボーンに入力され、マルチスケールのローカル 3D 特徴量とグローバル BEV 特徴が生成されます。各レベルのダイナミック フュージョン 3D/2D モジュールは、カメラと LIDAR/レーダーの機能を組み合わせます。この後、マージされたグローバル BEV フィーチャと各レベルのローカル 3D フィーチャ ボリュームがグローバル-ローカル アテンション フュージョンに供給されて、各スケールで最終的な 3D ボリュームが生成されます。最後に、各レベルの 3D ボリュームがアップサンプリングされ、マルチスケール監視メカニズムによってスキップ接続されます。
実験的比較分析
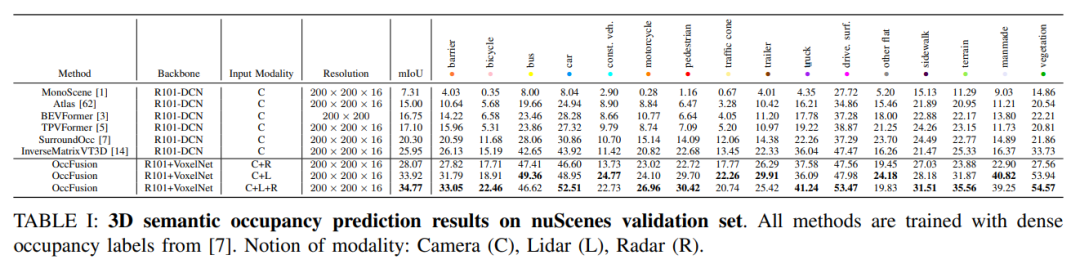
nuScenes 検証セットでは、高密度占有ラベル トレーニングに基づくさまざまな方法が 3D セマンティクスで実証されています。占有率予測で。これらの方法には、カメラ (C)、ライダー (L)、レーダー (R) などのさまざまなモーダル概念が含まれます。
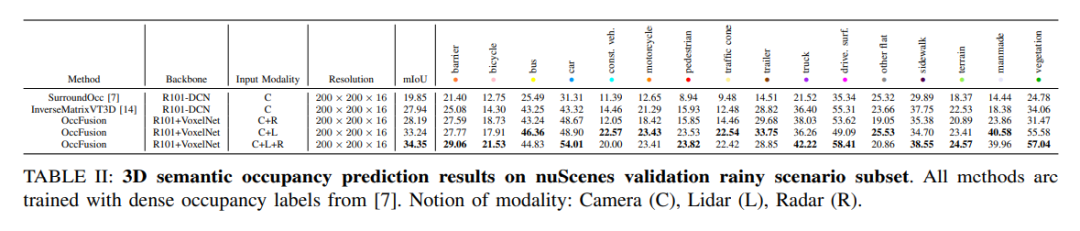
nuScenes データセットの雨のシーンのサブセットで、3D セマンティック占有を予測し、トレーニングに高密度占有ラベルを使用します。この実験では、カメラ (C)、ライダー (L)、レーダー (R) などのさまざまなモダリティからのデータを考慮しました。これらのモードを融合することで、雨のシーンをよりよく理解して予測することができ、自動運転システムの開発に重要な参考資料となります。
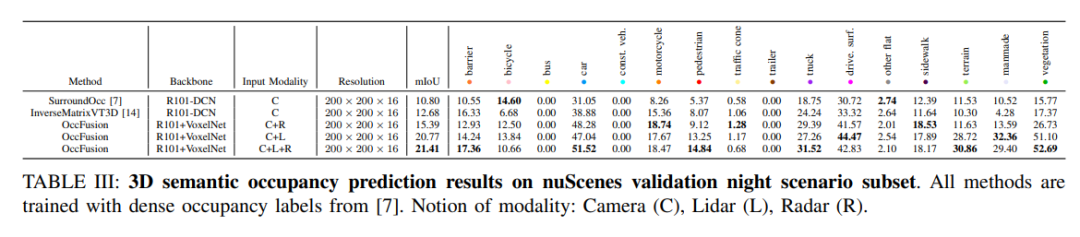
#nuScenes は、夜間シーンのサブセットに対する 3D セマンティック占有予測結果を検証します。すべてのメソッドは、高密度の占有ラベルを使用してトレーニングされます。モーダルコンセプト: カメラ (C)、ライダー (L)、レーダー (R)。
パフォーマンスの変化傾向。 (a) nuScenes 検証セット全体のパフォーマンス変化傾向、(b) nuScenes 検証夜景サブセット、(c) 雨シーン サブセットの nuScenes 検証パフォーマンス変化傾向。
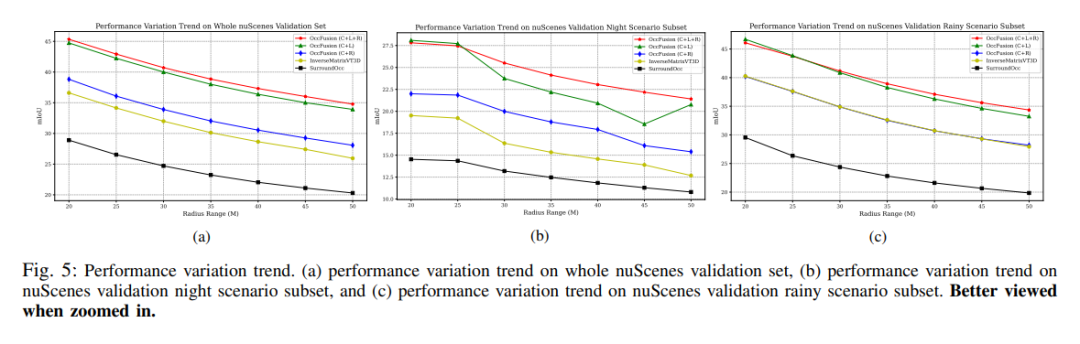
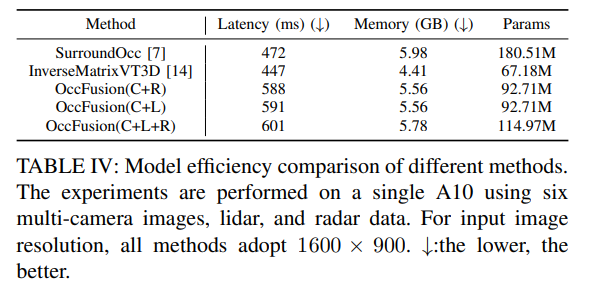
表 4: さまざまな方法のモデル効率の比較。実験は、6 台のマルチカメラ画像、ライダー、レーダー データを使用して A10 で実施されました。入力画像の解像度は、すべての方式で 1600×900 が使用されます。 ↓:低いほど良い。
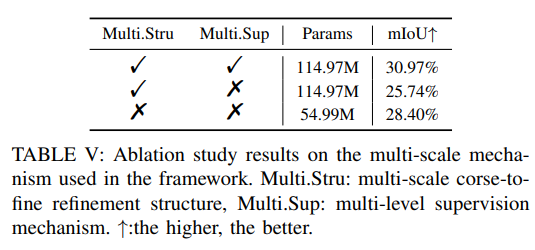
その他のアブレーション実験:


以上がOccFusion: Occ 用のシンプルで効果的なマルチセンサー フュージョン フレームワーク (パフォーマンス SOTA)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。